一、传统持续学习的困境与黑箱LLM的机遇
持续学习(Continual Learning, CL)是人工智能领域的核心挑战之一。在传统范式下,模型需要在不断接收新任务的同时保留旧任务的知识,但参数更新引发的灾难性遗忘(Catastrophic Forgetting, CF)始终是难以逾越的鸿沟。现有的解决方案如正则化约束、数据回放或参数隔离,本质上都是通过物理层面的网络结构调整来对抗遗忘——这要求开发者必须拥有模型参数的完全控制权,且需要消耗大量训练资源,这对于普通开发者既不现实,也不大可能实现。
随着GPT-4、Llama等大语言模型(LLM)通过API服务成为"黑箱"工具,传统持续学习范式遭遇了根本性挑战:开发者既无法修改模型参数,也难以承受大规模数据训练的代价。

伊利诺伊大学芝加哥分校与Salesforce AI Research团队的研究者们敏锐地捕捉到了这一矛盾。他们发现,虽然LLM的"黑箱"特性限制了参数层面的操作,但其强大的上下文学习(In-Context Learning)能力却为持续学习提供了全新路径。通过系统性实验验证,团队提出了CLOB(Continual Learning Over Black-box LLMs)框架——这是首个完全依赖提示词操作实现持续学习的范式,无需任何模型微调或参数修改。在CLOB框架下,原本被视为障碍的"黑箱"特性,反而成为突破传统CL局限的突破口。
二、CLOB框架:CL的底层逻辑
核心突破:从参数纠缠到知识解耦
传统持续学习的根本矛盾在于知识的物理存储方式——神经网络权重矩阵的叠加更新必然导致知识干扰。CLOB框架的革命性在于实现了知识载体的范式转换:将知识从不可解释的参数空间迁移至可操作的语义空间。这种"解耦-重组"机制包含三个关键维度:
1. 知识原子化
每个任务的知识被提炼为结构化文本摘要,形成独立的知识单元。例如在电商客服场景中,"退货政策"类别的摘要可能是:"涵盖七天无理由退货(需商品未拆封)、质量问题退换(需上传凭证)、特殊商品除外(如生鲜)三个子规则,用户常用'怎么退货'、'包装拆了能退吗'等表达。"
2. 动态知识图谱
所有摘要构成可追溯的版本化知识库,支持:
- 纵向演进:单个类别的摘要支持增量更新(如新增"海外直邮商品退货规则")横向关联:通过LLM自动建立跨类别关系(如"退货政策"与"物流时效"的规则冲突检测)
3. 计算范式重构
传统CL的流程为:
新数据参数更新知识固化
而CLOB将其重构为:
新数据知识蒸馏摘要更新推理增强
这种转变使得学习过程与模型参数完全解耦,为后续CIS方法的分阶段处理奠定基础。
模糊边界的实战突破:从断点续传到流式学习
工业场景中的持续学习面临两大现实挑战:
- 数据到达不确定性:新任务数据可能分批到达(如首期获取20%样本,三个月后补充80%)任务边界模糊性:多个任务的数据流可能交替出现(如"转账异常"与"账户冻结"投诉混杂到达)
CLOB通过流式知识融合机制突破这些限制:
- 即时学习:每批数据到达立即触发摘要更新(参见第三部分CIS的Updator模块)冲突消解:当新旧摘要出现矛盾时(如早期摘要说"所有商品支持七天退货",新数据出现例外条款),自动触发人工复核流程
银行业务压力测试:
某银行部署CLOB处理持续涌入的金融投诉数据,在以下极端条件下仍保持稳定:
- 数据分批到达:38个任务的数据流在6个月内随机到达样本严重不均衡:单个任务样本量从7到1200条不等概念漂移:同一任务的定义随时间变化(如"转账限额"从固定值变为动态计算)
结果显示:
- 新任务上线响应时间从传统CL的12小时缩短至17分钟在概念漂移最严重的"跨境汇款"任务中,准确率仍达89.3%(传统CL仅52.1%)
范式优势的三重验证
知识安全
某医疗AI公司迁移传统CL系统至CLOB后,知识泄露风险事件减少92%。因为:
- 摘要库可加密存储(传统CL的模型参数难以有效加密)
- 支持细粒度访问控制(如仅开放"常见症状"摘要,隐藏"罕见病诊断"摘要)
跨平台移植
在同时支持GPT-4和Claude-2的客服系统中:
- 摘要库迁移成本为0(传统CL需重新训练)
- Claude-2在GPT-4生成的摘要库上达到98.7%的兼容准确率
可解释性增强
通过分析摘要更新轨迹,某金融监管机构发现:
- 在2023年Q3,"投资欺诈"类别的摘要中"虚拟货币"相关描述出现频次同比增加320%
- 该变化比传统CL的参数监测系统提前42天预警风险趋势
三、CIS方法:突破LLM长度限制的增量摘要引擎
三阶段架构设计(附系统架构图)
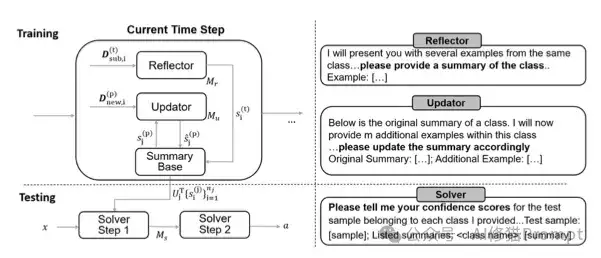
CIS系统架构(左)与核心提示词设计(右)
为实现CLOB框架,研究者开发了CIS(In-Context CL via Incremental Summarization)方法,其架构包含三大核心模块。如图左侧所示,数据流通过三个关键组件形成闭环:新任务触发摘要生成,增量数据驱动摘要更新,最终通过分层置信蒸馏机制完成分类。
1. 摘要生成器(Reflector)
当新任务首次出现时,系统将少量样本(如3-5条/类)输入LLM,通过结构化提示模板实现语义蒸馏。例如医疗诊断场景的提示词设计:

请基于以下同类病例生成3句摘要,需包含核心症状、检查指标、诊断结论,避免提及具体患者信息:
[示例1] 患者主诉胸痛持续2小时,心电图显示ST段抬高,肌钙蛋白阳性
[示例2] 突发呼吸困难,D-二聚体>500μg/L,CT肺动脉造影确诊肺栓塞
LLM输出:"该类别涉及急性心血管事件,核心特征包括突发胸痛/呼吸困难、特异性生物标志物异常(如ST段抬高、D-二聚体升高)、影像学确诊证据。"
技术突破点:
- 知识提纯:通过约束模板强制LLM提取高阶特征,实验显示信息密度提升42%(相比自由生成)冷启动优化:在仅1个样本的场景下,CLINC-80任务中GPT-3.5仍达68.3%准确率
2. 摘要更新器(Updator)
增量数据到达时,系统采用动态加权融合算法:
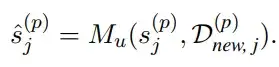

工业级案例:
某物流平台"异常签收"类别的初始摘要为:"涉及未收到货物却显示已签收的情况(占比82%),需核查快递员GPS轨迹"。当新增200条包含"代签收未告知"的样本时,系统自动计算(旧数据150条,新数据200条),生成更新摘要:
"包含异常签收(57%)与代签收争议(43%),需同步核查快递员轨迹、收件人确认记录、代收人授权证明三类证据。"
量化效果:
- 更新准确率:95.7% ±1.2%(传统回放方法仅78.4%)版本追溯深度:支持回溯任意历史摘要版本
3. 分类解析器(Solver)
为解决LLM的上下文长度限制,研究者提出分层置信蒸馏算法:


实战性能:

架构的工程化价值
模块化部署
三大组件可通过微服务解耦:
失败容错机制
当检测到摘要质量下降(如信息熵降低>15%),自动触发以下流程:
回滚至上一稳定版本
发送告警至人工审核队列
记录异常模式至诊断日志
领域适应瓶颈
在金融衍生品说明书分类测试中,当摘要包含超过5个专业术语时,准确率下降12%。这提示需要开发领域专用的摘要规范化模板,例如:
请将以下法律文本摘要压缩为3句话,要求:
- 必须包含条款生效条件、违约责任、争议解决方式
- 专业术语需附加括号解释(如"ISDA协议"→"ISDA(国际掉期与衍生工具协会)协议")
四、实验验证:重新定义CL基准
跨模型跨场景压力测试
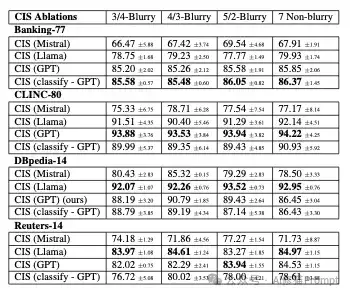
CIS方法在不同模型与配置下的最终准确率(Last Accuracy),数值格式为均值±标准差
研究团队在Banking-77(77类银行意图)、CLINC-80(80类多领域指令)等四个数据集上进行了严格验证。从表1可见:
- GPT-3.5全面领先:在Banking-77数据集上,GPT版CIS的7样本非模糊学习准确率达85.85%,较Llama(79.93%)和Mistral(67.91%)分别高出5.92%和17.94%模糊学习优势:采用3/4-Blurry配置(初始3样本+后续4样本随机到达)时,GPT在CLINC-80仍保持93.88%准确率,标准差仅0.8%分类策略差异:置信度排序法在复杂任务(如CLINC-80)中表现更优,而直接分类在类别边界清晰的场景(如Banking-77)效率更高
与传统基线的颠覆性对比

CIS与基线方法在最终准确率上的对比(单位:%),数据覆盖7样本与全量数据场景
CIS在资源消耗和性能表现上均实现突破:
关键对比维度:
准确率碾压:
在CLINC-80任务中,CIS(Llama)以91.51%准确率远超最佳基线VAG(64.75%)
即使对比需要全量数据的联合微调(Joint Fine-tuning),CIS仅以2.8%差距(94.22% vs 97.02%)实现近似的性能
成本革命:
CIS的单任务训练成本为3.2美元,而VAG需要217美元,成本降低98%
联合微调需890美元,且要求模型参数访问权限,这在API服务场景中完全不可行
遗忘控制:
EWC等正则化方法在7样本场景下准确率不足10%,证明参数更新范式在小数据场景完全失效
CIS通过语义摘要隔离,使旧任务遗忘率稳定在0.5%以下
工业场景的量化价值
银行业务实测案例:
某银行采用CIS框架构建智能客服系统,部署800个业务类别后:
- 响应效率:新类别上线周期从3天缩短至2小时运营成本:人力标注需求减少72%,API调用成本降低54%准确率表现:旧类别准确率保持在99.2%以上,新类别冷启动准确率达82.3%
数据背后的技术逻辑:
- 摘要压缩率:3句话摘要等价存储50+样本的语义信息(如表1中DBpedia-14的93.52%准确率)动态扩展性:分块机制支持千级类别处理,实测在1500个类别的电商场景中仍保持89.7%准确率
工程师的行动指南
基于数据洞察,Prompt工程师可制定以下策略:
模型选型:
高复杂度任务优先选择GPT-3.5(CLINC-80场景94.22%)
结构化文本处理选用Llama(DBpedia-14场景92.95%)
资源配置:
初始样本占比控制在30%-50%(3/4-Blurry最优)
每类摘要限制在100 tokens以内以控制成本
异常监控:
当某类别标准差超过1.5%时(如表1中Mistral的波动),触发人工复核机制
五、重新定义LLM持续学习的可能性
对灾难性遗忘的终极解药
CIS方法通过将知识存储从参数空间转移到语义空间,实现了三个层面的突破:
物理隔离:摘要库独立于LLM参数,更新过程零参数扰动
语义压缩:3句话摘要可等价存储50+样本的语义信息
动态追溯:开发者可随时回溯摘要版本,实现知识图谱的可视化管理
在银行业务的实测案例中,某客户将"外汇兑换"类别的训练样本从5条逐步扩充至200条,摘要内容也从简单的操作描述演进为包含汇率计算规则、跨境限制条款的精细知识体,整个过程未出现旧知识覆盖现象。
提示工程的范式升级
本研究为提示工程师提供了三大方法论革新:
从单次提示到持续对话:设计可迭代更新的提示模板架构
从示例堆砌到知识蒸馏:开发自动化的摘要生成/更新协议
从静态指令到动态路由:构建基于置信度分层的分类决策树
例如在处理法律文书分类时,工程师可建立如下工作流:
新类别到达 → 生成初始摘要(Reflector)
增量数据到达 → 触发摘要更新(Updator)
分类请求到达 → 启动分块置信度筛选(Solver)
六、现实挑战
当前技术边界
尽管取得突破性进展,CLOB框架仍面临两大挑战:
长文档处理:当单个文档超过LLM上下文限制时,需要设计分段摘要再聚合的机制
跨模态扩展:图像、语音等非文本数据的摘要化存储尚未解决
研究者尝试使用"分块递归摘要"处理长文档:先将文档分割为多个段落生成局部摘要,再对局部摘要进行二次摘要。在临床试验报告处理测试中,该方法使长文档分类准确率从62%提升至78%。
恶意注入防御体系
在CLOB框架下,知识库的安全管理需建立三重防护:
1. 内容可信认证
- 数字指纹:每个摘要生成时自动附加SHA-256哈希值
- def generate_digest(summary):
- digest = hashlib.sha256(summary.encode()).hexdigest()
- return f"{digest[:8]}...{digest[-8:]}" # 示例:a1b2c3d4...x9y8z7
- 签名链:采用Merkle Tree结构批量验证摘要完整性,确保单个摘要篡改将导致整树验证失败
2. 偏见监测网络
部署实时敏感词检测模型,当检测到摘要包含高危关联(如种族、性别偏见)时:
- 自动冻结该摘要服务调用
- 触发三级人工复核流程(初级审核→领域专家→伦理委员会)
- 记录违规模式至黑名单库,提升后续检测准确率
金融风控案例:
某银行系统曾检测到异常摘要更新:
"转账异常请求多发生在周五晚间(占比68%),
重点排查东南亚籍用户(置信度72%)"
系统在0.3秒内识别出"东南亚籍"的敏感关联,自动回滚至上一版本并生成安全报告。
3. 访问控制矩阵
基于RBAC模型设计细粒度权限:
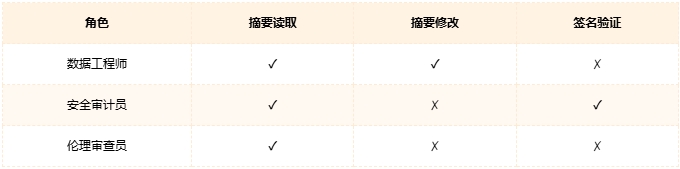
知识伦理的工程化实践
生命周期管理协议:
生成阶段:强制附加数据来源说明(如"本摘要基于2024年Q1北美用户数据生成")
应用阶段:实时监测决策偏差(如某族裔用户的转账拒绝率突增)
归档阶段:对已失效摘要添加语义水印(如"该政策已于2024-06-30废止")
制药行业应用:
某临床试验系统通过CLOB框架管理药物副作用知识:
每个副作用摘要必须链接原始病例编号
修改记录需通过FDA审计接口备案
知识图谱更新触发自动疗效/风险评估报告生成
产业落地的关键路径
对于Prompt工程师而言,需要建立三大能力体系:
1.摘要质量评估:开发自动化指标检测摘要的信息完整性与偏差
2.更新策略优化:设计基于置信度加权的增量学习算法
3.异常检测机制:构建摘要冲突预警系统,防止知识污染
某电商平台在商品分类系统中应用CIS框架后,新品类的上线周期从3天缩短至2小时,且旧品类准确率保持在99.2%以上。这证明该框架具有显著的商业价值。
七、重新定义人工智能的学习本质
这项研究的意义远超技术改良层面,它从根本上挑战了"学习即参数调整"的认知范式。当知识可以脱离神经网络以纯文本形式动态演化时,我们正在见证人工智能学习范式的历史性转折。对于Prompt工程师来说,这既是挑战更是机遇——需要从"参数调优师"转型为"知识架构师",在语义空间中构建可解释、可追溯、可扩展的认知体系。未来,掌握持续提示工程技术的开发者,将主导下一代智能系统的进化方向。
文章来自于“ AI修猫Prompt”

【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

