最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)
通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。
但随之而来的是一个日益严重的问题:它们太能「说」了!生成的推理过程往往充斥着冗余信息(比如反复定义)、
对简单问题过度分析,以及对难题的探索浅尝辄止。
正如 Qwen2.5-32B-Instruct 回答「3 的平方是多少」只需要 30 个 token,而它的 LRM 版本 QwQ-32B 却能滔滔不绝地输出 1248 个 token 来反复验证。
这种低效不仅拖慢了模型训练和推理速度,也给实际应用(如智能体系统)带来了巨大挑战。莎士比亚说:「简洁是智慧的灵魂(Brevity is the soul of wit)」。
在 LRM 时代,我们提出「效率是智慧的精髓(Efficiency is the essence of intelligence)」。
一个真正智能的模型,应该懂得何时停止不必要的思考,明智地分配计算资源(token),优化求解路径,用优雅的精确性平衡成本与性能。
上海AI Lab联合 9 家单位,总结超过 250 篇相关论文,深入探讨了当前提升 LRMs 思考效率的研究,聚焦于这个新范式下的独特挑战。

- 论文标题:A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond
- 论文链接:https://arxiv.org/pdf/2503.21614
- 代码仓库:https://github.com/XiaoYee/Awesome_Efficient_LRM_Reasoning
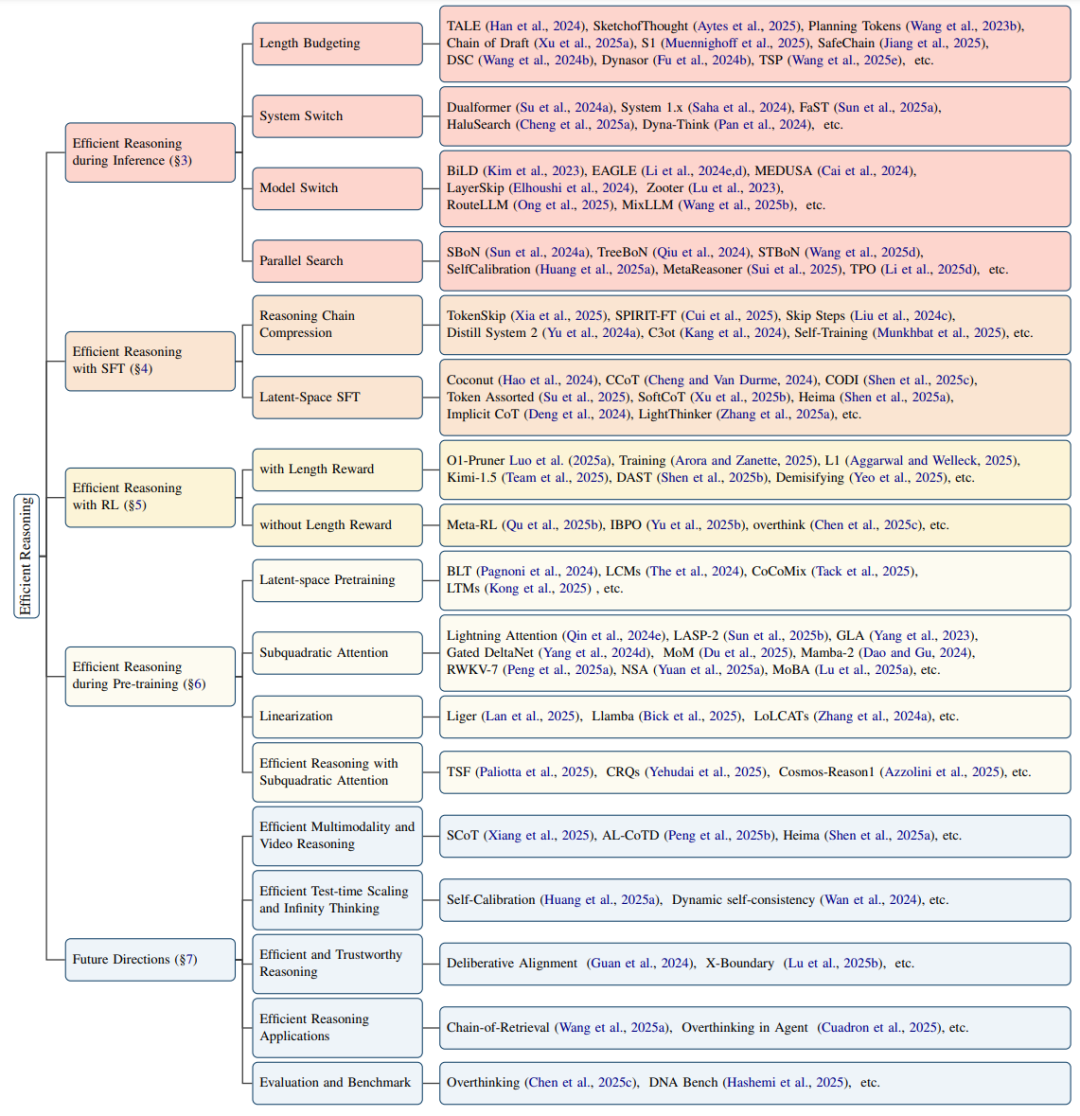
图表 1:综述的主要结构,分类章节,以及未来重要的研究方向
思考效率:定义、常见模式与挑战
在深入探讨方法之前,我们先明确什么是思考效率,看看 LRMs 通常在哪些方面表现「低效」,以及提升思考效率面临哪些独特挑战。
思考效率的定义
我们从任务分布的角度定义推理效率。对于一个 LRM 模型,其在任务分布上的思考效率定义为:
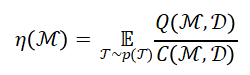

推理低效的常见模式
尽管长 CoT 有效,但 LRMs 常常表现出以下低效模式:
- 冗余内容:模型输出中充斥大量重复、冗余的文本(如反复复述问题),这些内容对最终答案帮助不大,却增加了计算成本。
- 过度思考简单问题:LRM 难以根据任务复杂度有效分配「思考预算」。即使是简单问题(如 2+3=?),也可能生成多轮冗余的验证步骤。
- 不连贯与次优推理:这类现象称为「欠思考」。模型频繁地切换思考方向,导致推理过程浅显、碎片化,增大了推理链的长度。
LRM 思考效率提升的独特挑战
提升 LRM 的推理效率面临一些新的、独特的挑战:
- 量化推理效用:难以评估推理链中每一步的实际贡献。
这使得精确判断哪些部分可以压缩或删减变得困难,在不牺牲性能的前提下追求简洁成为一个微妙的平衡问题。
- 控制思考长度:长度控制一直是 LLM 的难题,在 LRM 中更显关键。简单的 token 级限制过于死板,无法适应推理的语义结构。
如何让模型「思考得恰到好处」,既不太浅以致遗漏逻辑,也不太深以致浪费计算,仍是一个悬而未决的问题。
- 超越 Transformer 架构瓶颈:现有 LRM 大多基于 Transformer,其二次复杂度在处理数千甚至更多 token 的长推理链时成为严重瓶颈。
开发能够处理长序列的新架构或高效近似方法至关重要。
- 跨任务泛化:不同任务需要不同的推理深度。单一的推理策略或长度策略难以适应所有任务。如何在保证跨领域鲁棒性的同时实现效率,是一个复杂挑战。
推理时如何更高效?
