用AI过一个赛博新年。
自从有了 AI,过个年都相当「有戏」。
再有三天,就要进入蛇年了。
各家 AI 厂商都憋足了劲儿想搞波大的,AI 全家福、AI 写春联、AI 贺岁短片统统整上,甚至还有跟亲戚激情对线的 AI「嘴替」。
百度这次也没闲着,推出了「AI 拜年」活动,只需一张照片和一句 prompt,人人都可免费定制拜年贺卡。
比如,让「硅谷钢铁侠」马斯克给特斯拉贴福字:

奥特曼在春晚舞台上撒红包:

或者让「皮衣刀客」黄仁勋身穿喜庆的衣服点鞭炮:

再来句祝福语,一张年味十足的春节贺卡齐活。

外行看热闹,内行看门道。百度这一拜年神器的背后,离不开其自研的 iRAG(image-based RAG)技术。
凭借百度搜索的亿级图片资源和强大的基础模型能力,它可以生成各种超真实的图片,整体效果远远超过文生图原生系统,不仅去掉了 AI 味儿,而且成本很低。
先来看看我们的一手实测成果。
蛇年春节,你可以 AI 拜年
对于当代年轻人来说,春节拜年简直就是大型社死现场。
不仅要接受七大姑八大姨的「灵魂拷问」,还要绞尽脑汁找话题和不熟的亲戚「尬聊」。
即使是发个拜年短信也得反复编辑,要是太普通,总觉得没啥诚意,发出去怕被淹没在信息洪流里。要是太花哨,又显得不真诚,让人觉得在故意堆砌辞藻。要是用网络热梗,还担心长辈们看不懂,或者一不小心闹出误会……
总之,这个年,一拜一个不吱声。
而百度搜索的「AI 拜年」正好可以让年轻人远离这些尴尬。
玩法也很简单。直接在百度搜索「祝福语」,点击「做贺卡」进行文案调整,然后在「创意照片」中上传一张单人正脸图片,再输入 Prompt,就能生成一张独一无二的新年祝福贺卡。
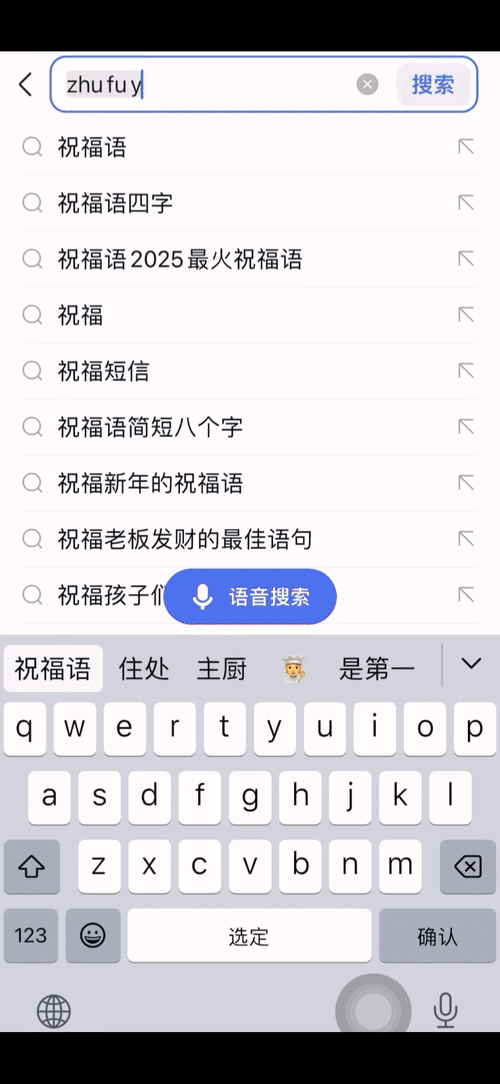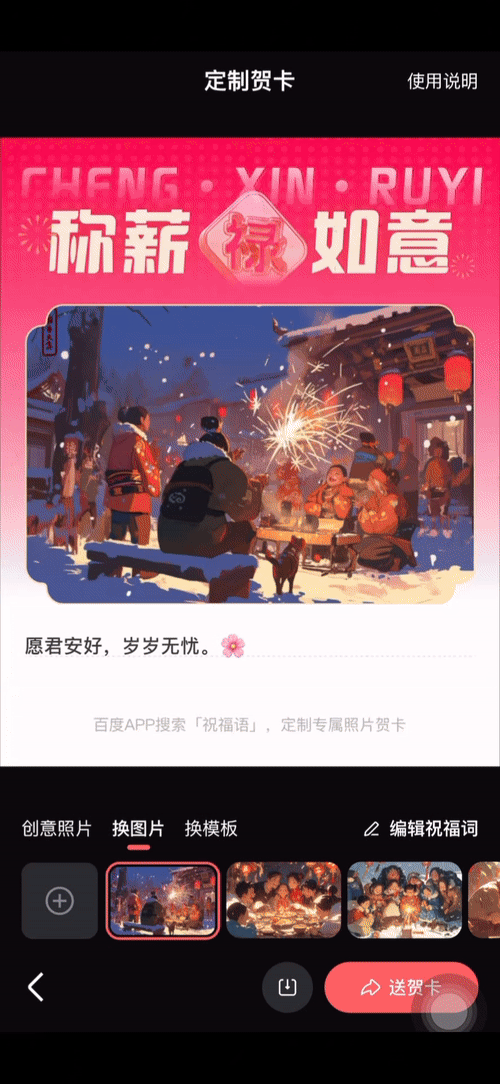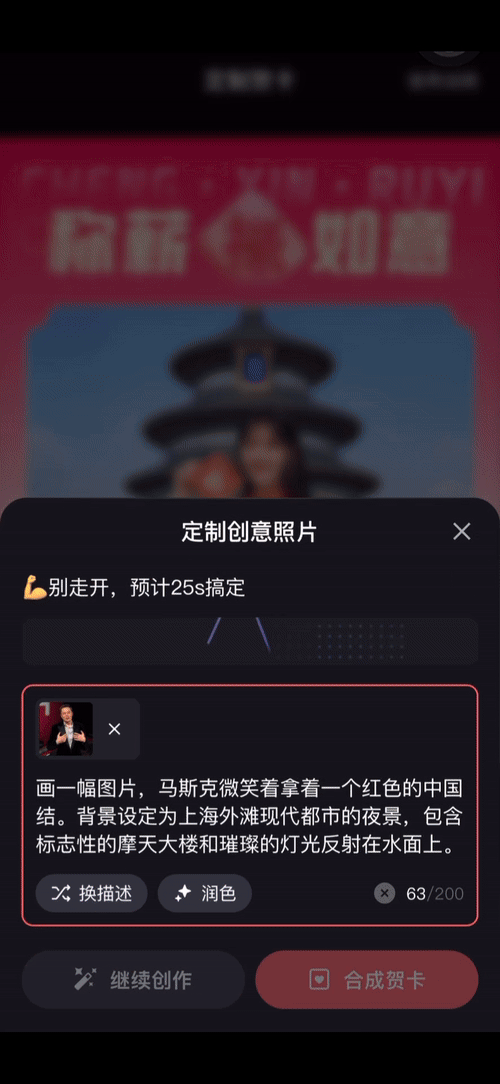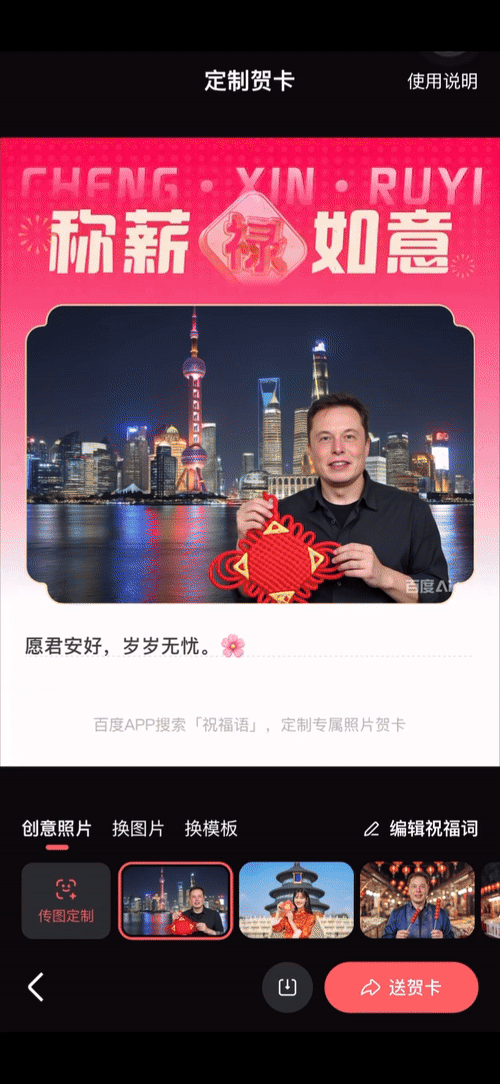
比如我们让名人来充当拜年大使,玛丽莲·梦露、马斯克甚至是甄嬛…… 只要将参考图提供给 iRAG 加持的百度文生图大模型,再用文本描述一下自己的创意,就能获得专属的拜年图片。

(左为原图,右为生成图。Prompt: 生成一张玛丽莲・梦露包饺子的图)

(左为原图,右为生成图。Prompt: 生成一张甄嬛打灯笼的图片)

(左为原图,右为生成图。Prompt: 生成一张马斯克穿着年画娃娃的衣服拱手作揖拜年的图片。)
可以看到,生成的图片非常精准地保留了人物的身份特征,同时也严格地遵循了用户的文本指令。在保证了超高质量的同时,生成的场景与物体也没有出现很多文生图模型常见的幻觉现象。
如果你更愿意自己出镜,但又是 P 图苦手,也完全可以交给「AI 拜年」代劳 —— 只需一张你自己的照片和一句话,就能生成或庄重、或活泼、或妙趣、或古灵精怪的拜年图。

此外,你还可以让参考图片中的人物出现在任何你想象的场景中或去做任何你想象的事情。
比如让奥黛丽・赫本穿着东北大花袄写春联,甚至还能用它给小李子合成相亲照片。

(左为原图,右为生成图。)
在测试过程中,我们还注意到,百度 iRAG 驱动的文生图模型不仅具有非常强大的抗幻觉能力,而且还在汉语对齐方面下足了功夫。
我们知道,在文生图时,使用成语的结果往往难以预料,因为很多文生图模型在面对成语时往往会直接取用其字面含义,从而生成严重偏离期望的结果。
举个例子,如果我们的提示词是「帮我画一个虎头虎脑的大胖小子」,那么文生图模型可能会画出一个真正老虎头的人物来。

不过,如今的百度凭借自身在中国文化上的积淀,能在很大程度上避免这种语义理解上的错误。

(Prompt:生成一张虎头虎脑的大胖小子的图片。)
再比如车水马龙、青梅竹马这类成语,甚至是唐伯虎点秋香,百度文生图模型统统搞得定。

曾经中国美食也让文生图模型们频频「翻车」。驴肉火烧成了驴肉汉堡、啤酒鸭成了「泡」在啤酒里的烤鸭。

而基于 iRAG 驱动的百度文生图模型目前也已攻克这一难题。

(左为原图,右为生成图。Prompt:生成画一张贝多芬吃虎皮蛋糕的图片。)
基于图像的 RAG 究竟如何炼成?
既然这个有趣应用的背后是百度自研的一种名为 iRAG 的技术,那么到底啥是 iRAG?
所谓 iRAG,就是检索增强的文生图技术,要想把它搞明白,我们就得先理解什么是 RAG。
什么是 RAG?
RAG(检索增强生成)的概念其实并不复杂。简单来说,就是让大模型在执行生成之前参考或引用某些数据,而这些数据通常并不在该大模型的训练数据集内,属于专有或私有数据。
利用这些数据,RAG 可以提升响应的相关性,从而无需重新训练模型就能提升大模型的输出。RAG 尤其显著的一大优势是可以降低大模型的「幻觉」问题 ——RAG 可通过引用外部知识有效减少生成内容出现事实性错误的问题。正是因为这些优势,RAG 已经在聊天机器人等 LLM 应用中得到了广泛应用。
RAG 技术近年来发展迅速,并且可以明显分成几个阶段。首先,RAG 诞生时,恰逢 Transformer 架构兴起,其作用主要是通过预训练模型来整合额外知识,从而增强语言模型。
后来,ChatGPT 横空出世,LLM 表现出了非常强大的上下文学习(ICL)能力。RAG 的研究方向也转向了为 LLM 提供更好的信息,从而使其可以在推理阶段回答更加复杂、需要更多知识的问题。这也是 RAG 高速发展的时代。
之后,随着研究进步,RAG 也不再限于推理阶段了,还开始与 LLM 微调技术结合在一起。
现在,RAG 这个研究方向可以说是百花齐放,但其核心流程基本可以归结为三个阶段:索引(Indexing)、检索(Retrieval)、生成(Generation)。下图就展示了一个典型的 RAG 应用。
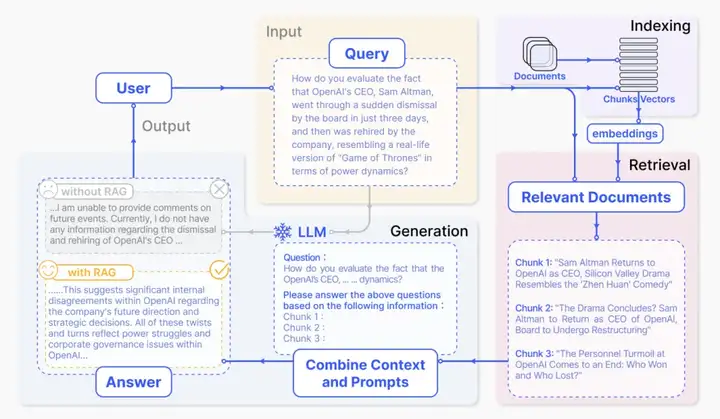
一个应用于问答任务的 RAG 典型实例,图源:arXiv:2312.10997
在这个示例中,用户先向大模型提出一个涉及当时最新新闻的问题,而这个新闻自然不可能出现在该大模型之前的预训练数据中。于是,RAG 就可以填补上这个空白 —— 收集与该用户查询相关的新闻文章,再将这些文章与原始问题一起组合成一个全面的提示词提供给大模型;这样一来,大模型便可以基于丰富的信息生成答案了。
当然,现如今的 RAG 技术要远远更加多样化,还会采用很多高级技术及模块化方法。百度的 iRAG 便是一种进阶版的 RAG 技术,是 RAG 向多模态的泛化与拓展。
iRAG = 图像 + RAG
在此之前,RAG 采用的外部知识库通常是文本数据或表格等结构化数据,而百度成功将这一技术思路应用在了图像数据上,并成功自主研发了 iRAG(检索增强的文生图技术 / Image-Based Retrieval-Augmented Generation)。该技术可解决文生图系统生成结果真实感低以及幻觉问题。
很多文生图系统都存在「一眼 AI」的问题,简而言之就是太假了,之前一个非常著名的例子是「威尔・史密斯吃意大利面」。

早期的文生图系统既不能很好地还原人像,也无法很好地处理事物之间的互动。
此外,与大型语言模型一样,文生图大模型同样也存在幻觉问题,也就是说这些模型可能会过度脑补,生成虽有真实感但却不符合实际情况的图像。百度创始人兼 CEO 李彦宏曾在百度世界大会 2024 上举了一个例子,一些文生图模型在生成「天坛」的图像时会忽视现实情况,自行将天坛加高一层。这就是文生图模型普遍存在的典型幻觉现象,并会在很大程度上限制多模态大模型的规模化应用。

图源:百度世界大会 2024
iRAG 基于百度搜索的亿级图片资源跟强大的基础模型能力(文心大模型),解决了文生图系统的两大核心难点:真实感不足和幻觉。
通过检索百度搜索的大规模图像数据库,iRAG 可通过参考和引用真实的图像元素为文生图的真实感和事实性保驾护航。当然,需要指出,iRAG 并不会直接引用数据库中的图像元素,而是会基于检索到的图像进行符合文本提示词要求的重绘。比如说,如果图像数据库中仅有一张天坛的正面照片,而用户想要生成一张天坛的航拍图,iRAG 就会在生成这张航拍图时以数据库中的正面照片为参考,保证变换视角后的生成图片不会偏离天坛的真实样貌。
不仅如此,百度还成功压低了 iRAG 的计算成本,能以非常快的速度、近乎零成本地为用户提供服务。百度自己给出的总结是:「无幻觉、超真实、没成本、立等可取」。
据了解,百度是在 2024 年初开始研究解决文生图模型的幻觉问题,推进 iRAG 的相关研究,当时 OpenAI 刚公开展示了 Sora 生成的多个高清视频,引起了无限遐想和讨论。几个月后,在 Sora 依然还在内测时,百度开始公开展示自己的研究成果 —— 基于 iRAG 的文生图系统已经能生成照片级真实感的图像!
在百度世界大会 2024 上,李彦宏展示了爱因斯坦漫游世界的例子,让这位无人不知的天才物理学家成功打卡长城、鸟巢等众多地标。之后他更是自信地表示:「在全球范围内,百度的 iRAG 能力是最领先的。」

百度 iRAG 能生成照片级真实感的图像
现在,时间又已经过去了两个多月,百度 iRAG 的能力又得到了进一步精进,不仅基础大模型更强了,而且百度还为之开拓了更多应用场景。通过百度搜索 APP,百度也拉低了使用 AI 的门槛,让任何人都能使用前沿的 AI 文生图一展自己的想象力,做出奇妙、好玩又有用的视觉内容。
并且,你不仅能用 iRAG 制作新年贺卡或名人乱入图,也能将其作为制作产品宣传图的生产力工具。举个例子,以前为了拍摄产品宣传图,你可能会聘请专业的拍摄团队,有时候还需要聘请产品模特 —— 有些汽车宣传海报的制作成本可能会达到数十万,但现在有了 iRAG,你只需要将自己的产品图提供给大模型作为检索数据源,然后用文本描述你想要的场景,百度 iRAG 加持的 AI 就能为你直接生成心仪的产品宣传图。
此外,凭借卓越的参考引用能力,百度 iRAG 还非常适合一些需要保持身份一致性的文生图应用,比如制作连续的漫画或画本、运营虚拟偶像、影视作品概念设计、开发品牌 IP 形象……
蕴藏无限可能,iRAG 吹响智能体之年序曲
前段时间,有不少 AI 从业者都对 2025 年做出了一个类似的判断:这一年会是「智能体之年」,也会是 AI 应用大爆发的一年。

很多 AI 从业者都认为 2025 年是智能体之年,其中也包括 OpenAI 总裁和 CEO 等
现在,2025 年才刚过不到一个月,以蛇年春节为契机,大量 AI 应用就已经诞生。可以说蛇年春节会是有史以来 AI 浓度最高的一个春节,也会为「智能体之年」吹响一个完美的序曲。
「AI 拜年」只是一个起点,也是一场立足中国传统节日文化的技术展示。iRAG 技术必然还将进一步拓展其应用场景,视觉设计类工作当然是最基本的。考虑到 iRAG 潜力,其很可能会成为未来视觉设计工作的一大基本组成,甚至有可能完成视觉设计中超过一半的基础工作量。甚至或许,街角煎饼摊的老板也能设计出自己的高级菜单。
视觉设计之外,iRAG 也可能会成为许多智能体的核心组件。简单想象一下,我们就能为其找到大量有价值的应用场景,包括基于现实场景创建游戏世界、根据老照片甚至画像进行人像复原、让我们和喜欢的动漫人物同框合影,还有生成靓丽帅气的春节相亲照…… 就正如基于文本和数据库的 RAG 让大量 AI 应用变得更有价值一样。
一点头脑风暴,我们就能想象出 iRAG 蕴含的无尽可能性。现在,这一技术就已经摆在我们眼前了。通过百度搜索,我们可以零成本且快速地抓住春节假期这个一年一次的大型营销契机,用 iRAG 为我们产品甚至为我们自己代言。
文章来自微信公众号 “ 机器之心 ”

【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

