
今天,我们正式发布jina-reranker-m0。这是一款多模态、多语言重排器(reranker),
其核心能力在于 对包含丰富视觉元素的文档进行重排和精排,同时兼容跨语言场景。
当用户输入一个查询(query)以及一堆包含文本、图表、表格、信息图或复杂布局的文档时,模型会根据文档与查询的相关性,输出一个排序好的文档列表。
模型支持超过 29 种语言及多种图形文档样式,例如自然照片、截图、扫描件、表格、海报、幻灯片、印刷品等等。
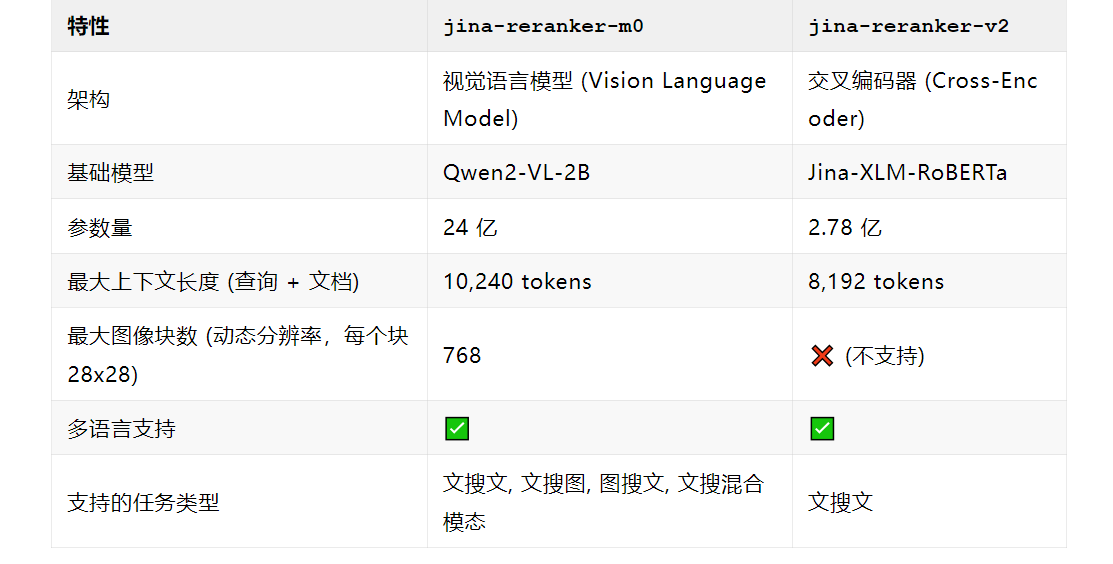
相较于前代纯文本的重排器 jina-reranker-v2-base-multilingual,jina-reranker-m0 不仅新增了处理视觉信息的能力,
在纯文本重排场景下,针对多语言内容、长文档及代码搜索等任务,其性能也得到了进一步提升。
开源链接:https://huggingface.co/jinaai/jina-reranker-m0
API 链接:https://jina.ai/?sui&model=jina-reranker-m0

上图展示了 jina-reranker-m0 在 ViDoRe、MBEIR 和 Winoground 这几个视觉检索基准测试上的表现。
印证了它在处理各种跨领域、跨语言的多模态检索任务上的强大能力。图里的每个数据点代表模型在特定类型的视觉文档或具体任务上的得分。
箱线图(boxplot)直观展示了这些得分的分布情况,高亮数字是平均性能。完整的基准测试结果,请参阅本文末尾的附录部分。

这张箱线图汇总了 jina-reranker-m0 在五个纯文本重排(Text-to-Text)基准测试上的性能。
每个基准测试可能涵盖多个数据集、语言或任务,图中每个点即代表一个具体测试实例的得分。箱线图描绘了整体得分的分布区间,高亮数字为平均性能。
这里需要注意一下,大部分基准测试用 NDCG@10 作为性能指标,但 MKQA 用的是 Recall@10,
因为 MKQA 的标注数据不支持计算 NDCG(官方评估用的是 recall,通过一些启发式规则来判断文档相关性)。完整的基准测试结果同样收录于文末附录。
全新架构
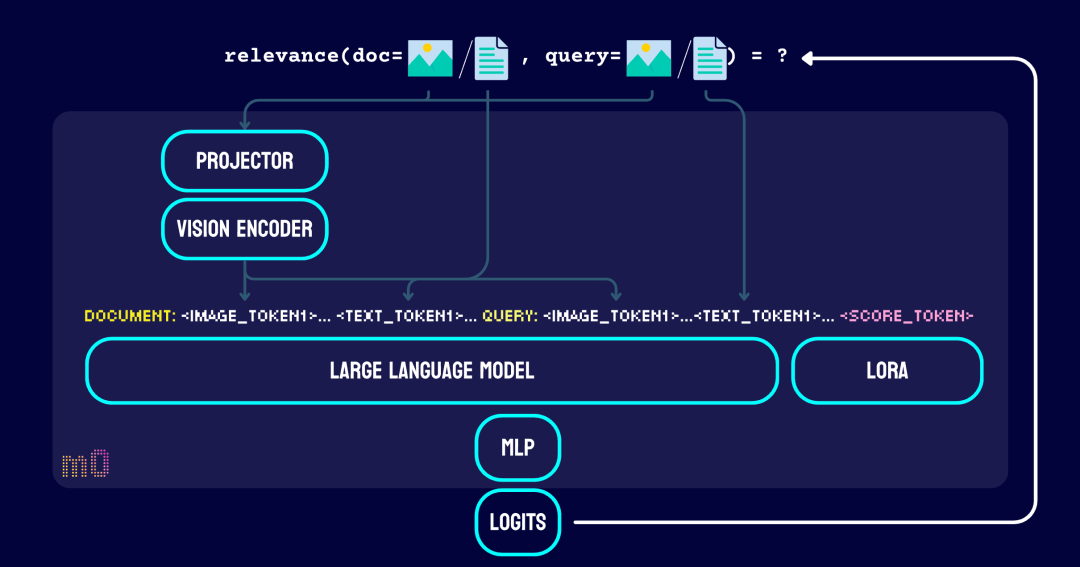
jina-reranker-m0 的模型架构基于 Qwen2-VL-2B 构建的,总参数量达到 24 亿。
该模型采用成对比较(pairwise comparison)机制,能够同时评估输入文档里的视觉和文本元素与查询的相关性,进而实现高效的文档排序。
跟 jina-reranker-v2-base-multilingual 不一样,
jina-reranker-m0 不再使用经典的交叉编码器(cross-encoder)架构,而是转向了仅解码器(decoder-only)的视觉语言模型。
它复用了 Qwen2-VL 预训练模型中的视觉编码器(vision encoder)和映射(projector),用 LoRA 对其中的大语言模型(LLM)部分进行了微调,
并且在之后额外训练了一个多层感知机(MLP),专门用于生成表征查询-文档相关性的排序分数(ranking logits)。
通过这种设计,我们构建了一个专门针对排序任务优化的判别式模型(discriminative model)。
这个新架构让 jina-reranker-m0 能处理长达 32K token 的输入,并且能无缝地结合图片和文本输入。
模型支持的图片尺寸范围很广,从最小的 56×56 像素到高达 4K 分辨率的图片都没问题。
处理图片时,ViT(Vision Transformer)和投影器协同工作,把相邻的 2×2 token 压缩成单个视觉 token,再输入给大语言模型。
像 <|vision_start|> 和 <|vision_end|> 这样的特殊 token 用来明确标示出视觉 token 的边界,
让语言模型能准确解析视觉信息,并把视觉和文本元素整合起来,进行复杂的多模态推理。
此架构还有效地缓解了模态鸿沟(modality gap)问题。这一问题曾困扰如 jina-clip-v1 和 jina-clip-v2 等早期模型。
在那些模型中,图像向量倾向于与图像向量聚集,文本向量则与文本向量扎堆,导致两者在表征空间中形成分离,存在一道鸿沟。
这就导致当你的候选文档既有图片又有文本时,用文本查询来检索图片效果就不好。
有了 jina-reranker-m0,你现在可以放心把图像和文档放在一起排序,不需要担心模态鸿沟,实现真正的统一多模态搜索体验。
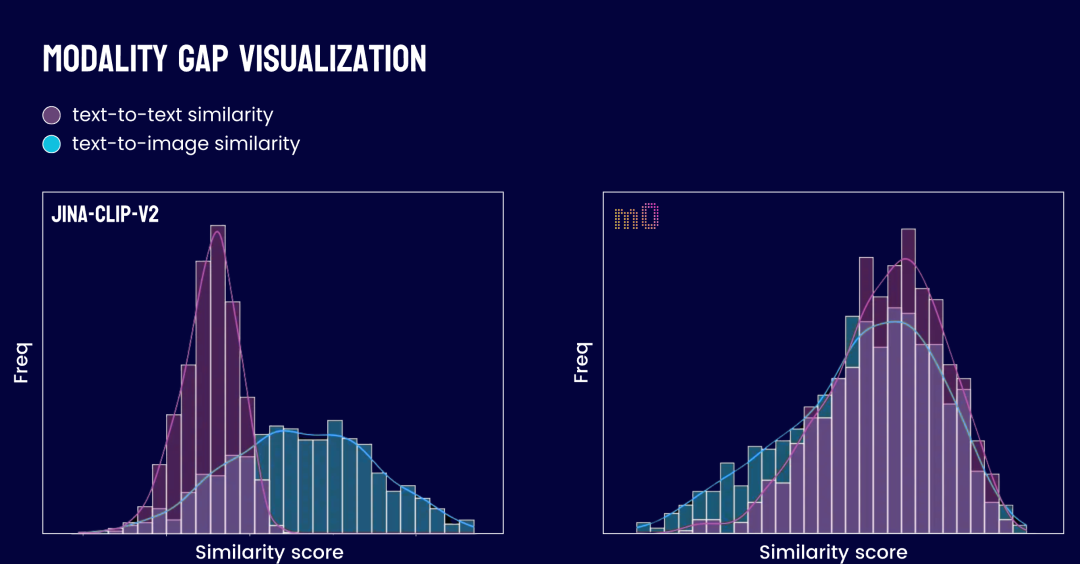
在多模态检索系统里,“模态鸿沟”指的是模型在给“文本到文本”相似度和“文本到图片”相似度打分时的差异。
看左边的图(代表 jina-clip-v2),两种分布明显分开了:
文本到文本相似度分布(红色)的峰值在 0.35 左右,而文本到图片相似度(蓝色)的峰值在 0.65-0.7 左右。
这种显著的分离说明存在巨大的模态鸿沟:模型给这两种配对打分时,用的根本不是一个评分区间。这就很难直接进行跨模态的分数比较。
理想情况下,在一个不存在模态鸿沟的系统(如 jina-reranker-m0)中,我们期望这两个分布能大体上重叠。
也就是说,模型在评估相关性时,主要依据内容本身的相关性,不看模态类型,并且对不同模态配对的打分范围保持一致。
需要说明的是,我们的训练过程限制了最大输入长度为 10K token,并且每张图像最多包含 768 token(在 <|vision_start|> 和 <|vision_end|> 之间)。
另外,我们没有针对“图像到图像”(image-to-image)、
“图像到多模态文档”(image-to-multimodal)或者“文本到多模态文档”(text-to-multimodal)这些重排任务进行训练。
这里的“多模态文档”指的是单个文档里同时包含图片和文本 token。
如果把查询和文档中所有可能的图片和文本 token 组合都考虑进去,jina-reranker-m0 支持的任务范围可以总结在下表中。
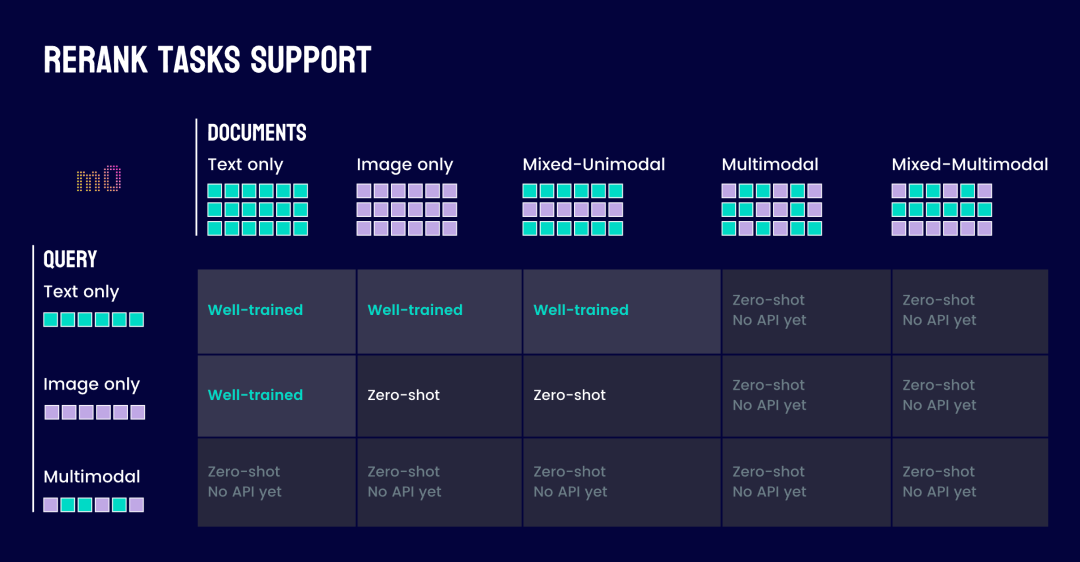
jina-reranker-m0 支持多种查询和文档输入组合来进行重排。经过显式训练与优化,在以下任务上达到了行业顶尖(state-of-the-art,SOTA)水平:
- 文本到文本 (Text-to-Text)
- 文本到图像 (Text-to-Image)
- 图像到文本 (Image-to-Text)
- 文本到混合单模态文档 (Text-to-Mixed-Unimodal):指使用文本查询对一个同时包含纯文本文档和纯图像文档的候选集进行统一排序
对于其他的输入组合(如图像到图像、图像到多模态文档、文本到多模态文档),模型也具备零样本(zero-shot)处理能力,
底层架构兼容这些模态组合的输入,只是训练阶段没有针对这些模态组合进行优化设计。
在内部测试中,我们观察到模型似乎具备一定的外推(extrapolation)能力,能够处理这些未经训练的排序任务。
当前阶段,这些任务上的有效性可以看做实验性功能,是模型零样本迁移(zero-shot transferability)能力的体现,或训练过程产生的非预期泛化效果。
我们尚未对这些零样本任务的性能进行系统性的严格评估,会在后续研究中对这些潜在能力做更深入的探索。
快速上手
通过 API 调用
下面的代码演示了如何计算查询 "small language model data extraction"(小语言模型数据提取)与一系列图片和文本文档之间的相关性得分。
你可以传入文本字符串、经过 base64 编码的图片,或者图片的 URL。新用户可以在 http://jina.ai 官网获取一个 Jina API 密钥,里面包含 100 万免费 token。
需要注意的是,我们的 API 目前还不支持用图片作为查询,但如果你通过 Hugging Face Transformers 库来使用模型,就可以用图片作为查询。
curl -X POST \
https://api.jina.ai/v1/rerank \
-H "Content-Type: application/json" \
-H "Authorization: Bearer JINA_API_KEY" \ # 这里换成你的 Jina API Key
-d '{
"model": "jina-reranker-m0",
"query": "small language model data extraction", # 你的查询
"documents": [ # 你要排序的文档列表
{
"image": "https://raw.githubusercontent.com/jina-ai/multimodal-reranker-test/main/handelsblatt-preview.png" # 图片 URL
},
{
"image": "https://raw.githubusercontent.com/jina-ai/multimodal-reranker-test/main/paper-11.png" # 图片 URL (ReaderLM-v2 论文截图)
},
{
"image": "https://raw.githubusercontent.com/jina-ai/multimodal-reranker-test/main/wired-preview.png" # 图片 URL
},
{
"text": "We present ReaderLM-v2, a compact 1.5 billion parameter language model designed for efficient web content extraction..." # 英文文本 (ReaderLM-v2 相关)
},
{
"image": "https://jina.ai/blog-banner/using-deepseek-r1-reasoning-model-in-deepsearch.webp" # 图片 URL
},
{
"text": "数据提取么?为什么不用正则啊,你用正则不就全解决了么?" # 中文文本 (不相关)
},
{
"text": "During the California Gold Rush, some merchants made more money selling supplies to miners than the miners made finding gold." # 英文文本 (不相关)
},
{
"text": "Die wichtigsten Beiträge unserer Arbeit sind zweifach: Erstens führen wir eine neuartige dreistufige Datensynthese-Pipeline namens Draft-Refine-Critique ein..." # 德语文本 (ReaderLM-v2 相关)
}
],
"return_documents": false # 设置为 false 表示只返回排序结果和分数,不返回原始文档内容
}'
下面是返回的结果,第一个结果 index=1 对应的是我们的 ReaderLM-v2 论文截图,它的相关性得分最高。

{"model":"jina-reranker-m0","usage":{"total_tokens":2829},"results":[{"index":1,"relevance_score":0.9587112551898949},{"index":3,"relevance_score":0.9337408271911014},{"index":7,"relevance_score":0.8922925217195924},{"index":2,"relevance_score":0.8891905997562045},{"index":0,"relevance_score":0.8827516945848907},{"index":4,"relevance_score":0.8701035914834407},{"index":6,"relevance_score":0.8676828987527296},{"index":5,"relevance_score":0.8455347349164652}]}
