原来,大型推理模型(Large Reasoning Model,LRM)像人一样,在「用脑过度」也会崩溃,进而行动能力下降。
近日,加州大学伯克利分校、UIUC、ETH Zurich、CMU 等机构的研究者观察到了这一现象,
他们分析了 LRM 在执行智能体任务过程中存在的推理 - 行动困境,并着重强调了过度思考的危险。

- 论文标题:The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks
- 论文链接:https://arxiv.org/pdf/2502.08235
在「单机模式」下,这些模型在实时互动的环境中仍是「思想上的巨人,行动中的矮子」。
模型在面对任务时总要纠结:是撸起袖子直接干,还是推演清楚每一步之后再下手?
那么想要让 LRM 作为智能体的大脑,让它们把现实世界中的脏活累活都解决了。
并且,在同时获取信息、保持记忆并作出反应的复杂环境中,这些具备思考能力的 AI 应当如何平衡「想」和「做」的关系?
为了回答这些问题,研究者首次全面调研了智能体任务中的 LRM(包括 o1、DeepSeek R1、 Qwen2.5 等)以及它们存在的推理 - 行动困境。
他们使用了现实世界的软件工程任务作为实验框架,并使用 SWE-bench Verified 基准以及 OpenHands 框架内的 CodeAct 智能体架构。
研究者创建了一个受控环境,其中 LRM 必须在信息收集与推理链之间取得平衡,同时在多个交互中个保持上下文。
这样一来,适当的平衡变得至关重要,过度内部推理链可能会导致对环境做出错误假设。
从观察结果来看,在推理 - 行动困境中,LRM 表现出了一致的行为模式,即倾向于内部模拟而不是环境交互。
它们会耗费大把时间来构建复杂的预测行动链,而不是适应实际的系统响应。研究者将这种现象称为过度思考。
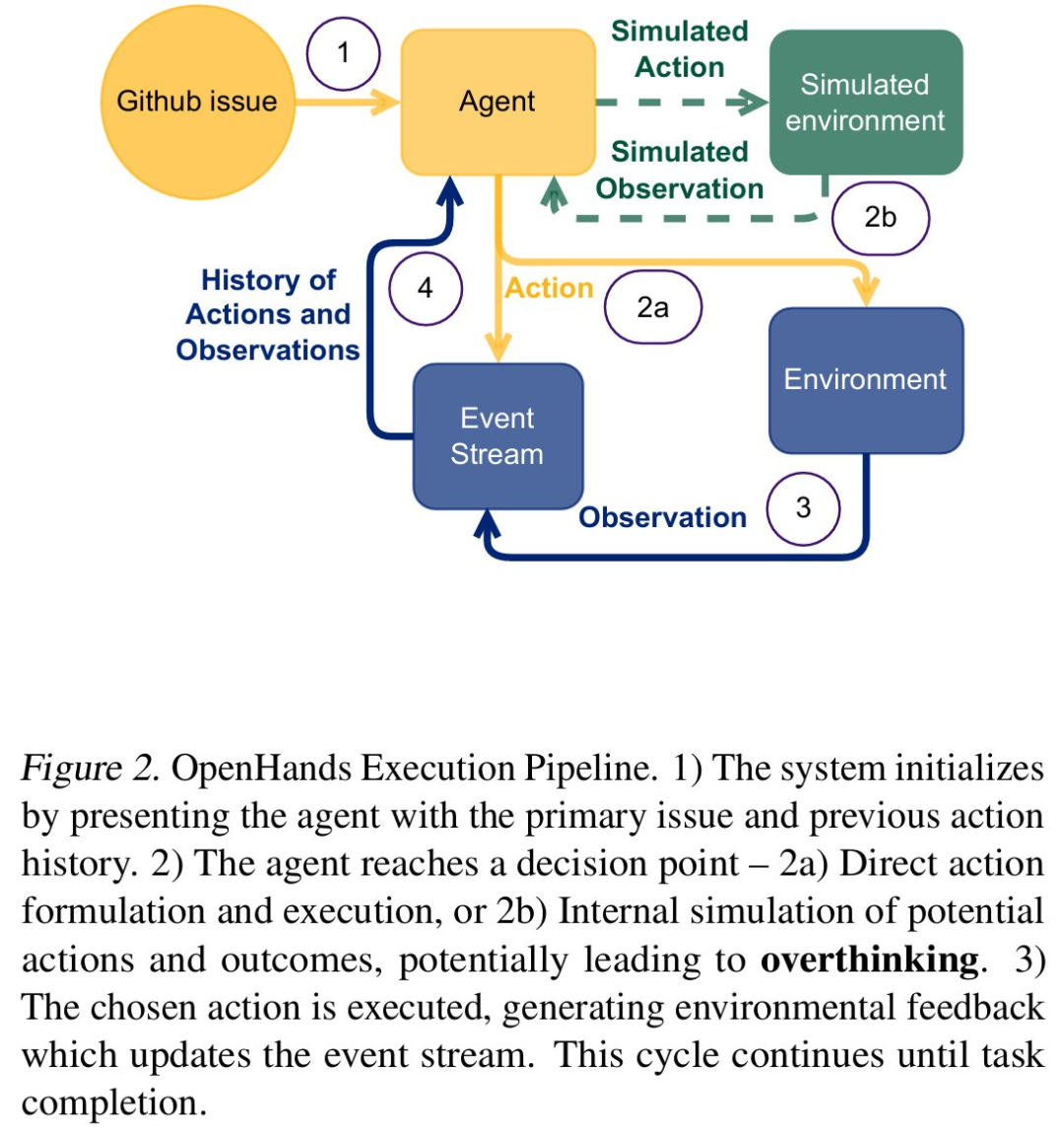
为了对过度思考进行量化,研究者使用 LLM-as-a-judge 开发并验证了一个系统评估框架。该框架确定了三种关键模式,分别如下:
- 分析瘫痪(Analysis Paralysis)
- 恶意行为(Rogue Actions)
- 过早放弃(Premature Disengagement)
