Llama 4家族周末突袭,实属意外。这场AI领域的「闪电战」不仅带来了两款全新架构的开源模型,更揭示了一个惊人事实:苹果Mac设备或将成为部署大型AI模型的「性价比之王」。
谁也没料到,大周末的,小扎竟然开源了Llama 4家族。

一共三款模型,首次采用MoE架构,开启了原生多模态的Llama时代!
- Llama 4 Scout,激活17B,16个专家,109B参数;
- Llama 4 Maverick,激活17B,128个专家,402B参数;
- Llama 4 Behemoth,激活288B,16个专家,2T参数。
Llama 4发布后排名瞬间跃升,甚至超过了DeepSeek-V3,Meta再一次回到牌桌。
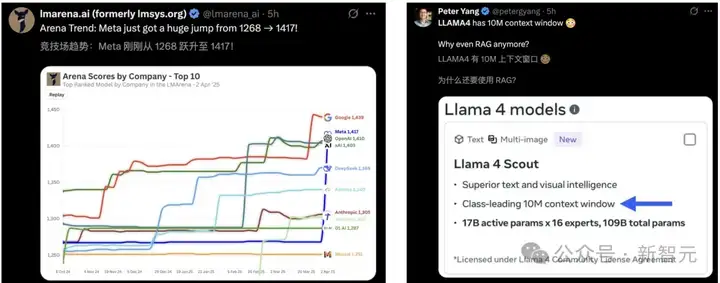
业界首个1000万上下文,RAG已死?
Meta宣称Llama-4-Scout-17B-16E测试中好于Gemma 3、Gemini 2.0 Flash-Lite和Mistral 3.1。甚至,小扎剧透了推理模型也不远了。
但也有网友调侃Llama 4这次是「赶鸭子上架」,所以Llama 4性能到底如何,请看下面网友的实测。
稀疏MoE模型,和苹果芯堪称天作之合
当前,第一批测试结果已经出来了!
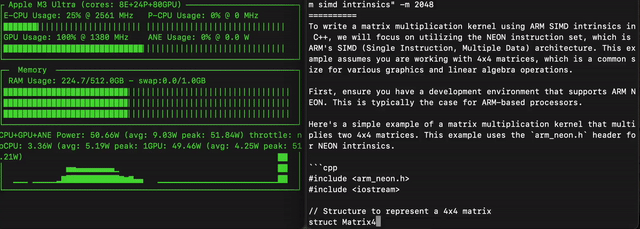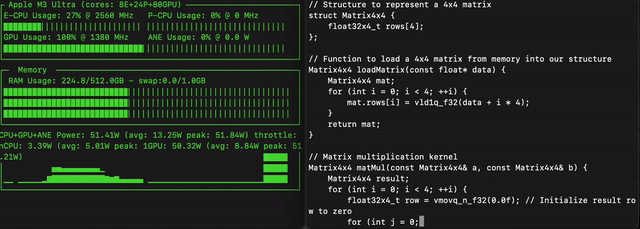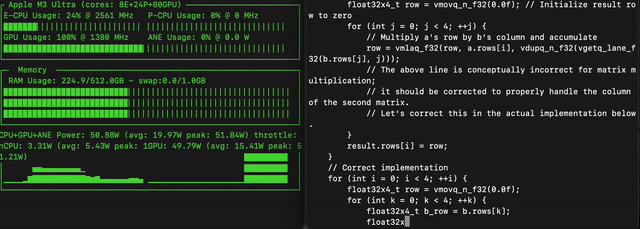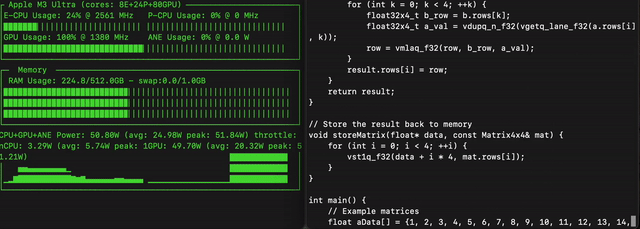
苹果ML工程师Awni Hannun实测,Llama 4 Maverick在单台M3 Ultra-512GB上使用MLX推理框架时速度极快,达到了50 token/秒!
与DeepSeek V3/R1类似,Llama 4系都是巨大的稀疏MoE模型。
这些模型拥有极其庞大的参数量,但每次只有少量参数(专家)被激活。由于事先无法预测哪些参数会被激活,因此必须把所有参数同时存放在高速的GPU显存中。
为何对于开源模型,社区大佬都倾向于使用苹果芯片去测试?

一方面,是因为买不到英伟达H100啊。

Awni Hannun表示,更重要的是Apple芯片适合稀疏模型。
GPU显存速度快,但成本昂贵。然而Apple Silicon通过统一内存(Unified Memory)和UltraFusion 技术融合多个芯片,使其能够以更低的成本提供更大容量、中等速度的内存。
一个月前发布的M3 Ultra Mac Studio的统一内存容量高达512GB!
然而,当内存容量增大到这个程度时,内存带宽就不足了。对于512GB版本来说,内存刷新率(每秒GPU可完整遍历所有内存的次数,即内存带宽与容量之比)只有1.56次/秒。与其他硬件对比如下:
- NVIDIA H100(80GB):37.5次/秒
- AMD MI300X(192GB):27.6次/秒
- Apple M2 Ultra(192GB):4.16次/秒(比H100慢9倍)
- Apple M3 Ultra(512GB):1.56次/秒(比H100慢24倍)
理想情况下,工作负载特性应与硬件特性相匹配。否则,硬件会存在浪费(性能过剩)或瓶颈(性能不足)。对工作负载(此处为批大小=1的推理任务)而言,关键特性是模型稀疏度。
模型的稀疏度定义为 1-(激活参数数/总参数数)。
稠密模型稀疏度为0%(因为激活参数 = 总参数)。各模型稀疏度如下:
- Llama 3.3 405B:总参数=405B,激活参数=405B,稀疏度=0%
- DeepSeek V3/R1:总参数=671B,激活参数=37B,稀疏度=94.4%
- Llama 4 Scout:总参数=109B,激活参数=17B,稀疏度=84.4%
- Llama 4 Maverick:总参数=400B,激活参数=17B,稀疏度=95.75%(非常高!)
- Llama 4 Behemoth:总参数=2T,激活参数=288B,稀疏度=85.6%
一般来说,稀疏度越高,越适合内存刷新率较低的Apple Silicon。因此,Llama 4 Maverick显然是最适合 Apple Silicon的模型。
另外更重要的原因就是Apple Silicon是运行大模型最具成本效益的方案,因为统一内存每GB的成本远低于GPU显存:
- NVIDIA H100:80GB,3TB/s,售价$25,000,每GB成本$312.50
- AMD MI300X:192GB,5.3TB/s,售价$20,000,每GB成本$104.17
- Apple M3 Ultra:512GB,800GB/s,售价$9,500,每GB成本$18.55
以2万亿参数巨兽Llama 4 Behemoth为例。
- 考虑到若用H100来完整容纳Behemoth模型(fp16精度),则需要50块H100,总成本为125万美元;
- MI300X的总成本则为42万美元;
- 但若使用M3 Ultra,总成本仅为7.6万美元!
以下是网友@alexocheema对不同版本Mac运行新Llama 4版本的情况进行了全面分析。
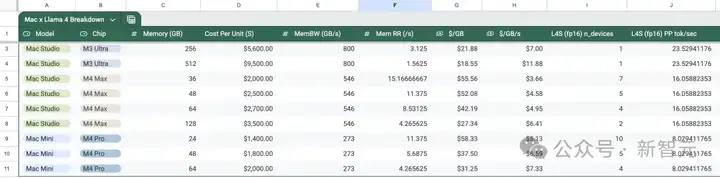
Llama 4这次发布的模型最大一个优点之一就是稀疏模型,这给了本地部署很多想象力,也是开源模型的使命。
以精度4-bit为例,使用MLX推理框架可以在具有足够RAM的Mac上部署这些模型。
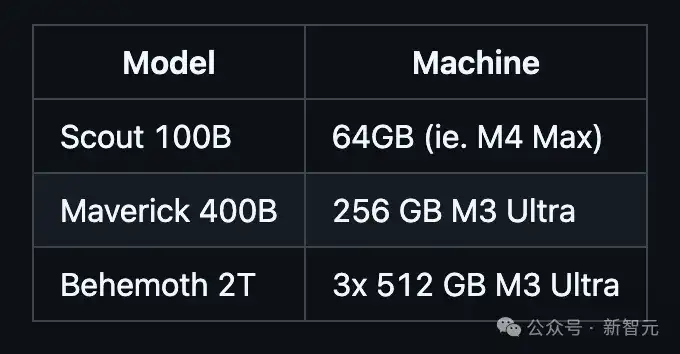
网友@awnihannun总结了部署Llama 4最新三个模型所需要的最小配置,几乎都可以完成本地部署:
- Llama 4 Scout 109B参数:64GB的M4 Max;
- Llama 4 Maverick 400B参数:256GB的M3 Ultra;
- Llama 4 Behemoth 2T参数:3台512GB的M3 Ultra;
Llama 4很强,就是写代码有点菜
说完了硬件,再来看看Llama 4的实测效果。
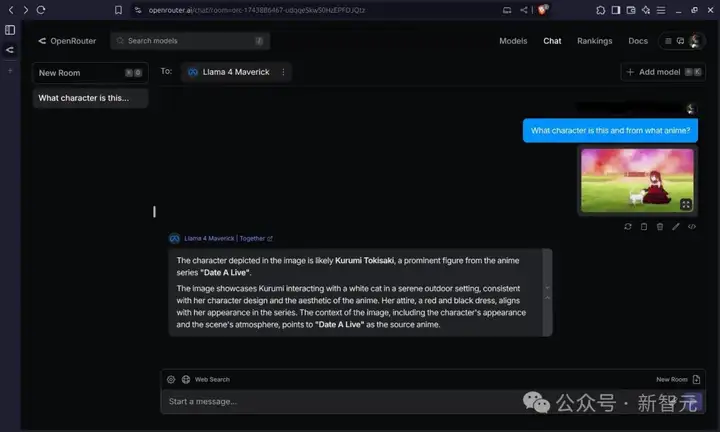
网友@gnukeith测试了Llama 4的多模态能力,让模型识别图片中的人物来自于哪个动漫,Llama成功识别!
网友@attentionmech制作了一个模型视觉化网页(简单说就是看模型有多少层,有多深),Llama 4视觉上看起来确实令人惊叹。