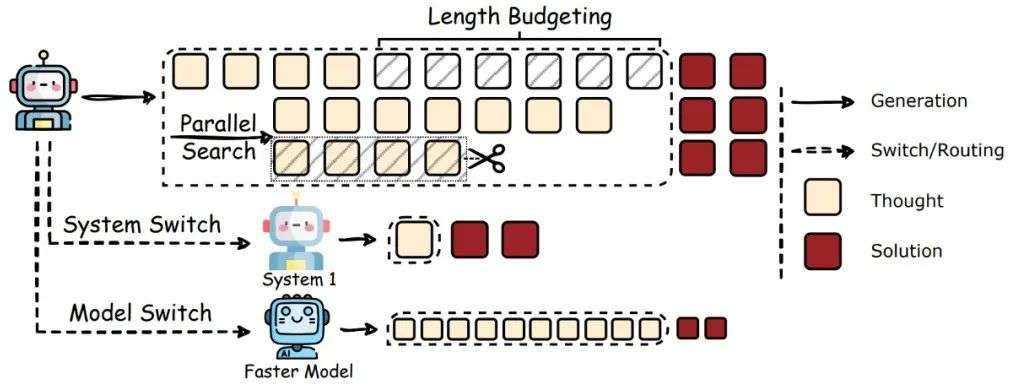
这一部分聚焦于在模型推理(生成答案)阶段提升效率的方法,主要有四类策略:
长度预算(Length Budgeting)
最直接的方法是明确限制计算资源。
- 整体预算:通过特定提示词或解码策略来控制总 token 数或思考步数。
- 分步预算:引入规划 token 来控制每步长度,或鼓励生成简洁的中间步骤。
- 动态预算:根据问题难度或模型置信度动态分配资源,或通过惩罚机制阻止不成熟的思考切换。
系统切换(System Switch)
借鉴人类思维的双系统理论(System1 快直觉,System2 慢审慎)。
- 核心思想:让模型根据任务情况在快速(类 System1)和慢速(类 System2)推理模式间切换,优化资源分配。
模型切换(Model Switch)
在不同复杂度的模型间分配计算任务。
- 核心思想:用小模型处理简单部分/草稿,大模型处理困难部分/验证,或根据任务动态选择最合适的模型。
并行搜索(Parallel Search)
提升 Best-of-N、Self-Consistency 等并行生成方法的效率。
- 核心思想:同时生成多个候选答案,但通过更智能的策略减少总体计算量。
通过微调学习高效推理
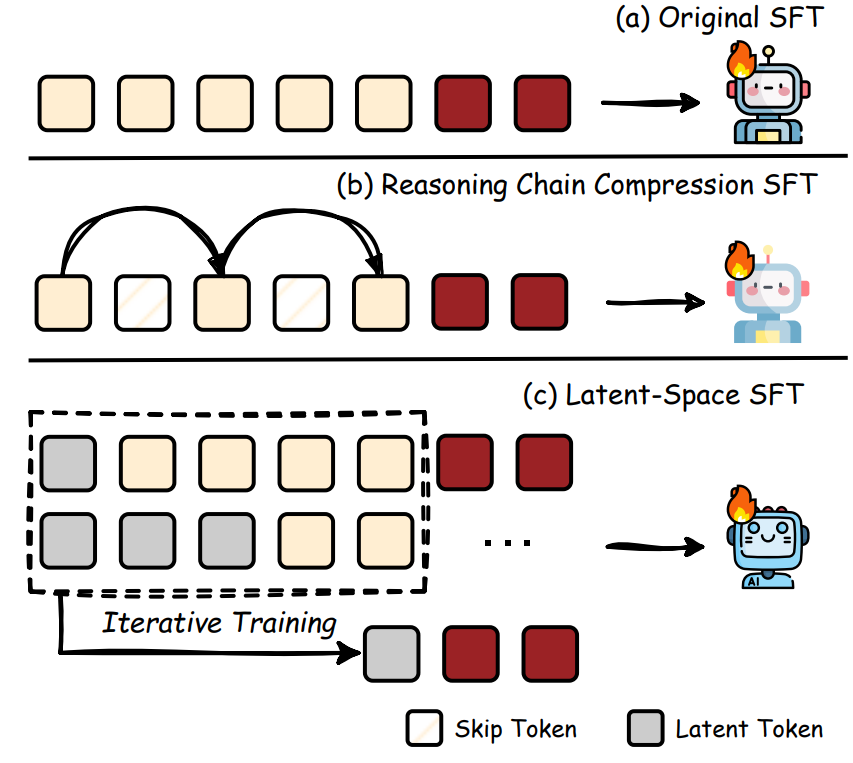
监督微调(SFT)是让模型学习遵循特定指令的常用方法。这一部分探讨如何通过 SFT 让 LRM 学会更高效地推理,主要分为两类:
推理链压缩(Reasoning Chain Compression)
- 核心思想:让模型学习生成更简洁、无冗余的推理链。
潜空间微调(Latent-Space SFT)
- 核心思想:用连续的隐藏状态(latent space)表示推理步骤,替代显式的 token 生成。
如何用强化学习塑造高效推理?