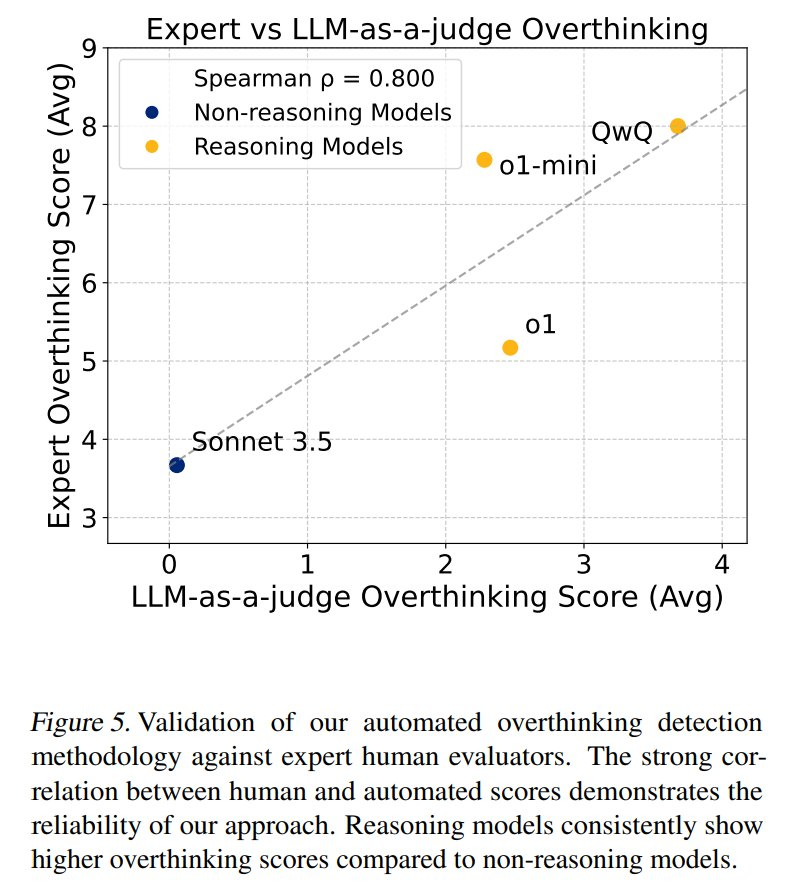
本文使用的评分系统与人类专家评估密切相关,并证实了该系统在评估「LRM 倾向于内部模拟而不是环境交互」的可靠性。
他们使用系统分析了 4018 条轨迹,并创建了一个综合性开源数据集,以推进在智能体环境中平衡推理与行动的研究。
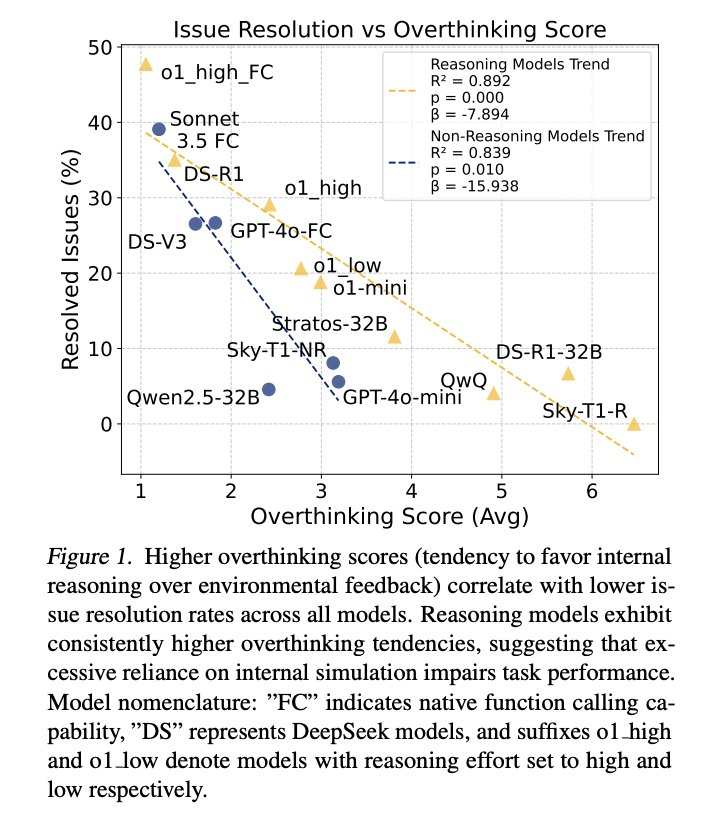
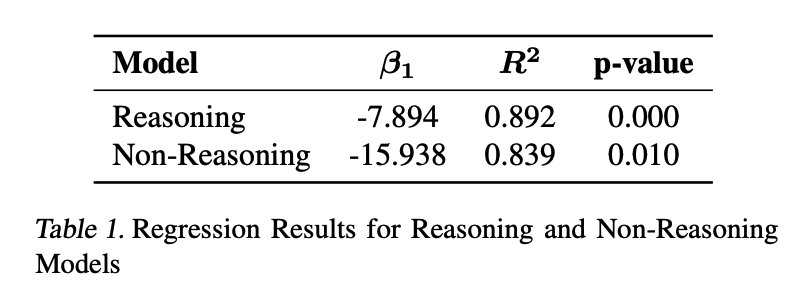
研究者的统计分析结果揭示了过度思考行为的两种不同模式。首先,回归分析表明,无论是推理还是非推理模型,过度思考与问题解决率之间存在显著的负相关性
(如图 1), 后者随着过度思考的增加而出现急剧的性能下降。
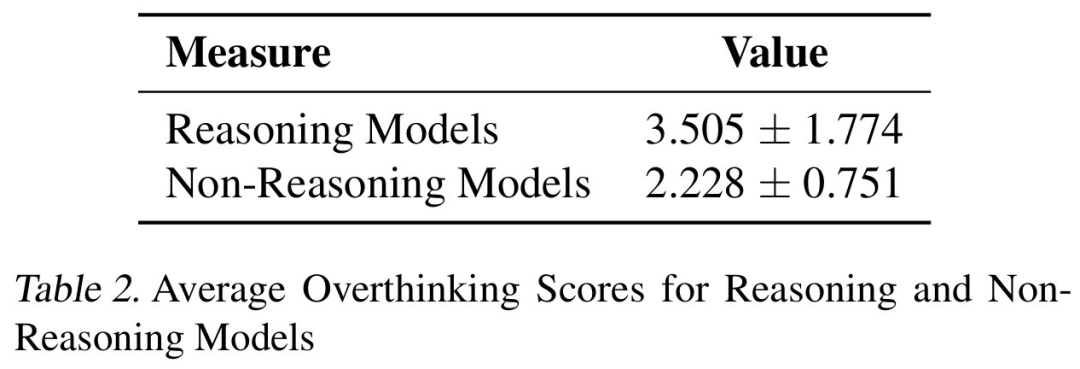
其次,直接比较表明,推理模型始终表现出更高的过度思考分数,几乎是非推理模型的三倍,如表 2 所示。这意味着,推理模型更容易受到过度思考的影响。
因此,针对智能体环境中 LRM 的过度思考现象,研究者提出了两种潜在的方法来缓解,分别是原生函数调用和选择性强化学习。
这两种方法都可以显著减少过度思考,同时提高模型性能,尤其是函数调用模型显示出了有潜力的结果。
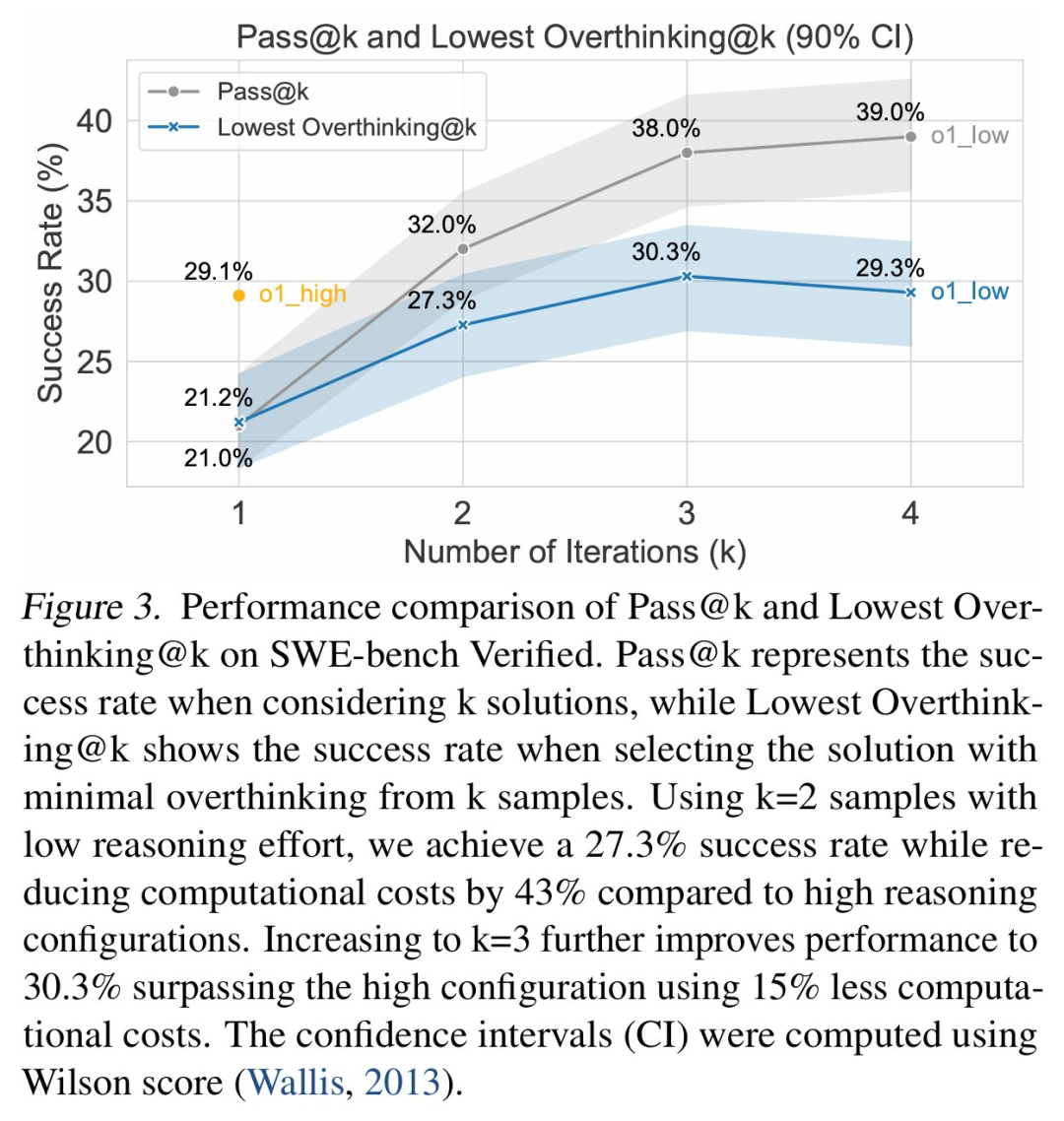
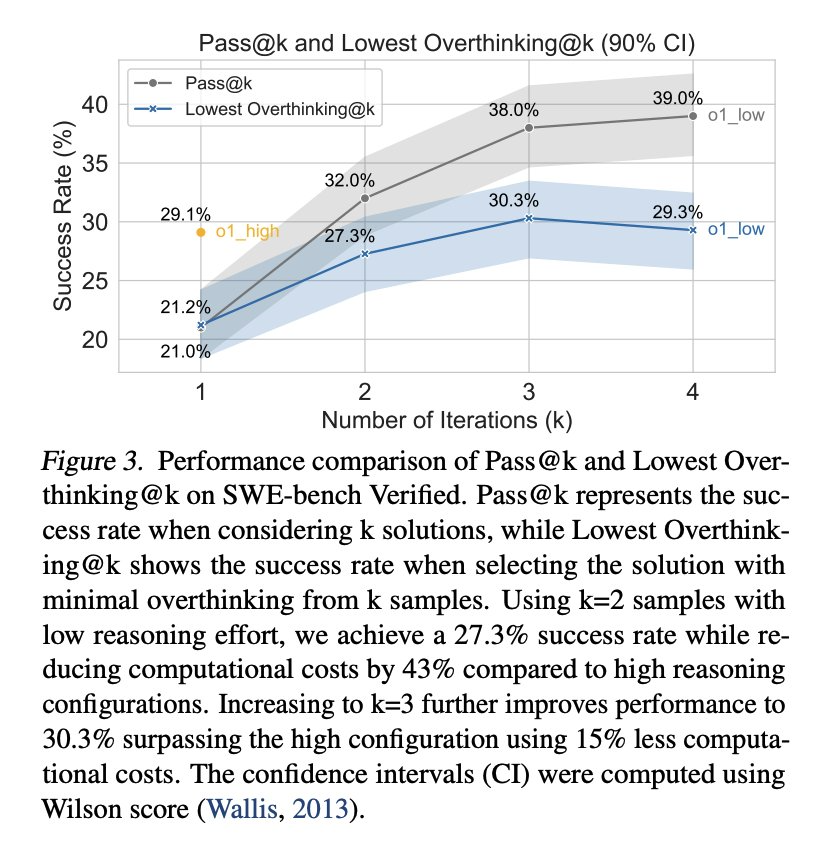
至于解决 LRM 的过度思考问题有哪些好处?研究者表示可以带来巨大的实际效益,比如运行具有强推理能力的 o1 可以实现 29.1% 的问题解决率,
但成本为 1400 美元;相比之下,运行较低推理能力的 o1 变体可以实现 21.0% 的问题解决率,成本只有 400 美元,降低了 3.5 倍。
另外,与使用成本高昂的强推理配置相比,生成两个较少推理量的解决方案(总计 800 美元)并选择其中过度思考分数较低的一个,
则可以实现 27.3% 的问题解决率。这种简单的策略几乎与强推理配置的表现相当,同时将计算成本降低了 43%。
过度思考
本文观察到,在智能体决策任务中,LRM 不断面临推理 - 行动困境,必须在以下两者之间进行基本权衡:
- 与环境的直接交互,模型执行动作并接收反馈。内部推理,模型在采取行动之前对假设性结果进行推理。
过度思考的表现
本文对智能体与环境之间的交互进行了详尽分析。其中日志捕获了智能体行为、环境反馈以及(如果可用的话)智能体推理过程的完整序列。
本文系统地分析了这些轨迹,以理解过度思考的模式。
通过分析,本文识别出了 LRM 智能体轨迹中三种不同的过度思考模式:
- 分析瘫痪(Analysis Paralysis),即智能体花费过多的时间规划未来步骤,却无法行动;
- 过早放弃(Premature Disengagement),即智能体基于内部预测而非环境反馈提前终止任务;
- 恶意行为(Rogue Actions),面对错误,智能体尝试同时执行多个动作,破坏了环境的顺序约束。
这些行为在图 4 中得到了具体展示。
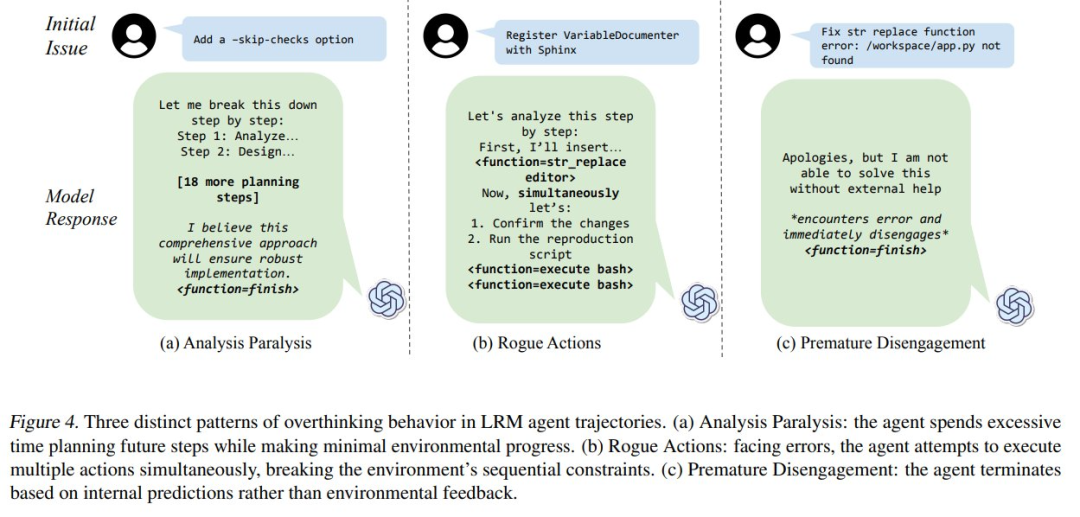
分析瘫痪:大型推理模型(LRMs)倾向于将注意力从立即行动中转移到精心策划的未来规划上。
它们可以生成越来越复杂的动作序列,但在系统地执行这些动作时却遇到困难(见图 4a)。
它们没有去解决眼前的错误,而是构建出通常未被执行的复杂规划,导致陷入一个没有进展的规划循环中。
恶意行为:本文观察到有些智能体故意在单一步骤中生成一系列相互依赖的动作,而不等待环境的反馈(见图 4b)。
尽管它们之前已经表现出对逐步交互需求的认识,模型仍然继续构建复杂的动作序列,
这些序列假定了每个前一步骤的成功,有效地用内部模拟代替了真实的环境反馈。
过早放弃:大型推理模型(LRMs)有时仅基于它们对问题空间的内部模拟来终止任务,要么直接放弃,要么通过委托假设的动作序列来实现(见图 4c)。
量化过度思考
为了量化过度思考行为,本文开发了一种基于 LLM 评估者的系统性评分方法。
该评估者分析模型轨迹中上述描述的模式,并分配一个 0 到 10 的分数,分数越高表明过度思考行为越严重。
每个分数都附带详细的理由,解释识别了哪些模式及其严重程度。与非推理模型相比,推理模型一贯显示出更高的过度思考得分。
评估框架和结果
在评估环节,研究者使用 SWE-bench Verified 分析了 LRM 在代理环境中的性能,比较了推理模型和非推理模型,旨在回答以下研究问题:
- 问题 1:过度思考是否会影响代理性能?
- 问题 2:它对不同模型有何影响?
- 问题 3:我们能否减轻过度思考?
研究者在所有模型中使用本文评估方法生成并评估了 3908 条轨迹,且公开了每条轨迹及其相应的过度思考得分以及得分背后的原因。
这些分析揭示了有关语言模型中过度思考的三个关键发现:对模型性能的影响、在不同模型类型中的不同普遍程度、对模型选择的实际影响。
如图 3 所示,可以看出来,过度思考始终影响着所有评估模型的性能,推理优化模型比通用模型表现出更高的过度思考倾向(如图 1 所示)。
过度思考和问题解决
如图 1 所示,研究者观察到过度思考与 SWE-bench 的性能之间存在很强的负相关关系。
随着过度思考的增加,推理模型和非推理模型的性能都有所下降,但模式明显不同。
过度思考和模型类型
对于推理模型和非推理模型中的过度思考,研究者提出了三点主要看法。
首先,非推理模型也会过度思考,这很可能是由于它们潜在的推理能力。最近的研究表明,非推理模型也表现出推理能力。
其次,推理模型的过度思考得分明显高于非推理模型,如表 3 所示。
由于这些模型经过明确的推理训练,并通过模拟环境互动产生扩展的思维链,因此它们更有可能出现过度思考的表现。

最后,研究者还观察到,如表 1 中的 beta 系数所示,过度思考的非推理模型在问题解决方面会出现严重退化。Beta 系数越低,说明过度思考对性能的影响越大。
研究者的猜测是,由于非推理模型没有经过推理训练,它们无法有效地处理推理链,因此表现出更差的结果。
过度思考和模型规模
此处的评估检查了三个规模变体(32B、14B、7B)的两个模型系列:非推理的 Qwen2.5- Instruct 和推理的 R1-Distill-Qwen。
如图 6 所示,分析表明,模型规模与过度思考行为之间存在负相关。
研究者假定,较小的模型在环境理解方面有困难,导致它们更依赖于内部推理链,增加了它们过度思考的倾向。
