近期关于 scaling law 的讨论甚嚣尘上,很多观点认为 scale law is dead. 然而,我们认为,高质量的 “无监督” 数据才是 scaling law 的关键,尤其是教科书级别的高质量的知识语料。此外,尽管传统的语料快枯竭了,但是互联网上还有海量的视频并没有被利用起来,它们囊括了丰富的多种模态的知识,可以帮助 VLMs 更好好地理解世界。
浙大和阿里巴巴达摩院联合提出一个图文交织的多模态知识语料:他们收集互联网上超过 22000 课时 (两年半) 的教学视频,提取关键步骤的画面和音频(转录成文本),组织成连贯、图文交织的格式,制作成数学,物理,化学等多个学科的图文教科书 (textbook)。基于这些 textbook,VLMs 可以像人类上课一样学习这些图文交织,由易至难的学科知识。

- 论文地址: arxiv.org/abs/2501.00958
- Code: https://github.com/DAMO-NLP-SG/multimodal_textbook
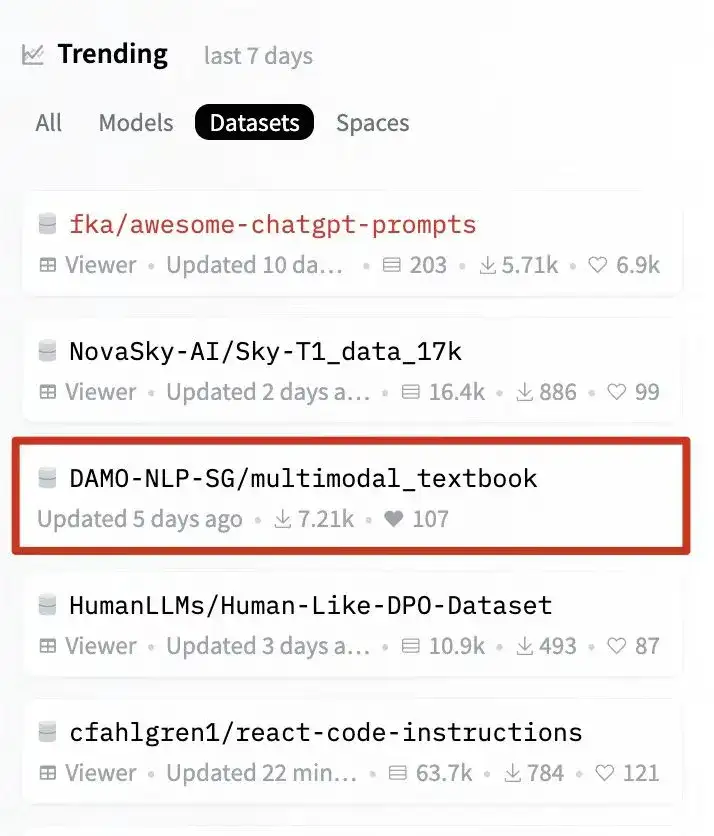
该研究还登上了huggingface dataset trending榜单,不到两周下载量已经7000+。
1. 背景和动机
当前多模态大模型(VLMs)的预训练语料主要有两种形式:图像 - 文本对语料以及图文交织语料:
- 图文对数据 (image-text pair corpus):多模态模型通常依赖大量图文对数据进行预训练,这种数据能快速对齐图像与文本。
- 图文交错数据集 (image-text Interleaved corpus):如 MMC4, OBELICS 等数据集,它们引入了更加自然,更加灵活的图文任意交织形式。这些语料由穿插着图像的文本段落组成,通常是从网页和文档(如 Common Crawl)中抓取的。与图像 - 文本对数据相比,图文交错语料库使 VLMs 能够更自然地处理任意输入,像人类一样理解世界。
然而当前的 interleaved corpus 大多爬取自网页或者文档,存在以下问题:
(1)文本与图像关系松散:网页中的图像和文本之间的关联通常很松散,甚至可能包括不相关的图像,例如徽标或广告。
(2)图像序列缺乏逻辑连贯性:大多数网页包含的图像相对较少,更重要的是,图像之间的逻辑关系往往很模糊,使得学习复杂的视觉推理变得困难。
(3)知识密度低:抓取的网页不可避免地包括新闻、娱乐和广告推荐等内容,很少涉及专业知识,即知识密度较低。
因此,探索如何构建高质量、教科书级别的 interleaved 数据集是非常必要的。此外我们还注意到互联网中存在的海量的教学视频 (例如 Youtube 上的在线课程),这些视频包含丰富的知识,人们经常使用这些视频来学习基础学科知识,但这些宝贵资源在 VLMs 训练中仍未得到充分利用。基于此,我们思考如何让 VLMs 像人类一样,利用这些教学视频进行高质量的预训练,从而提升其知识水平和推理能力。为实现这一目标,关键在于将这些教学视频转化为教科书级别的图文交织训练语料。

2. 方法:如何利用教学视频构建高质量的知识语料
2.1 LLM 辅助分门别类地收集教学视频
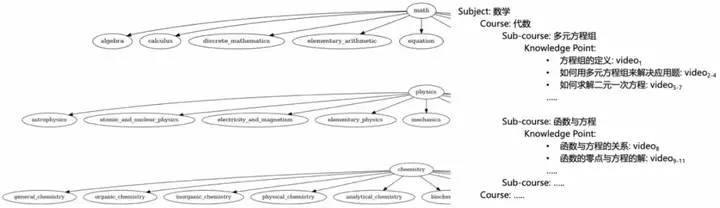
- 知识分类体系的构建:我们创建了一个四层的知识分类体系,包括学科(Subject)、课程(Course)、子课程(Sub-course)和知识点(Knowledge Point),然后使用 LLM 来自动构建这个分类体系。
- 涵盖数学、物理、化学、地球科学、工程学和计算机科学六大学科,共计 55 门课程,细化为 3915 个知识点。示例:数学(学科) → 小学数学(课程) → 有理数与无理数 (子课程) → 无理数的定义 (知识点)。
添加图片注释,不超过 140 字(可选)
- 教学视频的收集和过滤:
- 以构建的知识体系中的每个知识点为检索关键词,利用在线视频网站 (例如 YouTube) 的 API 搜索相关教学视频的元数据,每个知识点保留排名靠前的 50 个视频。然后我们利用 LLM 对所有视频元数据进行审查 (视频标题,简介,评论等),过滤不合适的视频,并且去除重复的视频。
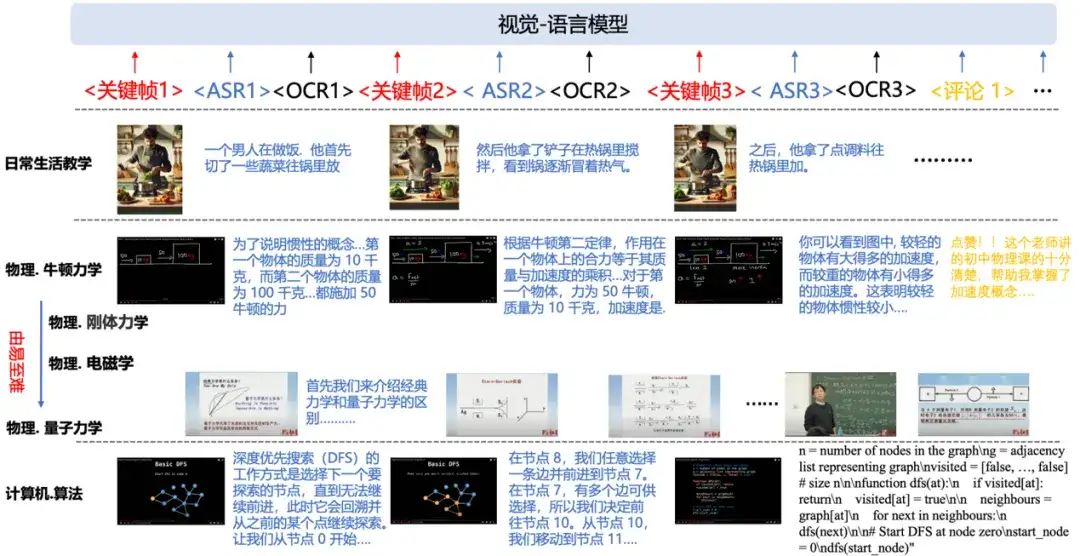
2.2 Video-to-Textbook Pipeline
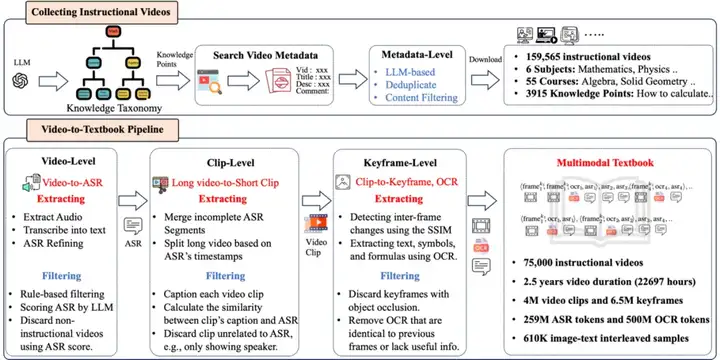
为了将教学视频转化为多模态教科书,我们设计了一个多层级的处理流程,包括 video-level、clip-level 和 keyframe-level,确保数据的高质量和知识的密集性。
(1) Long Video-Level
- 音频提取与转录(ASR):使用 FFmpeg 提取音频,并通过 Whisper 模型进行转录,将视频的讲解转化为文本。
- 转录文本质量:由于教程语音的口语化特点,ASR 文本的困惑度(PPL)较高。我们通过 LLM 重写转录文本,提升其流畅性与连贯性,同时保持原始语义不变。
- 视频质量评估:通过 LLM 对转录文本进行分析,按以下标准过滤低质量视频:
- 相关性:确保转录文本与目标知识点匹配,剔除与教学内容无关的视频(如广告、综艺片段)。知识密度:剔除知识点稀疏、包含大量无意义填充词的视频,如 “嗯”“然后我们得到这个” 等口语表达。转录质量:删除 Whisper 转录质量较低的文本,例如重复、识别错误的文本。
最终我们保留了 75,000 个高质量教学视频和对应的 ASR。
(2)Video Clip-Level
- 视频分割:为实现文本与帧的时间对齐。我们现合并多个 ASR 片段,形成具有完整语义的句子。然后利用合并后的 ASR 的时间戳将长视频切分为 10-20 秒的短片段 (video clip),每个 video clip 包含一段语音文本和对应的视频帧。视觉知识和文本知识匹配:
- 使用 VideoLlama2 为每个 video clip 生成详细描述 (caption);计算 video clip 的 caption 与 ASR 文本的相似度,剔除视觉内容与文本内容不匹配的片段,或者剔除无信息量的 clips(例如如过渡场景,仅有演讲者的画面或者严重遮挡的画面)。这些 clips 的视觉信息虽然过滤了,但是对应的 ASR 依然保留在 textbook 中。
(3)Keyframe-Level
- 关键帧检测:通过计算连续帧之间的结构相似性( Structural Similarity Index, SSIM),提取视觉变化显著的帧,迭代式地过滤掉重复或冗余的画面。OCR 文本提取:由于教学视频中常包含文本、公式和符号等重要知识,我们使用先进的 VLMs(如 InternVL)对关键帧进行 OCR,这些内容往往蕴含重要的教学知识,作为 ASR 的补充。
最后,我们将处理后的关键帧、OCR 文本和 ASR 转录按时间顺序排布,交错组织成多模态教科书。
3. 数据集统计和分析
- 教学视频和知识点统计
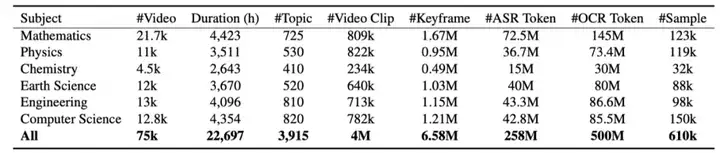
我们收集了 15.9 万个教学视频,经过元数据审查,去重和 ASR 过滤后保留了 7.5 万个长视频,视频总时长超过 22000 小时 (2.5 年)。这些教学视频囊括数学,物理,化学,地科,工程,计算机六大学科,3915 个知识点。
- Textbook 统计
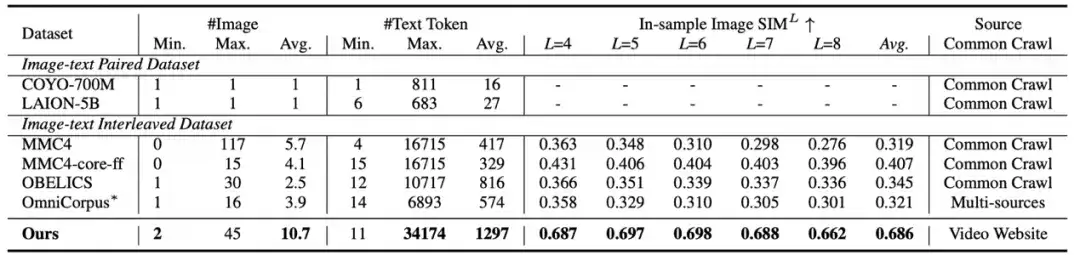
经过 video-to-textbook pipeline,我们生成了 6.5M 个关键帧、258M ASR tokens 和 500M OCR tokens。我们将其拼接成 610k 个样本,每个样本平均包含 10.7 张图片,1297 个 text tokens。我们观察到样本内图像之间的相似度显著高于先前的 interleaved dataset,例如 MMC4 和 OBELICS。这体现了我们的 textbook 语料中图片之间关系更紧密,知识密度更高。
4. 实验和分析
4.1 实验设置
我们使用主流的多模态模型 LLaVA-1.5-7B 和 Idefics2-8B 作为基座模型,对比 textbook 数据集与 webpage-centric interleaved datasets (MMC4 和 OBELICS) 的持续预训练的效果。
4.2 持续预训练的实验效果
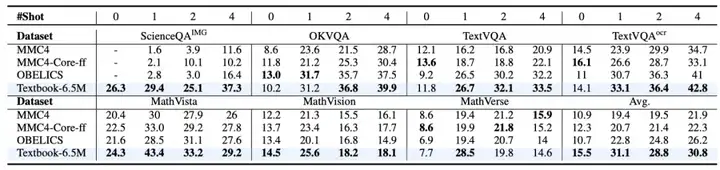
模型性能提升显著:在 Textbook-6.5M 上预训练后,LLaVA-1.5 和 Idefics-8B 在多个基准上表现出显著改进。在 0-shot 到 4-shot 设置下,分别提升了 +3.2%、+8.3%、+4.0% 和 +4.6%。即使对于像 Idefics2 这样的原本支持图文交织输入的 VLM,该 textbook 仍带来了额外 +1.4% 的提升,突出了其丰富的知识内容和高数据质量。
在知识和推理基准上优势明显:在知识导向和推理相关基准上,该数据集相比其他数据集改进显著。例如在 ScienceQA 上,与 MMC4 相比,零样本和少样本设置下均有超过 20% 的提升。在 MathVista 等数学相关基准上,与 OBELICS 相比,平均改进 +5.3% 和 +6.4%。
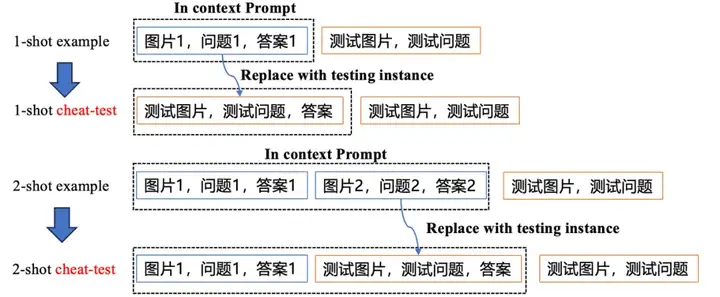
4.3 “作弊测试” 检验上下文感知 (in-context awareness) 能力
