随着大模型(LLMs)的发展,AI 写作取得了较大进展。然而,现有的方法大多依赖检索知识增强生成(RAG)和角色扮演等技术,其在信息的深度挖掘方面仍存在不足,较难突破已有知识边界,导致生成的内容缺乏深度和原创性。
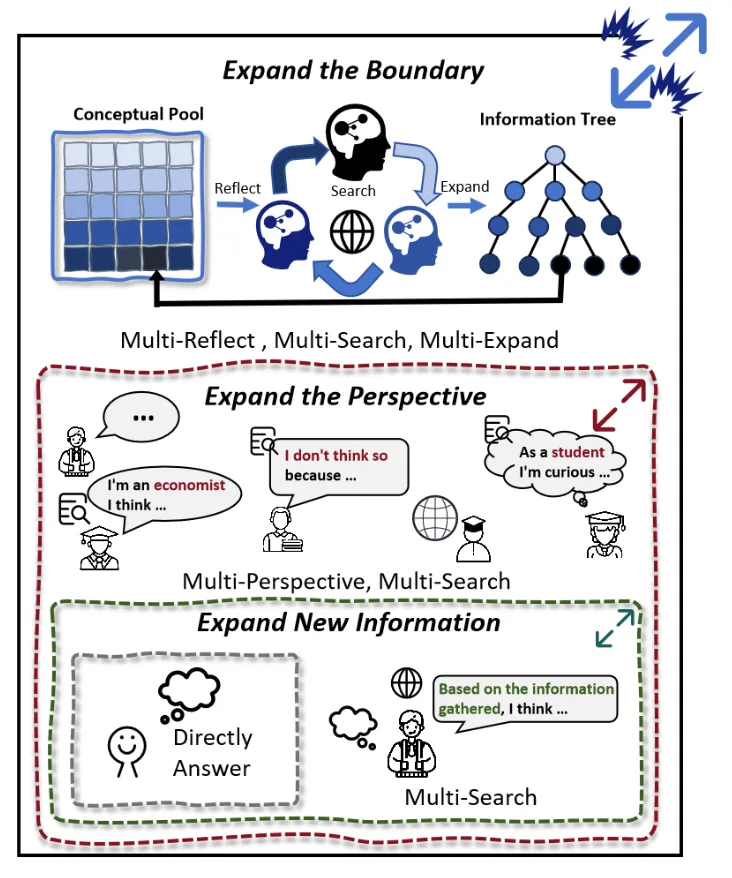
针对上述问题,浙大通义联手提出慢思考长文本生成框架 OmniThink,通过模拟人类写作中反思与扩展这一过程来突破知识的边界,基于知识增强使生成的文章更加深入、丰富和原创,该框架可应用于综述写作、新闻报道、报告生成等场景。

- 论文题目:OmniThink: Expanding Knowledge Boundaries in Machine Writing through Thinking
- 论文链接:https://arxiv.org/abs/2501.09751
- 在线Demo: https://modelscope.cn/studios/iic/OmniThink
背景与挑战

- 文章内容重复:如图所示,基于 RAG(GPT-4o)的框架主要依赖固定的检索策略,检索得到的内容信息单一,生成文章时可利用的信息有限,进而导致文章存在内容重复问题。
- 缺乏深度和创新:角色扮演的方法尝试从多个角度扩展信息空间,但依然存在深度不足和知识边界无法突破的缺陷,生成的内容往往较为浅显而缺乏新意。
OmniThink 概览
OmniThink 通过引入反思与扩展机制,在传统知识检索增强的基础上,增加了动态反思和扩展反馈的步骤。通过对先前信息的反思,OmniThink 能够识别哪些内容值得进一步扩展,哪些信息应当被重新整理或过滤。该机制有效地避免了信息的片段化,使得生成的文章能够实现知识的更深层次整合,进而提高文章的知识密度和创新性。
总体工作流程
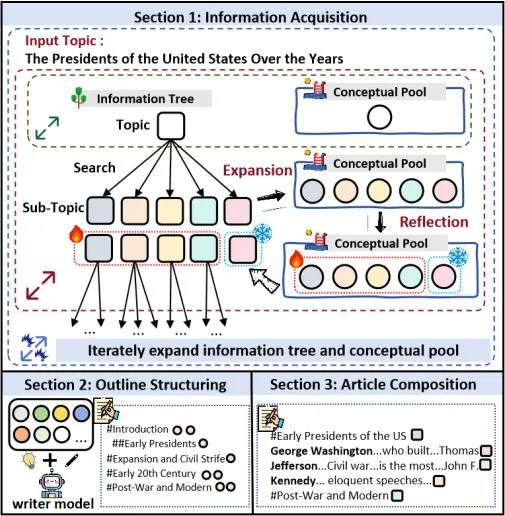
如图所示,OmniThink 的工作流程可以分为三大部分:信息获取、文章大纲构建和文章创作。通过这三大步骤,OmniThink 能够系统地获取信息,组织知识,并最终生成结构化、信息丰富的文章。
- 信息获取:通过动态的扩展和反思机制,OmniThink 逐步深化对主题的理解,形成包含层次信息和核心见解的「信息树」与「概念池」。
- 大纲构建:根据前一步获取的深入信息,OmniThink 会生成清晰、有逻辑性的大纲,确保文章内容的系统性与层次性。
- 文章创作:在大纲指导下,OmniThink 将信息整合并生成各个部分内容,最终通过多轮修正和去冗余过程,输出一篇内容完整、信息密集的长文。
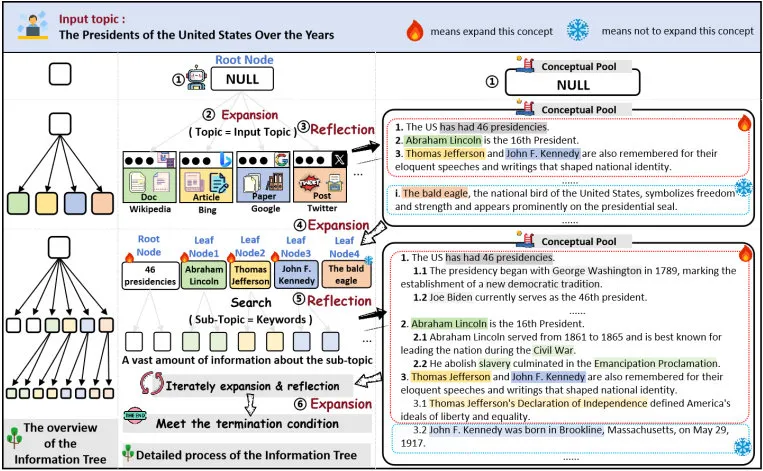
信息获取:扩展与反思
OmniThink 的关键步骤是信息获取,它通过模拟人类学习知识的过程,逐步加深对某一主题的理解。这个过程由两部分组成:扩展和反思。
- 扩展:在每一个迭代阶段,OmniThink 会对主题进行信息扩展。系统首先从搜索引擎(如 Google、Bing 或自定义知识库)获取相关信息,并构建初步的「信息树」。每一个信息节点都代表了一个子话题或相关领域的知识,系统会通过多轮检索,针对每个节点进一步拓展,确保知识的深度与全面性。
- 反思:扩展信息后,OmniThink 会对已获取的内容进行反思和过滤,提炼出核心见解。这些见解将不断更新到概念池中,形成对话题的动态理解。通过这样的反思过程,OmniThink 能够不断提升其信息的精度和深度,为文章创作打下坚实基础。
大纲构建:引导文章结构
构建文章大纲是生成高质量文章的关键一步。一个好的大纲不仅能明确文章的主题和结构,还能确保各个部分之间的逻辑关联性。
在 OmniThink 中,研究者首先通过初步的草稿大纲来对文章的框架进行初步构思。接着,OmniThink 结合从概念池中提取的核心信息,优化并精炼这个大纲,形成最终的结构化大纲。这种基于概念池的生成方法,能够确保大纲全面涵盖主题的关键点,并且逻辑严谨,层次分明。
文章创作:生成高质量内容
一旦大纲完成,OmniThink 进入文章创作阶段。此时,系统会根据大纲中每个部分的标题和子标题,计算与信息树中相关节点的语义相似度,获取最相关的文献和数据。这些信息被用于生成文章的各个部分。
- 并行生成:每一部分的内容在并行处理下进行生成。OmniThink 会依据已有的检索信息和大纲要求生成每个部分的内容,并确保在生成过程中对引用信息进行标注。
- 去冗余与修正:由于各个部分内容是并行生成的,因此初始文章会存在一定的冗余或信息不一致。OmniThink 会在最后的阶段对文章进行整合,去除重复内容,修正逻辑关系,最终生成一篇结构清晰、内容完整的高质量文章。
实验结果
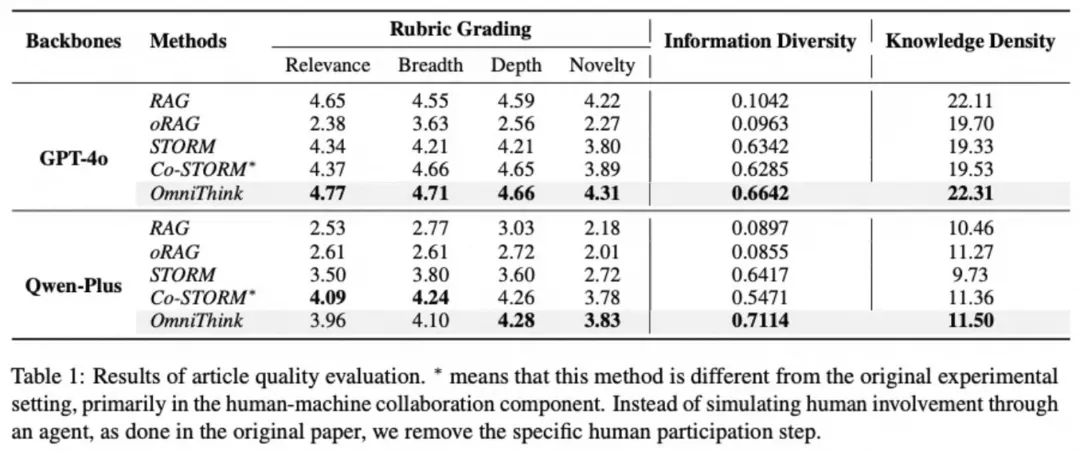
在本文的实验中,研究者使用了 WildSeek 数据集来评估 OmniThink 的生成能力,并与现有的几个基准方法(如 RAG、oRAG、STORM 和 Co-STORM)进行了对比。通过这次实验,研究者全面评估了 OmniThink 在自动评价和人工评价方面的表现,以下是所得的关键实验结果。
自动评估结果
研究者首先使用 Prometheus2 自动评价工具对生成的文章进行了打分,评价维度包括:相关性、广度、深度和新颖性。同时,研究者还加入了信息多样性和知识密度两个指标来衡量文章内容的丰富性和深度。
从表格中可以看到,OmniThink 在所有维度中均表现优秀,尤其在新颖性上表现尤为突出。与传统的生成方法相比,OmniThink 的强大反思能力使其能够从已有的知识中挖掘出新的视角和创见,从而在生成内容时展现出较高的创新性。
另外,OmniThink 在知识密度上也表现得尤为出色,这得益于其动态信息检索策略,能够通过持续不断地获取多样化的信息,进而提升文章内容的深度和精确度。
大纲生成质量分析
文章大纲作为内容生成的基础,其质量直接影响最终文章的结构性、逻辑性和表达清晰度。在实验中,研究者通过评估大纲的结构性、逻辑一致性和对内容生成的指导性,进一步分析了 OmniThink 在大纲生成方面的表现。
结果显示,OmniThink 在大纲的结构性和逻辑一致性方面优于其他基准方法,特别是在如何为内容创作提供有效的生成指导方面,表现出了较为明显的优势。这一优势归功于 OmniThink 独特的概念池设计,它帮助模型更全面地理解目标话题,从而使得生成的大纲更加清晰和一致。
不过,研究者也发现,尽管在结构性和逻辑一致性上有所提升,但在逻辑一致性方面,OmniThink 的改进仍然有限,未来可以进一步优化这一环节。
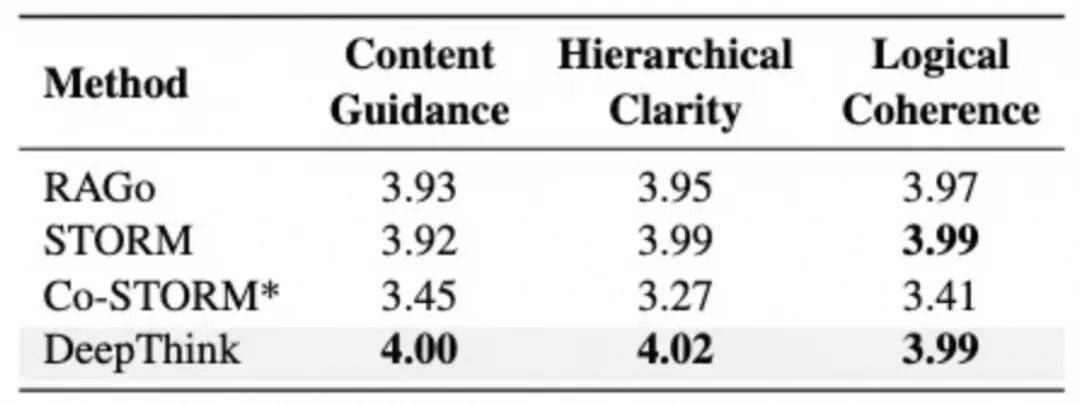
消融实验:动态扩展与反思的作用
为了进一步验证 OmniThink 中动态扩展与反思机制的有效性,研究者进行了消融实验,去掉了 OmniThink 的扩展和反思观察各项指标的变化。
实验结果表明,去除这一机制后,模型在信息多样性和新颖性等关键指标上下降。这表明,动态扩展与反思机制在提升文章质量,特别是在增加信息多样性和创新性方面,起到了至关重要的作用。

扩展与反思的深入分析
由于在扩展与反思的环节中,两者是相互依赖关系,无法完全剥离其中一个,研究者设计了一个巧妙的分析实验:分别将负责反思和拓展的模型换成能力更弱的小模型。观察各项指标的下降程度,作为其对各项指标的贡献程度。
反思机制被证明是提高文章新颖性和信息多样性的重要因素。反思不仅可以帮助模型重新评估和整合现有的知识,还能通过深度的自我反省激发出更多创新的观点和想法。研究者认为,反思机制是推动 OmniThink 创新性提升的关键因素。
扩展机制则在知识的深度和信息的相关性上起到了更为显著的作用。通过扩展,OmniThink 可以接触到更广泛的知识领域,增加信息的深度,从而提升生成文章的质量和知识密度。
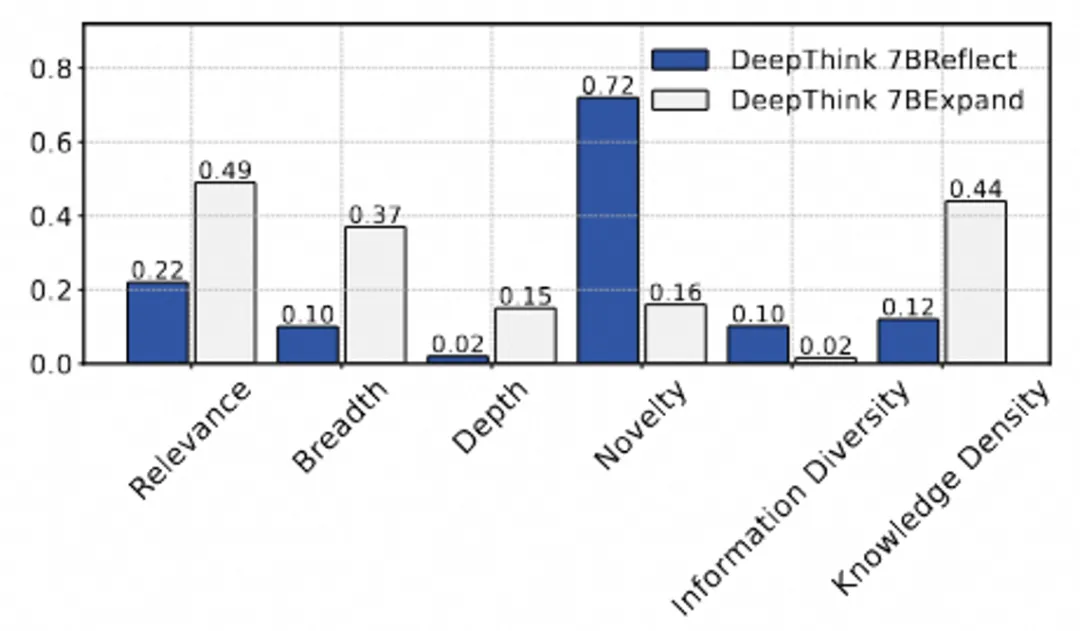
思维深度分析:信息量与生成质量的关系
随着检索信息量的增加,文章的知识密度和信息多样性都有提升。研究者发现,当检索深度从 1 级提升到 3 时,生成的文章质量迅速提高。但当深度达到 4 时,增长速度放缓。
这表明,在长篇文章生成中,适当增加检索深度可以有效提升文章的多样性和知识密度,但过多的信息也可能导致效果递减。因此,如何平衡信息深度和生成质量,仍然是未来研究的一个重要方向。
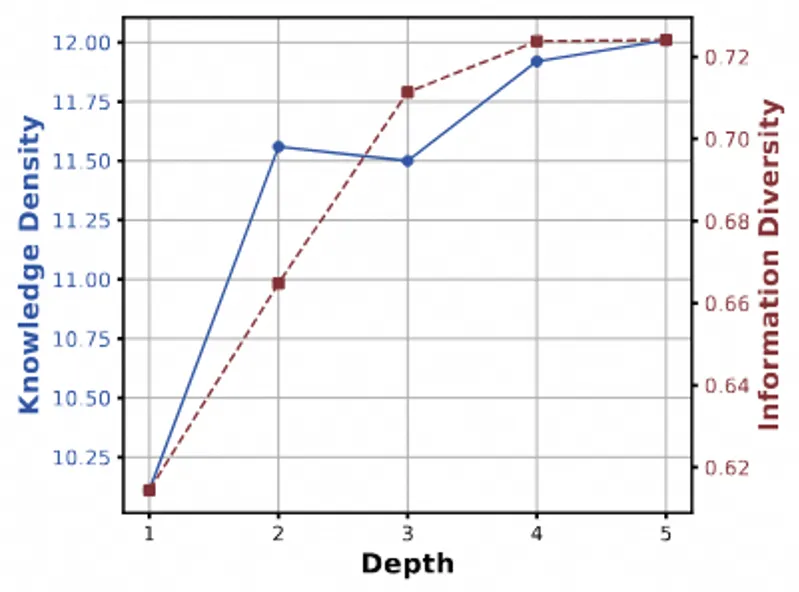
人工评估结果:OmniThink 的实际优势
为了更全面地评估 OmniThink 的性能,研究者邀请了 15 位具有良好教育背景的志愿者进行了人工评估。通过人工评分,结果显示 OmniThink 在多个维度上的表现都优于当前最强基线 Co-STORM,特别是在 广度 维度上,OmniThink 的评分提升了 11%。
尽管在新颖性上,自动评估显示了较为明显的提升,但人工评估却仅显示了轻微的优势。这一差异揭示了目前自动评估与人工评估之间存在的差距,未来的评估体系需要更加精细化,才能更好地对长篇文章的生成质量进行评估。
尽管 OmniThink 在大多数维度上表现出色,仍有约 30% 的文章在人工评估中与 Co-STORM 相当,这可能是因为大型模型的基础写作能力已经达到较高水平,使得人工评估更难察觉细微差别。因此,如何在未来的研究中开发更细致的评估标准,成为了提升生成质量评估的关键。
实验结果表明,OmniThink 提高了生成文章的知识密度,并且在保持文章一致性和深度的基础上,增强了信息的多样性与深入性。尤其在长篇文章生成中,OmniThink 能够提供更具洞察力、更加全面的内容,从而解决了传统方法生成浅薄、重复的文章的问题。
在人类评估和专家反馈中,OmniThink 展现出了相对较高的潜力,特别是在应对复杂、开放领域文章的生成任务时,其信息整合和反思调整的能力优于现有技术。
应用场景
- 综述写作:OmniThink 能够帮助学术研究人员在撰写综述时,快速收集并整合相关领域的知识,生成更具深度的文献综述或理论分析,避免内容的表面化与重复性。
- 新闻报道:在新闻报道领域,OmniThink 能够处理多角度的信息源,生成多层次、有深度的报道文章,尤其在处理复杂社会事件时,能够提供更丰富的背景信息与分析视角。
- 报告生成:OmniThink 框架可通过检索相关知识库和自我反思,生成具有深入分析和洞察力的报告内容。
总结
OmniThink 的优势:
- 知识密度的提升:通过反思与扩展机制,OmniThink 可以提高生成文章的知识密度,避免了内容的重复和表面化。
- 多样性与深度并存:与现有技术相比,OmniThink 能够在保持文章深度的同时,增加信息的多样性和多维度的探索。
- 更高的原创性:通过动态调整信息检索策略和反思机制,OmniThink 能够生成更加原创且具有新颖视角的文章。
存在的局限:
- 计算资源需求较高:由于需要进行多轮反思与扩展,OmniThink 的计算资源需求较高,可能会影响其在实时应用中的效果。
- 信息筛选的挑战:在信息收集和筛选阶段,如何有效识别有价值的信息并避免冗余,仍然是一个待解决的问题。
总的来说,OmniThink 提供了一种基于慢思维的长文本生成新框架,为未来更高效、更智能的知识增强长文本生成方法提供了实践参考。
文章来自微信公众号 “ 机器之心 ”

【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/