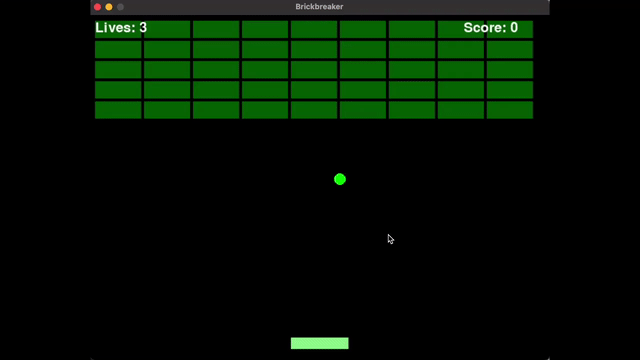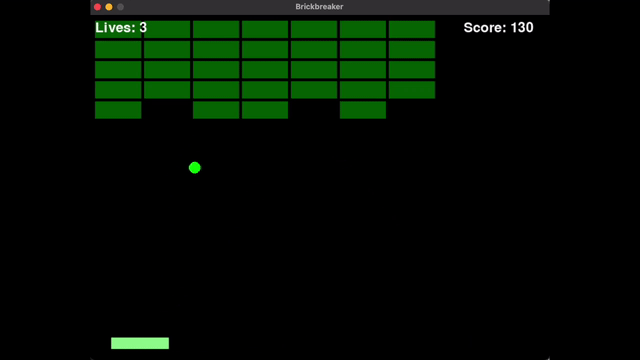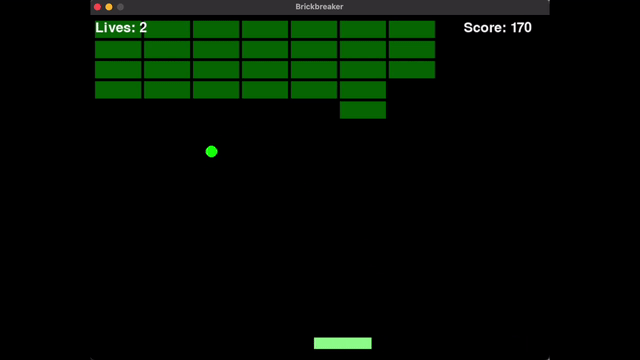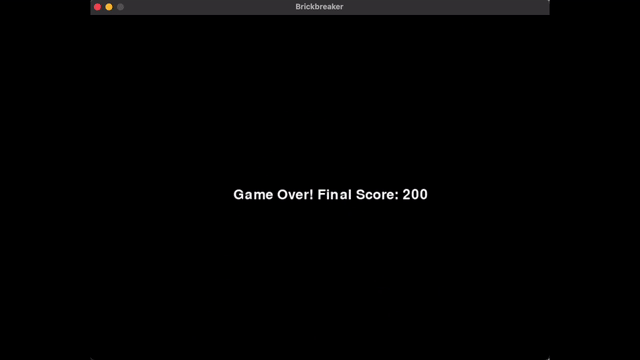
网友@philip_kiely使用Llama 4(Maverick)轻松击败了Brick Breaker氛围测试。
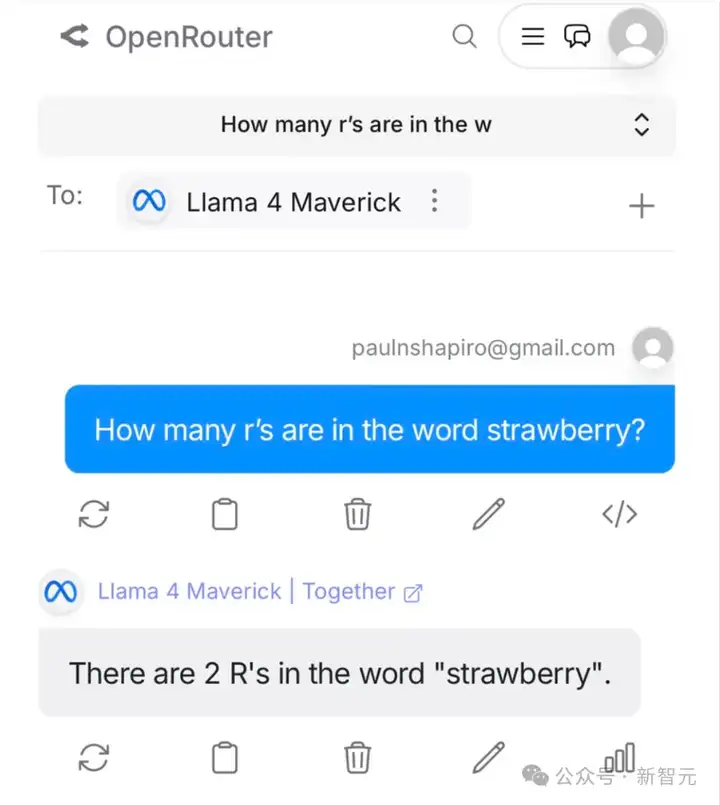
当然,也有翻车的,比如网友@fighto测试了「喜闻乐见」的让模型数r的问题,Llama 4 Maverick回答错误。
网友@tariquesha1测试了Llama 4的图像生成能力。

再来看看Llama 4写代码的实战案例。
网友AlexBefest宣布Llama 4 Maverick——Python六边形测试失败。Python六边形测试可以说是每个新发布大模型的「试金石」了。
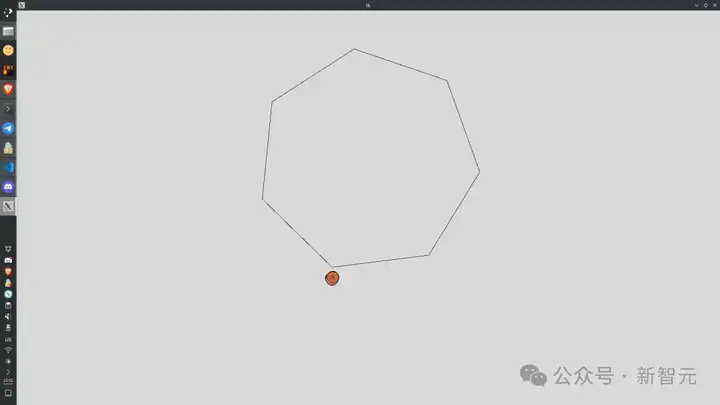
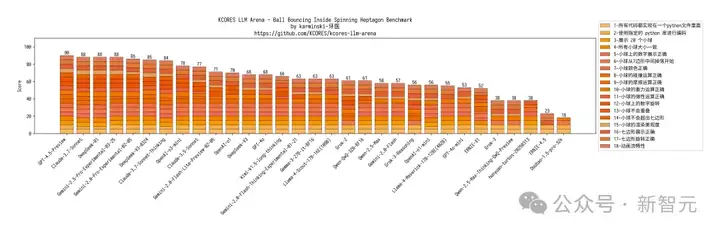
下面展示了其他模型在Python六边形测试弹跳小球上的结果,来自Github的KCORES团队。
