月之暗面和 DeepSeek 这次又「撞车」了。
上次是论文,两家几乎前后脚放出改进版的注意力机制,可参考《撞车 DeepSeek NSA,Kimi 杨植麟署名的新注意力架构 MoBA 发布,代码也公开》、《刚刚!
DeepSeek 梁文锋亲自挂名,公开新注意力架构 NSA》。
这次是开源。
上周五,DeepSeek 刚刚官宣这周要连续开源 5 个代码库,却被月之暗面深夜截胡了。
昨天,月之暗面抢先一步开源了改进版 Muon 优化器,比 AdamW 优化器计算效率提升了 2 倍。
团队人员表示,原始 Muon 优化器在训练小型语言模型方面表现出色,但其在扩展到更大模型方面的可行性尚未得到证明。因此,团队人员确定了两种对扩展 Muon
至关重要的技术:
- 添加权重衰减:对扩展到更大模型至关重要。一致的 RMS 更新:在模型更新上执行一致的均方根。
这些技术使得 Muon 能够在大规模训练中直接使用,而无需调整超参数。Scaling law 实验表明,与计算最优训练的 AdamW 相比,Muon 的计算效率提升了 2 倍。
基于这些改进,月之暗面推出了 Moonlight,这是一个 3B/16B 参数的 Mixture-of-Expert(MoE)模型,使用 Muon 进行了 5.7 万亿 tokens 的训练。该模型刷新了当
前的「帕累托前沿」,换句话说,在相同的训练预算下,没有其他模型能在所有性能指标上同时超越它。
与之前的模型相比,Moonlight 也以更少的训练 FLOPs 获得了更好的性能。