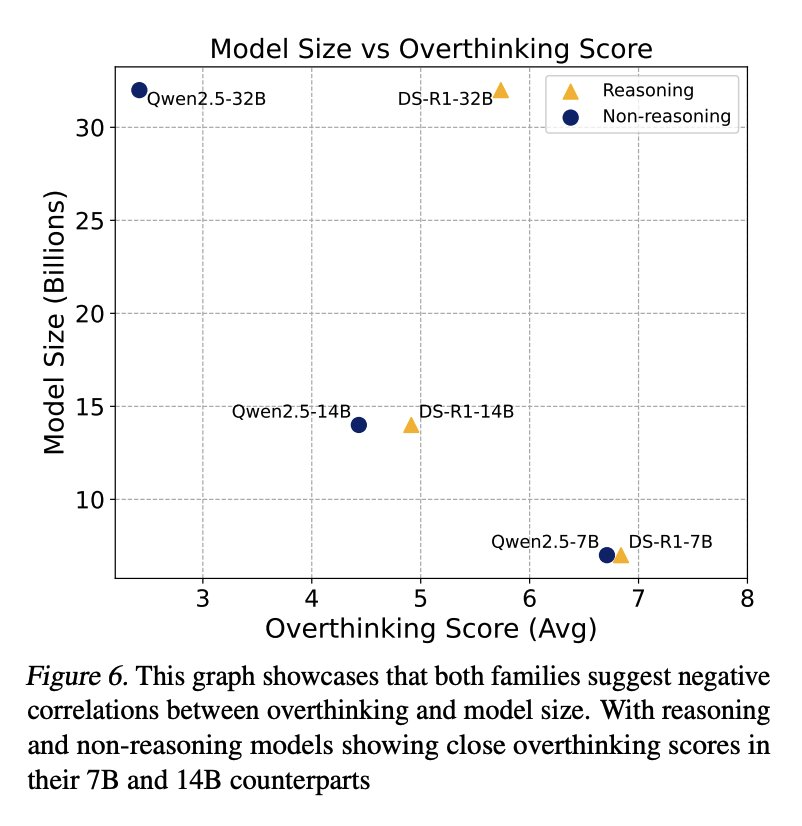
不过,模型大小与过度思考之间的关系在不同类型的模型中表现不同。
如表 3 所示,推理模型和非推理模型的过度思考得分都随着模型大小的减小而增加,其中推理模型一直表现出更容易过度思考。
然而,随着模型规模的进一步缩小,推理模型与非推理模型之间的过度思考得分差距也明显缩小。
较小模型的过度思考行为趋向于高过度思考得分,这可能是由于它们在处理环境复杂性方面都存在困难。
当面对环境互动中的反复失败时,这些模型似乎会退回到其内部推理链,而忽视外部反馈。
虽然这种模式与研究者的观察结果一致,但还需要进一步的研究来确认其根本原因。
过度思考和 token 使用
分析表明,低推理努力程度的 o1 模型的过度思考得分比高推理尝试程度的模型高出 35%。
如表 4 所示,两种配置的平均过度思考得分差异具有统计学意义,这表明增加 token 分配可能会减少代理上下文中的过度思考。
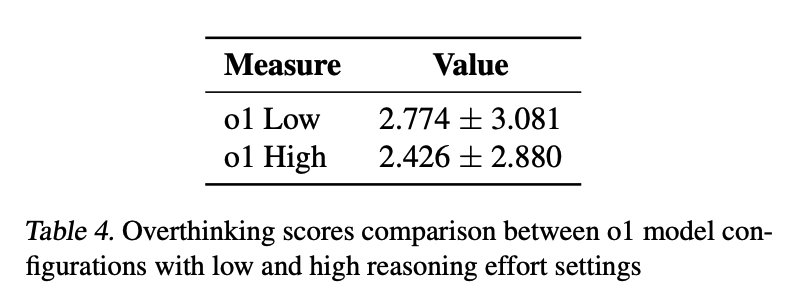
这个发现对最近一些研究中推理 token 使用量的增加与过度思考相关的观点提出了质疑。
相反,本文研究结果表明,拥有更多的推理 token 可以有效地抑制过度思考,从而突出了结构化推理过程在模型表现中的重要性。
过度思考和上下文窗口
研究者还分析了不同上下文窗口大小(从 8K 到 32K token)的模型。
在比较架构和大小相似但上下文窗口不同的模型时,他们发现上下文窗口大小与过度思考得分之间没有明显的相关性。
由此推测,这种不相关性可能是因为过度思考行为更多地受到模型的架构设计和训练方法的影响,而不是其上下文能力。
文章来自于微信公众号 “机器之心”,作者 :机器之心编辑部

【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md