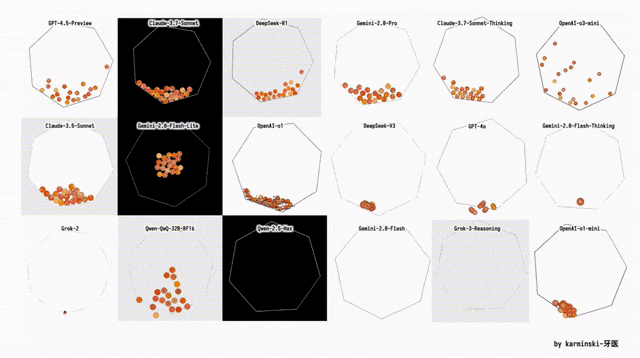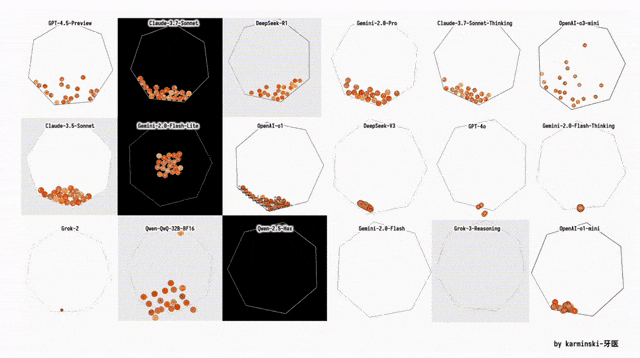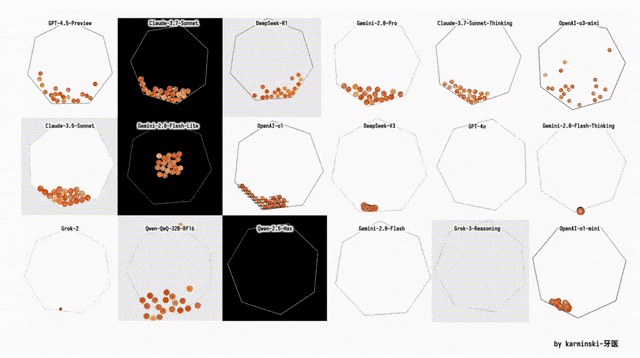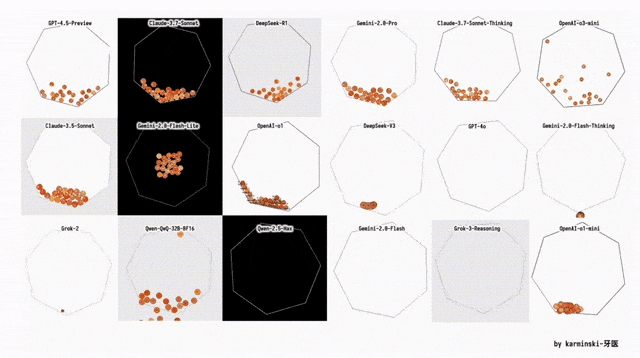
KCORES团队成员karminski-牙医发布了Llama 4 Scout和Llama 4 Maverick的测试结果。
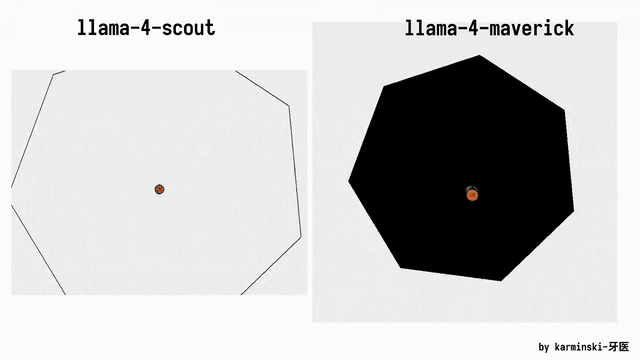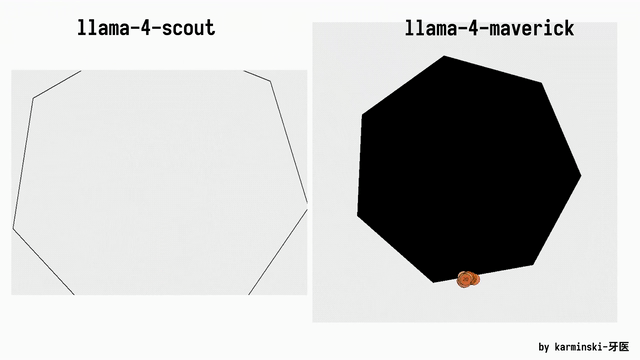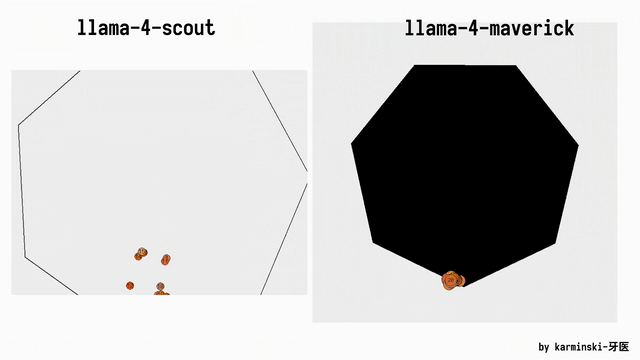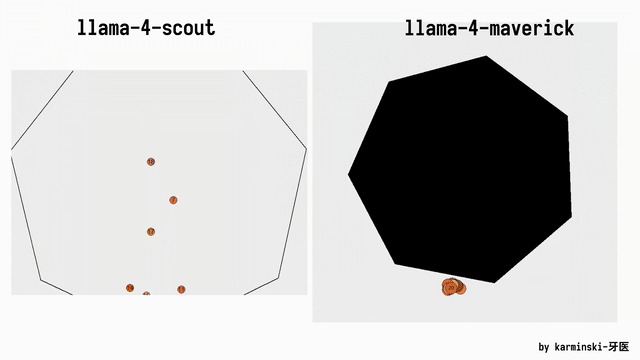
用他的话说,Llama 4 Scout小参数模型开心就好;足足有402B参数的Maverick模型的表现并不是很满意:
- Scout小参数模型大概接近Grok2的水平(咋还倒退了);
- 而Mavericks还不如使用DeepSeek-V3-0324;
- 总之不建议Llama 4写代码

按照KCORES LLM Arena的评测结果,目前最好的模型GPT-4.5-Preview。
当然,目前的测试只针对写代码,其他长文本和多模态领域还需要更多的测试案例。
Llama 4的另一个突破就是支持10M的上下文窗口长度,相当于20个小时的视频。

全网部署Llama 4
不管怎么说Llama 4的发布依然是开源模型的又一剂强心针。
各家巨头和平台同时宣布支持最新的Llama 4。
微软CEO Satya Nadella宣布马上将Scout和Maverick发布在Azure AI Foundry平台。
Cerebras宣布将在下周完成Llama 4最新模型的部署。
Together AI上也同步推出Llama 4模型,作为Meta的发布合作伙伴,还支持Together API的方式来访问Llama 4 Maverick 和Llama 4 Scout。

T3 Chat也宣布Llama 4 Scout和Maverick均已启动,Scout由Groq托管,而Maverick由OpenRouter托管,并且声明了小参数模型Scout非常便宜,决定免费发布。
Databricks数据智能平台宣布使用Llama模型来为AI应用程序、智能体和工作流程提供支持。
接下来还会有更多的平台跟进Llama 4最新模型,就像几个月前各家平台也是「疯狂」上线DeepSeek一样。
还有一个问题,为啥小扎选在他们的休息日发布Llama 4,马上就周一了啊?