通过云厂商平台 (CSP Marketplaces)
jina-reranker-m0 现已上架 AWS、Azure 及 GCP 等主流云服务平台的官方市场 (Marketplace),可直接在相应平台查找并根据其定价方案进行订阅部署。
- AWS Marketplace:https://aws.amazon.com/marketplace/pp/prodview-ctlpeffe5koac?sr=0-1&ref_=beagle&applicationId=AWSMPContessa
- Azure Marketplace: https://azuremarketplace.microsoft.com/en-us/marketplace/apps/jinaai.jina-reranker-m0?tab=Overview
通过 Hugging Face
你也可以从我们的 Hugging Face 页面把模型下载到本地使用。我们准备了一个 Google Colab notebook 来演示怎么操作。
跟我们的官网 API 相比,本地使用模型要更灵活,比如可以用图片作为查询,还能处理包含图文的混合模态文档。
Google Colab 教程:https://colab.research.google.com/drive/1gNTJHbdYSdgOEAea7kB6XaW56Zala0vk?usp=sharing
总结
jina-reranker-m0 代表了我们在 reranking 任务上的一次架构性转变:首次采用统一的、基于 VLM 的 decoder-only 方案。
这背后其实是建立在我们先前开发一系列 encoder-only 模型(如 jina-clip-v2, jina-embeddings-v3, jina-reranker-v2 等)所积累的工程经验和认知之上。
这次架构升级带来了两个核心进展:首先,原生支持了多模态输入,使得处理图文混合文档的排序、文搜图重排等成为可能;
其次,在纯文本任务上(特别是代码和长文本),其性能相较于之前的 jina-reranker-v2-base-multilingual 也有所提升。
模型的“m 系列”命名就强调了其多模态(multimodal)的核心特性。
在对比 jina-reranker-m0 和 jina-reranker-v2-base-multilingual 时,我们对 m 系列的目标是:在实现多模态能力的同时,也要保持甚至提升纯文本处理性能。
有人可能要问,如果纯文本任务的性能提升看起来不大,那用一个 8 倍大的模型有什么价值呢?
确实,对于仅需处理标准长度、纯文本的场景,m0(参数量约 2.4B)相较于 v2(约 278M)的边际性能提升,
可能不足以完全抵消其 8 倍的参数量增长带来的部署成本。在这种特定约束下,v2 仍是更好的选择。
但采用 decoder-only 架构的意义远不止是优化传统指标,而是在于解锁了 encoder-only 架构无法支持的新功能:
- 统一的混合模态重排:能够直接处理查询与包含不同模态(文本、图像)文档集的复杂排序场景。
- 实现列表式重排(Listwise reranking)和文档去重:decoder 模型更自然地支持将整个候选文档列表作为上下文进行联合评估,
从而实现更优的全局排序效果和内置去重逻辑。
- 基于注意力机制的可解释性:decoder 架构固有的注意力机制为理解模型的排序决策过程、分析特征重要性提供了基础,提升了模型的可解释性潜力。
基于以上判断,我们后续的技术路线将围绕两个重心展开:一是持续优化模型的基础文本重排性能;
二是更深入发掘并工程化落地由 decoder-only 多模态架构所带来的新特性,推动搜索技术向着能力更强、适用场景更广泛的目标演进。
附录:完整评测
完整的评估数据及细节,请查阅这个 Google Spreadsheet 链接:
https://docs.google.com/spreadsheets/d/1KrCD7l0lhzMkyg3z-gEDmymxe4Eun9Z-C0kU3_cxw7Q/edit?usp=sharing
我们在多个公开基准上评估了 jina-reranker-m0 的性能,以全面了解其在不同场景下的表现,以下是评估结果概括:
核心优势领域
1.多模态处理能力: 这是 m0 跟其他 reranker 不一样的地方。在 ViDoRe(视觉文档检索,NDCG@5 达 91.02)和 M-BEIR(跨模态检索,比如文搜图、图搜文)这些基准上,m0 表现非常扎实,能够有效理解并排序包含丰富视觉信息的文档,效果明显好过纯文本模型,也优于我们测的一些同类多模态竞品(如基于 Qwen2-VL 的 MonoQwen2-VL-v0.1)。即使在考验模型细粒度组合推理的 Winoground 基准上,这对所有模型来说都很难,但 m0 的得分也是相对最高的(平均 43.92)。
2.代码检索能力: 在 CoIR 基准上,m0 的表现很突出(平均 NDCG@10 达 63.55),大幅领先于其他通用重排模型(如 bge-reranker-v2-m3),也比我们之前的多语言模型 (jina-reranker-v2-multilingual)强不少,甚至比一些专门的代码向量模型 jina-embeddings-v2-base-code 在重排任务上的表现更好),印证了它在理解代码语义和结构方面的强大能力。
3.长文档处理能力: 在 MLDR(多语言长文档)基准上,m0 同样拿下了最佳性能(平均 NDCG@10 达 59.83),说明它能有效处理更长的输入序列,适合深度理解上下文的应用场景。
4.常规文本检索(英语 & 多语言):
- 在 BEIR(英语为主的标准文本检索集合)上,它的平均分 (58.95) 是最高的。
- 在 MIRACL(覆盖 18 种语言)上,m0 的竞争力也很强(平均 66.75),虽然总平均分略低于 bge-reranker-v2-m3(69.32),
但在不少具体语言上打平甚至反超。
- 在 MKQA(24 种语言的问答式检索)上,m0 的平均 Recall@10 (68.19) 又是最高的。
测试背景补充
主要对比模型包括我们之前的 jina-reranker-v2-base-multilingual、社区流行的 bge-reranker-v2-m3、以及基于相似基础模型构建的 MonoQwen2-VL-v0.1 等。
评估指标根据基准标准选择,主要是 NDCG@k 或 Recall@k,具体 k 值(如 5 或 10)已在各基准说明中提及。
评估覆盖了纯文本(英语、多语言、长文档、问答、代码)和多模态(视觉文档、跨模态图文、组合推理)等多种场景。
文章来自于微信公众号 “Jina AI”,作者 :Jina AI

【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

