本文介绍了 FoundationStereo,一种用于立体深度估计的基础模型,旨在实现强大的零样本泛化能力。
通过构建大规模(100 万立体图像对)合成训练数据集,结合自动自筛选流程去除模糊样本,
并设计了网络架构组件(如侧调谐特征主干和远程上下文推理)来增强可扩展性和准确性。
这些创新显著提升了模型在不同领域的鲁棒性和精度,为零样本立体深度估计设立了新标准。
相关论文 FoundationStereo: Zero-Shot Stereo Matching 获得 CVPR 2025 满分评审,代码已开源。

- 论文地址:https://arxiv.org/abs/2501.09898
- 项目主页:https://nvlabs.github.io/FoundationStereo/
- 项目代码和数据集:https://github.com/NVlabs/FoundationStereo/

对比常用 RGBD 相机:

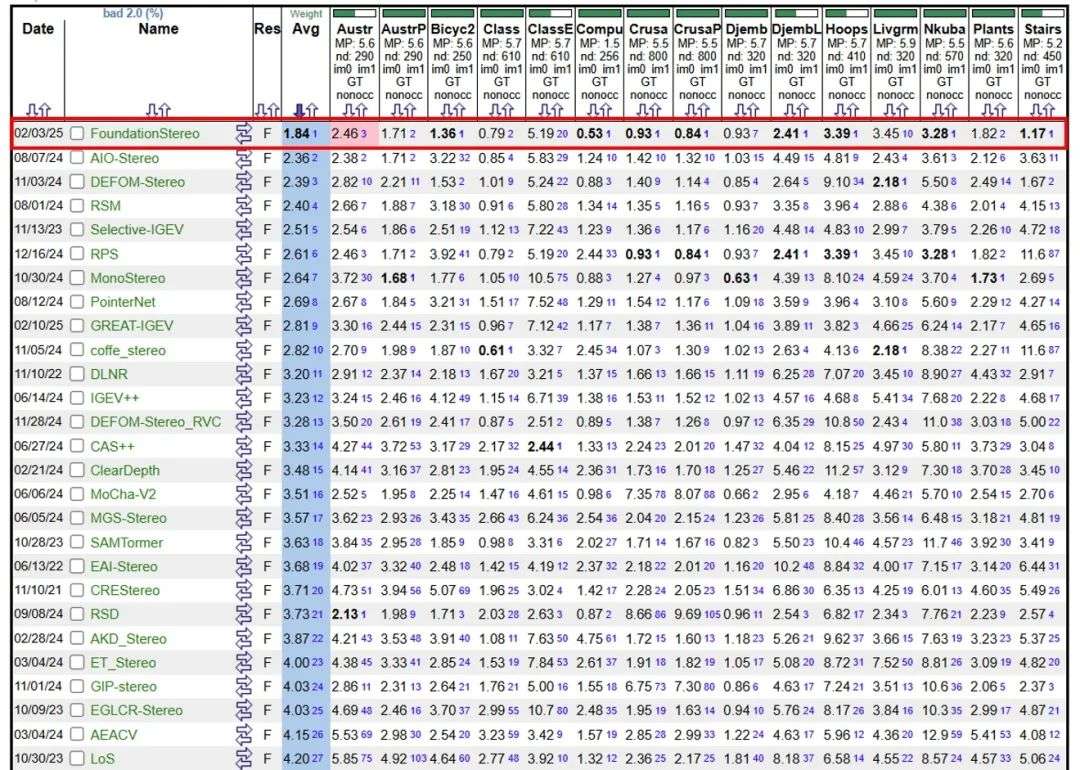
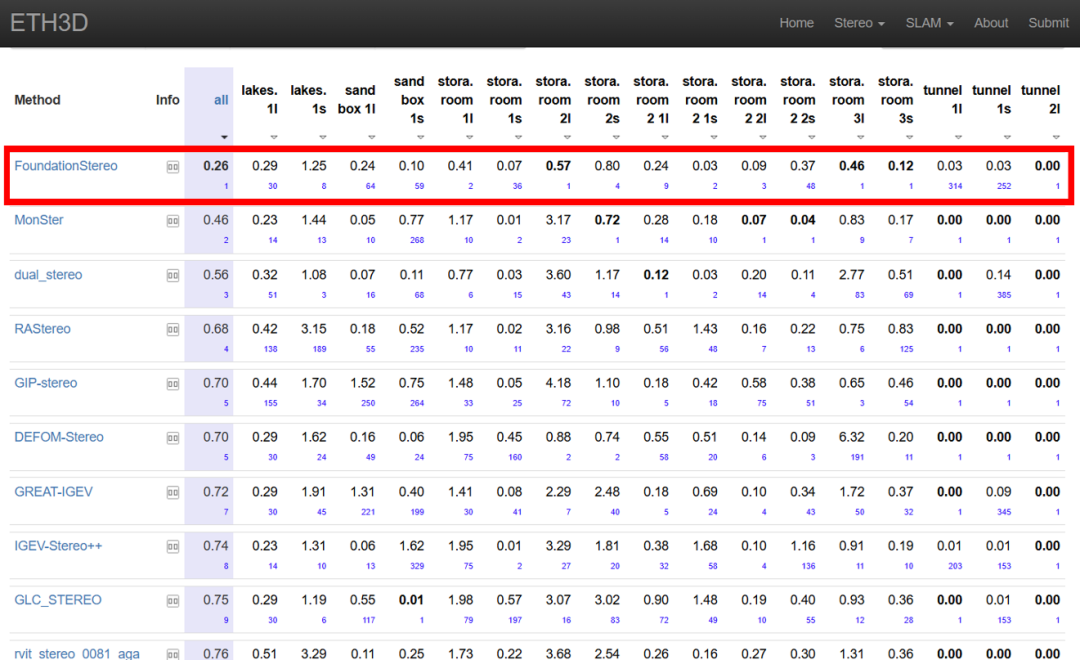
目前 FoundationStereo 在 Middlebury, ETH3D 等多个排行榜位列第一。
引言
立体匹配算法虽在基准数据集上表现优异,但零样本泛化能力仍不足。现有方法依赖目标域微调,且受限于网络结构或数据规模。
本文提出 FoundationStereo,通过大规模合成数据、自筛选流程及结合单目先验的架构设计,实现了无需微调的跨域泛化能力。主要贡献如下:
1.FoundationStereo 大模型
- 提出首个零样本泛化能力强大的立体匹配基础模型,无需目标域微调即可在多样场景(室内 / 室外、无纹理 / 反射 / 透明物体等)中实现高精度深度估计。