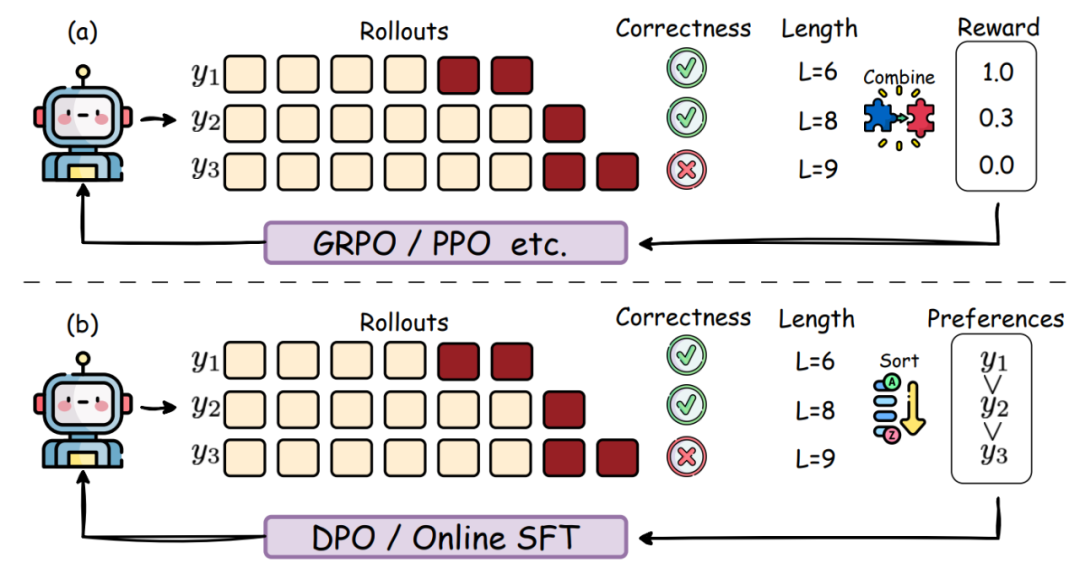
强化学习(Reinforcement Learning,RL)已被证明能有效引导 LLM 发展深度推理能力(如 DeepSeek-R1)。
这自然引出了一个想法:能否用 RL 更直接、更直观地提升推理效率?目前的研究主要围绕如何通过 RL 策略减少或控制推理轨迹的 token 使用,同时保持性能。
带长度奖励的强化学习(Efficient RL with Length Reward)
- 核心思想:在 RL 的奖励函数中直接加入对长度的考量,通常是惩罚过长输出。
- 实现方式如下:
1. 设定预算:
基于任务难度(通过成功率等指标量化)设定 token 长度预算,并据此设计奖励。
在 prompt 中明确给出目标长度指令,并惩罚偏离目标的行为。
2. 归一化奖励:
将长度奖励与基线模型(通过预采样得到)的长度进行比较和归一化。
在每个 prompt 内部进行长度惩罚归一化。
使用相对于同问题下生成的最长/最短答案的归一化长度因子作为奖励。
3. 设计特定函数:
使用如余弦函数形式的奖励,在鼓励有效推理步骤的同时,对过度增长的长度施加惩罚。
无长度奖励的强化学习(Efficient RL without Length Reward)
- 核心思想:不直接在奖励中加入长度项,而是通过改变 RL 框架或优化目标来间接实现效率。
从源头提升效率:预训练阶段的探索
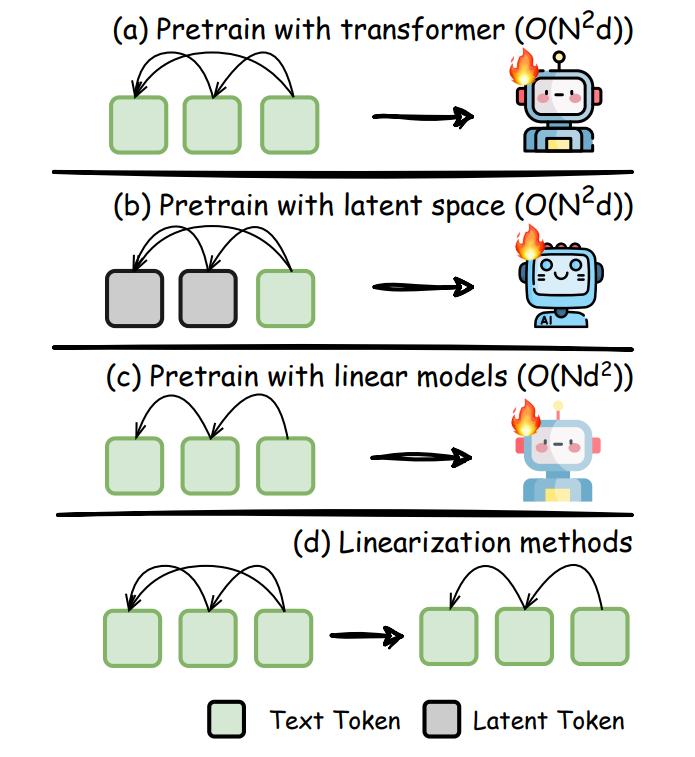
这一部分着眼于在模型预训练阶段就融入高效设计的思路,旨在从根本上提升计算效率和性能。主要有三条路线:
潜空间预训练(Pretraining with Latent Space)
- 核心思想:使用连续表示(而非离散 token)作为预训练的基本单元。
子二次注意力(Subquadratic Attention)
- 核心思想:用计算复杂度低于 O(N²) 的注意力机制替代标准自注意力,以应对长 CoT 带来的长序列处理挑战。
线性化(Linearization)
- 核心思想:将预训练好的标准 Transformer 模型转换为线性循环结构(如 RNN 或 SSM),以提升部署效率。
未来方向:路在何方?
针对 LRM 高效思考的研究尚处早期,未来有许多激动人心的方向值得探索:

高效多模态与视频推理(Efficient Multimodal and Video Reasoning)
- 现状:CoT 推理在多模态领域(图像、视频)也显示出重要作用,但是其过度思考的问题非常严重,效率研究不足。
高效测试时扩展与无限思考(Efficient Test-time Scaling and Infinity Thinking)
- 现状:测试时扩展(增加思考时间/计算)是提升性能的直接方法,主要分并行采样(增宽)和顺序修正(加深)。
- 当前面临如下挑战:
- 并行:固定采样数对简单问题浪费计算,对复杂问题可能探索不足。顺序:推理链可能无限延长(「无限思考」),带来巨大计算开销和管理难题。平衡:如何高效地平衡搜索宽度和深度以优化延迟和资源?
高效且可信赖的推理(Efficient and Trustworthy Reasoning)
- 现状:长 CoT 给 LRMs 的可信赖性带来新挑战,包括安全性和可靠性。
- 当前面临如下挑战:
- 安全:推理过程中可能暴露敏感信息,即使最终答案安全。
可靠:长链更容易积累错误(幻觉),且 CoT 过程本身可能与模型内部实际「思考」不符(CoT 不忠实问题)。
构建高效推理应用(Building Efficient Reasoning Applications)
- RAG:高效推理对动态、步进式检索与推理,以及根据需要调整检索链长度和数量至关重要。
- Agent:LRM Agent 推理能力强,但计算开销大,限制了实时性。需要高效推理来降低延迟、成本,并缓解过度思考。
- Tool learning:需要结合分层推理、早停、并行执行、动态查询路由等策略来提升调用外部工具的效率。
- 其他领域:编码、自动驾驶、医疗、具身智能等领域同样需要高效推理。
评估与基准(Evaluation and Benchmark)
- 现状:当前评估多集中于数学任务,比较准确率-token 权衡。
- 当前面临如下挑战:
- 需要更细粒度的指标来评估「过度思考」现象,区分有效推理和冗余步骤。需要评估推理效率是否牺牲了通用智能(如创造力)。
缺乏专门用于衡量 LRM 过度推理倾向的基准。
文章来自于微信公众号 “机器之心”,作者 :机器之心

【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

