OpenAI o1/o3-mini级别的代码推理模型竟被抢先开源!UC伯克利和Together AI联合推出的DeepCoder-14B-Preview,仅14B参数就能媲美o3-mini,开源代码、数据集一应俱全,免费使用。
OpenAI o1/o3-mini级的推理模型,竟被抢先开源了?
刚刚,来自UC伯克利和Together AI的联合团队,重磅推出了一款完全开源的代码推理模型——DeepCoder-14B-Preview。
现在,只需要14B就可以拥有一个媲美o3-mini的本地模型,并且完全免费!
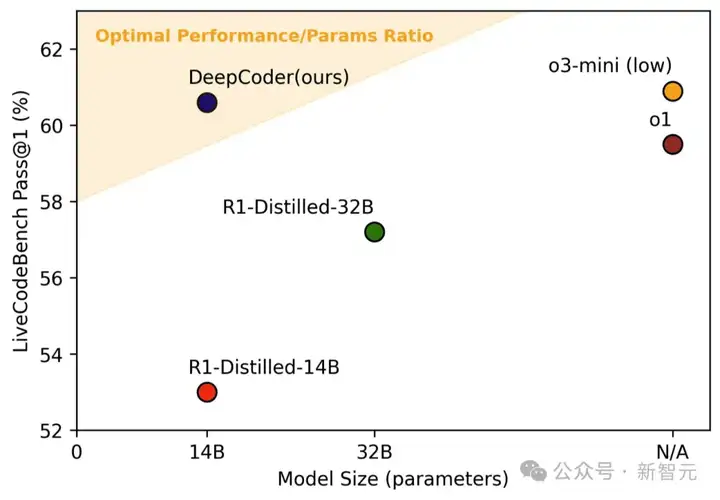
DeepCoder-14B-Preview通过分布式RL从Deepseek-R1-Distilled-Qwen-14B微调得来。
在LiveCodeBench基准测试中,它的单次通过率(Pass@1)达到了60.6%,提升幅度高达8%。
至此,又见证了强化学习的胜利。
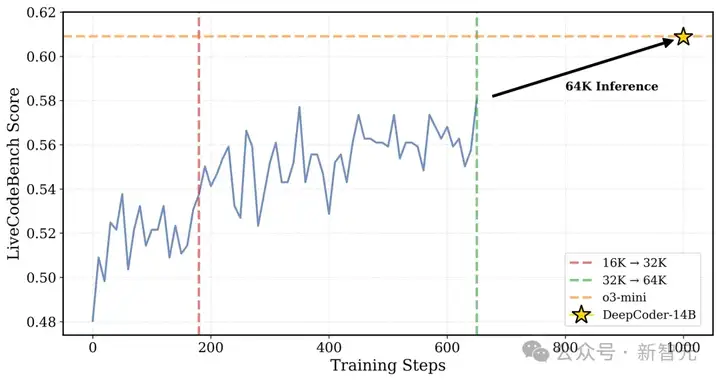
DeepCoder在训练过程中的LiveCodeBench (LCB) 得分:训练到第180步的时候,上下文长度扩展到了32K;用32K时最佳的检查点来做推理,并且把上下文扩展到64K,这时LCB得分能达到60.6%,和o3-mini性能相当
同时,团队还开源了verl-pipe,这是verl后训练系统的扩展,集成了多项系统优化,能让端到端的训练速度提高2倍。
对此网友们称赞:这是完全开源的胜利,不仅仅是模型,数据集、代码、训练日志也开放。

值得一提的是,DeepCoder-14B-Preview基于24K个可验证的编程问题,在32个H100 GPU上训练了2.5周。
数据集构建
数学领域的研究发现,强化学习要是有可验证的奖励机制,能显著提升模型的推理能力。
在数学领域,网上能找到好多高质量、可验证的数据,编程则相对稀缺。
在早期实验中,团队评估了几个常见的代码数据集,像APPS、TACO、CodeContests、KodCode和LeetCode。
结果发现,有些数据集对模型来说太简单了,如KodCode和LeetCode;还有些数据集有噪声,或者里面的测试用例有缺陷、不完整,不可验证。这会给出错误的奖励信号,让RL训练无法稳定进行。
为解决这些问题,研究者整理出一个高质量的训练集,包括:
- TACO里已验证过的问题。
- PrimeIntellect的SYNTHETIC-1数据集中经验证的问题。
- 2023年5月1日到2024年7月31日提交的LiveCodeBench问题。
为保证数据质量,让RL训练能顺利开展,有一套严格的过滤流程:
- 程序化验证:每个问题都会用外部官方的解法自动检查一遍,只保留官方解法能通过所有单元测试的问题,检查过程在tests/rewards/test_code_batch.py脚本中自动完成。
- 测试过滤:每个问题至少包含5个单元测试。测试用例少的问题容易让模型钻空子,模型通过识别常见测试用例,学会简单地输出记忆的答案,即「奖励黑客」。
- 去重:研究者会把数据集中重复的问题都去掉,防止互相干扰。他们对Taco Verified、PrimeIntellect SYNTHETIC-1和LCB(2023年5月1日-2024年7月31日)这三个训练数据集做了去重处理,还检查了测试数据集LCB(2024年8月1日-2025年2月1日)和Codeforces的57个竞赛数据集。
过滤后,得到24K个高质量的编程问题,用于RL训练,其中7.5K个来自TACO Verified,16K个来自PrimeIntellect SYNTHETIC-1,600个来自LiveCodeBench。
代码沙盒环境
为了计算代码RL训练的奖励,得在代码沙盒里,对模型生成的代码进行单元测试。
每个RL迭代过程,用1024个问题来评估训练效果,每个问题至少有5个单元测试。
这么多测试任务,就得靠100多个代码沙盒一起并行运行,才能在合理的时间内,准确验证模型生成的代码。
目前,研究者用了两种沙盒:Together代码解释器和本地代码沙盒。
Together代码解释器
这个环境速度快、效率高,能直接用在RL训练上,每个问题的成本仅3美分。
Together代码解释器已支持100多个沙盒同时运行,每分钟能执行1000多次沙盒操作。
这些沙盒能访问标准输出(stdout)、标准输入(stdin),还能评估代码最后一行输出的结果。
同时,它能把代码运行的环境和主机系统隔离开,保证安全。
本地代码沙盒
本地代码沙盒是通过启动一个独立的、有防护的Python子进程来运行的。它从标准输入(stdin)接收测试用例的输入,然后把答案输出到标准输入(stdout)。
本地沙盒用的是LiveCodeBench官方代码库里的评估代码,确保测试结果和现有排行榜一致。
奖励函数
有些奖励方式容易让模型作弊,比如给思维链(CoT)惩罚,或者N个测试中有K个通过就给K/N奖励。
奖励函数采用稀疏结果奖励模型(ORM),具体奖励规则是这样的:
- 奖励为「1」:生成的代码必须通过所有抽选的单元测试。有些问题有几百个测试用例,全部验证不太现实,所以会根据输入字符串的长度,每个问题挑出15个最难的测试(根据输入字符串的长度来判断)。