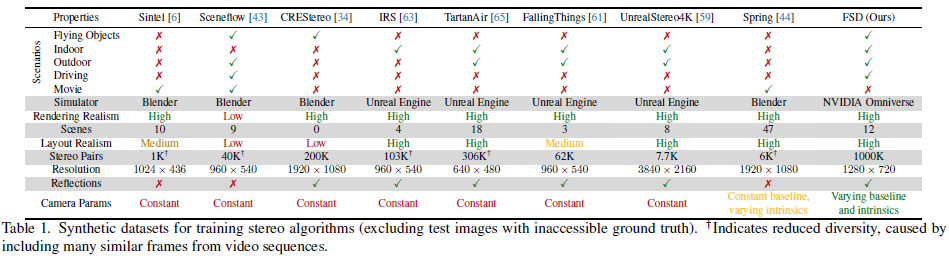
2. 大规模合成数据集(FSD)
- 构建包含 100 万立体图像对的高保真合成数据集,覆盖复杂光照、随机相机参数及多样化 3D 资产,并通过路径追踪渲染提升真实性。
- 设计迭代自筛选流程,自动剔除模糊样本(如重复纹理、纯色区域),提升数据质量。
3. 单目先验适配(STA 模块)
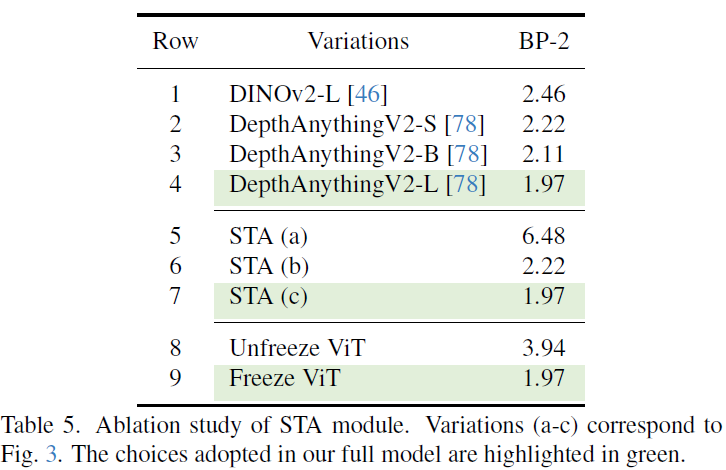
- 提出侧调谐适配器(STA),将单目深度估计模型(DepthAnythingV2)的互联网尺度几何先验与 CNN 特征结合,显著缓解合成到真实的域差距。
4. 注意力混合成本过滤(AHCF)
- 轴向平面卷积(APC):将 3D 卷积解耦为空间和视差维度的独立操作,扩展感受野并降低计算开销。
- 视差 Transformer(DT):在成本体积中引入跨视差自注意力机制,增强长程上下文推理能力。
5. 实验性能突破
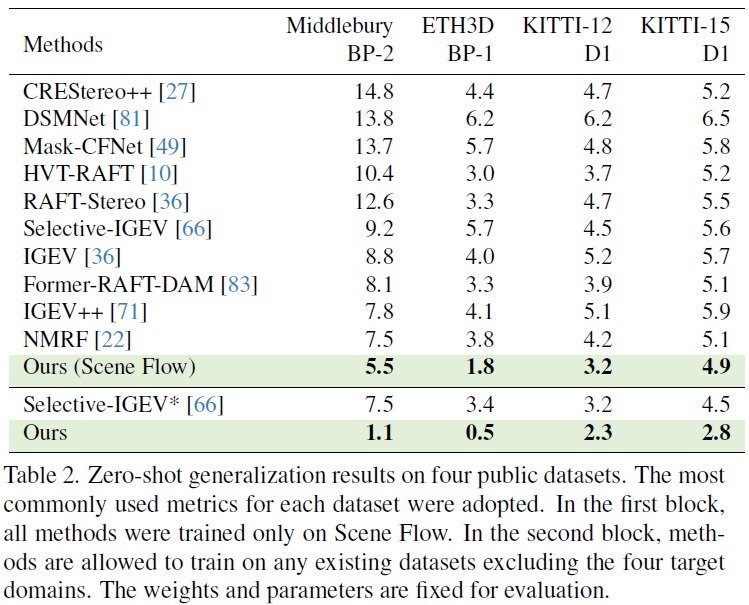
- 零样本泛化:在 Middlebury、ETH3D 等基准上超越微调模型(如 Middlebury BP-2 误差从 7.5% 降至 1.1%)。
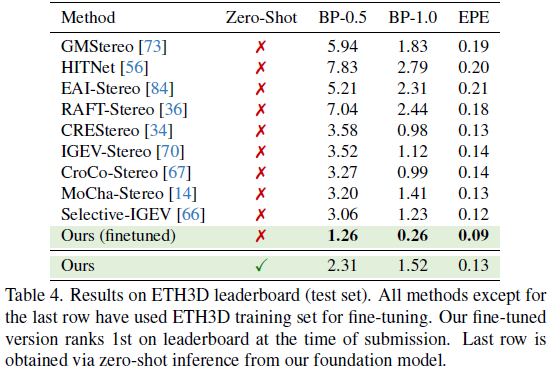
- 领域内最优:Scene Flow 测试集 EPE 刷新纪录(0.34),ETH3D 微调后排名第一。

方法
概览
1. 单目 - 立体协同:通过 STA 融合 ViT 的几何先验与 CNN 的匹配能力,缩小仿真 - 真实差距。
2. 成本体积高效滤波:APC(大视差核) + DT(全局注意力)实现多尺度上下文聚合。
