【新智元导读】新年第一天,陈天奇团队的FlashInfer论文出炉!块稀疏、可组合、可定制、负载均衡......更快的LLM推理技术细节全公开。
新年第一天,FlashInfer在arxiv打响第一枪。

作者团队来自华盛顿大学、英伟达、Perplexity AI和CMU,曾开发了TVM、XGBoost,同时也是MXNET作者之一的陈天奇,也位列其中。

论文地址:https://arxiv.org/abs/2501.01005
FlashInfer实现了高效的注意力引擎,利用块稀疏和可组合格式来解决KV cache存储异构问题,优化了内存访问并减少冗余。
它还提供了可定制的注意力模板,通过即时编译(JIT)来适应各种Attention的设置。
另外,FlashInfer的负载平衡调度算法,可以根据用户请求的动态变化进行调整,同时又能够与静态配置的CUDAGraph保持兼容。

虽然论文是刚放出来,但FlashInfer早已实际应用到SGLang、vLLM和MLC-Engine等流行的LLM Serving框架中。
实测表明,FlashInfer能够在各种推理场景中显著提升内核性能。
与最先进的解决方案相比,FlashInfer将token间延迟降低了29%-69%,将长上下文推理的延迟降低了28%-30%,使并行生成的速度提高了13%-17%。

「对如何在LLM Serving框架中构建高效且可定制的注意力引擎感到好奇吗?快来看看Flashlnfer的最新论文吧,了解所有酷炫的想法。」
高效注意力引擎是怎样炼成的
LLM推理现状
原始Transformer本身的计算很简单,但要更好的为人民服务,就需要解决许多工程上的问题。
实际应用中,服务端会面临多样的工作负载,还有个性化的Attention实现,要满足延迟吞吐量等指标,又要能够充分发挥硬件的能力。
比如,LLM的推理可以分类为下面三种情况:
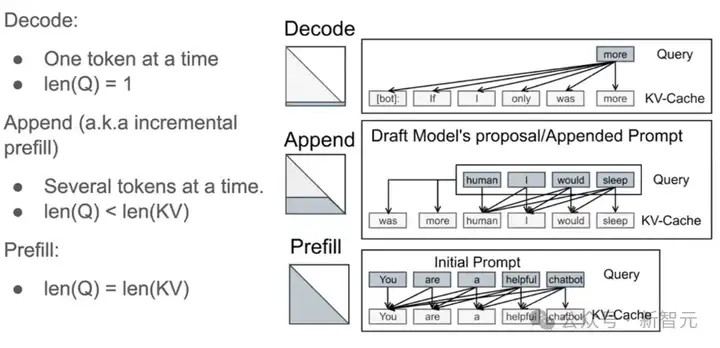
Prefill阶段拿到最开始的Prompt,填充kv cache;Decode阶段则是一个query计算出一个输出;存在多轮对话或者使用投机推理(Speculative Decoding)时,又可以有多个query向量并行计算。
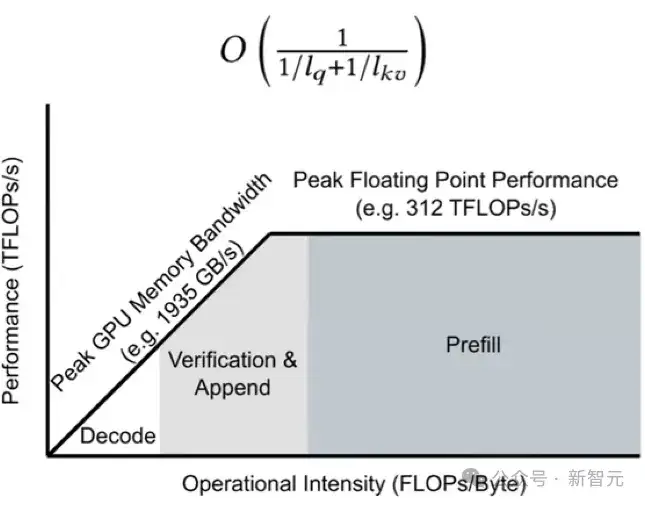
不同的输入带来了不同的计算访存比,给GPU的利用造成麻烦。
另一方面,当今流行的不同框架和方法在存储kv cache时,存在很大差异。
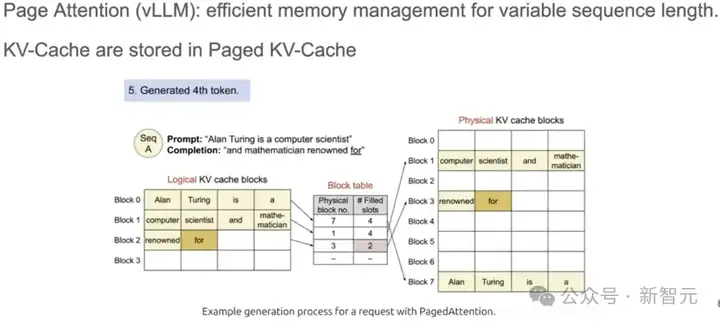
比如vLLM使用的Paged Attention,参照操作系统中分页管理内存的方式,将kv cache切成一个个block,逻辑上连续而物理上不连续。
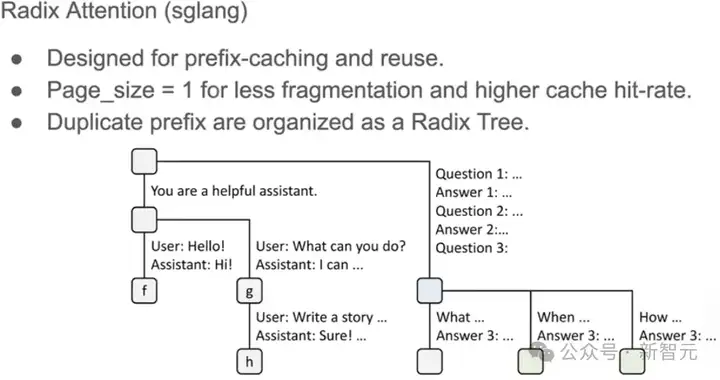
而SGLang采用的Radix Attention是一棵前缀树,不同query共享的kv cache(比如系统提示)存储在同一个节点。
再看Speculative Decoding,多个草稿小模型生成的token序列通常组织成token tree的形式,表示成矩阵时是稀疏的。
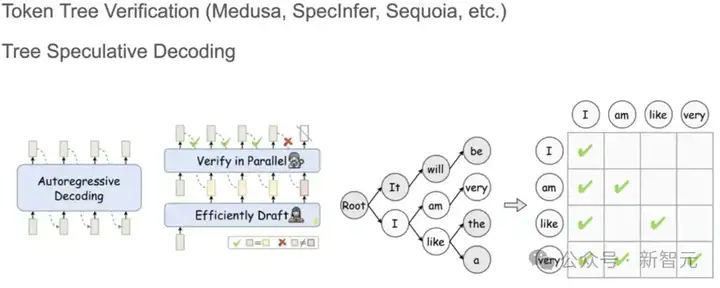
还有下面这种,通过重要性计算只选择topk个kv cache参与Attention计算,同样是稀疏矩阵的形式。
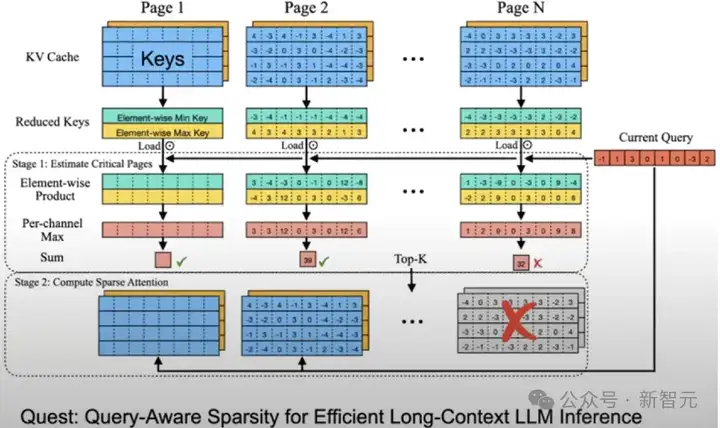
个性的Attention这么多,框架想要满足所有人的要求,kv cache应该怎么存储?
块稀疏格式出马
作者表示,所有这些都可以抽象成块稀疏(Block Compressed Sparse Row,BSR)矩阵。
BSR跟通常用来存储稀疏矩阵的CSR(Compressed Sparse Row)很像,如下图所示,CSR只需存储矩阵元素的非零值、在行中的下标、以及每行的偏移。
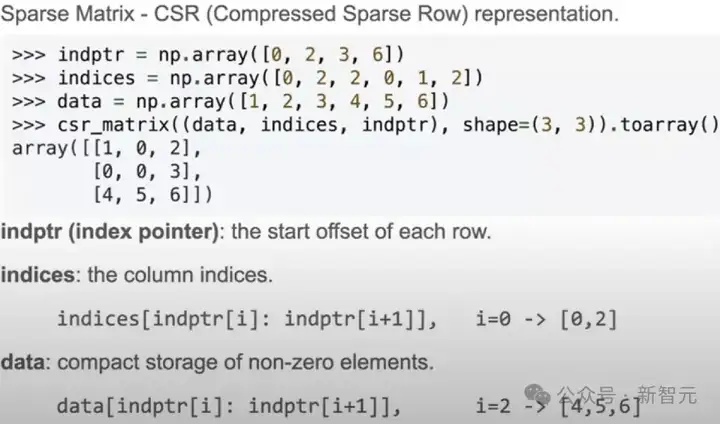
——但是这么稀碎的存储格式对显卡来说很不友好,于是做一些改进:
相同的存储方式,对应到BSR,只需将操作的最小单元由元素(单个数据)换成Block(一块数据),块大小为(Br,Bc)。
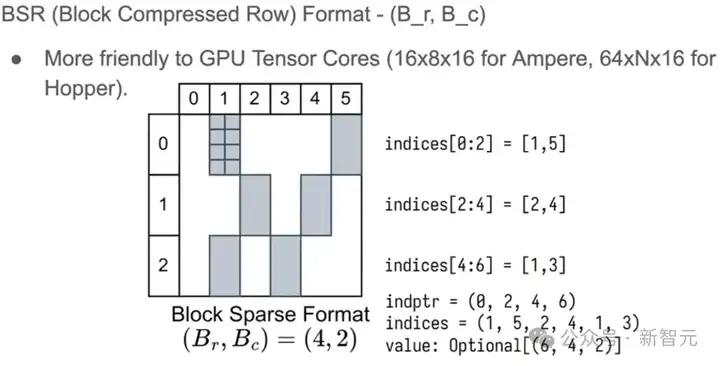
这样一来,显卡就可以直接加载整块的数据(比如16 * 16),来填满自己的tensor core,进行矩阵乘法。
有了BSR,我们再来看下之前提到的几种Attention。
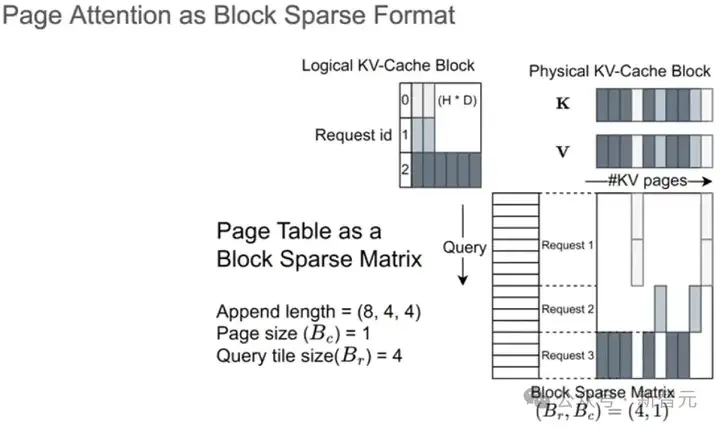
Paged Attention的block可以直接对应到BSR的block,如下图所示,让Bc = 1。而query tile size(Br)设为4保证矩阵乘法的硬件利用率。
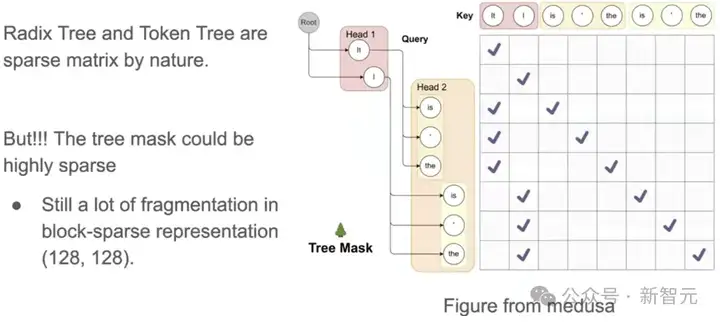
再看本身是树结构的Radix Tree和Token Tree,表示成矩阵时相当稀疏的,如果BSR使用比较大的方块(比如16 * 16)会造成很大的浪费。
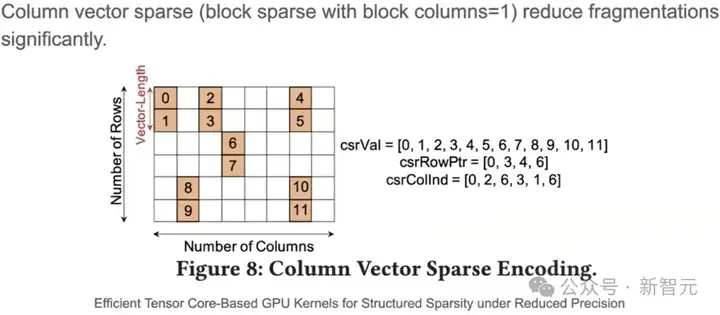
此时可以设置Bc = 1,如下图所示,再使用合适的向量长度,就可以消除大部分的冗余,同时显卡也支持下图这种形式的稀疏计算。
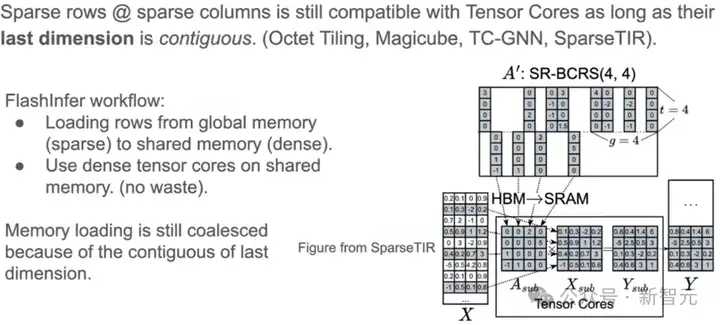