- 我们设计了一个作弊测试(cheat test) 来测试 VLMs 是否能有效感知图文交织的上下文。Cheat-test: 我们将 few-shot example 中的某个示例替换成测试样本,观察模型是否能快速识别 prompt 中的已经包含了测试样本。
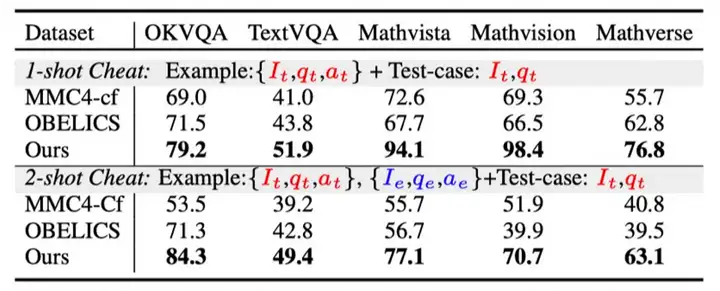
- Cheat-test 显示在 1-shot 和 2-shot 场景下,相比 MMC4 和 OBELICS,textbook 有近 20% 的显著优势。这表明来自视频的 textbook 训练语料让 VLMs 能更关注输入图文交织的 context,并且能利用 context 中的线索回答问题。例如在 MathVista 任务中,Textbook 训练的模型在 1-shot 设置下准确率达到 94.1%,远超 MMC4 的 72.6%。
4.4 其他实验
除了上述实验,作者还研究了数据集中图像顺序的影响,指令微调后下游任务性能,以及一系列的消融实验。通过这些实验表明了数据集的高质量。
总结和展望
我们引入了一种多模态教科书来预训练视觉语言模型,使它们能够以自然且图文交织的方式学习专业知识。通过收集海量的在线教育视频并将其转换为关键帧 - 自动语音识别(ASR)交错数据集,这本教科书提供了一个更加连贯且相互关联的学习语境,补充了传统的图像 - 文本对齐方法。实验证明了其有效性,特别是在 VLMs 的上下文感知和数学推理等方面。此外,这些 textbook 语料不仅仅可以用来做多模态的理解,未来还可以探索利用它们实现任意模态的连续生成,实现更好的世界模型。
作者介绍
本文一作是张文祺 (浙江大学博士生),他的研究基础是基于大模型智能体,多模态模型等,开发了数据分析智能体 Data-Copilot,在 github 上获得超过 1400 stars。共同通讯包括鲁伟明 (浙江大学副教授),李昕(阿里巴巴达摩院算法工程师),其中李昕和张航(本文二作)主导开发了 VideoLlama 系列视频理解模型。其他作者包括浙江大学庄越挺教授,赵德丽(阿里巴巴达摩院基础智能中心主管), 邴立东(达摩院语言技术实验室主管),沈永亮(浙大百人计划研究员),孙嘉硕 (达摩院算法工程师)。
文章来自于“机器之心”,作者“机器之心”。

【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales

