瞄准推理时扩展(Inference-time scaling),DeepMind新的进化搜索策略火了!
所提出的“Mind Evolution”(思维进化),能够优化大语言模型(LLMs)在规划和推理中的响应。
由于提升显著,Reddit/𝕏一时间出现了大量讨论:
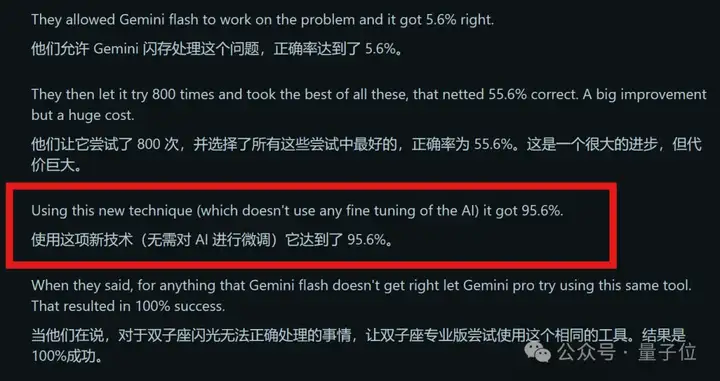
由于结合了遗传算法,使用Mind Evolution能让Gemini 1.5 Flash任务成功率从原本的5%左右,一下提升90个百分点。
而且成本方面,和最接近这一性能的传统方法Sequential-Revision+相比,所使用的tokens数量仅为后者的几分之一。

响应更好,成本还降低了,还是无需微调的结果。
这令人熟悉的配方又直接“迷倒”了一大片网友:
与此同时,Mind Evolution还有一大优势也令人津津乐道:
它可以直接处理自然语言问题,而无需像传统一样需要将任务问题进一步形式化(即将实际问题转化为精确的、可被算法处理的数学或逻辑形式)。
也就是说,仅需一个最终检查解决方案是否正确的评估器,任务形式化也不需要了。
将问题形式化,需要大量领域专业知识和对问题的透彻理解,才能找出所有需用符号表示的关键元素及其关系,这大大限制了Inference-time scaling的适用范围。

总之按网友形容,这项研究就像给大语言模型升级大脑而不刷爆信用卡,酷酷酷!!
下面来看具体是如何做到的。
结合了进化搜索原理和LLMs的自然语言能力
首先,OpenAI的o1系列模型率先引入了推理时扩展(inference-time scaling)的概念,通过增加思维链(Chain-of-Thought)推理过程的长度,在数学、编程、科学推理等任务上取得了显著的性能提升。
换句话说,通过让模型思考更多、更深,其响应也会越来越好。
而为了更多利用推理时扩展,先前研究还提出了自一致性(self-consistency)、基于反馈的顺序修正(如Sequential-Revision +),以及由辅助验证器或评估器引导的搜索(如Best-of-N)。
基于同样目的,DeepMind提出了Mind Evolution这一针对LLMs的新进化搜索策略。
结合了进化搜索原理与LLMs的自然语言能力,既允许对可能的解决方案进行广泛探索,也允许对有希望的候选方案进行深入细化。

具体而言,Mind Evolution依赖于两个关键组件:搜索算法和遗传算法。
搜索算法比较常见,一般用来让LLMs找到最佳推理路径以获得最优解;而遗传算法结合大语言模型,在自然语言处理任务中,通过迭代优化候选解决方案,以更好地满足任务目标。
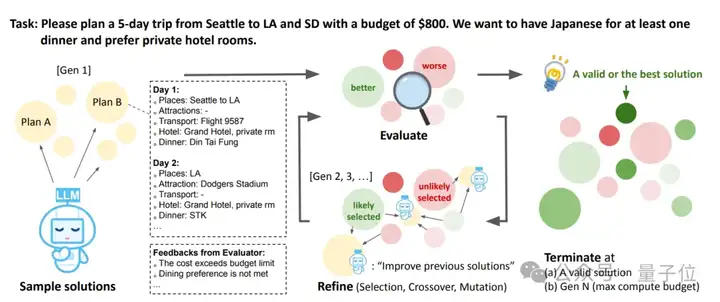
举个例子,假如面临上图中的任务:
请计划从西雅图到洛杉矶和南达科他州的5天旅行,预算为800美元。我们希望至少有一顿晚餐吃日本料理,并且偏好入住私人酒店客房。
Mind Evolution整体处理流程如下(类似遗传算法):
- 样本解决方案生成(Sample solutions):使用LLMs生成多个初始旅行计划;评估(Evaluate):对生成的解决方案给出反馈,指出问题,如成本超出预算限制、用餐偏好未满足等;改进(Refine,包括选择、交叉、变异):根据评估反馈,对解决方案进行改进;终止条件(Terminate):当满足以下条件之一时终止,如找到有效或最佳解决方案,或达到最大计算预算(Gen N)。
这里尤其需要提到改进过程,其中选择是指依据评估反馈,选择更有可能改进的解决方案;交叉指将不同解决方案的部分内容进行组合,实现类似生物基因重组的效果,生成新的候选解决方案;变异是指对解决方案进行随机调整,增加种群多样性,以探索更多可能的解决方案。
最终,评估、选择和重组的循环将持续进行,直到算法达到最优解或耗尽预设的迭代次数。

另外值得一提的是,Mind Evolution具体是通过“The fitness function”(适应度函数)来消除任务形式化问题。
简单说,适应度函数适配自然语言规划任务,解决方案以自然语言呈现。
如此一来,在有程序性解决方案评估器时,系统可规避问题形式化,并且除给出数值评分外,还能提供文本反馈,帮助LLMs理解具体问题并开展针对性优化。
此外,Mind Evolution还采用“island”(岛屿)方法来确保多样化探索。
在每一个阶段,算法都会创建各自独立进化的解决方案组。然后,它将最优解从一组“迁移”到另一组,以结合并创造新的解决方案。
那么,Mind Evolution实际表现如何呢?
规划表现均优于其他基线方法
实验阶段,研究人员将它和其他基线进行了对比。
- 1-pass:使用o1-preview,模型只生成一个答案;Best-of-N,模型生成多个答案并选择最佳答案;Sequential Revisions+:模型独立提出10个候选解决方案,然后分别对80次迭代进行修订。
可以看出,尽管缺少遗传算法组件,Sequential Revisions+在旅行规划上的成功率最为接近Mind Evolution。
不过随着从左至右任务复杂性的增加,Mind Evolution与其他方法之间的差距越来越大,优势愈发凸显。
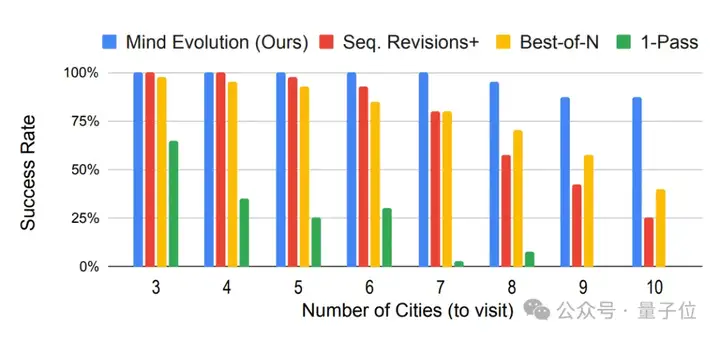
整体来看,在所有测试中,Mind Evolution的表现都远远超过了基线,尤其是在任务变得更加困难时。
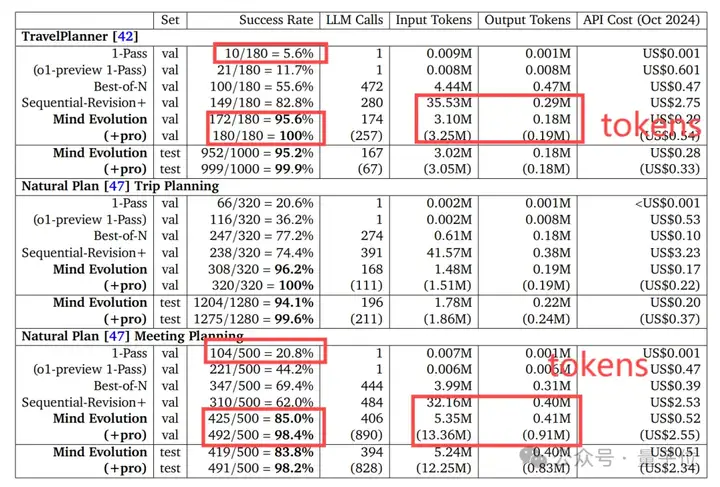
在TravelPlanner(评估旅行规划)和Natural Plan(评估会议规划)这两项基准测试中,未采用Mind Evolution的Gemini 1.5 Flash任务成功率分别为5.6%和20.8%,而采用Mind Evolution之后,其任务成功率分别提升至95.6%和85.0%。
而且,如果继续将Gemini 1.5 Flash未解决的问题丢给1.5Pro,其成功率更是上升至100%和98.4%。
另外成本方面,和最接近上述性能的传统方法Sequential-Revision+相比,所使用的tokens数量仅为后者的几分之一。
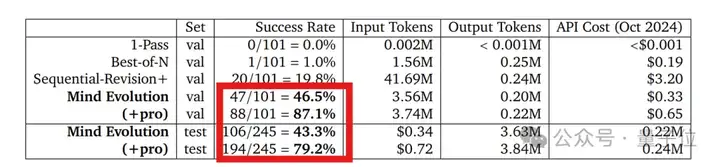
除此之外,研究人员引入了一项新测试任务——StegPoet。
需要在创意写作中嵌入隐写信息,属于自然语言规划任务范畴。
简单说,它要求在创作富有创意的文本内容时,还要将特定的信息以隐写的方式巧妙融入其中,这既需要逻辑推理能力,也对LLMs在创造性表达方面的能力提出了更高要求。

而从相关实验来看,Mind Evolution也经受住了这一复杂任务的考验。
总体来说,这项研究通过将广泛搜索(随机探索)与深度搜索(利用LLM进行解决方案细化)相结合,进一步提升了模型在规划和推理上的响应。
更多细节欢迎查阅原论文。
论文:
https://arxiv.org/abs/2501.09891
参考链接:
[1]https://venturebeat.com/ai/deepmind-new-inference-time-scaling-technique-improves-planning-accuracy-in-llms/
[2]https://www.reddit.com/r/singularity/comments/1i5o6uo/google_deepmind_evolving_deeper_llm_thinking/
[3]https://x.com/_akhaliq/status/1881182840857178146
文章来自于微信公众号“量子位”,作者“一水”

【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

