"Deepseek R1不就是一个参数更大的语言模型吗?随便问问题就行了,还需要什么特殊技巧?"——当你说出这句话时,是否意识到自己正像《西游记》里高举紫金葫芦的妖怪,对着齐天大圣叫嚣:"我叫你的名字,你敢答应吗?"
这恰似当下AI应用场景中最危险的认知陷阱:开发者们手握GRPO锻造的"炼丹炉至宝",却用着石器时代的唤醒咒语。
当你在测试环境随手写下"帮我分析数据"的提示词时,就像银角大王得意洋洋地晃动宝葫芦——看似声势惊人,实则完全错估了对手的维度。
Deepseek R1的GRPO算法,本质上是被炼丹炉三昧真火淬炼过的"如意金箍棒"。它不仅具备传统RLHF的单路径强化能力,更通过Group Relative机制形成了多维认知空间。就像孙悟空拔毫毛化出万千分身,GRPO会让模型同时生成数十个潜在解决方案,在动态博弈中筛选出最优思维链。这种特性决定了:
- 盲目提问=自投罗网:当你的提示词像"银角式叫阵"般粗糙时,模型的多维探索能力反而会成为认知牢笼
- 精准诱导=七十二变:符合GRPO特性的提示词,能像孙悟空那样在葫芦内部开辟逃生通道
- 策略迭代=紧箍咒进化:持续优化的提示工程,本质上是在重构模型的认知相对论框架
那些把生产环境当作"莲花洞酒宴"的团队正在付出惨痛代价:曾有某金融机构用基础提示词处理风控数据,结果GRPO的群体优化机制放大了某个隐藏偏差,导致模型像被幌金绳捆住的沙僧般陷入死循环。
本文将揭示如何将GRPO的"多重身外身"特性转化为战略优势:
- 从紫金葫芦的维度陷阱到认知迷宫的拓扑解法
- 把"叫你名字"的死亡游戏改写为认知升维的密钥
- 用GRPO的相对论机制铸造提示词的"金刚不坏之身"
当你真正理解这个AI炼丹炉的运行法则时,就会明白:那些看似随意的提示词,正在把你的关键业务数据推向"一时三刻化为一滩水"的危险边缘。
年末恰逢顿悟《了凡四训》aha时刻,看到诸多公众号好友发文降低Deepseek R1提示词难度。遂希望能帮大家通俗理解GRPO,通过"一日三省"训练对抗LLMs的认知窄化,保持δ-贝叶斯脑可塑性(δ>0.7),在关键决策点启动"立命协议"(详见下图Deepseek R1经过11秒的思考结果)。

一、颠覆传统:无监督数据的推理突破
如何提升模型的推理能力一直是一个核心挑战。传统方法主要依赖大量标注数据进行监督训练,这不仅耗费大量人力物力,而且容易导致模型过度拟合已有数据模式。DeepSeek团队的最新研究成果DeepSeek-R1通过纯强化学习方法,在没有任何监督数据的情况下,实现了模型推理能力的显著提升。这一突破性成果不仅挑战了传统认知,更为未来AI发展提供了全新思路。

研究表明,DeepSeek-R1-Zero在AIME 2024数学竞赛测试中的pass@1得分从15.6%提升至71.0%,采用多数投票后更是达到86.7%,这一成绩与OpenAI-o1-0912相当。这些数据充分证明,纯强化学习方法完全可以激发出模型的推理潜力,而无需依赖大量标注数据。这对于当前AI领域普遍存在的数据依赖问题提供了一个全新的解决思路。
 二、GRPO:突破性的强化学习算法
二、GRPO:突破性的强化学习算法
2.1 算法原理与创新
分组相对策略优化(Group Relative Policy Optimization,GRPO)算法是DeepSeek-R1的核心创新。该算法摒弃了传统强化学习中价值模型(Critic)与策略模型(Actor)双轨并行的复杂架构,转而采用单组输出间的相对评分来计算优势函数,这一设计将训练成本降低40%以上。

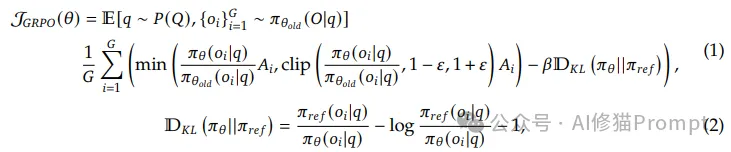
这种设计不仅巧妙规避了价值模型的训练开销,使得RL训练可在单卡环境下完成,还通过相对评分机制提供了更稳定的学习信号。
通俗理解GRPO
GRPO(群组相对策略优化)就像是一个智能的学习系统,它的学习方式模仿了优秀学生解决复杂问题时的思维过程。这个系统有几个关键特点:
- 多方案探索 不同于传统方法只生成单一答案,GRPO会同时产生多个解决方案。这就像一个认真的学生会先列出几种不同的解题思路,然后再决定哪种最好。这种方法不仅增加了找到正确答案的机会,还帮助系统学习不同解题策略的优劣。
- 智能评估机制 GRPO的评估过程非常巧妙:
- 它不是简单地判断对错,而是计算每个答案相对于群组的"优势度"
- 复杂的数学公式您也可以这么理解:优势度 = (当前答案的分数 - 组内平均分数) / 组内分数的标准差
- 这种方法确保了评估的公平性,不会因为问题难度不同而产生偏差
3.渐进式学习保护 为了确保学习过程的稳定性,GRPO采用了多重保护机制:
- 使用"裁剪"函数限制单次改变的幅度,避免过激的调整
- 通过KL散度监控与原始行为的偏离程度,保持学习的连续性
- 在探索新方法和保持已有经验之间找到平衡点
这种设计看似简单,实则暗含深意。通过弱约束引导而非强内容干预(写提示词时您也需要这么考虑),模型在保持自由探索的同时,逐渐形成结构化推理的习惯。实验数据显示,经过3000步RL训练后,模型生成的思考链平均长度从87词增至512词,且在AIME测试中展现出多步骤验证、错误回溯等高级行为。
GRPO采用了双轨并行的奖励系统,通过规则奖励和格式奖励的有机结合,引导模型形成系统化的推理能力:
- 规则奖励层
- 基础正确性评估:通过预定义规则自动判定答案
- 推理完整性检查:验证关键步骤的存在和正确性
- 边界条件测试:评估特殊情况的处理能力
2.格式奖励层
- 结构化输出要求:使用和标签规范化思考过程
- 语言一致性评估:确保输出语言的纯净度
- 可读性衡量:评估表达的清晰度和专业性
- 关于格式部分您也可以移步《微软和麻省理工权威发布:Prompt格式显著影响LLM性能,JSON比Markdown准确性高42%》《又见惊雷,结构化Prompt格式小小变化竟能让LLM性能波动高达76%,ICLR2024》
3.动态调节机制
- 阶段性权重调整:根据训练进度调整不同奖励的权重
- 难度感知:为更具挑战性的问题提供更高奖励
- 组合奖励:综合考虑多个维度的表现
这种设计通过弱约束引导而非强制干预,让模型在保持探索自由的同时,逐渐形成结构化的推理习惯。实验数据显示,经过3000步RL训练后,模型生成的思考链平均长度从87词增至512词,且在AIME测试中展现出多步骤验证、错误回溯等高级行为。
2.4 涌现现象:认知能力的跃迁
在GRPO训练过程中,研究团队观察到了多种令人惊叹的自发进化现象:

- "顿悟时刻"的出现
<think>
让我解决方程:√(a-√(a+x))=x
初步思路:
1. 两边平方消除第一个根号...
等等,我需要先考虑定义域!
- a-√(a+x)必须≥0
- a+x必须≥0
这个约束条件很关键,让我重新推导...
</think>
- 自主反思行为
<think>
分析这个优化问题...
我的第一个想法是使用贪心算法,因为看起来局部最优可以导致全局最优。
不过等等,让我先证明一下这个性质是否成立。
假设我们有序列{a1, a2, ..., an}...
[推导过程]
啊,找到反例了!原来在特殊情况下贪心会失效。
需要改用动态规划来解决。
</think>
- 策略优化能力
<think>
这道几何题可以用解析几何方法...
但是,我注意到这些点都在单位圆上,
使用复数可能会让解法更优雅。
让我尝试用复数方法重新解决:
z = cos θ + i sin θ
[推导过程]
果然,这种方法大大简化了计算!
</think>
三、突破性的两阶段训练方法
3.1 DeepSeek-R1-Zero:纯强化学习探索
在第一阶段,研究团队进行了一个大胆的尝试:完全摒弃监督数据,仅通过强化学习来训练模型。这个阶段的关键设计包括:
- 基础模型选择
- 选用DeepSeek-V3-Base作为起点
- 不进行任何监督微调(SFT)
- 直接应用GRPO进行训练
2.训练模板设计
用户和助手之间的对话。助手首先在思维中进行推理过程,然后向用户提供答案。
推理过程和答案分别包含在<think></think>和<answer></answer>标签中。
3.自进化现象观察
- 思考链条自然延长:从平均87词增至512词
- 自我纠错行为形成:学会在发现问题时停止并重新思考
- 策略持续优化:逐步形成更系统的解题方法
3.2 DeepSeek-R1:精细化提升阶段
为了解决R1-Zero在可读性和语言混合等方面的问题,团队开发了一个系统化的优化流程:
- 冷启动数据构建
- 数据来源:
- Few-shot示例生成
- R1-Zero高质量输出筛选
- 专家优化和标注
- 质量控制:
- 推理过程清晰可读
- 语言表达规范统一
- 格式结构标准化
2.定向能力强化
- 重点领域:
- 数学推理
- 代码生成
- 科学问题解决
- 训练策略:
- 保持GRPO框架
- 优化奖励机制
- 强化输出规范
3.大规模数据生成
- 生成规模:约60万条推理数据
- 筛选标准:
- 答案正确性验证
- 推理过程评估
- 表达规范检查
- 补充数据:20万条通用任务数据
4.全场景优化
- 目标平衡:
- 推理能力保持
- 通用能力提升
- 输出质量优化
- 实现策略:
- 多维度奖励结合
- 跨语言能力增强
- 安全性强化
3.3 知识蒸馏:规模化部署的突破
研究团队通过创新的知识蒸馏方法,成功将DeepSeek-R1的能力迁移到更小的模型中:
- 蒸馏方案设计
- 训练数据:DeepSeek-R1生成的80万高质量样本
- 目标模型:覆盖1.5B到70B不同规模
- 训练方式:纯监督学习,无需强化学习
2.实验效果
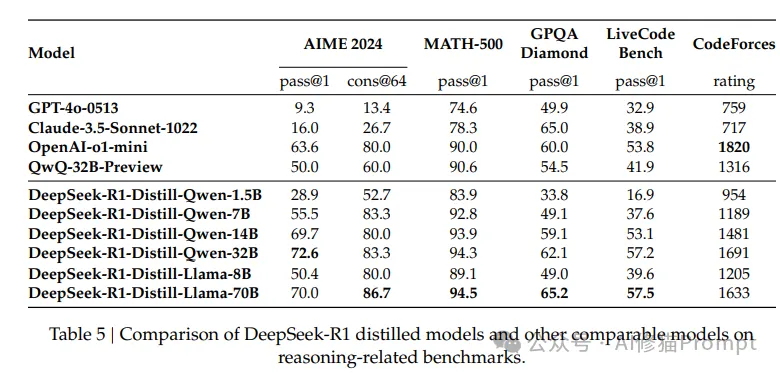
- DeepSeek-R1-Distill-Qwen-7B:
- AIME:55.5%(超越GPT-4)
- MATH:92.8%
- DeepSeek-R1-Distill-Qwen-32B:
- AIME:72.6%
- MATH:94.3%
- LiveCodeBench:57.2%
3.关键发现
- 蒸馏效果优于直接训练
- 推理模式可有效迁移
- 训练过程更稳定可控
四、性能评估与分析
4.1 全面的性能提升
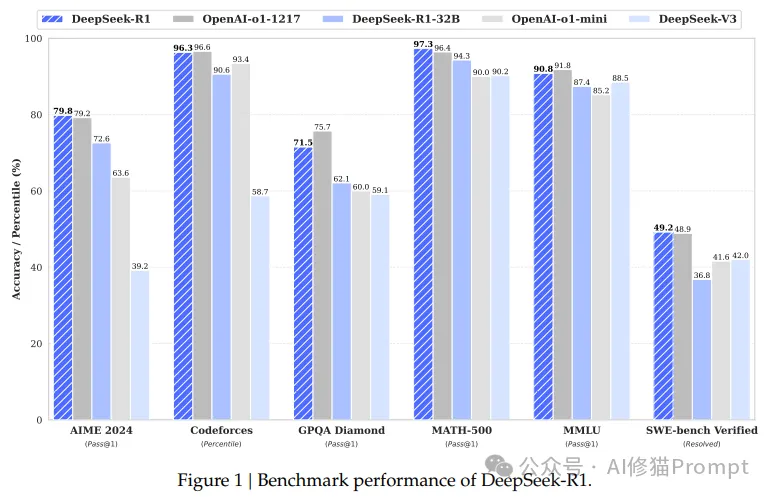
DeepSeek-R1在多个权威基准测试中展现出卓越性能:
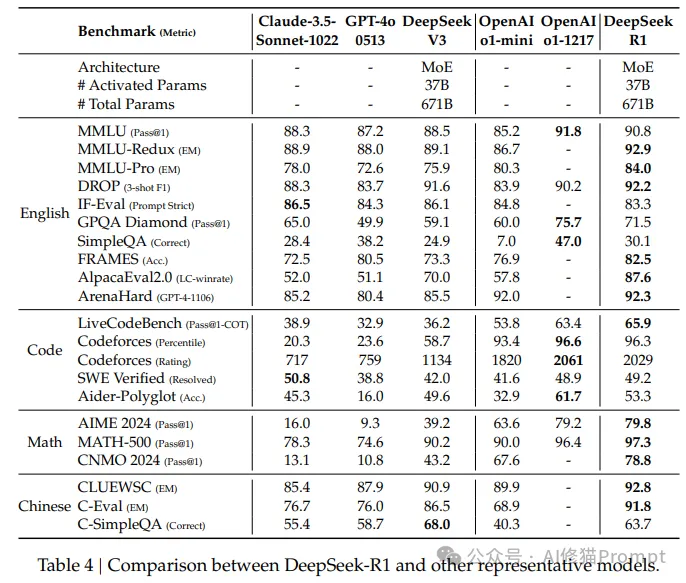
- 数学推理能力
- AIME 2024:79.8%(Pass@1)
- MATH-500:97.3%(Pass@1)
- CNMO 2024:78.8%(Pass@1)
2.编程能力评估
- Codeforces:96.3%
- LiveCodeBench:65.9%(Pass@1)
- SWE Verified:49.2%(Resolved)
3.知识理解水平
- MMLU:90.8%
- MMLU-Pro:84.0%
- GPQA Diamond:71.5%
4.2 自进化过程分析
研究团队通过长期观察,总结出模型在训练过程中展现的三类典型进化特征:
- 认知深度提升
- 思考链条自然延长
- 问题分析更加全面
- 解决方案更加系统
2.方法论进化
- 自发形成验证习惯
- 主动寻找最优解法
- 建立问题解决框架
3.创新能力涌现
- 发现新的解题思路
- 优化已有解决方案
- 跨领域知识迁移
五、应用场景推荐
- 教育领域应用
- 数学问题解答辅导
- 编程技能培训
- 科学探究引导
2.软件开发支持
- 代码生成与优化
- 程序调试辅助
- 技术文档生成
3.通用智能问答
- 复杂问题分析
- 多步骤推理
- 结果验证与优化
六、写在最后
DeepSeek-R1的突破性成果为大语言模型的发展开辟了新路径。纯强化学习方法不仅证明了其在提升模型推理能力方面的巨大潜力,还为解决AI领域的数据依赖问题提供了创新思路。这一进展将推动AI技术向着更智能、更自主的方向发展。对于AI研究者和实践者而言,理解和掌握这些新技术将有助于开发出更强大、更实用的AI应用。
篇幅原因,GRPO的系统提示词,我将发到群里与大家分享。如果您希望进一步了解或者需要更多提示词,您也可以参照这篇文章《AI修猫Prompt公众号文章赞赏赠与资料分类汇总》对我进行赞赏支持,可以得到更多SYSTEM PROMPT。如果需要更多DSPy已经运行过的代码,或者据提的案例可以看下以下文章。希望这篇文章对您有所帮助!
文章来自微信公众号 “ AI修猫Prompt ”

【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