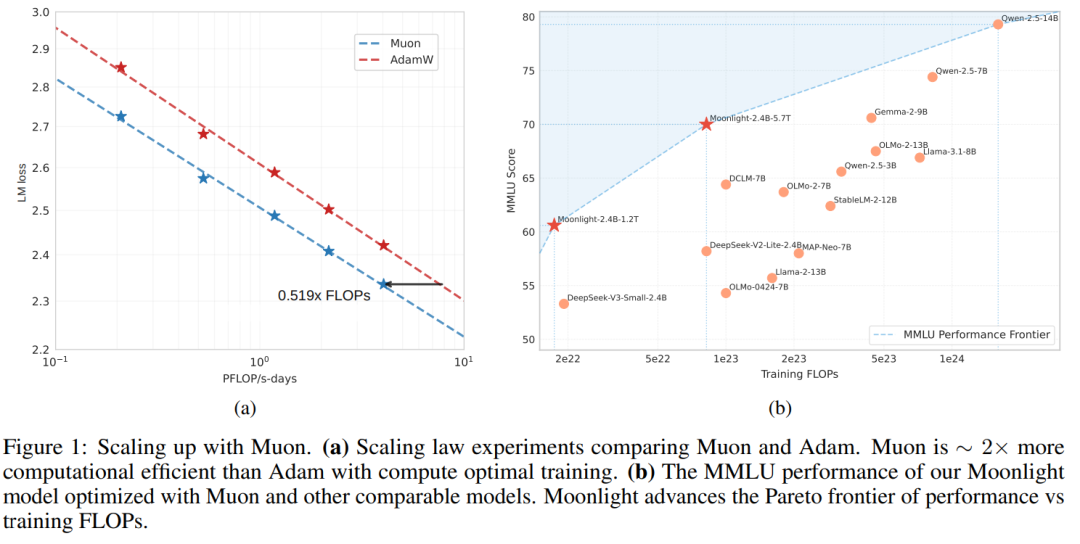
如下图所示,该研究进行了 Scaling law 研究,将 Muon 与强大的 AdamW 基线进行了比较,结果展示了 Muon 的卓越性能。Muon 实现了与 AdamW 训练相当的性
能,同时仅需要大约 52% 的训练 FLOP。
月之暗面不但开源了内存优化且通信高效的 Muon 实现代码,并且还发布了预训练、指令调优以及中间检查点,以支持未来的研究。
论文《 MUON IS SCALABLE FOR LLM TRAINING 》。

- 论文地址:https://github.com/MoonshotAI/Moonlight/blob/master/Moonlight.pdf
- 代码地址:https://github.com/MoonshotAI/Moonlight
- 模型地址:https://huggingface.co/moonshotai/Moonlight-16B-A3B
研究介绍
扩展 Muon
Muon 优化器为 OpenAI 研究者 Keller Jordan 等人在 2024 年提出的,他们的研究表明在小规模训练中 Muon 的表现显著优于 AdamW。
但月之暗面发现,当将其扩展到训练更大模型并使用更多 token 时,模型性能提升逐渐减弱。他们观察到,权重和层输出的 RMS 值持续增长,最终超出了 bf16 的
高精度范围,这可能会损害模型的性能。
为了解决这个问题,月之暗面在 Muon 中引入了标准的 AdamW(Loshchilov 等人,2019)权重衰减机制。
为了探究这一机制,研究者对 Muon 进行了有无权重衰减的实验,他们训练了一个包含 800M 参数和 100B token(约为最优训练 token 量的 5 倍)的模型。图 2 展
示了使用 AdamW、无权重衰减的原始 Muon 以及带权重衰减的 Muon 训练的模型的验证损失曲线。
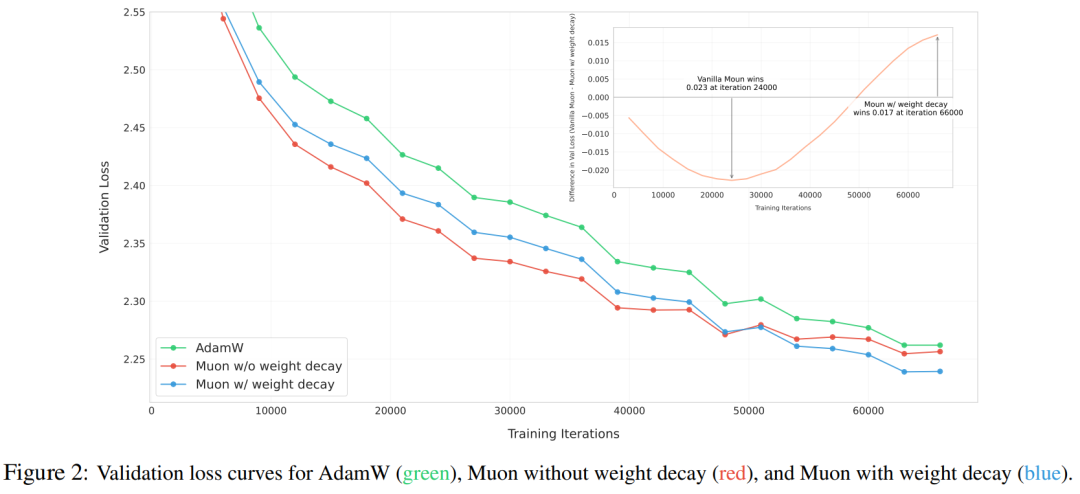
结果显示,虽然原始 Muon 在初期收敛速度更快,但一些模型权重随时间的推移增长过大,可能会影响模型的长期性能。
加入权重衰减后解决了这一问题 —— 结果表明,带权重衰减的 Muon 优于原始 Muon 和 AdamW,获得了更低的验证损失。公式 3 为表达式,其中 λ 为权重衰减比
率。

一致的 RMS 更新。研究者发现 Adam 和 AdamW 的一个重要特性是,它们将更新的 RMS 维持在 1 左右。然而,月之暗面发现 Muon 更新 RMS 会根据参数矩阵形
状的变化而变化,具体如下引理 1 所示:
![]()

在实际应用中,研究者通常将 AdamW 与 Muon 结合使用,以处理非矩阵参数。本文希望优化器超参数(学习率 η、权重衰减 λ)能够在矩阵参数和非矩阵参数之间
共享。
因此他们提出将 Muon 更新的 RMS 调整到与 AdamW 相似的范围。他们通过以下调整将 Muon 更新 RMS 缩放至这一范围:
