全面评估大模型电商领域能力,首个聚焦电商基础概念的可扩展问答基准来了!
ChineseEcomQA,来自淘天集团。
此前,大模型常因生成事实性错误信息而受限,而传统基准又难以兼顾电商任务的多样性与领域特殊性。
但随着大模型在电商领域的广泛应用,如何精准评估其对专业领域知识的掌握成为关键挑战。
为此,ChineseEcomQA针对性进行了3大核心设计:
- 基础概念覆盖:覆盖20大行业,聚焦10类核心电商概念(如行业分类、品牌属性、用户意图等),包含1800组高质量问答,适配多样电商任务;
2.混合数据构建:融合LLM生成、检索增强(RAG)与人工标注,确保数据质量与领域专业性;
3.平衡评估维度:兼顾行业通用性与专业性,支持精准领域能力验证。

ChineseEcomQA构建流程
从电子商务基本元素(用户行为、商品信息等)出发,团队总结出电子商务概念的主要类型。
最终定义了从基础概念到高级概念的10个子概念(具体详见论文):
行业分类、行业概念、类别概念、品牌概念、属性概念、口语概念、意图概念、评论概念、相关性概念、个性化概念。

然后,研究人员采用混合的数据集构建过程,结合LLM验证、RAG验证和严格的人工标注,确保基准符合三个核心特性:
- 专注基础概念
- 电商知识通用性
- 电商知识专业性
具体来说,构建ChineseEcomQA主要分为自动化问答对生成和质量验证两个阶段。
第一阶段,问答对生成。
研究者收集了大量知识丰富且涵盖各种相关概念的电子商务语料库。
然后,提示大模型(GPT-4o)根据给定的内容忠实地生成问答对;对于比较开放的问题,要求大模型同时提供非常混乱和困难的候选答案。
从而自动化地构建出大量问答对作为初始评测集。
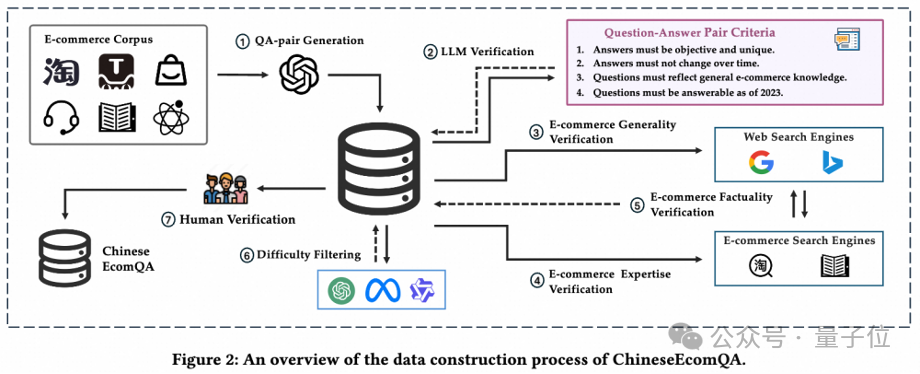
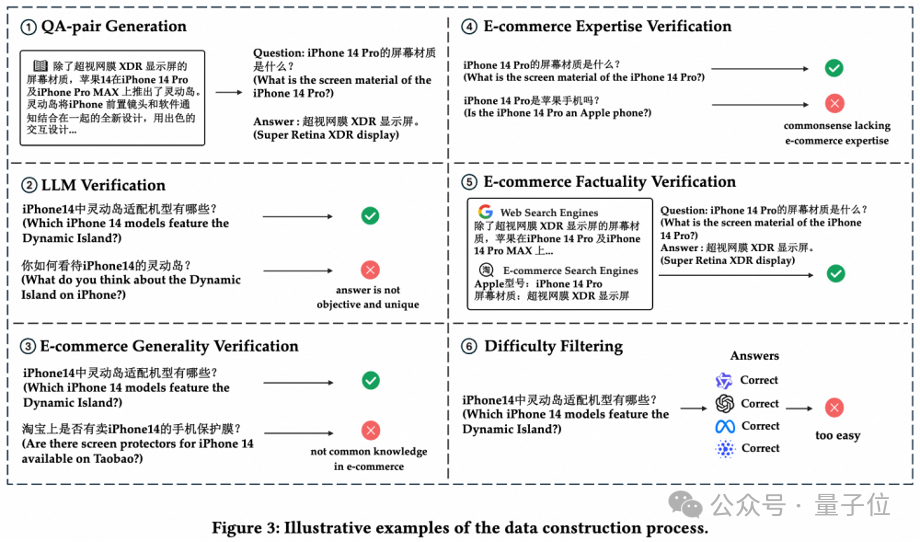
第二阶段,质量验证。
我们开发了一个多轮自动化流程对生成的问答对进行验证,重新生成或过滤不符合标准的问题。
具体包括大模型验证、电子商务通用知识验证、电子商务专业知识验证、电子商务事实性验证、难度筛选、人工验证。
经过多重严格筛选,最终得到均匀覆盖10大类电商子概念的1800条高质量问答对作为终版数据集。
DeepSeek-R1和V3表现最佳
评估了11个闭源模型和16个开源模型,得出如下排名榜:
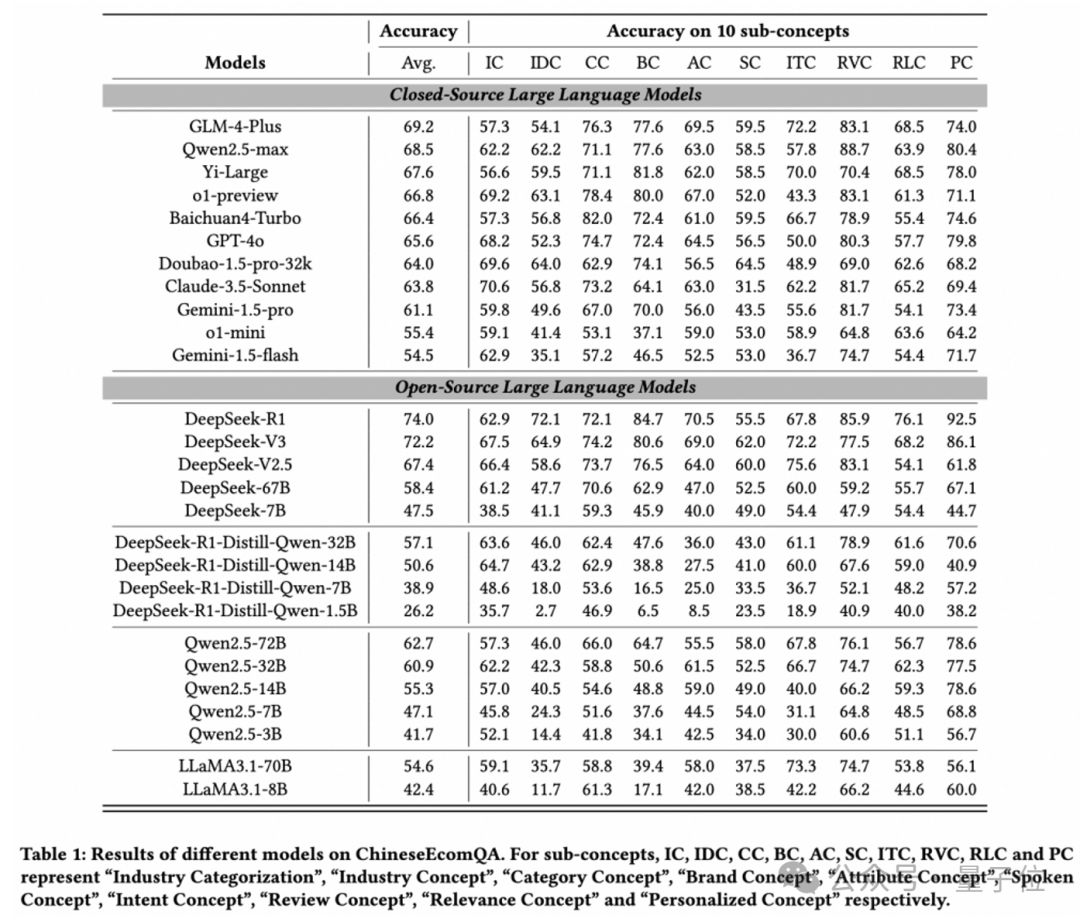
(注:对于子概念,IC、IDC、CC、BC、AC、SC、ITC、RVC、RLC 和 PC 分别代表“行业分类”“行业概念”“类别概念”“品牌概念”“属性概念”“口语概念”“意图概念”
“评论概念”“相关性概念”和“个性化概念”)
总的来看,DeepSeek-R1和DeepSeek-V3是表现最好的模型,展示了强大的基础模型(推理模型)在电子商务领域的巨大潜力。
此外,研究团队对主流模型表现分析并得出了以下发现:
- 更大的模型在高级电商概念上表现更好,遵循Scaling Law,但小模型在特定电商任务上仍面临显著挑战。
- 中文社区模型(如Qwen系列、GLM-4)在电商场景适应性上表现突出,尤其是在高级电子商务概念上。
虽然O1-preview在基本概念上表现更好,但在更高级的概念上面临困难。
- 某些类型的电子商务概念(如相关性概念)仍然对 LLM 构成重大挑战。
大参数量模型由于其强大的通用能力,可以泛化到电商任务上,而小参数量模型则更有困难。这些特点体现了专门开发电商领域模型的必要性。
- Deepseek-R1-Distill-Qwen系列的表现不如原始的Qwen系列,主要原因是在推理过程中引入知识点错误,进而导致最终结论出错。
- 开源模型和闭源模型之间的性能差距很小。以Deepseek为代表的开源模型使二者达到了相似的水平。
- 通过引入RAG策略,模型的性能显著提升,缩小了不同模型之间的性能差距。
- LLM的自我评估能力(校准)在不同模型中存在差异,更大的模型通常表现出更好的校准能力。
- Reasoning LLM需警惕“思维链中的事实性错误累积”,尤其是蒸馏模型。
同时,团队还在ChineseEcomQA上探索了模型校准、RAG、推理模型思维过程等热门研究课题(具体详见论文)。
模型往往对回答“过于自信”
一个完美校准的模型应该表现出与其预测准确度一致的置信度。
ChineseEcomQA团队通过提示模型在回答问题的同时给出其对回答内容的置信度(范围0到100),探索模型的事实准确性与置信度之间的关系。
结果显示,o1-preview表现出最佳对齐性能,其次是o1-mini。
然而,大多数模型始终低于完美对齐线,表明模型普遍存在过度自信的趋势。
这凸显了改进大型语言模型校准以减轻过度自信产生错误响应的巨大空间。
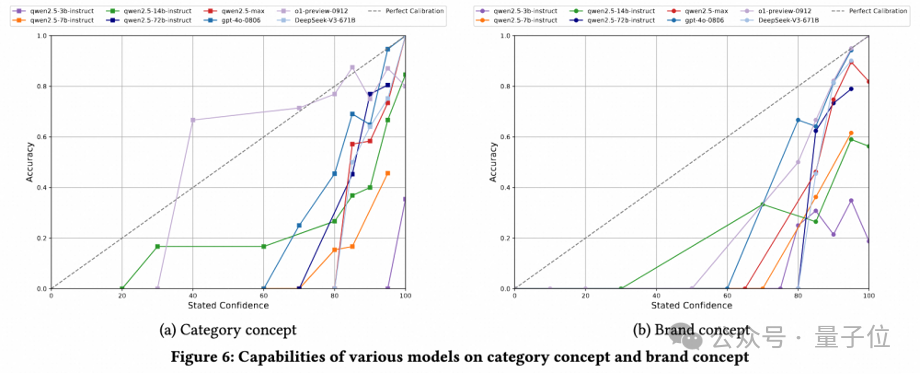
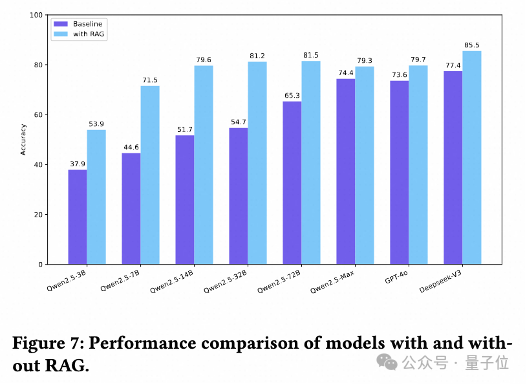
RAG仍是快速提升模型能力的捷径
研究过程中,团队探讨了RAG策略在ChineseEcomQA数据集上增强LLM领域知识的有效性。
具体来说,研究者在类别概念和品牌概念上的设置重现了一个RAG系统。
结果显示,所有模型都通过RAG都得到了显著提升。研究人员总结出三个详细的结论。
第一,对于小型LLM,引入RAG信息可以显著提高评估指标的绝对值。
例如,Qwen2.5-14B实现了27.9%的改进。
第二,对于大型LLM,RAG也可以实现显著的相对改进。
例如,DeepSeek-V3的平均相对改进达到了10.44%(准确率从77.4提高到85.5)。
第三,在RAG设置下,模型之间的性能仍然遵循缩放规律,但差距迅速缩小。
例如,Deepseek-V3和Qwen2.5-72B之间的准确率差异从12.1%缩小到 4%。
总之,RAG仍是增强LLM电子商务知识的有效方法。
警惕“思维链中的事实性错误累积”
在主要结果中,Deepseek-R1取得了最佳结果,充分展示了Reasoning LLM在开放领域中的潜力。
然而,在从Deepseek-R1蒸馏出的Qwen系列模型上,准确率明显低于预期。
由于开源Reasoning LLM揭示了它们的思维过程,研究者进一步调查其错误的原因,并将推理模型的思维过程分为以下四种类型:
- Type A:Reasoning LLM通过自我反思反复确认正确答案。
- Type B:Reasoning LLM最初犯了错误,但通过自我反思纠正了错误。
- Type C:Reasoning LLM通过自我反思引入知识错误,导致原本可能正确的答案被修改为不正确的答案。
- Type D:Reasoning LLM反复自我反思。虽然最终得出了答案,但并没有通过反思获得高度确定和自信的答案。
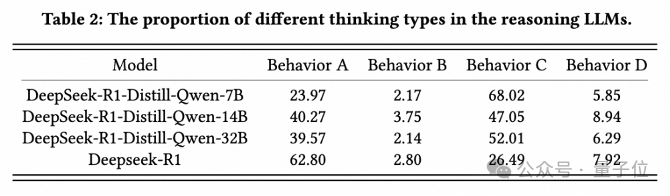
总体而言,Type A和Type B是通过扩大test-time计算量获得的推理能力;Type C和Type D是肤浅的自我反思,导致最终答案不正确。
由于Deepseek-R1强大的buase模型能力表现出更好的泛化能力。
相比之下,在某些特定领域蒸馏的DeepSeek-R1-Distill-Qwen系列似乎在肤浅的自我反思方面遇到了困难。中间推理步骤中事实错误的积累增加了整体错误率。
对于较小的推理LLM,开放领域的推理能力不能直接通过数理逻辑能力来泛化,需要找到更好的方法来提高它们的性能。
One More Thing
该论文核心作者包括陈海斌,吕康滔,袁愈锦,苏文博,研究团队来自淘天集团算法技术 - 未来生活实验室。
该实验室聚焦大模型、多模态等AI技术方向,致力于打造大模型相关基础算法、模型能力和各类AI Native应用,引领 AI 在生活消费领域的技术创新。
淘天集团算法技术 - 未来生活实验室团队将持续更新和维护数据集及评测榜单,欢迎广大研究者使用我们的评测集进行实验和研究~
论文链接:
https://arxiv.org/abs/2502.20196
项目主页:
https://openstellarteam.github.io/ChineseEcomQA/
代码仓库:
https://github.com/OpenStellarTeam/ChineseEcomQA
数据集下载:
https://huggingface.co/datasets/OpenStellarTeam/Chinese-EcomQA
文章来自于微信公众号 “量子位”,作者 :淘天未来生活实验室

【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/

