4月9日,中国科学院深圳先进技术研究院娄春波团队与北京大学定量生物学中心钱珑团队成功推出一款生物制造大语言模型SYMPLEX。
SYMPLEX是全球首个面向合成生物学元件挖掘与生物制造应用的大语言模型。
该模型能够自动高效地从海量生物文献中发现具有目标功能的关键基因,并进行精准筛选和功能验证,为后续的蛋白质功能设计、生物制剂开发以及生物制造的应用提供科学依据。
SYMPLEX网页版
目前,研究已经发表到Science Advances上,同时SYMPLEX网页版也正式上线,供研究人员免费使用。
全球首个,面向生物制造元件
合成生物被视为引领生物制造变革和生物经济发展的颠覆性技术,被誉为“第三次生物技术革命”。
通过为设计、改造或从头合成生物元件、代谢路径乃至完整基因组,构建具有特定功能的人工生命系统,为解决人类发展在环境、资源、能源等方面面临的若干重大挑战提供新技术方案。
其中,生物元件是合成生物学中基本要素之一,也是合成生物学的基石。
通过设计这些元件,科学家能够精确调控基因表达、代谢途径和信号传递,实现生物系统的工程化改造。
尤其从自然界基因组中大规模挖掘新的酶蛋白元件,则是其中的重要研究领域。
目前,通过大规模测序技术(如宏基因组、转录组)获取海量生物基因数据后,当前仅有少数明星基因被深度挖掘,绝大多数仍处于“沉睡”状态。
因此利用各类手段进行对比分析,并识别编码特定功能的基因序列,用于挖掘环境中的未培养微生物基因资源,是当前合成生物元件的一大挑战。
针对这一难题,研究人员打造了SYMPLEX模型。
它能够自动化阅读和理解千万级体量的生物学文献,在基因、功能和知识水平上对文献内容进行提取分析,实现了从海量文献中自动化挖掘功能基因元件,并精准评估其工程化应用潜力。
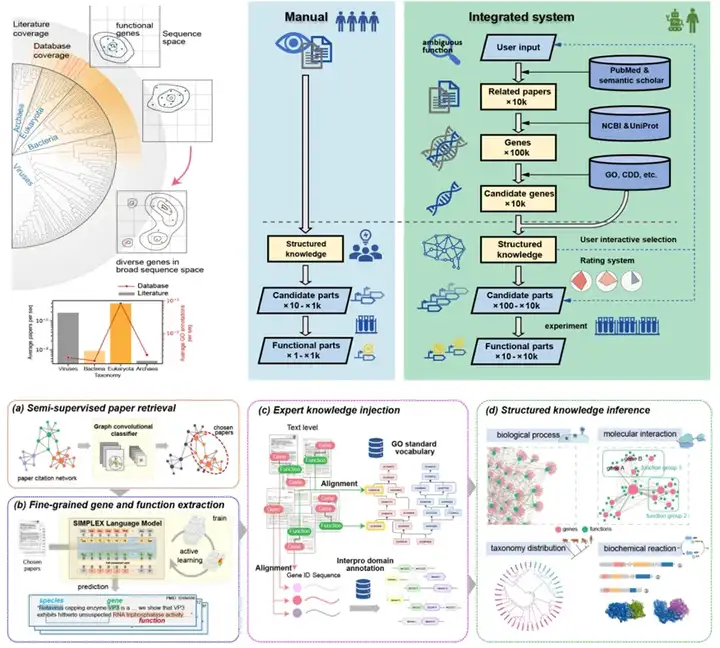
SYMPLEX技术路线及其与传统基因挖掘流程的对比
团队为了量化模型效果,SYMPLEX大规模挖掘mRNA 加帽酶,并进行了实验验证。
mRNA 5’端加帽一直是mRNA疫苗生产的难点。加帽过程对于稳定mRNA、促进翻译和减少免疫反应至关重要,而目前mRNA疫苗生产传统工艺选择极为有限且价格昂贵。
于是,研究团队将SYMPLEX应用于加帽酶的挖掘,识别出16,685个与 mRNA 加帽相关的基因,并进一步筛选出75类(18,779 条序列)高置信度的完整加帽酶基因。
经过46种候选基因实测,研究团队获得了14种可在哺乳动物和酵母细胞中稳定发挥作用的加帽酶。
第三方公司实验验证显示,这些酶在催化效率上超越国际头部企业商业化加帽酶2倍以上,显著提升了mRNA疫苗生产率和成本效益。
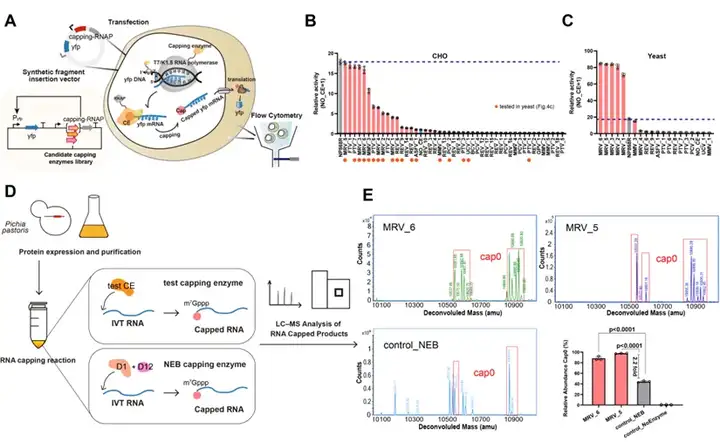
候选加帽酶在细胞体系和体外转录体系中的表现
此项成果不仅为合成生物学元件设计提供了AI驱动的新范式,更展现了大语言模型等人工智能技术在生物制造中的广阔应用前景。
网页版已上线
目前,SYMPLEX在线交互式平台已上线供研究人员免费使用。
https://bdainformatics.org/page?type=SYMPLEX
平台采用模块化设计,提供三个核心功能:
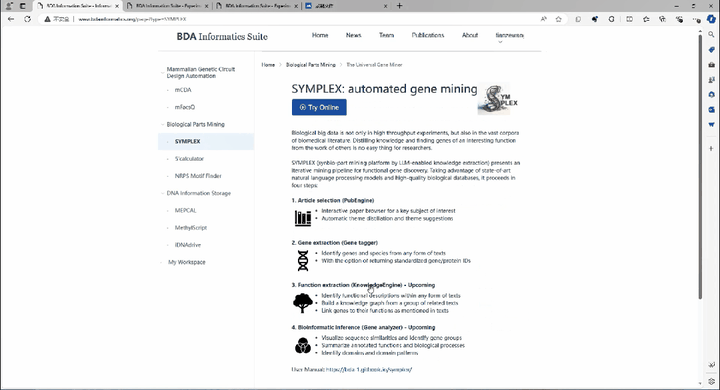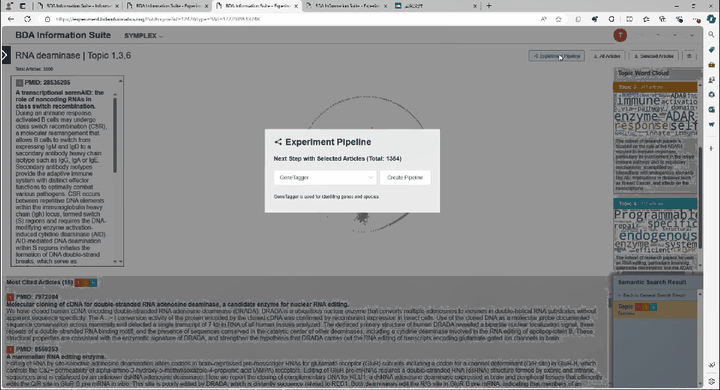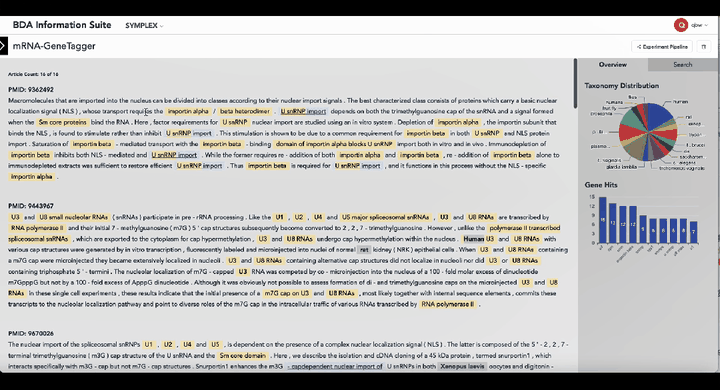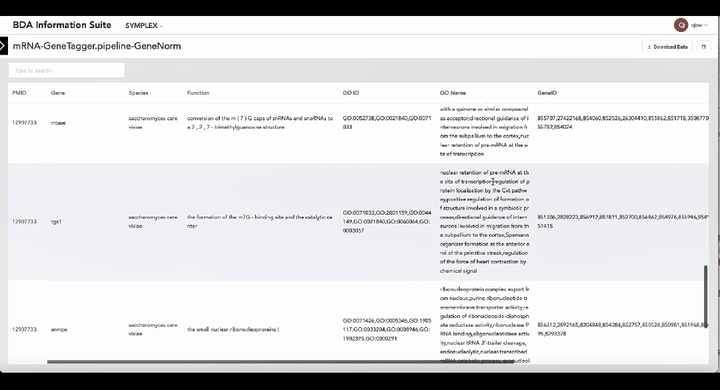
(1)文献智能提取引擎PubEngine:支持高通量的文献智能检索分析与可视化交互;
(2)基因功能标注系统GeneTagger:实现从分子机制到生物过程的细粒度自动化基因与功能提取;
(3)标准化知识中枢GeneNorm:实现与专家知识库的概念对齐与标准化,支持知识树构建和功能模式识别。
各模块既可无缝协同实现高效数据流转,又能独立运行,以加速功能基因挖掘以及蛋白质设计。
简单而言,本项研究开创了功能基因深度挖掘的新范式,利用大语言模型高效推动生物知识转化,为mRNA疫苗规模化生产提供了关键酶资源库。
研究团队正利用SYMPLEX挖掘更多可用于生物制造和合成生物学的关键酶元件,并将该平台拓展至合成通路设计等领域,有望推动生物制造进入“AI for Science”新纪元。
文章来自微信公众号 “ 智药局 ”

【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT