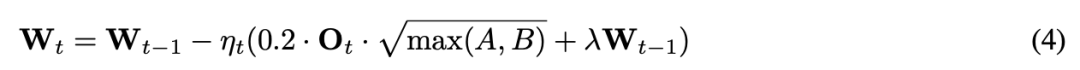
分布式 Muon
月之暗面团队还提出了一种基于 ZeRO-1 的分布式解决方案,称为分布式 Muon(Distributed Muon)。分布式 Muon 遵循 ZeRO-1 在数据并行(DP)上对优化器状
态进行划分,并与普通的 ZeRO-1 AdamW 优化器相比引入了两个额外的操作,算法 1 描述了分布式 Muon 的实现。

实验
RMS 的一致性
为了使所有矩阵参数更新的 RMS 值与 AdamW 的 RMS 保持一致,研究团队尝试了两种方法来控制参数更新的 RMS,并将其与只用了 AdamW 的基线的 RMS 进行
了对比。
由于大规模训练模型时,会出现各种意料之外的情况,因此,研究团队测试了 Muon 对训练早期阶段的影响。当矩阵维度差异增大时,更新 RMS 不一致的问题会更
加明显。该团队对模型架构进行了微调,用标准的 2 层 MLP 替换了 Swiglu MLP,并将其矩阵参数的形状从 [H, 2.6H] 改为 [H, 4H]。
团队评估了模型的损失,并监控了关键参数的 RMS,尤其是形状为 [H, H] 的注意力查询权重和形状为 [H, 4H] 的 MLP 权重。

实验结果表明(见表 1),Update Norm 和 Adjusted LR 均优于基线方法,且 Adjusted LR 的计算成本更低,因此被选用于后续实验。
Muon 的 Scaling Law
为了与 AdamW 公平比较,该团队在一系列基于 Llama 架构的模型上对 Muon 进行了拓展。
对于 Muon,由于其 RMS 与 AdamW 匹配,团队直接复用了 AdamW 的超参数。
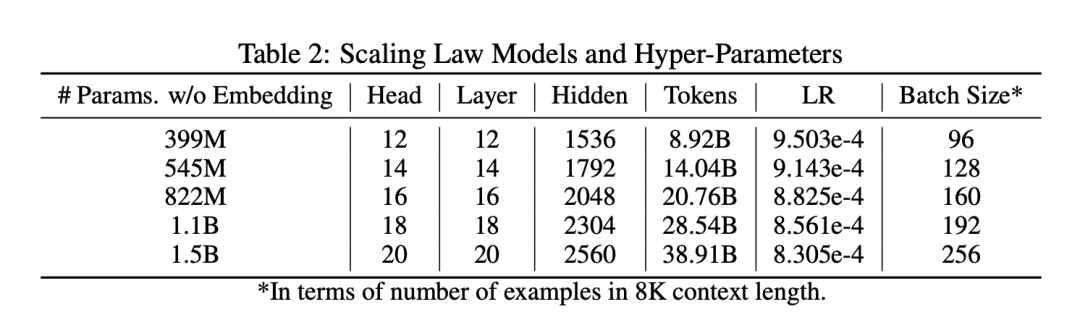
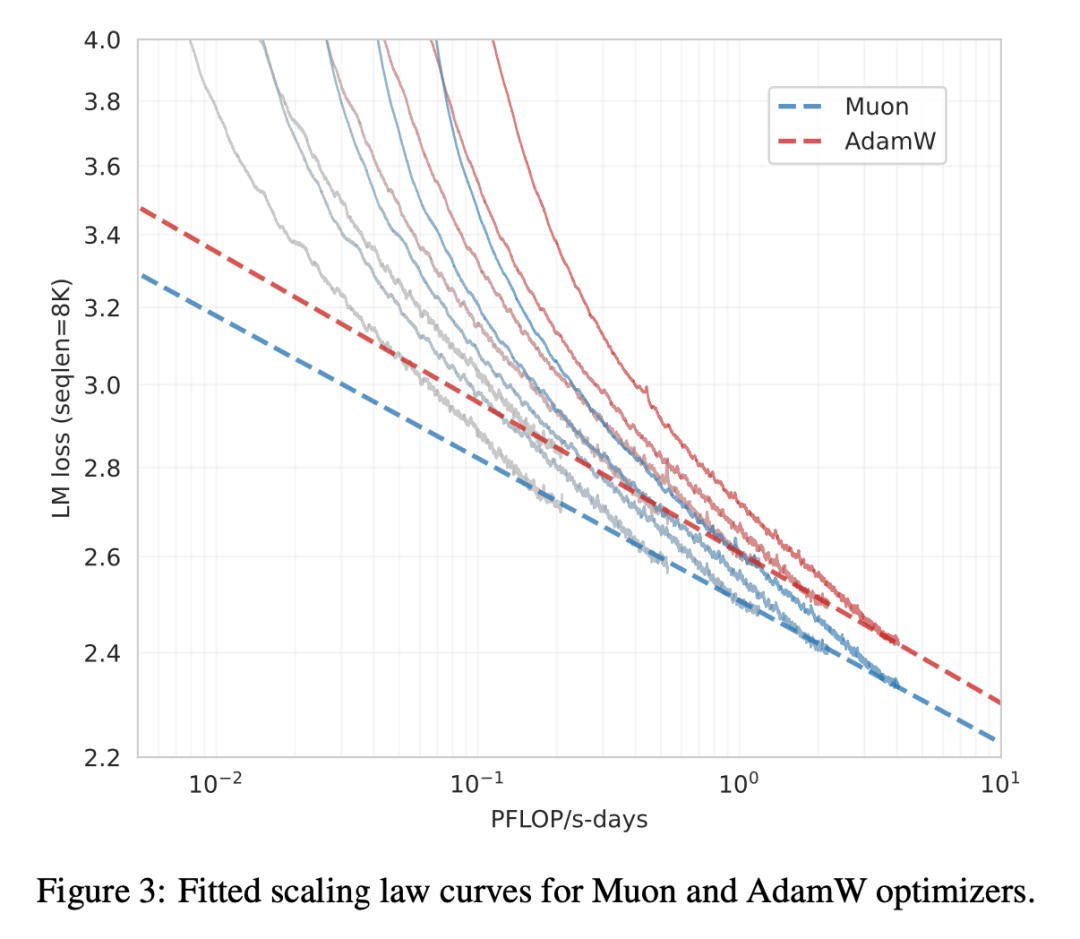
实验结果显示,拟合的 Scaling Law 曲线表明,在计算最优设置下,Muon 仅需约 52% 的训练 FLOPs 即可达到与 AdamW 相当的性能。这进一步说明了 Muon 在大规模语言模型训练中的高效性。
使用 Muon 进行预训练
为了评估 Muon 在模型架构中的表现,该团队使用 DeepSeek-V3-Small 架构从头开始预训练了 Moonlight 模型。
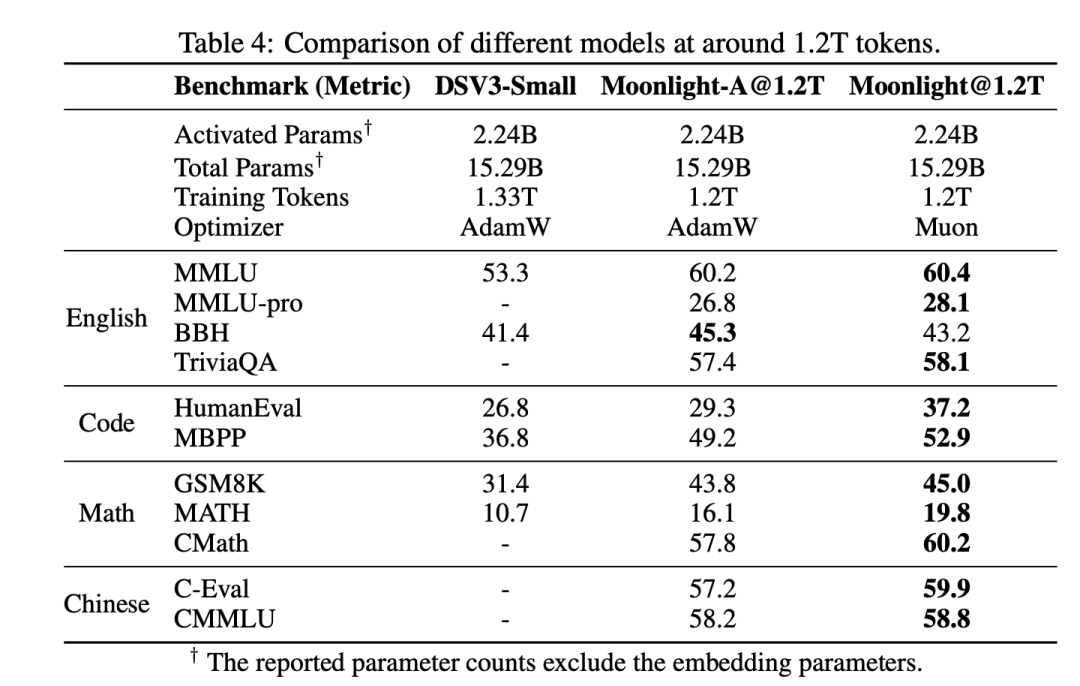
Moonlight 模型总共进行了 5.7 万亿 tokens 的训练,但在训练到 1.2 万亿 tokens 的阶段,团队将其与 DeepSeek-V3-Small(使用 1.33T tokens 训练的 2.4B/16B 参数 MoE 模型)和 Moonlight-A(与 Moonlight 设置相同,但使用 AdamW 优化器)进行了比较。如表 4 所示,Moonlight 在语言、数学和编码等任务上都显著优于 Moonlight-A,证明了 Muon 的扩展优势。