有研究表明,稀疏的矩阵只需让最后一维保持连续,即可享受到tensor core的加速。
在FlashInfer中,系统从global memory中加载稀疏块数据,并在shared memory中将其排布成密集格式,tensor core可以直接计算这些数据,不会产生硬件的浪费。
块并行与可组合
另外,FlashInfer采用与Block-Parallel Transformer (BPT)相同的形式分解kv cache(同时也是RingAttention和Flash-Decoding的实现依据)。
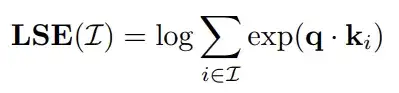
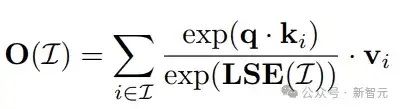
对于相同的query,需要计算的完整kv cache被分块,每块的Attention计算可以独立(并行)进行,只需记录一个统计量(这里是LSE),用于最后的汇聚。
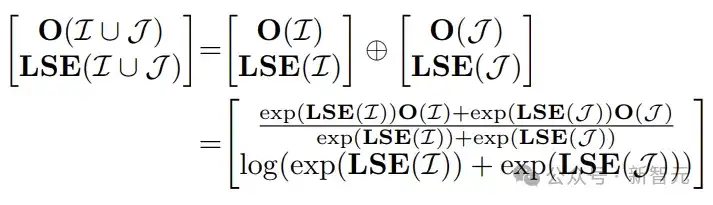
学会这个之后,再来看一下FlashInfer提供的可组合特性,当query之间存在可共享的kv cache时,可以把存储表示成不同大小block的组合。
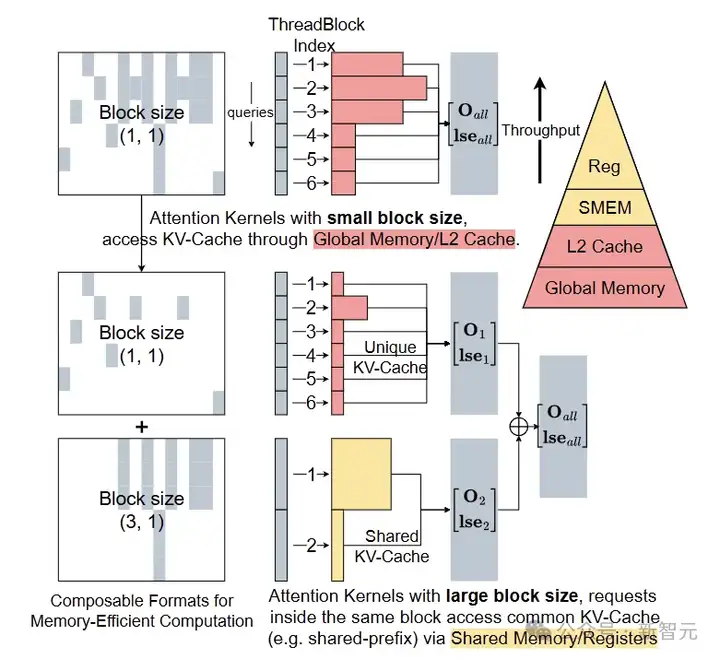
能够共享的部分使用大的block,让请求可以通过shared memory访问;不能共享的部分使用小的block,在global memory中访问。
拿捏定制化Attention
作者为FlashAttention开发了CUDA/CUTLASS模板,专为密集矩阵和块稀疏矩阵设计,兼容从Turing到Hopper架构的英伟达GPU。
其中,FlashAttention2用于Ada(sm89)之前的架构,FlashAttention3用于Hopper架构。
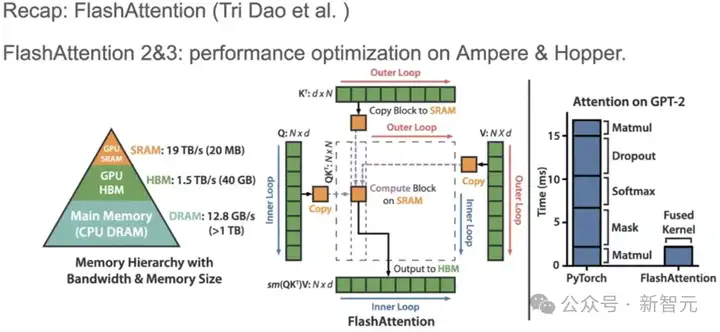
实现的主要改进包括:增强将稀疏块加载到共享内存中的能力、扩展块大小配置、针对分组查询注意力(GQA)优化内存访问模式、以及可自定义的注意力。
下面就说一下这个可自定义的注意力。
我们实际中接触到的各种LLM,会在算子中实现自己个性化的部分。受FlexAttention启发,FlashInfer提供了在Attention计算的不同阶段插入自定义函数的机制。
比如下面这个用于大模型位置编码的ALiBi,可以利用FlashInfer提供的接口轻松实现。

还有Gemma和Grok需要的Logits SoftCap、常见的RoPE位置编码、滑动窗口注意力机制等,都可以通过这种方式无痛解决。

数据移动
FlashInfer的注意力模板支持任意的块大小,由于块可能与张量核心形状不对齐,所以需要专门的数据加载方法,也就是前面讲过的,将tiles从分散的全局内存转移到连续的共享内存。
单个MMA指令可以指定可以块稀疏矩阵中的不同块作为Tensor core的输入,下图展示了FlashInfer如何将tiles加载到共享内存中:
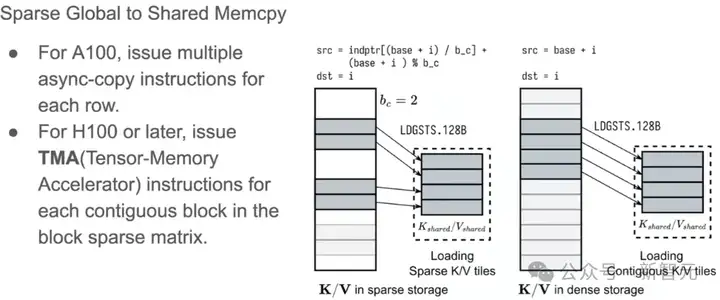
对于稀疏的KV-Cache,地址使用BSR矩阵的indices数组计算;而密集的KV-Cache地址使用row index仿射变换。
KV-Cache的最后一个维度保持连续(也就是head_size),以适应GPU缓存行大小的合并内存访问。这里使用宽度为128B的异步复制指令LDGSTS来最大化内存带宽。
尽管Hopper架构中的TMA(Tensor Memory Accelerator)可以进一步加速数据移动,但它不支持非仿射内存访问模式,所以只在连续的情况下使用TMA。

另外,为了适应不同的计算访存比,FlashInfer提供具有不同块大小的FlashAttention2内核,并根据硬件资源和工作负载强度来选择合适的尺寸。
负载均衡
下图展示了FlashInfer运行时调度程序的工作流程。
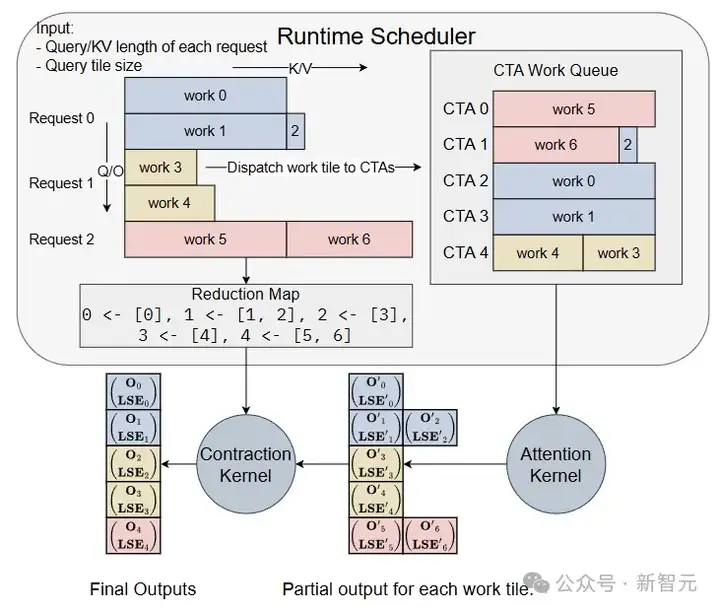
Attention kernel不会直接产生最终输出,因为一些长KV被分成了多个chunk,每个chunk的部分输出存储在用户提供的工作区缓冲区中,最终输出需要所有chunk进行聚合。
FlashInfer实现了高效的注意力合成算子,可以处理变长聚合。每个CTA的工作队列,以及部分输出与最终输出之间的映射,都由调度程序规划。
先由CPU计算规划信息,之后FlashInfer会将计划信息异步复制到GPU工作区缓冲区的特定区域,用作注意力内核的输入。
FlashInfer保证Attention和contraction内核与CUDAGraph兼容。二者都使用持久内核,并且编译后网格大小是固定的,这意味着内核在每个生成步骤中都以相同的网格大小启动。
作者为工作区缓冲区的每个部分设置了固定偏移量,以存储部分输出和计划信息,确保传递给内核的指针对于每个生成步骤都是相同的,满足CUDAGraph的要求。
参考资料:
https://arxiv.org/abs/2501.01005
https://x.com/tqchenml/status/1875123214919328039
文章来自于微信公众号“新智元”,作者“alan”

【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