3. 数据驱动泛化:百万级合成数据 + 自动筛选,覆盖极端场景(透明 / 反射 / 无纹理物体)。
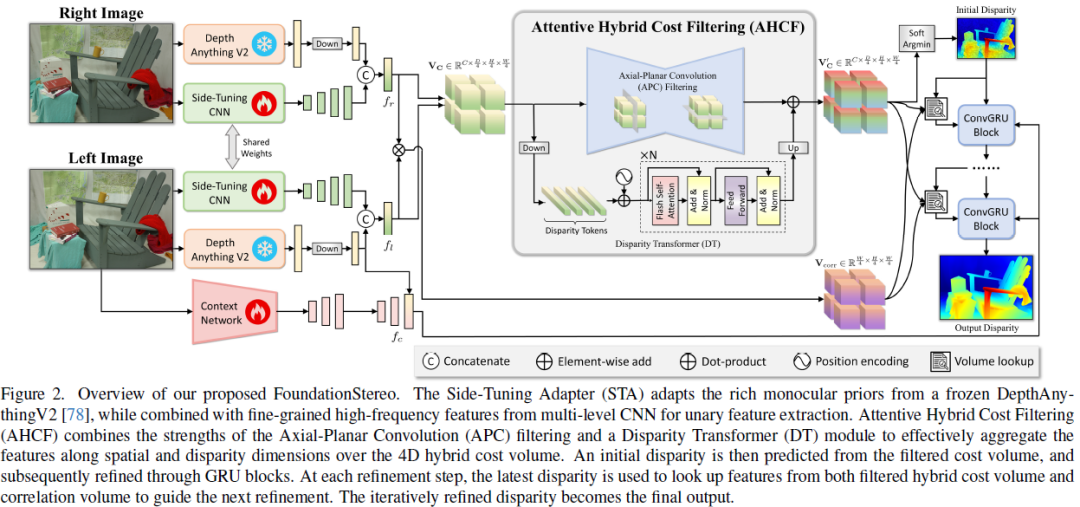
单目基础模型适配(Monocular Foundation Model Adaptation)
1.动机:合成数据训练的立体匹配模型存在仿真 - 真实差距(sim-to-real gap),
而单目深度估计模型(如 DepthAnythingV2)在真实数据上训练,能提供更强的几何先验。
2.方法:
- 采用侧调谐适配器(STA, Side-Tuning Adapter),将冻结的 DepthAnythingV2 ViT 特征与轻量级 CNN(EdgeNeXt-S)提取的特征融合。
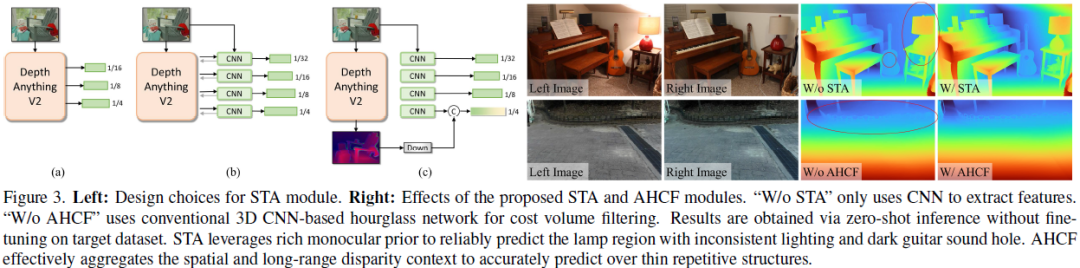
- 实验对比三种融合策略(图 3 左):
(a) 直接使用 ViT 特征金字塔 → 效果较差(缺乏局部细节)。
(b) ViT 与 CNN 双向特征交换 → 计算复杂,收益有限。
(c) ViT 最终层特征降维后与 CNN 特征拼接 → 最优选择(平衡效率与性能)。
- 关键优势:STA 模块保留 ViT 的高层语义先验,同时结合 CNN 的细粒度匹配能力,显著提升对模糊区域(如弱纹理、反射表面)的鲁棒性。
注意力混合成本过滤(Attentive Hybrid Cost Filtering)
1.混合成本体积构造(Hybrid Cost Volume Construction)
- 输入:STA 提取的左右图像 1/4 分辨率特征(fl4,fr4fl4,fr4)。
- 构造方式:
1.分组相关(Group-wise Correlation):将特征分为 8 组,计算逐组相关性(VgwcVgwc),增强匹配多样性。
2.特征拼接(Concatenation):直接拼接左右图像特征(VcatVcat),保留单目先验信息。
3.最终成本体积:兼顾局部匹配与全局上下文。
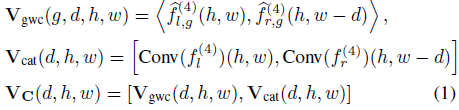
2.轴向平面卷积(APC, Axial-Planar Convolution)
- 问题:传统 3D 卷积(如 3×3×3)对大视差范围计算代价高,且感受野有限。
- 改进:将 3D 卷积解耦为两部分:
1. 空间卷积(Ks×Ks×1Ks×Ks×1):处理图像平面内的特征。
2. 视差卷积(1×1×Kd1×1×Kd):沿视差维度聚合信息。
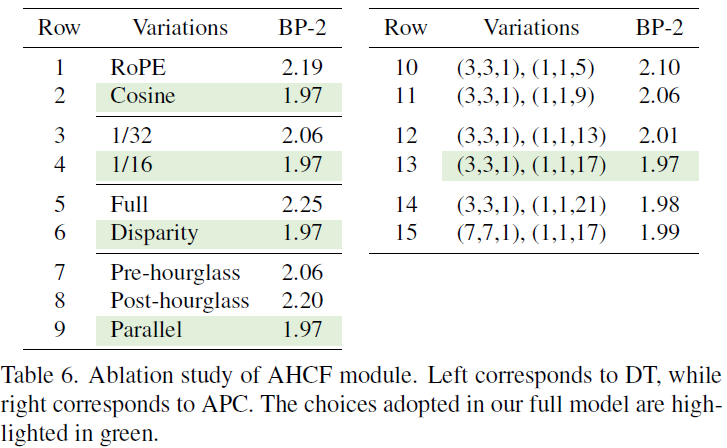
效果:在视差维度使用大核(如 Kd=17),显著提升长距离匹配能力,同时降低内存占用。
3.视差 Transformer(DT, Disparity Transformer)
- 动机:传统成本滤波缺乏全局视差关系建模。
- 设计:
1.将成本体积降采样至 1/16 分辨率,转换为视差序列 token。
2.通过 4 层 Transformer 编码器(含 FlashAttention)执行跨视差自注意力。
3.位置编码:实验表明余弦编码优于 RoPE(因视差维度固定)。作用:增强对薄结构、重复纹理等复杂场景的匹配鲁棒性。

4.初始视差预测
- 对滤波后的成本体积 VC∗VC∗执行 Soft-Argmin,生成 1/4 分辨率的初始视差图 d0。
迭代优化(Iterative Refinement)
- 相关性体积查找:基于当前视差 dk,从 VC 和左右特征相关性体积 Vcorr中提取特征。
- GRU 更新:
1. 输入:成本体积特征 + 当前视差 + 上下文特征(来自 STA)。
2. 采用 3 级 ConvGRU(粗到细)逐步优化视差,每级隐藏状态由上下文特征 初始化。
- 视差修正:通过卷积预测残差 Δd,更新视差
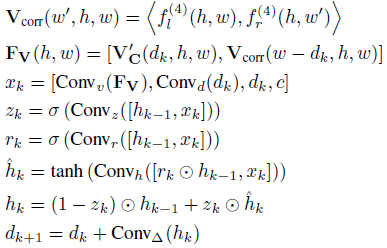
损失函数(Loss Function)
- 监督目标:
1.初始视差 d0:平滑 L1 损失。
2.迭代优化视差 {dk}{dk}:加权 L1 损失(权重随迭代指数衰减,γ=0.9)。
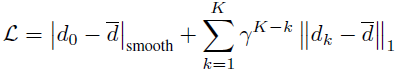
合成训练数据集(Synthetic Training Dataset)
- 数据生成:
1.工具:NVIDIA Omniverse 路径追踪渲染。
2.多样性增强:随机化相机参数(基线、焦距)、光照、物体布局。
3.场景类型:结构化室内 / 室外场景 + 随机飞行的复杂物体(图 4)。
- 自筛选流程:
1. 训练初始模型,在 FSD 上评估。
2. 剔除 BP-2 > 60% 的模糊样本(如无纹理区域、过度反射)。
3. 重新生成数据并迭代训练(共 2 轮),提升数据质量。

实验和结果
我们在 PyTorch 中实现了 FoundationStereo 模型,使用混合数据集进行训练,包括我们提出的 FSD 数据集以及 Scene Flow、Sintel、CREStereo、
FallingThings、InStereo2K 和 Virtual KITTI 2 等公开数据集。采用 AdamW 优化器训练 20 万步,总 batch size 为 128,均匀分布在 32 块 NVIDIA A100 GPU 上。
初始学习率设为 1e-4,在训练过程进行到 80% 时衰减为原来的 0.1 倍。输入图像随机裁剪为 320×736 大小,并采用与 IGEV 类似的数据增强方法。
训练时使用 22 次 GRU 迭代更新,而在后续实验中(除非特别说明),我们使用相同的基础模型进行零样本推理,采用 32 次精炼迭代和 416 的最大视差范围。
除非特别说明,我们用同一权重的大模型进行零样本的泛化测试。

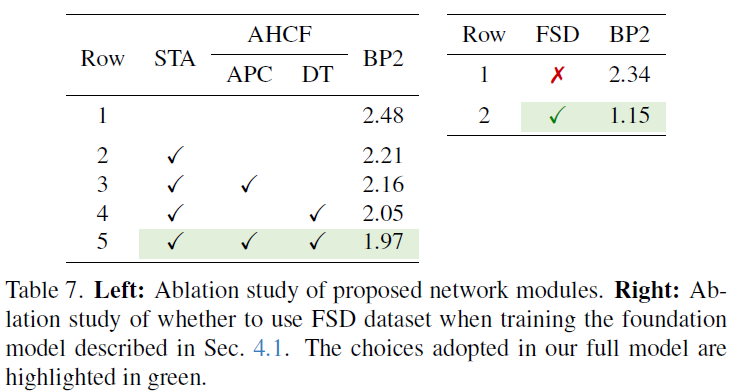
在消融实验中,我们系统验证了模型各关键组件的有效性:首先比较了不同单目基础模型(DepthAnythingV2 和 DINOv2)及其融合策略,
发现 ViT 特征降维拼接 CNN 的 STA 设计效果最佳;
其次测试了 AHCF 模块中位置编码(余弦编码优于 RoPE)、注意力范围(仅视差维度优于全成本体积)和 APC 卷积核配置(视差核尺寸 17 时性能饱和);
最后证明了引入 FSD 数据集能显著提升泛化性(Middlebury 上 BP-2 指标从 2.34% 降至 1.15%)。这些实验全面支撑了模型设计的合理性。
FoundationStereo 在透明和千纹理物体上也表现出很好的泛化性:

团队介绍
该论文来自于英伟达研究院。其中论文一作华人温伯文博士任高级研究员,此前曾在谷歌 X,Facebook Reality Labs, 亚马逊和商汤实习。
研究方向为机器人感知和 3D 视觉。获得过 RSS 最佳论文奖提名。个人主页: https://wenbowen123.github.io/

文章来自于微信公众号“机器之心”,作者 :英伟达研究院

【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