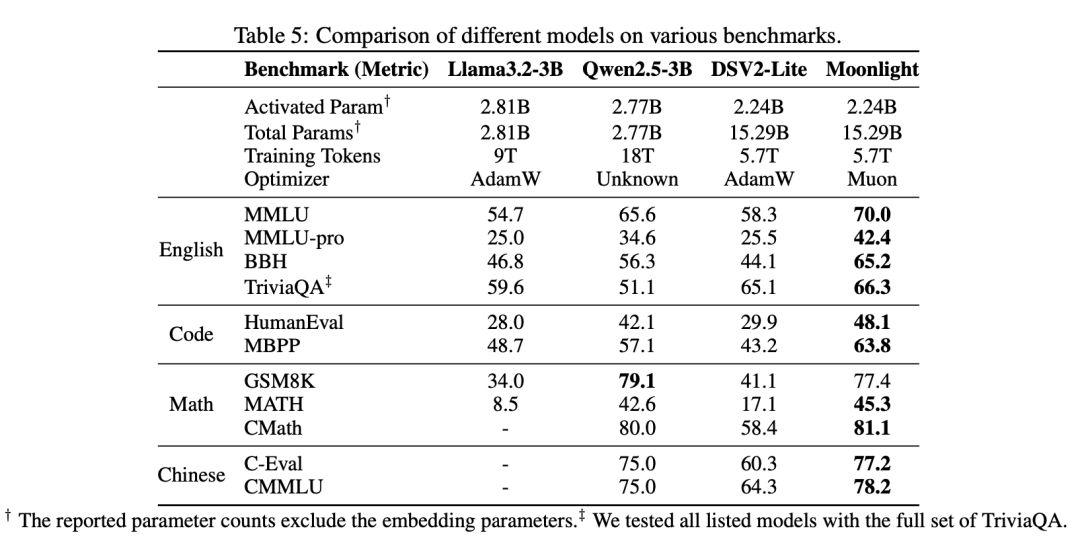
在完整训练后,Moonlight 与类似规模的开源模型(如 LLAMA3-3B、Qwen2.5-3B 和 Deepseek-v2-Lite)进行了比较。结果显示,Moonlight 在性能上优于使用相同
数量 tokens 训练的模型,与更大参数规模模型相比,也较有竞争力。
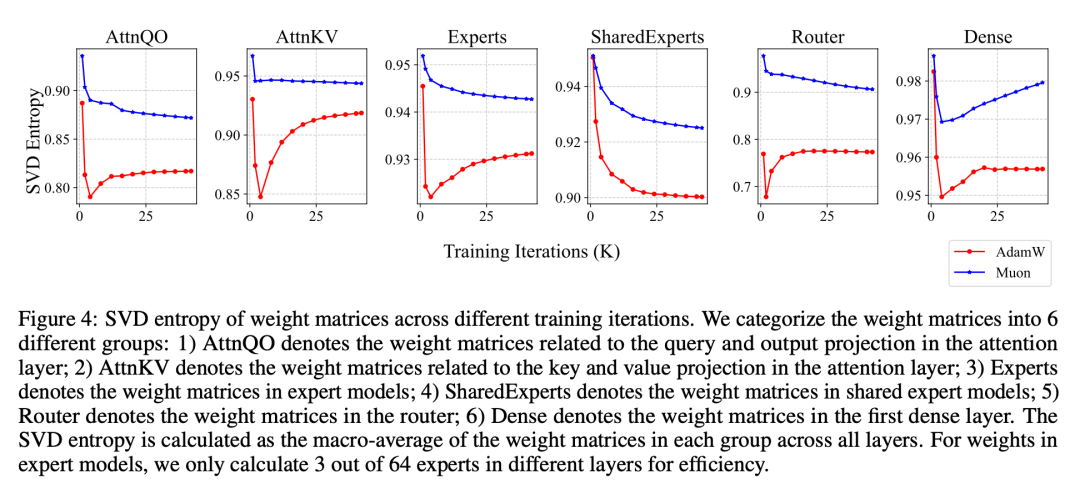
此外,研究团队还发现,Muon 可以让模型的权重更新更「多样化」,尤其在 MoE 模型中表现突出。
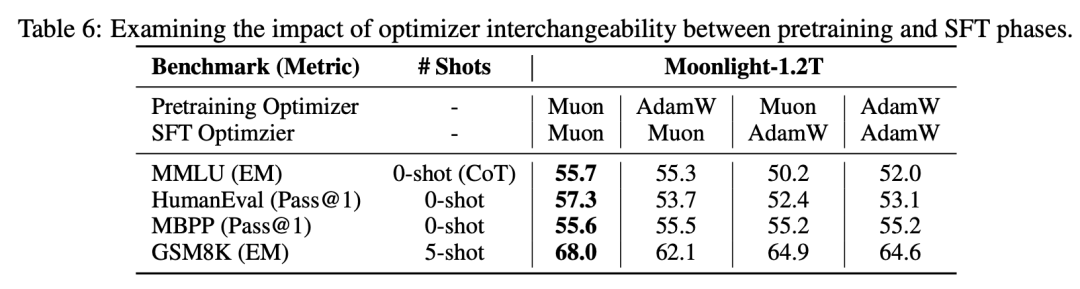
在微调阶段,在预训练和微调阶段都使用 Muon,模型表现会比用 AdamW 的组合更好,但如果微调和预训练的优化器不一致,优势就不明显了。
更多细节,请参阅论文原文。
参考链接:
https://github.com/MoonshotAI/Moonlight?tab=readme-ov-file
https://github.com/MoonshotAI/Moonlight/blob/master/Moonlight.pdf
https://x.com/Kimi_Moonshot/status/1893379158472044623
文章来自于微信公众号 “机器之心”,作者 :陈陈、佳琪

【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