- 奖励为「0」:要是模型生成的代码有一个测试用例没通过,或者答案格式不对(比如缺少python[CODE]标记),就没有奖励。每个测试用例都有6-12秒的时间限制。
训练方法
GRPO+
研究者参考了DAPO的关键思路,改进了GRPO算法,让训练过程更稳定:
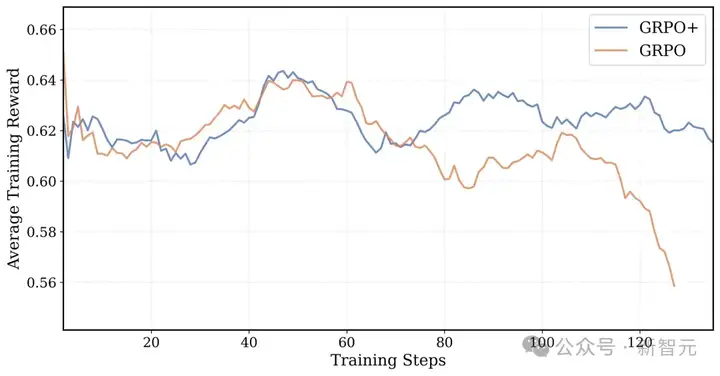
GRPO+和GRPO在16K上下文训练中的平均训练奖励:GRPO的奖励曲线最后会崩溃,GRPO+因为有Clip High机制,奖励曲线保持稳定
- 无熵损失:加上熵损失项,很容易让训练不稳定,熵值指数级增长,导致训练崩溃。因此移除了熵损失项。
- 无KL损失(源自DAPO):去掉KL散度损失,LLM就不会被限制在原来监督微调(SFT)模型的置信区域内。还能省掉为参考策略计算对数概率,训练速度也就更快了。
- 超长过滤(源自DAPO):为保留长上下文推理能力,对超出长度而被截断的序列做了特殊处理。这项技术使DeepCoder即使在32K上下文环境中训练,在64K上下文下也能推理。这种过滤方法允许响应长度自然增长,而不会因截断而受到惩罚。
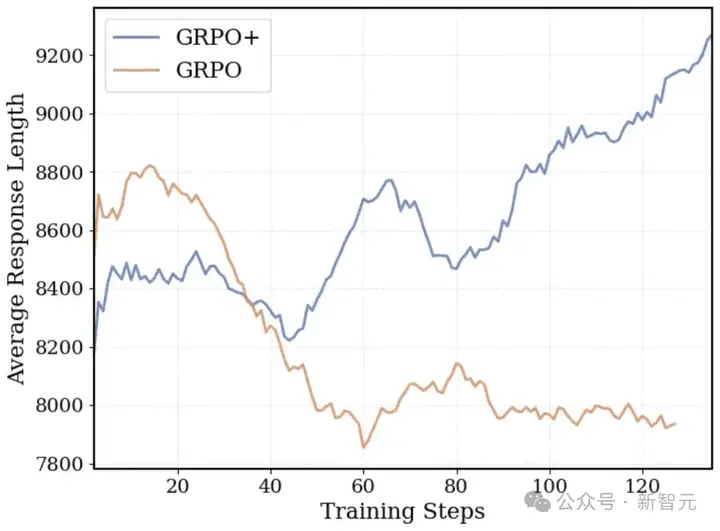
由于采用超长过滤机制,GRPO+的响应长度随训练时间稳步增长
- Clip High(源自DAPO):通过提高GRPO/PPO代理损失的上限,鼓励模型尝试更多不同的可能,熵值也更稳定。这样调整后,训练更稳定,模型性能也有提升。
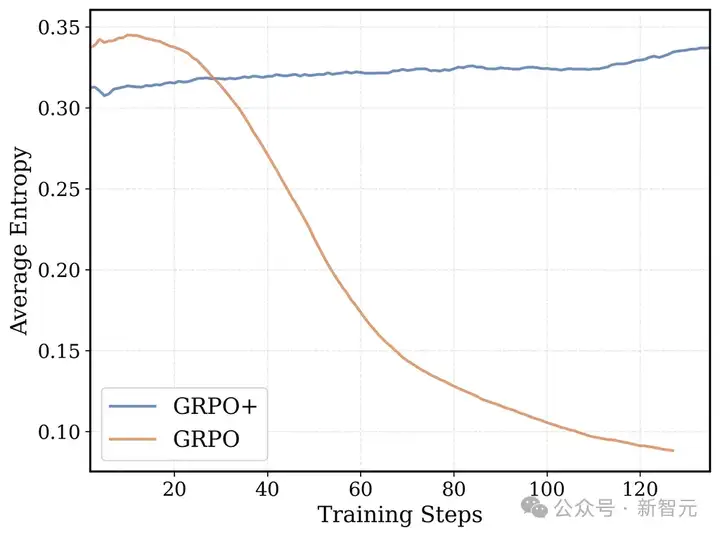
Clip High机制和没有熵损失,能保证GRPO+的token级熵不会崩溃,鼓励模型充分探索
迭代式上下文扩展
在DeepScaleR的介绍中,提到过迭代式上下文扩展技术。它能让模型先在短一点的上下文里学会有效思考,然后再应用到更长的上下文。
这个方法曾让1.5B参数模型的下游任务性能稳步提升,随着上下文窗口从8K扩大到16K,再到24K的过程中,在AIME测试里的准确率从33%提高到38%,最后到了43%,最终达到了o1-preview的水平。
不过,将这个技术用在14B参数模型的时候,遇到了新问题:
- 14B参数模型本身推理能力就很强,想要再提升,就得解决更难的问题。
- 这些更难的问题往往需要比8K更长的上下文窗口,而8K是之前小模型训练的起始上下文长度。
如果一开始用短上下文训练,模型输出超出这个长度就惩罚它,这样做效果不好。模型的初始性能会下降,输出的内容也会变短,长上下文的推理能力也会变弱。
为了在保证训练效率的同时,让模型能处理长上下文推理,研究者引入了DAPO的超长过滤技术。在训练的时候,会忽略那些因为太长被截断的序列,这样模型就算生成的内容长一点,也不会被惩罚。
因此,模型即使在较短的上下文中训练,也能「想得长远」。
研究者把迭代上下文扩展用在DeepCoder-14B-Preview上,把训练的上下文窗口从16K扩大到32K,LiveCodeBench基准测试中,模型表现如下:
- 在16K和32K上下文长度下,准确率从54%提升至58%。
- 在64K上下文长度评估时,达到了60.6%。
这说明模型的泛化能力很强,超出了训练时的上下文范围也能表现得很好。
和DeepSeek-R1-Distill-Qwen-14B这种基础蒸馏模型比起来,DeepCoder-14B-Preview的泛化能力就更突出了。
基础蒸馏模型一旦超出训练时的上下文长度,性能就很难提升了。

虽然DeepCoder因为平均响应长度较长,在16K上下文长度下的原始性能低一些,会因为截断和格式问题扣分,但它在长上下文的推理能力很强,最终在64K上下文长度的评估中超越了其他模型。
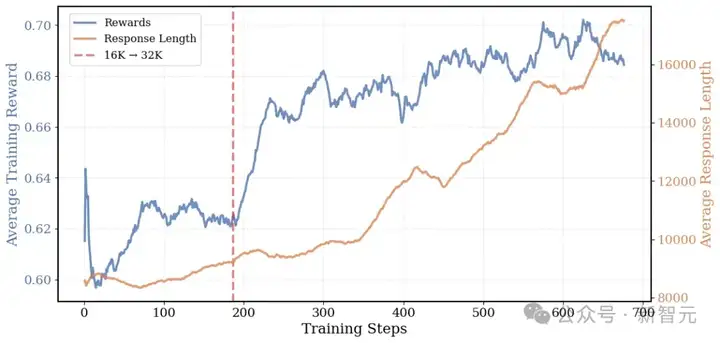
DeepCoder在训练过程中的平均响应长度和训练奖励:平均响应长度从8K增长到17.5K
DeepCoder的成功,正是把迭代上下文扩展和超长过滤技术结合起来了。
从图中可以看到,在训练过程中,模型的平均响应长度从8K增长到17.5K,平均奖励也从0.6提高到 0.7。说明随着时间推移,模型学会了更厉害、更有条理的思考方式。
关键技术改进
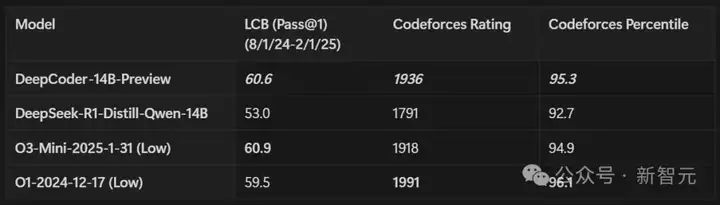
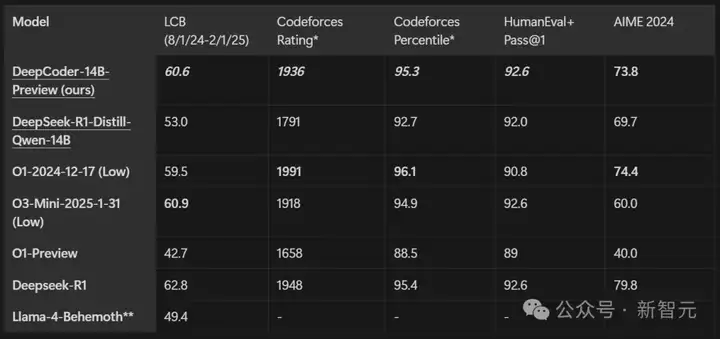
在多种编程基准上对 Deepcoder-14B-Preview 进行了评估,包括LiveCodeBench (LCB)、Codeforces、HumanEval+以及AIME2024数学竞赛。
凭借14B的参数量,模型在所有编程基准上均展现出强劲性能:在LiveCodeBench上实现了60.6%的Pass@1准确率,在Codeforces上获得了1936的评分,其表现可与o3-mini (low) 和o1模型相媲美。
训练耗时太长?系统优化来帮忙
使用长上下文对LLM进行强化学习(RL)训练非常耗时,需要在长上下文环境中反复进行采样和训练。
