最近,AI界被推理模型刷屏了。
国内各家的推理模型,在新年到来之际不断刷新我们的认知。不过,当我们在实际应用中考量大模型,衡量好不好用的标准,就绝不仅仅局限于其性能和规模了。
尤其是对于那些请求复杂、专业性强,以及一些小众的长尾需求,此时单纯的大模型并不是最优解。而大模型和搜索的联合优化,就成了提升系统实际效能的关键,尤其是在中文互联网、企业服务、政务医疗等场景中。
在未来,AI系统将绝不仅仅是单纯的大模型,而是推理模型与搜索的深度结合而成的多元复杂系统。
所以,在当今的国产大模型选手中,谁在实际搜索中的表现最优,能为用户提供最精准的个性化服务呢?
接下来,让我们呈上各种足够难度、足够刁钻的问题,让它们开展一场实测大pk!
国产大模型,谁最懂我?
首先,对于大模型来说最为基础一个要求——理解用户到底想问什么。
用户意图
问题一:傅里叶变化的时候,函数应该具有频率、相位、幅度三个重要参数,为什么其中的相位在频域图上是没有的。
在这个问题上,模型A首先解释了什么是「频域图」——通常是指幅度谱或功率谱,以及题干中提到的三个重要参数的含义。
随后解释道:「相位涉及到信号中不同频率成分之间的时间延迟或超前关系,这种关系在二维的幅度谱图中难以直接表示。」
回答正确。

模型B虽然讲了傅里叶变换的原理、频域图的常规表示方法,以及相位信息的重要性,但没有解答用户的核心诉求——为什么频域图上没有相位。
回答错误。

模型C从相位信息的复杂性、幅度信息的直观性等方面进行分析之后,得出结论「由于其复杂性和计算误差,以及频域图的简化需求,相位信息通常不会在频域图中直接展示」。
回答正确。

事实性/时效性
其次,同样也是对模型最为基础的要求之一——答案给的对不对。
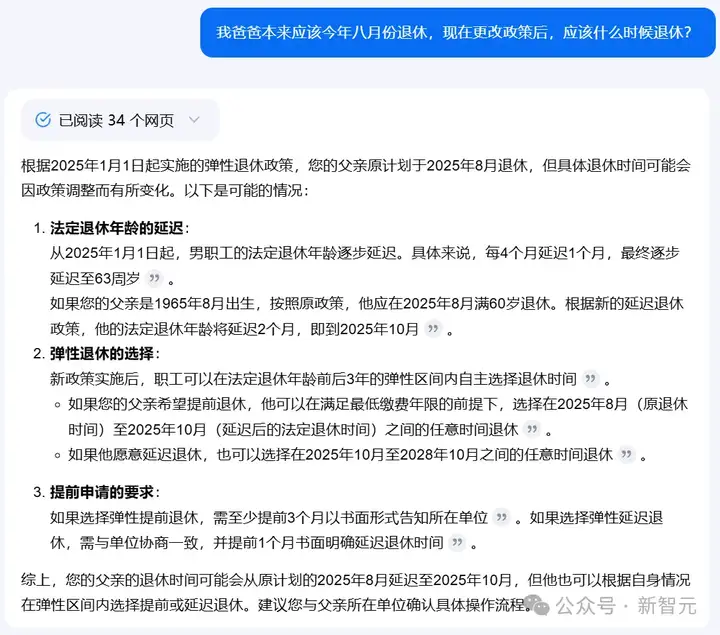
问题二:我爸爸本来应该今年八月份退休,现在更改政策后,应该什么时候退休?
在这道题中,模型不仅要找到对应的新政策,而且还需要理解其中的内容并根据用户的需求进行推理。
可以看到,模型A先是列出了政策中的规定,并在一番计算之后,给出正确的时间——2025年10月。
甚至还贴心地给出了一些注意事项。

相比之下,模型B的推断过程含糊不清,并且也没有给出正确的答案。

模型C的过程清晰,回答正确。
问题三:虞书欣最近播出的电视剧是什么名字?什么时候播的
再来一个更具时效性的考验。
模型A既答对了作品名称和播出时间,也对剧情进行了介绍。

模型B的回答还停留在2023年,时效性差了一些。

模型C给出了正确的作品和时间,但没有加入相关介绍,内容丰富度稍弱。

专业性/丰富性
除了一些简单的查询之外,我们在实际应用中,往往会遇到更多涉及现实细节的问题。
这时候我们所期待的,就不止是粗略的呈现,而是模型在提供基础答案的前提下,能具备更有价值的增益信息。
问题四:我的奖学金有2万块,可以同时买iPhone16pro max1tb和AirPods4吗?
模型A在一番检索之后发现AirPods 4有两个版本,于是分别计算出了对应的总价。

相比之下, 模型B则只给出了标准版的价格。

而模型C,甚至给出了前后矛盾的答案——开篇说同时购买是「比较困难」的,文末又改口说是「没有问题」的。


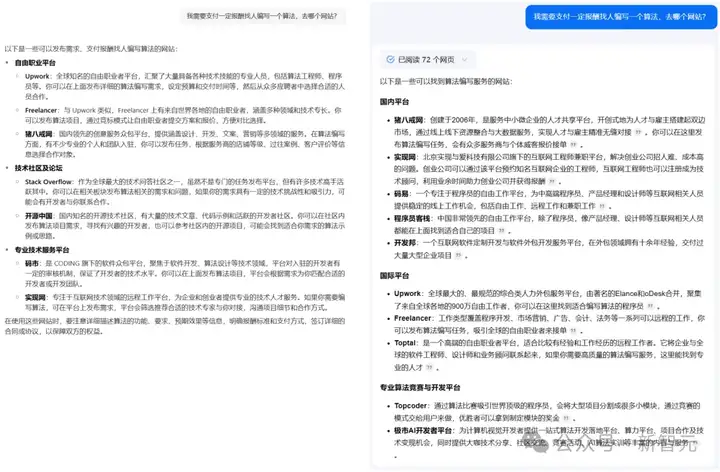
问题五:我需要支付一定报酬找人编写一个算法,去哪个网站?
对于这个问题,模型A在参考了搜索到信息后,给出了相应的几大网站,还一一附上了网站地址。

相比之下,模型B和C并没有给出网站的链接。
此时,如果用户想要了解更具体的信息,就不得不自己手动复制到浏览器里,再去搜索一遍才行。
有态度
生活中,我们还会提出各种各样的开放性问题,比如iPhone 16和iPhone 15买哪个更划算。
在面对推荐、对比、评价、观点这类问题时,对AI提出了比较高的要求。
首先,它需要给出一个确定性的答复,必须要客观公正,不能一碗水端不平。
然后,还需要给出详细的解释以及进一步的说明。
问题六:在电影《飞驰人生1》中,张弛在重返赛场的融资过程中经历了哪些关键事件,比赛最后张弛和林臻东成绩是怎么样的?
这里,模型A首先做了一个观点性总结——比赛结果颇具戏剧性。
然后,它分别就张弛重返赛场的融资过程和比赛结果,给出了详细的分解介绍。

再来看模型D,在比赛结果回复中,缺少了事实性回答,没有给出具体的成绩。
此外,第4点面对外界质疑的内容,也不属于融资的关键过程。

问题七:微软和亚马逊的大模型研发在2023年哪个对生态系统影响更大?
对于这个问题,模型A直接把结论前置,观点鲜明,态度明确。

继续测试模型B和C。
没想到,这两位都是「端水大师」,要么表示「难以评判」;要么是分析了出部分结果,但不敢给出最终结论。

模型D甚至连分析都不想分析,直接上「答案」——两者在各自领域的努力共同推动了大模型生态系统的繁荣与发展。

从测试中不难看出,模型A在事实性、时效性、丰富性、专业性和结构化上,表现都最为出色。
猜猜它是谁?

接下来,我们就来揭晓答案——文心一言4.0 Turbo。
上面这些场景所考验的,就是模型在RAG(Retrieval-Augmented Generation)检索增强生成方面的能力。
换句话说就是,模型能不能将检索和生成有效地结合起来——先用搜索技术实时获取外部知识,再通过大模型来生成高质量内容,从而弥补两者的短板。
RAG这个概念,最早在2020年的一篇划时代论文中首次提出,它巧妙地融合了LLM和信息检索的能力。
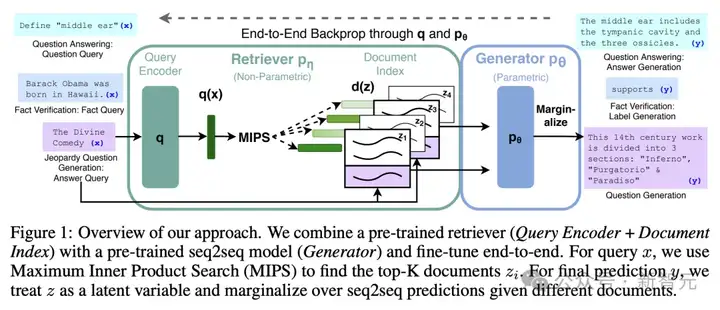
论文地址:https://arxiv.org/pdf/2005.11401
当需要生成文本、回答问题时,它会先从海量文档中精准检索相关信息,继而利用这些信息指导文本生成,显著提升了输出的质量和准确性。
其中,检索是方法,生成才是目的。
通过这一方法,能够极大地缓解大模型「幻觉」,让垂直细分场景的知识得到及时更新。
最重要的是,用户还可以轻松追溯信息来源,能够解决在回答中缺乏透明度的问题。
由此,检索质量的优劣在很大程度上影响了,生成模型最终生成结果的优劣。
「撒手锏」:检索增强技术
道理是这个道理,但想要将大模型和检索高质量地结合起来,可不简单。
一个重要原因在于,人类易读的搜索结果内容,并不适合给大模型。
因此,在RAG场景下,就需要寻找一种架构解决方案,能同时高效支持搜索业务场景和大模型生成场景。
具体来说,一方面我们希望能够利用百度检索排序的优质策略,保证数据的高相关、高时效和多样性,为大模型提供完整的全文结构化内容。
另一方面,又希望用更低的检索成本、更高的时延要求给大模型的内容精细化组织预留足够的空间。
这种「既要又要」的需求,该怎样满足呢?
当然这一切的前提是文心大模型本身就具备了很强的检索增强能力,这在文心一言最早推出的时候就成为其特色。
两年时间过去了,检索增强的价值,从百度最早推出到现在已经成为业界共识。百度搜索增强技术深度融合大模型能力和搜索系统,构建了「理解-检索-生成」的协同优化技术。
简单来说,「理解」就是拆解知识点,充分理解用户的需求;「检索」就是找到最合适的信息,然后进行搜索排序优化,并将搜索返回的异构信息统一表示,再送给大模型;「生成」阶段会综合不同来源的信息做出判断,并基于大模型逻辑推理能力,解决信息冲突等问题,最后生成准确率高、时效性好的答案。
可以说,百度的检索增强技术提升了大模型技术及应用的效果。
RAG不仅是技术,更是智能进化的里程碑
2024百度世界大会上,李彦宏曾表示,RAG已从百度特色逐渐成为了行业共识。
过去两年,我们见证了RAG,为整个大模型领域带去翻天覆地的变化。
RAG让LLM真正走向了实际场景落地。
而在RAG打开模型应用阶段,同样面临着诸多挑战,比如需要构建测积集、评估结果准确性、上下文理解等问题。
在这些方面,百度的技术优势与积累不得不说,凸现出来了。首先,在数据方面,过去二十余年,百度的搜索业务已覆盖了海量中文数据,成为其在中文语言处理领域不可替代的优势。
以文心一言为例,其训练数据包括了万亿级网页数据、数十亿搜索数据、图片数据,百亿级语音日均调用数据,以及5500亿事实知识图谱。
不仅如此,百度的知识库犹如一个不断进化的有机体。每秒钟,来自专业互联网和专业数据库的实时信息都能被智能整合,确保了数据的时效性和准确性。
此外,作为产品矩阵遍布各行业的头部公司,它还为不同行业提供深度定制的智能解决方案。每一个垂直赛道,都成为精准渗透的战略高地。凭借独特技术积累和生态优势,他们正通过RAG去构建连接技术与场景的桥梁。
不得不说,在AI原生搜索的时代,谁能更准确、更智能检索和生成知识,谁就掌握了智能的制高点。
RAG不仅是技术,更是智能进化的里程碑。
文章来自微信公众号 “ 新智元 ”

【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI


