AI生成内容已深度渗透至生活的方方面面,从艺术创作到设计领域,再到信息传播与版权保护,其影响力无处不在。
然而,随着生成模型技术的飞速发展,如何精准甄别AI生成图像成为业界与学界共同聚焦的难题。
来自小红书生态算法团队、中科大、上海交通大学联合提出行业稀缺的全人工标注Chameleon基准和行业领先的AIDE检测方法。

团队经过分析,几乎所有模型都将Chameleon基准中AI生成的图像归类为真实图像
于是他们提出了AIDE(具有混合特征的AI -generated Image DE tector ),它利用多个专家同时提取视觉伪影和噪声模式。最终分别比现有的最先进方法提高了
3.5% 和 4.6% 的准确率。
重新定义AI生成图像检测任务
Train-Test Setting-I:在现有研究中,AI 生成图像检测任务通常被设定为在一个特定的生成模型(如 GAN 或扩散模型)上训练模型,然后在其他生成模型上进行测
试。
![]()
然而,通常来说,这种设定存在两个主要问题:
评估Benchmark过于简单:现有Benchmark中的图像通常会有一些artifacts。
训练数据的局限性:将模型限制在特定类型的生成模型上 (GAN or 扩散模型) 训练,限制了模型从更先进的生成模型中学习多样化特征的能力。
为了解决这些问题,团队提出了一个新的问题设定:
Train-Test Setting-II:鉴别器可以将多种生成模型的图像混合一起训练,然后在更具挑战性的、真实世界场景中的图像上进行测试。这种设定更符合实际应用中的
需求,能够更好地评估模型的泛化能力和鲁棒性。
![]()
为了更真实地评估 AI 生成图像检测方法的性能,团队精心构建了Chameleon 数据集。

Chameleon数据集具有以下显著特点:
高度逼真性:所有AI生成图像均通过了人类感知“图灵测试”,即人类标注者无法将其与真实图像区分开来。这些图像在视觉上与真实图像高度相似,能够有效挑战现
有检测模型的极限。
多样化类别:数据集涵盖了人类、动物、物体和场景等多类图像,全面模拟现实世界中的各类场景。这种多样性确保了模型在不同类别上的泛化能力。
高分辨率:图像分辨率普遍超过720P,最高可达4K。高分辨率图像不仅提供了更丰富的细节信息,也增加了检测模型对细微差异的捕捉能力。
数据集构建
为构建一个能够真实反映 AI 生成图像检测挑战的高质量数据集,团队在数据收集、清洗和标注环节均采取了创新且严谨的方法,确保数据集的高质量和高逼真度。
数据收集:多渠道、高逼真度图像获取
与之前的基准数据集不同,团队从多个流行的 AI 绘画社区(如 ArtStation、Civitai 和 Liblib)收集了超过 150K 的 AI 生成图像,这些图像均由广泛的用户创作,使
用了多种先进的生成模型(如 Midjourney、DALL·E 3 和 Stable Diffusion 等)。这些图像不仅在视觉上逼真,而且涵盖了丰富多样的主题和风格,包括人物、动
物、物体和场景等。此外,还从 Unsplash 等平台收集了超过 20K 的真实图像,这些图像均由专业摄影师拍摄,具有高分辨率和高质量。所有图像均获得了合法授
权,确保了数据的合法性和可用性。
相比之下,之前的基准数据集通常使用生成效果较差的模型生成图像,缺乏多样性和真实感,如下图所示。

数据清洗:多维度、精细化过滤
为确保数据集的高质量,团队对收集的图像进行了多维度、精细化的清洗过程:
分辨率过滤:团队过滤掉了分辨率低于 448×448 的图像,确保所有图像具有足够的细节和清晰度,以反映 AI 生成图像的真实特性。
内容过滤:利用先进的安全检查模型(如 Stable Diffusion 的安全检查模型),团队过滤掉了包含暴力、色情和其他不适宜内容的图像,确保数据集的合规性和适用
性。
去重处理:通过比较图像的哈希值,团队去除了重复的图像,确保数据集的多样性和独立性。
文本-图像一致性过滤:利用 CLIP 模型,团队计算了图像与对应文本描述的相似度,过滤掉了与文本描述不匹配的图像,确保图像与文本的一致性和相关性。
之前的基准数据集往往缺乏严格的过滤步骤,导致数据集中包含大量低质量、不适宜或重复的图像,影响了数据集的整体质量。
数据标注:专业标注平台与多轮评估
为确保数据集的准确性和可靠性,团队建立了专门的标注平台,并招募了 20 名具有丰富经验的人类标注者对图像进行分类和真实性评估:
分类标注:标注者将图像分为人类、动物、物体和场景四类,确保数据集覆盖了多种现实世界中的场景和对象。
真实性评估:标注者根据“是否可以用相机拍摄”这一标准对图像的真实性进行评估。每个图像独立评估两次,只有当两名标注者均误判为真实时,图像才被标记为“高
逼真”。
多轮评估:为确保标注的准确性,团队对标注结果进行了多轮审核和校对,确保每个图像的分类和真实性评估结果准确无误。
与之前的基准数据集不同,该数据集经过了严格的人工标注,确保了数据集的高质量和高逼真度。之前的基准数据集往往缺乏严格的人工标注,导致数据集中的图像
质量和标注准确性参差不齐。
通过上述多维度、精细化的数据收集、清洗和标注过程,构建了一个高质量、高逼真度的 AI 生成图像检测基准数据集,为后续的研究和模型评估提供了坚实的基
础。该数据集不仅在规模上更大,而且在图像质量和标注精度上也有了显著提升,能够更好地反映 AI 生成图像检测的实际挑战。
数据集对比
Chameleon数据集可以作为现有评测数据集的扩展,Chameleon数据集在规模、多样性和图像质量等方面均展现出显著优势:
规模:Chameleon数据集包含约26,000张测试图像,是目前最大的AI生成图像检测数据集之一。
多样性:数据集涵盖了多种生成模型和图像类别,远超其他数据集的单一类别。
图像质量:图像分辨率从720P到4K不等,提供了更高质量的图像数据,增加了检测模型的挑战性。
AIDE模型:多专家融合的检测框架
在AI生成图像检测领域,现有的检测方法往往只能从单一角度进行分析,难以全面捕捉AI生成图像与真实图像之间的细微差异。
为了解决这一问题,研究者们提出了简单且有效的AIDE(AI-generated Image DEtector with Hybrid Features)模型,该模型通过融合多种专家模块,从低级像素统
计和高级语义两个层面全面捕捉图像特征,实现了对AI生成图像的精准检测。
AIDE模型主要由两个核心模块组成:Patchwise Feature Extraction(PFE)模块和Semantic Feature Embedding(SFE)模块。这两个模块通过多专家融合的方
式,共同为最终的分类决策提供丰富的特征信息。
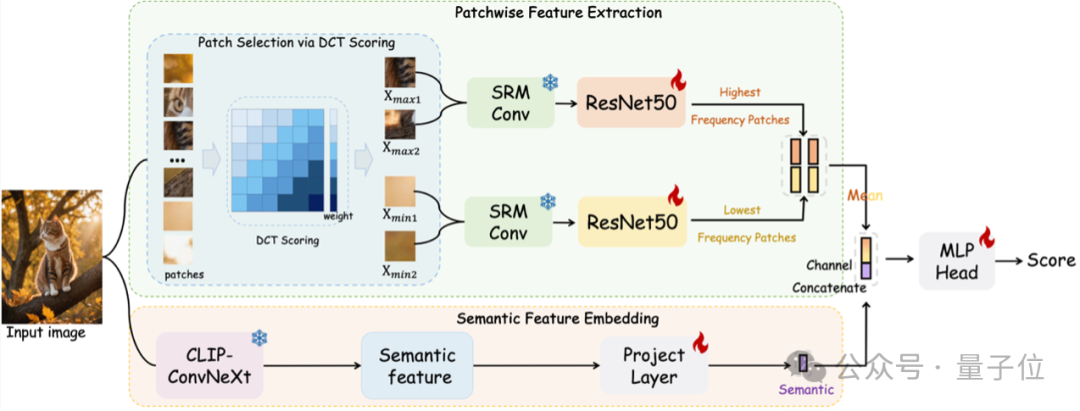
Patchwise Feature Extraction(PFE)模块
PFE模块旨在捕捉图像中的低级像素统计特征,特别是AI生成图像中常见的噪声模式和纹理异常。具体而言,该模块通过以下步骤实现:
Patch Selection via DCT Scoring:首先,将输入图像划分为多个固定大小的图像块(如32×32像素)。然后,对每个图像块应用离散余弦变换(DCT),将其转
换到频域。通过设计不同的带通滤波器,计算每个图像块的频率复杂度得分,从而识别出最高频率和最低频率的图像块。
Patchwise Feature Encoder:将筛选出的高频和低频图像块调整为统一大小(如256×256像素),并输入到SRM(Spatial Rich Model)滤波器中提取噪声模式特
征。这些特征随后通过两个ResNet-50网络进行进一步处理,得到最终的特征图。
Semantic Feature Embedding(SFE)模块
SFE模块旨在捕捉图像中的高级语义特征,特别是物体共现和上下文关系等。具体而言,该模块通过以下步骤实现:
Semantic Feature Embedding:利用预训练的OpenCLIP模型对输入图像进行全局语义编码,得到图像的视觉嵌入特征。通过添加线性投影层和平均空间池化操
作,进一步提取图像的全局上下文信息。
Discriminator模块
将PFE和SFE模块提取的特征在通道维度上进行融合,通过多层感知机(MLP)进行最终的分类预测。具体而言,首先对高频和低频特征图进行平均池化,得到低级
特征表示;然后将其与高级语义特征进行通道级拼接,形成最终的特征向量;最后通过MLP网络输出分类结果。
实验结果
数据集:实验在AIGCDetectBenchmark、GenImage和Chameleon三个数据集上进行。AIGCDetectBenchmark和GenImage是现有的基准测试数据集,而
Chameleon是研究者们新构建的更具挑战性的数据集。
模型对比:研究者选择了9种现成的AI生成图像检测器进行对比,包括CNNSpot、FreDect、Fusing、LNP、LGrad、UnivFD、DIRE、PatchCraft和NPR。
评价指标:实验采用分类准确率(Accuracy)和平均精度(Average Precision, AP)作为评价指标。
团队评测了AIDE在AIGCDetectBenchmark和GenImage上的结果,如下表所示:
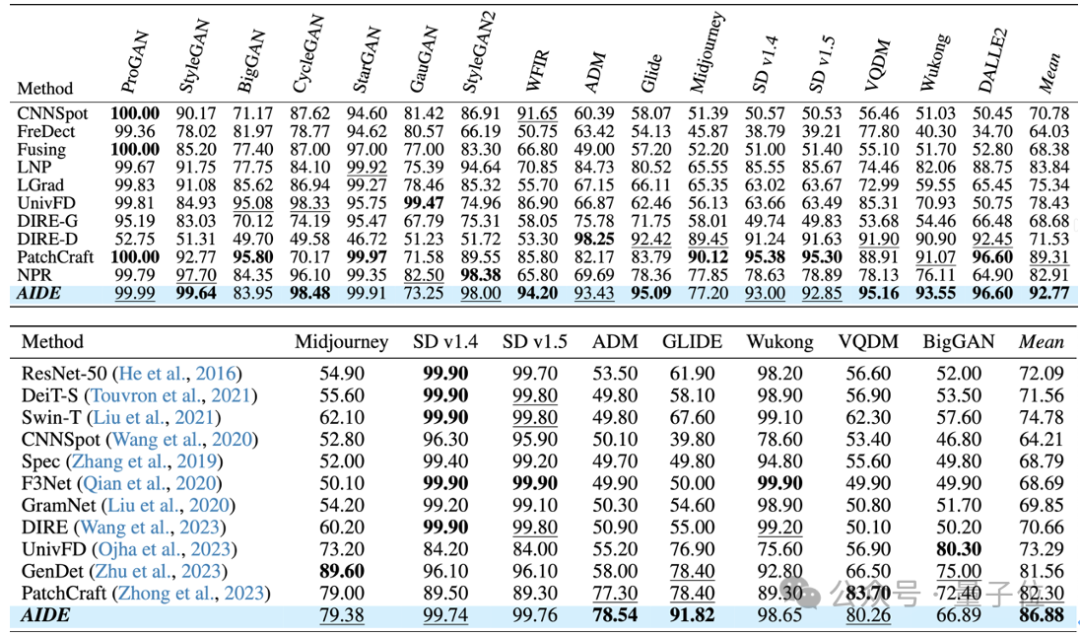
AIDE模型在这两个数据集上的优异表现表明,融合低级像素统计和高级语义特征的方法能够有效捕捉AI生成图像与真实图像之间的差异,从而提高检测准确率。
随后在Chameleon benchmark上测评了9个现有的detectors,如下表所示。

同时团队可视化了,之前的SOTA方法PatchCraft在AIGCDetectBenchmark & GenImage 以及Chameleon上的表现
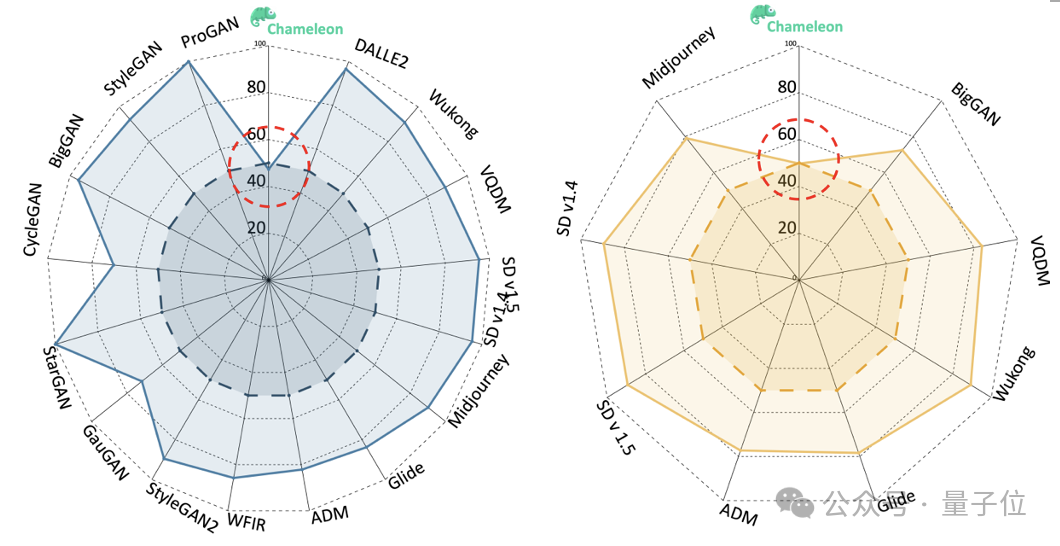
结果表明,之前在AIGCDetectBenchmark &GenImage上表现优异的模型,在Chameleon benchmark上均表现很差,这表明Chameleon数据集中的图像确实具有高
度的逼真性,对现有检测模型提出了更大的挑战。
本论文通过对现有 AI 生成图像检测方法的重新审视,提出了一个新的问题设定,构建了更具挑战性的 Chameleon 数据集,并设计了一个融合多专家特征的检测器
AIDE。实验结果表明,AIDE 在现有的两个流行基准(AIGCDetectBenchmark 和 GenImage)上取得了显著的性能提升,分别比现有的最先进方法提高了 3.5% 和
4.6% 的准确率。然而,在 Chameleon 基准上,尽管 AIDE 取得了最好的性能,但与现有基准相比,仍存在较大的差距。
这表明,检测 AI 生成图像的任务仍然具有很大的挑战性,需要未来进一步的研究和改进。希望这一工作能够为这一领域的研究提供新的思路和方向,推动 AI 生成图
像检测技术的发展。
尽管AIDE模型在AI生成图像检测领域取得了显著进展,但研究者们仍计划在未来的工作中进一步优化模型架构,探索更高效的特征提取和融合方法。
此外,研究者们还计划扩大Chameleon数据集的规模,涵盖更多类别、更多场景、更多生成模型的图像,以推动AI生成图像检测技术的进一步发展。
论文: https://arxiv.org/pdf/2406.19435
主页: https://shilinyan99.github.io/AIDE/
代码: https://github.com/shilinyan99/AIDE
文章来自于微信公众号 “量子位”,作者 :小红书团队

【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI

