第一作者为哈尔滨工业大学(深圳)博士生王霄和华为大模型研究员佀庆一,该工作完成于王霄在华为实习期间。
王霄的研究方向为多模态视频理解和生成,佀庆一的研究方向为多模态理解、LLM post-training和高效推理。
随着视频内容的重要性日益提升,如何处理理解长视频成为多模态大模型面临的关键挑战。
长视频理解能力,对于智慧安防、智能体的长期记忆以及多模态深度思考能力有着重要价值。
华为与哈尔滨工业大学(深圳)联合提出了一个全新的长视频理解框架 ——AdaReTaKe(Adaptively Reducing Temporal and Knowledge redundancy)。
无需训练,该框架通过在推理时动态压缩视频冗余信息,使多模态大模型能够处理长度提升至原来的 8 倍(高达 2048 帧),
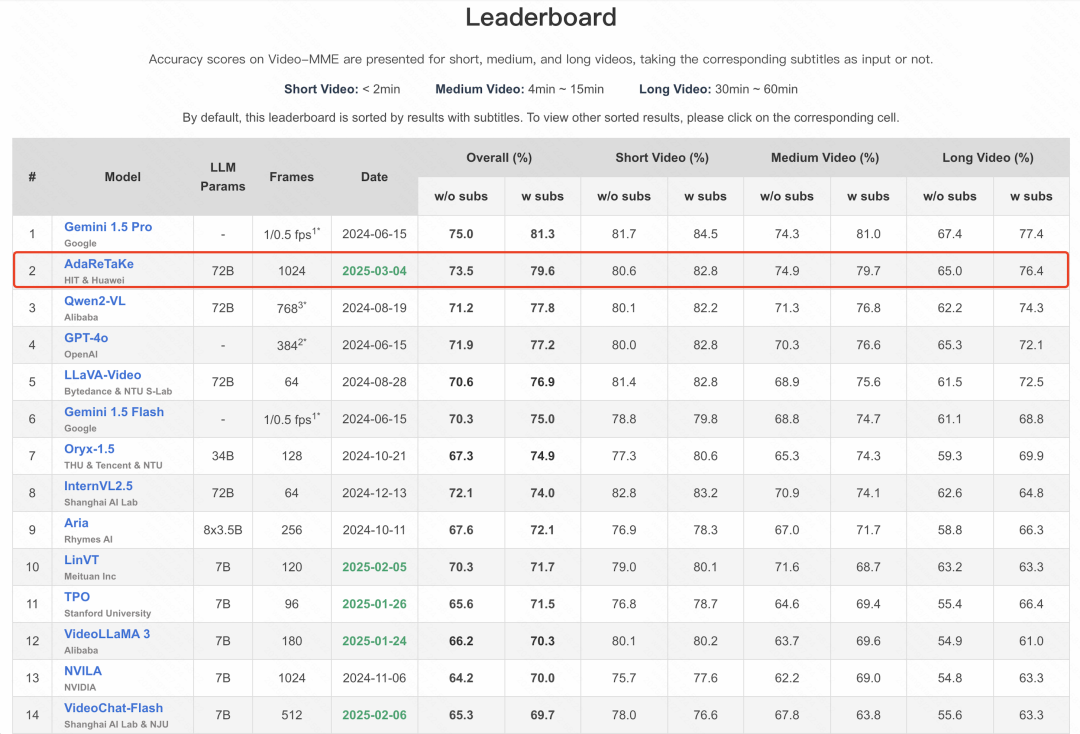
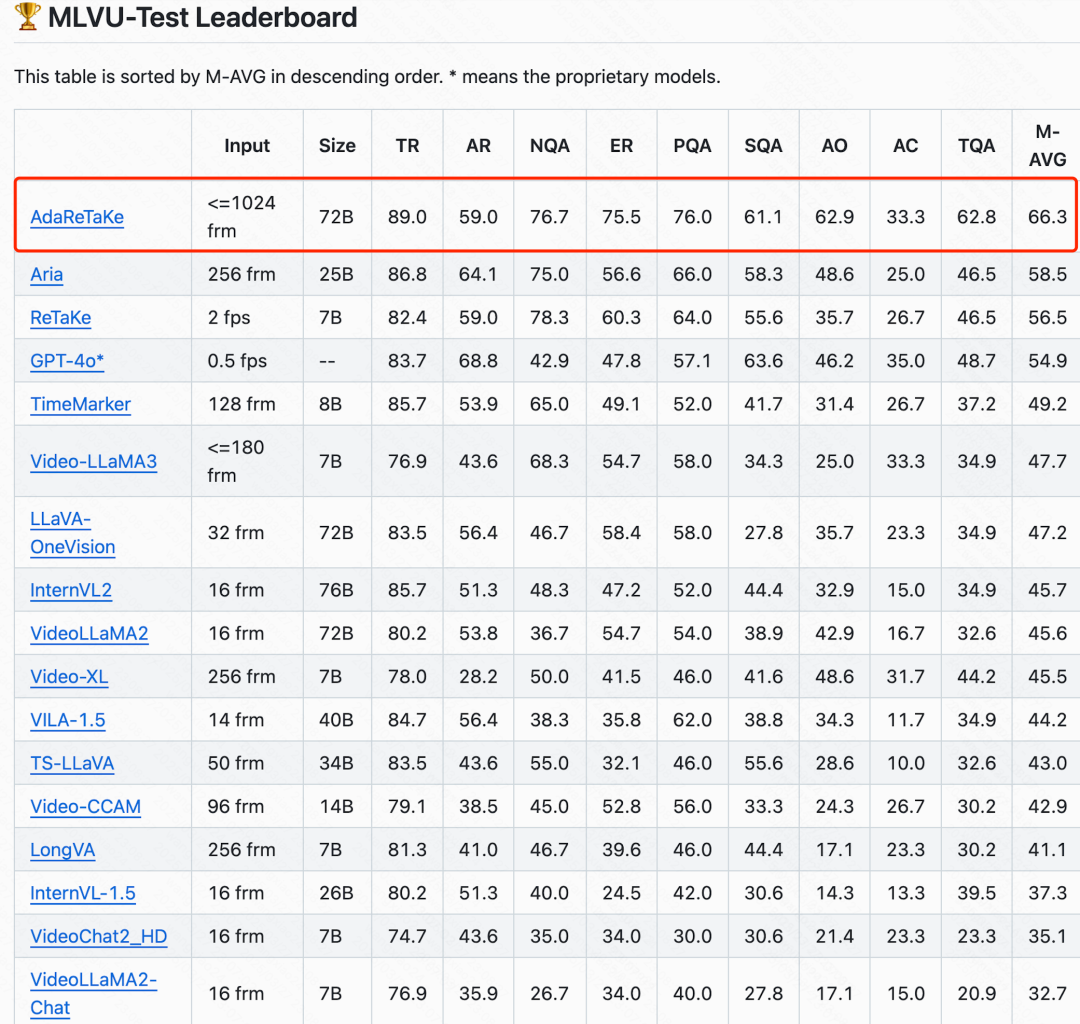
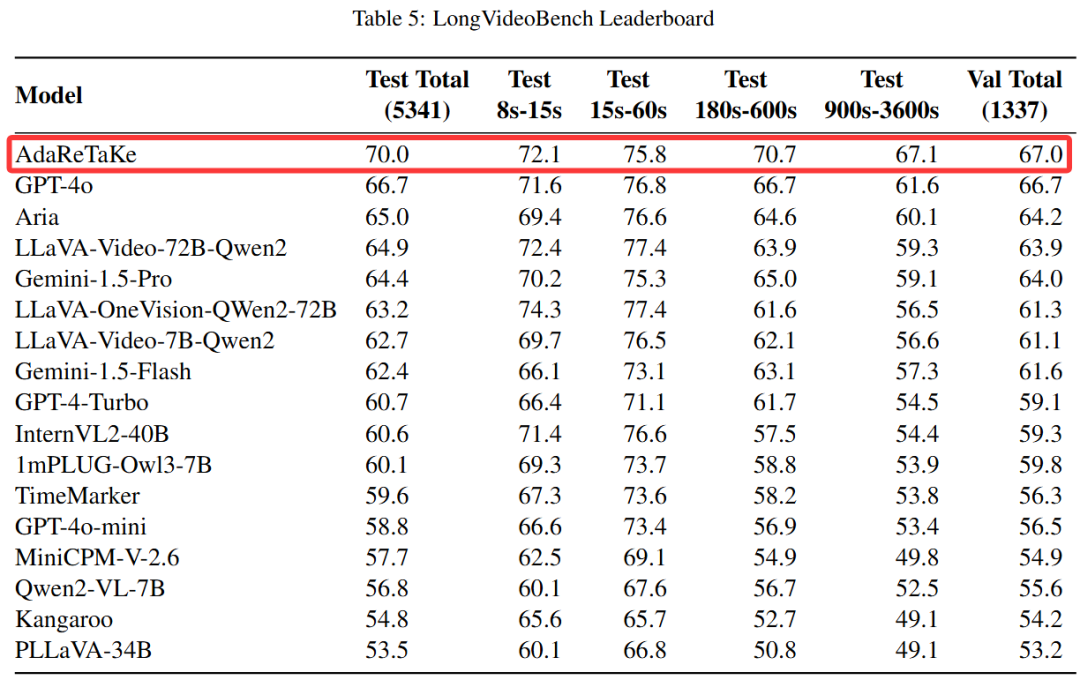
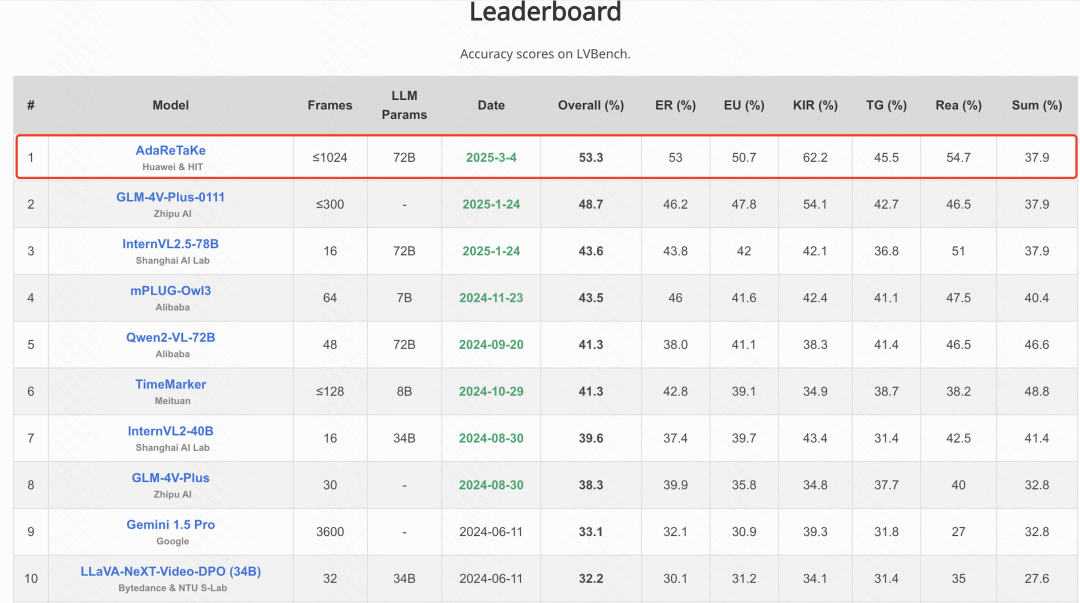
在多个基准测试中超越同规模模型 3-5%,位列 VideoMME、MLVU、LongVideoBench 和 LVBench 四个长视频理解榜单开源模型第一,
为长视频理解设立了新标杆。
- 论文标题:AdaReTaKe: Adaptive Redundancy Reduction to Perceive Longer for Video-language Understanding
- 论文链接:https://arxiv.org/abs/2503.12559 开源代码:https://github.com/SCZwangxiao/video-FlexReduc.git
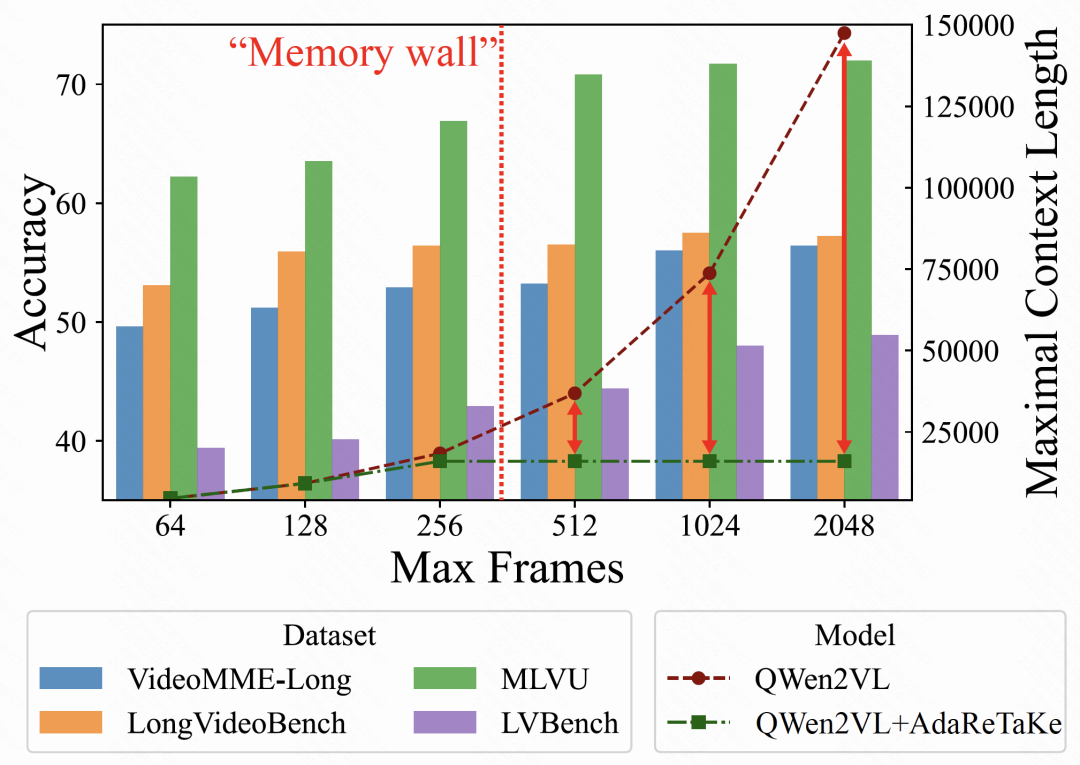
下图展示了 AdaReTaKe 的效果。在单卡 A100 上基于 QWen2VL 实验,AdaReTaKe 将输入视频 context length 压缩固定的 16K,
进而将所能处理的最大帧数由 256 提升至 2048,持续地提升多个 benchmark 上的表现。
在 AdaReTaKe 的 Github 仓库中可以发现其使用方法比较简洁,
只需要对 transformers 导入的模型进行简单的 patch 即可,支持 QWen2VL、QWen2.5VL、LLaVA-OneVision 等多种多模态理解模型。
接下来,将从前言、设计思路、方法以及实验效果四个方面介绍 AdaReTaKe。
前言
随着多模态大模型需要处理的序列长度越来越长,其显存开销的大头越来越趋向于被 KV Cache [1] 占据。
为了减少显存开销,从而处理更长视频以获得更多有效信息,现有方法主要采用视觉序列压缩技术,基于 Attention 的稀疏性质,
通过删除、合并冗余 token 减少序列长度。但是已有方法未能充分挖掘视觉稀疏程度在视频时序上、大模型层间的不一致性。
设计思路
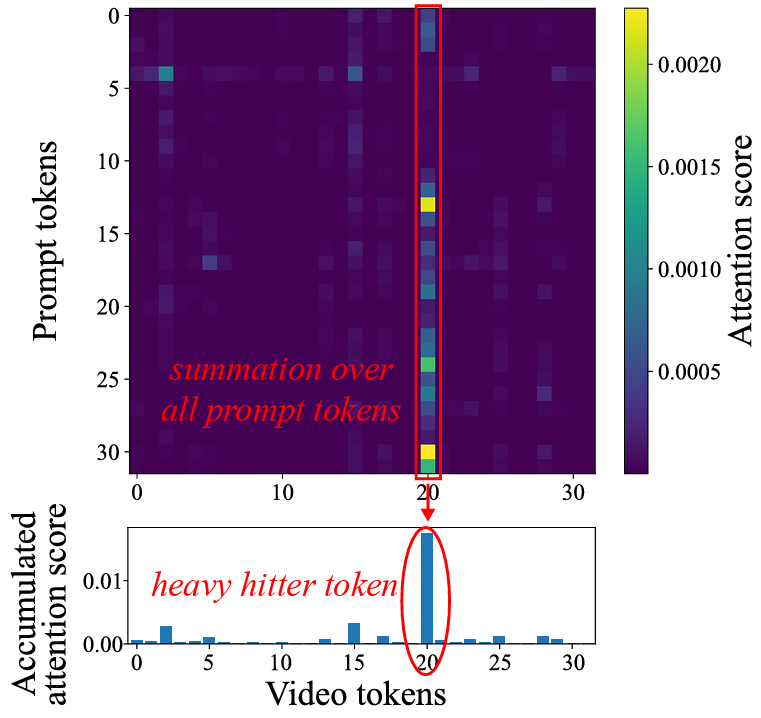
- 大多数视觉序列压缩技术的核心是寻找 attention 过程中的 Heavy Hitter [2]。即最收到 prompt 关注的多个视觉 token,如下图所示。
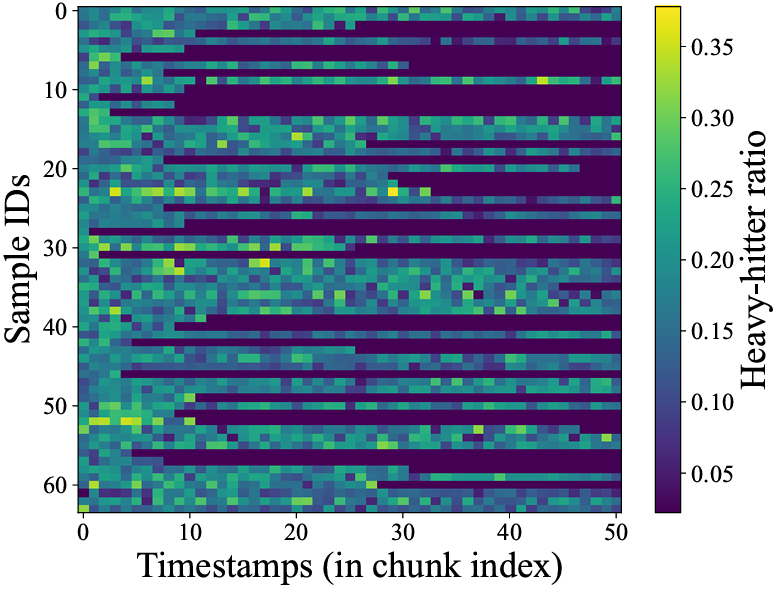
- Heavy Hitter 在视频时序上分布不均匀。
如下图所示,研究团队对 VideoMME 上随机采样的 64 个视频实验发现,时序上 Heavy Hitter 密度差距最多可以达到 7 倍。
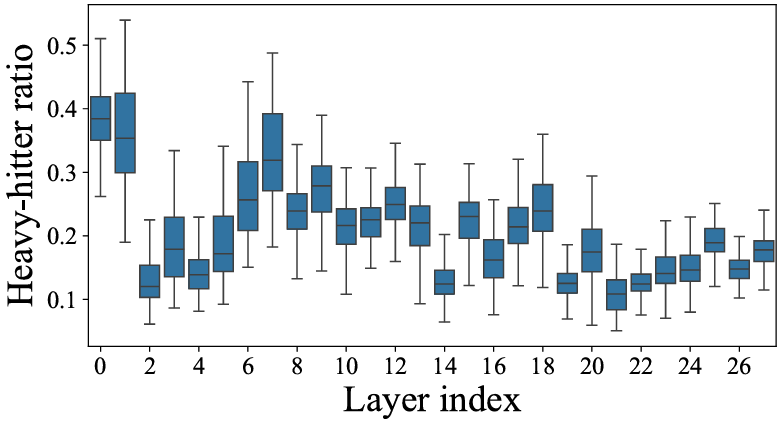
- Heavy Hitter 在大模型层间分布不均匀。
如下图所示,研究团队对 VideoMME 全量视频实验发现,大模型不同层之间 Heavy Hitter 密度差距最多可以达到 4 倍,且这种密度差异并非单调变化。
基于上述发现,团队设计了 AdaReTaKe 方法,
赋能视频大模型在相同的计算资源和上下文窗口下尽可能多的放入更有信息量的信息,从而实现对更长序列的理解和更多细节的捕捉。具体方法如下:
方法
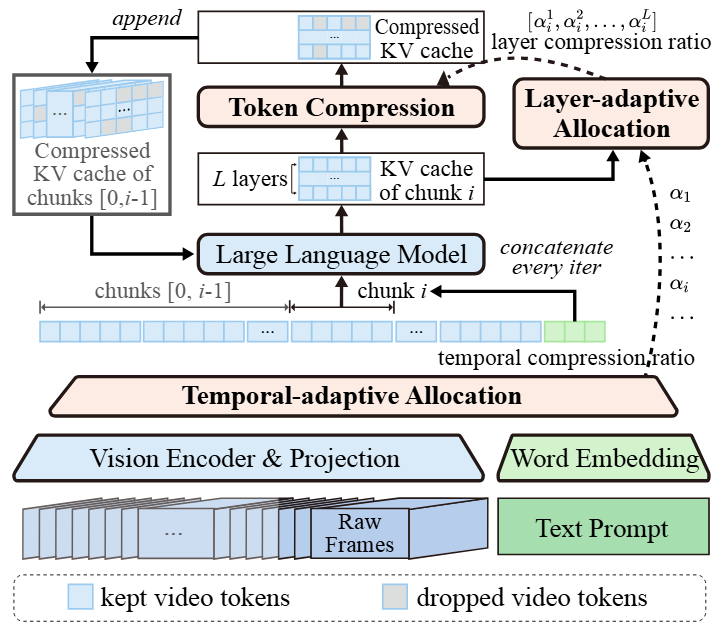
AdaReTaKe 框架图
ReTaKe 系列的核心有两个方面,其一是大模型视频序列分块压缩方法(来自 ReTaKe),
其二是动态压缩率分配方法(AdaReTaKe),根据时间与模型层间冗余性差异动态分配压缩率。
大模型视频序列分块压缩方法
大模型视频序列分块压缩方法首先将视频帧分割成若干个包含 τ 帧的块,
通过视觉编码器和投影层提取每块的特征,并根据最大上下文长度 为每个块分配一个基于其内容的压缩比率,确保最终序列长度不超过 。
然后,将每个块依次输入大模型进行预填充。每一个分块预填充(chunk prefilling)结束后,压缩其对应的 KV cache,
从而在减少冗余的同时保持重要细节,提高长视频序列处理能力。
基于视频时间与模型层间冗余性的压缩率分配
1. 时间自适应分配
将长视频分块,根据相邻帧相似度动态分配压缩比。静态片段高压缩,动态片段保留更多细节。
2. 层次自适应分配
不同模型层关注不同抽象特征(如浅层纹理、深层语义),通过注意力分数调整各层压缩比率,避免 “一刀切” 策略。
3. 理论保障
提出压缩损失上界理论,确保动态分配策略接近最优解,信息保留最大化。
实验结果分析
基准方法比较
ReTaKe 方法能够一致提升各个基准的长视频理解能力。
实验结果显示,AdaReTaKe 方法在 VideoMME、MLVU、LongVideoBench 和 LVBench 四个长视频理解基准上,
对于 LLaVA-Video、QWen2VL 和 QWen2.5VL 三种基准模型有一致且稳定的性能提升,平均提升幅度高达 3%-5%。
对于平均时长最长(超过 1 小时)的 LVBench,AdaReTaKe 将 7B 和 72B 模型的准确率分别提升 5.9% 和 6.0%。
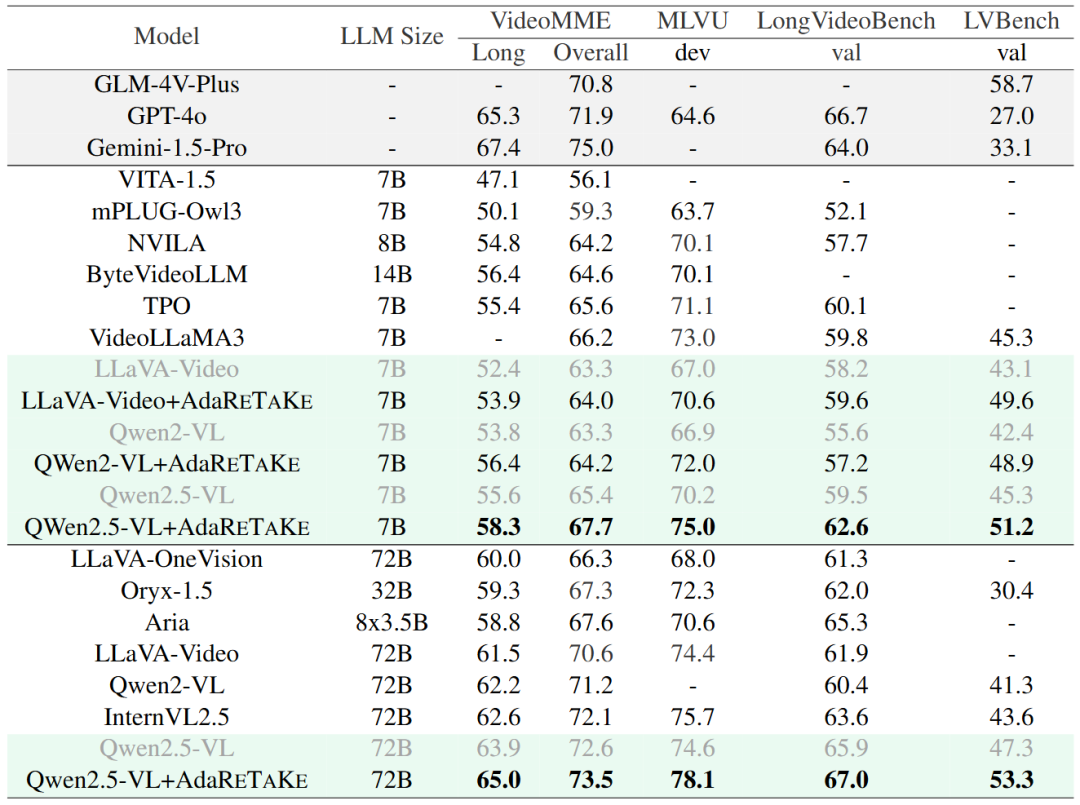
消融实验
研究团队通过一系列对比实验深入探讨了 AdaReTaKe 模型各组件对性能提升的具体贡献。
首先,将基线模型(#0)与加入了 token 压缩的方法进行对比,发现尽管 token 压缩引入了轻微的性能下降(#1),
但它允许模型在同一上下文长度内处理更多的帧(#2),从而捕捉到更丰富的信息,最终实现了净性能增益。
其次,在不同层和不同帧之间应用不同的压缩比率(分别为 #3 和 #4),结果显示这种分配策略能够有效提升模型性能,验证了 AdaReTaKe 方法的有效性。
最后,通过扩展上下文长度至 MLLMs 的一般上限(#5),模型性能得到了显著提升。
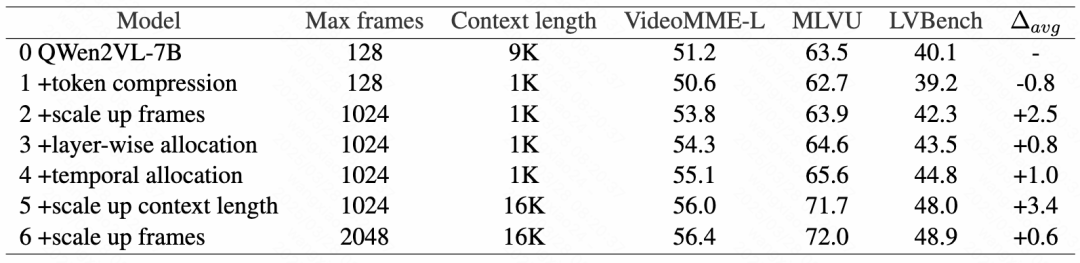
ReTaKe 对细粒度时序感知能力的影响
总的来说,如果单纯考虑 ReTaKe 对视频的压缩,可能会对某些细粒度任务(如 Needle QA,NQA)的性能造成轻微损害。
但由于它使得模型能够在相同上下文长度内处理更多的帧,从而吸收了更丰富的信息。
因此最终,这种潜在的损害不仅被有效抵消,还在多个任务中实现了超越基线的表现。
实验对比了基线模型 LLaVA-Video-7B 和 QWen2VL-7B 的表现,结果显示:
单纯实现 token 压缩导致 Needle QA 性能略有下降,这是由于压缩不可避免地带来了一定的信息丢失,但在其他相对粗粒度的任务中,
如动作顺序(AO)、关键信息检索(KIR)以及时间定位(TG),ReTaKe 的压缩策略带来了略微的性能提升。
最终,得益于更密集的帧采样,模型能够补偿因压缩造成的细微信息损失,并有效增强了对动作的理解及关键信息的提取。
可视化结果
可视化结果显示,ReTaKe 能有效识别并保留关键信息和细微语义变化的区域,如身体动作和面部表情,同时过滤掉静态场景中的冗余帧。

长视频理解榜单
团队于 VideoMME 榜单位列第二位,开源模型第一位,仅次于 Gemini-1.5-Pro。
在 MLVU、LongVideoBench 和 LVBench 榜单位列第一位,其中 LongVideoBench 是超过 GPT-4o 的首个开源模型。
未来研究方向
- 原生视频压缩模块:当前依赖训练后的启发式压缩策略,未来可设计端到端压缩模块,将压缩能力和模型深度融合。
- 智能分块策略:现有视频分块方法依赖固定时长,探索基于语义边界的分块(如场景切换)可进一步提升效率。
- 多模态联合优化:结合音频、文本等多模态信号,构建冗余评估的综合指标,实现更精准的压缩。
总结
长视频理解是最接近人类接收信息方式的场景,也是长序列推理在多模态场景下的首要战场,
ReTaKe 系列论文通过大模型视频 token 压缩技术,解决了长视频理解中的动态冗余难题,为 AI 处理小时级视频提供了新范式,
助力学术界与工业界探索视频智能的边界。未来,随着原生压缩与多模态融合的突破,长视频理解将迈向更智能的时代!
参考文献
[1] Hooper, Coleman, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. KVQuant: Towards 10
Million Context Length LLM Inference with KV Cache Quantization. NeurIPS 2024,
[2] Zhang, Zhenyu, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, et al. H2O: Heavy-Hitter Oracle for Efficient Generative
Inference of Large Language Models. NeurIPS 2023.
文章来自于微信公众号“机器之心”,作者 :哈尔滨工业大学(深圳)博士生王霄和华为大模型研究员佀庆一

【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