若无系统层面的优化,完整的训练流程可能耗费数周乃至数月。14B参数编程模型训练,每一步就得花1200至2500秒,总训练时长达到2.5周!
团队引入并开源了verl-pipeline。它是开源RLHF库verl的一个优化版本,用了多项系统级改进措施,旨在加速端到端的RL训练过程。
相较于基准的verl实现,verl-pipeline实现了高达2.5倍的速度提升。
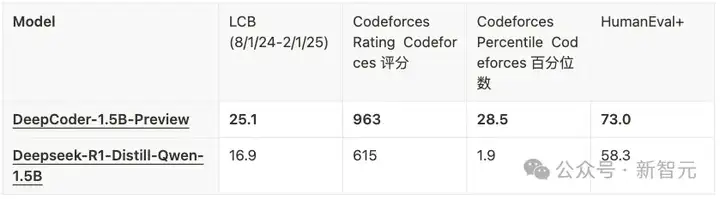
运用这些新的系统优化来训练DeepCoder-1.5B-Preview模型,该模型在LiveCodeBench上的准确率达到了25%,相比Deepseek-R1-Distill-Qwen-1.5B提升了8%。
采样器是瓶颈
在后训练中,采样往往是拖慢整体进度的关键因素。这是因为用vLLM和SGLang这类推理引擎生成32K token的长序列时,会产生延迟。
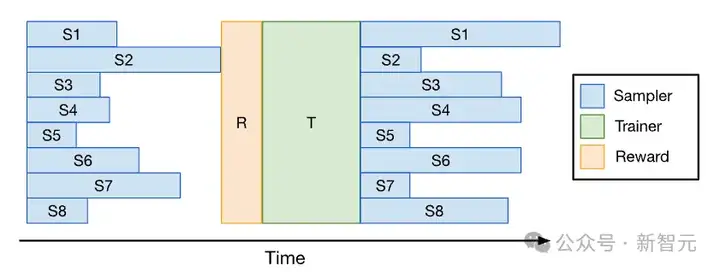
Verl的PPO/GRPO训练流程:每次RL迭代都包含采样、奖励函数计算和训练这三个阶段;其中,采样是整个训练流程的瓶颈,训练速度受限于那些生成较长序列的掉队采样器(straggler samplers)
RL训练系统通常受限于采样时间——上图展示了Verl的PPO/GRPO流水线,其中响应长度的不一致性导致部分采样器成为掉队者。
这些掉队者会拖慢训练进度,而先完成任务的采样器则处于空闲状态,从而导致GPU利用率低下。
朴素解决方案:小批流水线化
为了减少RL训练过程中的空闲时间,研究者将采样和训练过程流水线化(Minibatch Pipelining)。
如此一来,训练器在采样器继续生成后续数据批次的同时,就会开始利用较早到达的小批数据进行模型更新。这种重叠执行有助于减少采样带来的延迟。
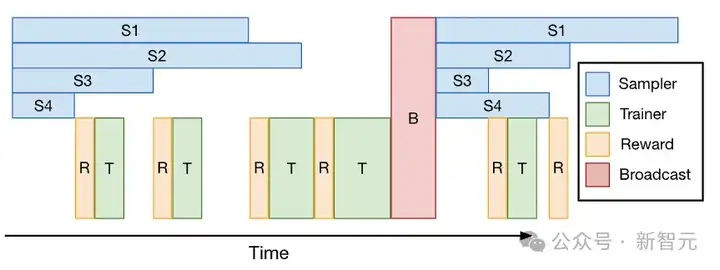
小批流水线:采样器和训练器分别在不同的工作机组中运行;当完成采样并释放小批量数据(用于PPO/GRPO训练)后,训练器会异步处理这些数据;在一次迭代结束时,训练器会将更新后的权重给采样器
然而,这种方法存在三个关键的局限性:
- 小批数据的平均序列长度往往随训练进展而增长,这增加了处理后续小批的训练时间。结果就是,最后几个小批数据常常在采样阶段结束后才能处理完毕,从而限制了流水线化带来的实际效益。
- 流水线化需要在采样器和训练器之间静态划分GPU资源,这减少了可用采样器的数量。不同于Verl可以在同一个GPU池中动态地切换采样器和训练器角色,这种静态划分因采样器数量减少,可能反而会延长端到端的总采样时间。
- 奖励函数的计算可能耗时很长,特别是对于编程类任务,每个RL迭代都需要运行数千个单元测试。在Verl的默认设置中,奖励计算是在所有采样任务完成后,在头节点(head node)上集中进行的。
尽管存在这些约束,团队在代码库的ray_trainer_pipeline.py文件中实现了小批流水线化,并且需要指出的是,这种流水线技术可以通过引入微批处理(microbatching)来进一步优化。
DeepCoder的解决方案:一次性流水线化
为实现训练、奖励计算和采样的完全流水线化,研究者引入了一次性流水线化(One-Off Pipelining)。
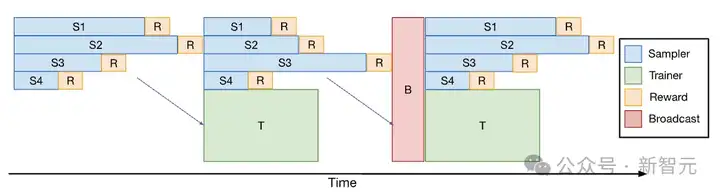
一次性流水线:采样器会提前一个迭代周期生成一批数据,而训练器则使用上一次迭代的数据来更新梯度;此外,奖励函数的计算与采样过程是交错进行的;这种方法不会为GRPO/PPO的策略算法引入异步离策略样本
其思路非常简单:牺牲第一个RL迭代,仅执行采样任务,然后利用这个采样得到的数据批次在下一个迭代中进行训练。
这样一来,采样和训练就能并行处理,彻底消除了采样完成后训练器的等待空闲时间。
其次,奖励计算被嵌入到采样流程中,与之交错执行。
一旦某个采样请求完成,其对应的奖励会立即被计算出来——这有效减少了奖励评估环节的开销,特别是对于计算密集型任务(例如编程任务中的测试用例执行)而言效果显著。
团队在代码库verl分支(fork)中的ray_trainer_async.py文件里实现了一次性流水线化。
端到端性能
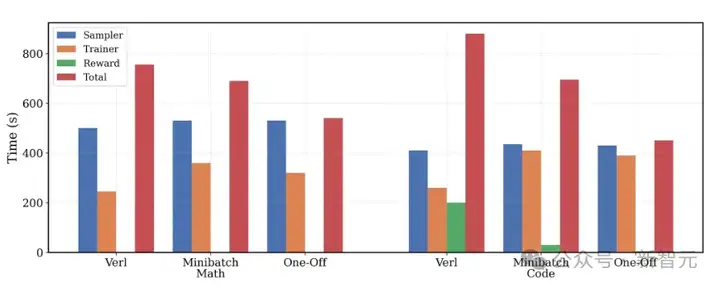
一次性流水线完全掩盖了训练器和奖励计算的时间,数学任务训练时间缩短1.4倍,编程任务缩短2倍
上图展示了对verl、小批流水线化和一次性流水线化在两种工作负载(数学和编程)下的评估结果。
为确保公平性,所有基准方法都利用Python线程池并行计算奖励;而verl官方实现是串行计算每个样本的奖励,这种方式对于编程任务来说耗时过长,难以实际应用。
在8块A100 GPU上对Deepcoder-1.5B-Preview进行了评估,并细致调整了采样器与训练器的资源配比,旨在更好地平衡两者所需的时间开销。
- 对于数学任务:一次性流水线化将每次RL迭代所需时间缩短了1.4倍。值得注意的是,数学任务的奖励计算时间几乎为零,因为它仅涉及基础的Sympy检查。特别之处在于,一次性流水线化能够完全掩盖(mask away)训练器所需的时间,这与小批流水线化中最后一个小批会「溢出」(spill over)导致延迟的情况形成了对比。
- 对于编程任务:计算奖励需要在每次RL迭代中运行数千个单元测试,这是一个非常耗时的过程。一次性流水线化能够同时掩盖训练器时间和奖励计算时间,从而将端到端的训练总时长缩短了2倍。
最关键的是,一次性流水线化不仅切实有效,而且能成功扩展应用于复杂的编程任务。
DeepCoder使用ray_trainer_async.py(采用一次性流水线化)训练了DeepCoder-1.5B-Preview,其在 LiveCodeBench (LCB) 上的得分相较于基础的蒸馏模型提升了8%。
作者介绍
Sijun Tan(谭嗣俊)

谭嗣俊是UC伯克利计算机科学专业的三年级博士生,导师是Raluca Ada Popa。隶属于伯克利的Sky Computing Lab。
此前,他在弗吉尼亚大学获得计算机科学和数学双学士学位,导师是David Wu和Yuan Tian。
他曾在Facebook AI Research(FAIR)实习过一段时间,并在蚂蚁集团担任过高级算法工程师。
他的研究领域涵盖机器学习、计算机安全和应用密码学。目前,其研究重点是增强通用型AI智能体的能力和鲁棒性。
Michael Luo

Michael Luo目前是UC伯克利电气工程与计算机科学系(EECS)的博士生,导师是Ion Stoica教授。
在此之前,他获得了UC伯克利电气工程与计算机科学硕士和工商管理双学士学位。
他的研究兴趣主要在人工智能和系统领域。目前,其研究主要是为机器学习从业者构建可扩展的系统,以实现Sky Computing的愿景。
Roy Huang

Roy Huang目前是UC伯克利计算机科学专业的大四学生,对CV和NLP领域的研究感兴趣。
参考资料:
https://pretty-radio-b75.notion.site/DeepCoder-A-Fully-Open-Source-14B-Coder-at-O3-mini-Level-1cf81902c14680b3bee5eb349a512a51https://huggingface.co/agentica-org/DeepCoder-14B-Previewhttps://x.com/togethercompute/status/1909697124805333208
文章来自于“新智元”,作者“编辑部 HXs”。

【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