Defined和Liftoff的联合创始人Nathan Lambert说顶尖Lab的领导们都会知道其他Labs的发布计划。
难道说小扎知道下周会有什么「疯狂」的模型发布可能会盖过Llama 4的风头,所以「赶鸭子上架」吗。

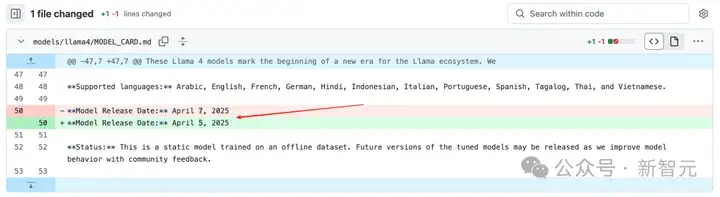
首先在Llama 4的Github Model_Card的更新日志中,发现一个改动:
模型发布的日期从美国时间的4月7号改到了4月5号(也就是我们4月6号的凌晨)!
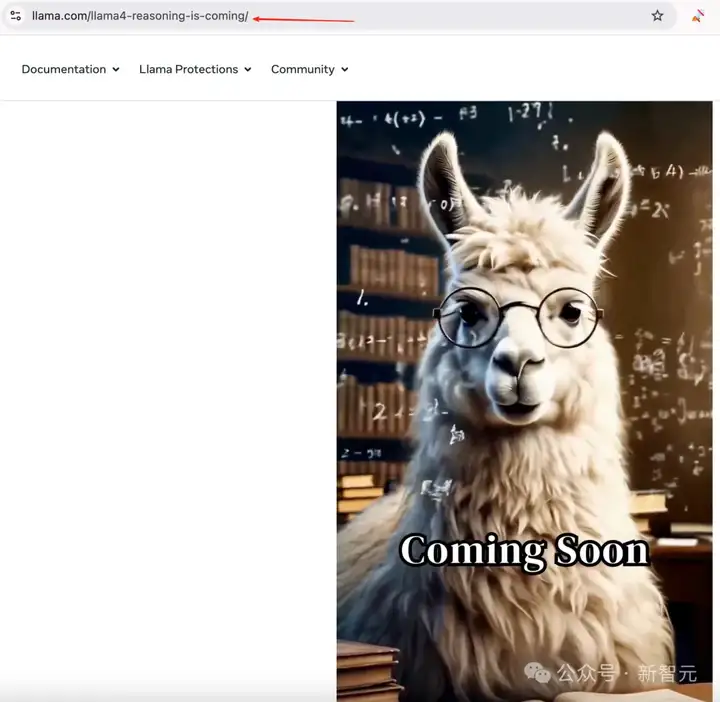
所以,周一Meta还会发布什么新模型吗?
在llama.com的官网上,我们看到了llama4-resoning-is-coming的后缀,似乎预示着llama-4推理模型也要马上发布了!
而奥特曼继续放出他的烟雾弹,在社交媒体不停的预热:OpenAI接下来也要放大招了!

而不论是此前奥特曼宣布GPT5、o3和o4-mini的消息,还是Llama 4的发布,还是DeepSeek和清华共同发布的论文,似乎预示着一件事:
所有人都在等待并期待着DeepSeek-R2!
请大家做好准备,也许下周即将是「疯狂」的一周。
参考资料:
https://x.com/karminski3/status/1908673924596195838
https://x.com/awnihannun/status/1908676110717771994
https://x.com/alexocheema/status/1908651942777397737
https://docs.google.com/spreadsheets/d/1mcRayUPtVJG_hOMruWWEf6T8TKbfTQIvH3WUkj_kx6E/edit?gid=0#gid=0
文章来自于“新智元”,作者“定慧 桃子”。

【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI

