RTP-LLM 是阿里巴巴大模型预测团队开发的高性能 LLM 推理加速引擎。它在阿里巴巴集团内广泛应用,支撑着淘宝、天猫、高德、饿了么等核心业务部门的大模型推理需求。在 RTP-LLM 上,我们实现了一个通用的投机采样框架,支持多种投机采样方法,能够帮助业务有效降低推理延迟以及提升吞吐。本文重点介绍其中的一种投机编辑技术,该技术已被应用于阿里内部智能化产品 Aone Copilot 的 fast apply 功能,该技术在这一特定业务场景下可实现每秒推理 1000 个 token 的能力。
背 景
相比于其他 AI 应用,LLM 的推理阶段最大的特点是它是一个自回归过程,绝大部分推理框架的优化工作都是围绕这个自回归过程展开的。
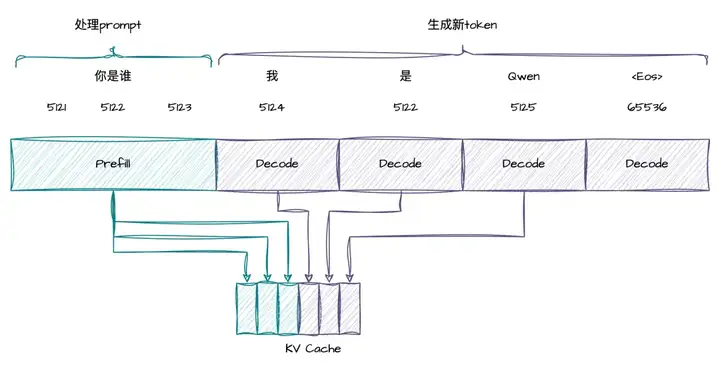
具体来讲,在下面这个例子中,用户的输入是“你是谁”,LLM 的返回是“我是 Qwen”,假设这些“你是谁”这些字符串在分词后对应的 token id 时 5121,5122,5123,“我是 Qwen”对应的 token id 时 5124,5122,5125 和 65536。在这个过程中,处理用户输入的 prompt 那个阶段称为 Prefill 阶段,它会对用户输入的所有 prompt(包含 5121,5122,5123) 进行并行计算,将中间计算产生的 KV Cache 保存起来,并且输出第一个 token 5124。之后生成新 token id(5122, 5125, 65536) 的阶段称为 Decode 阶段,与 Prefill 阶段相比,Decode 阶段每次只会对当前的 token 进行计算,比如在第一次 Decode 时,模型的输入只有 5124 这个 token,我们会将中间计算得到的 KV Cache 保存下来,并产生下一个 token 5122,之后这个过程会自回归的进行下去,直到遇到结束 token 65536。通常情况下,对于一个推理请求,处理 prompt 的 Prefill 只会进行一次,而生成新 token 的 Decode 会自回归的进行非常多次,取决于用户的输出有多长。
LLM 的推理离不开 GPU,对于任何一张 GPU,有四个硬件特性非常关键,它们分别是算力,显存带宽,通信和显存。以 A100 80GB SXM 为例,它的 FP16 Tensor Core 的算力 312 TFLOPS,显存带宽为 2,039 GB/s,NVLINK 卡间通信带宽为 600 GB/s,PCI-E 卡间通信 64 GB/s,显存为 80GB。不管是推理还是训练系统,最大化算力利用率都是至关重要的优化目标,这通常被称为提高 MFU(Model FLOPs Utilization)。在实现这一目标的过程中,开发人员往往会面临多种挑战,比如带宽瓶颈、通信瓶颈以及显存限制等。为了突破这些障碍,开发人员需要采用各种优化策略,力求将算力发挥到极致。
对于推理来说,绝大部分情况下都是单机部署(可能会有单机多卡),我们这里只分析其中最为朴素的一种情况,单机单卡部署,并且显存是充裕的。这时候影响推理性能的硬件因素的只有两个,算力和显存带宽。
- 对于 Decode 来说,它每次输入的 token 只有一个,但是在计算的过程中需要将 LLM 全部的 weights 加载到寄存器中,在这个过程中,首先会达到硬件的显存带宽瓶颈,导致 GPU 算力无法充分发挥。
- 对于 Prefill,它每次输入的 token 来自完整的 prompt,假设这个 prompt 包含的 token 比较多,比如几百个以上,那么在计算过程中,加载一次 weights 就可以同时计算几百个 token,这时候硬件会达到算力瓶颈。
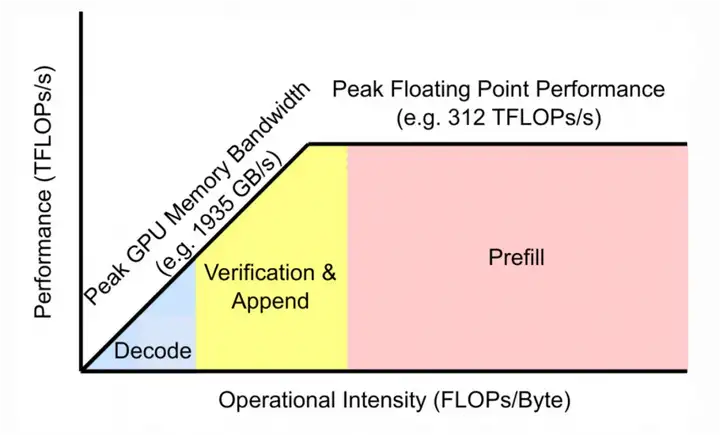
上图这张图 (来自于 FlashInfer) 生动的阐述了这一过程,这张图通常也被称为 Roofline Model,横轴是计算强度,即每进行 1FLOPS 计算所需要的访存量,纵轴是 GPU 每秒的浮点数计算次数,在计算强度降低时,比如 Decode 阶段,我们会达到显存带宽瓶颈,导致只有一部分 GPU 算力被使用,随着计算强度拉大,在 Verification 和 Append 过程,越来越多的 GPU 算力被使用,最后,到了 Prefill 阶段,我们达到了算力瓶颈,每秒进行的浮点数计算次数达到 312 TFLOPs,这也是推理最理想的情况。注意:上面的 Verication 对应着投机采样中大模型的 Score 过程,Append 过程对应着使用 reuse cache 的情况下,Prefill 过程中被 reuse 的那部分 KV Cache 不需要重新计算,只需要计算后面的 KV Cache。
上述Roofline Model展示的是请求并发度为1的情况,对于主流的推理引擎,通常可以在一次迭代过程中可以同时对多个请求进行并行处理。计算强度跟batch_size成线性关系, batch_size的计算公式如下:batch_size = seq_len1 + seq_len2+ ... + seq_lenn
这里的 n 是并发的请求数,seq_len~i~ 是每一请求当前轮迭代要处理的 token 数量,对于 Decode,seq_len 为 1,对于 Prefill,seq_len 为 prompt 的 token 数量(不考虑 reuse cache)。
根据上述 batch_size 的计算公式可以发现,提升计算强度的方式有两种,一是提升请求的并发度,让同一时刻有多个请求在 Decode,二是提升每一个请求的 seq_len。投机采样正是这样一种提升计算强度的方式,它在保持原有请求并发度的情况下,通过小模型来猜测未来大模型可能会生成的 k 个 token,进而让大模型一次性对这 k 个 token 进行并行计算 (每一个请求的 seq_len 从 1 增加到了 k),之后通过验证算法来决定接受多少 token。大模型一次性对 k 个 token 进行并行计算的过程称为 Score,对于 Score 而言,通过调整小模型提议的 token 数量 (即 k 值),我们可以控制投机采样的计算强度,当 seq_len 长到一定程度之后,Score 也会跟 Prefill 一样达到算力瓶颈。
投机采样简介及性能分析
简介
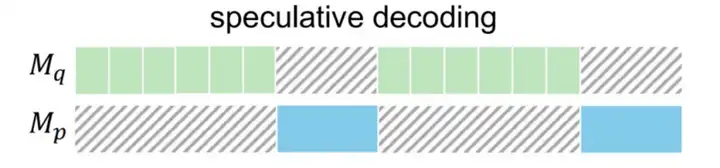
投机采样会有两个以上的模型(图来自于pearl):
小模型Mq(后面称为Propose Model),Mq既可以是概率模型,比如神经网络,也可以是规则模型,比如n-gram token匹配,RAG匹配等
大模型Mp(后面称为Score Model),Mp是需要加速的GPT模型本身
投机采样每一步的迭代过程都会包含下面三个阶段
- Propose Stage: 小模型 M~q~ 提议 k 个 token
- Score Stage: 大模型 M~p~ 对这 k 个 token 进行打分,这个打分过程是并行计算的
- Verification Stage: 根据小模型和大模型的输出的 token 和 probs 来决定本轮迭代接收多少个 token
通过上面这种方式,投机采样把原来逐个 token 逐个 token 的 Decode 过程转换成一次性对 k 个 token 进行 Score 并行计算的过程,从而更高效的利用了 GPU 的算力资源。另外,相比于其他的推理加速手段,比如量化,投机采样在某种特定的验证算法可以保证精度不丢失,这是投机采样相比于其他加速手段一个重要优势。
延迟分析
请求并发度为 1
在本小节,我们通过数学公式来分析下投机采样在延迟方面的理论降低上限,为了简化分析,我们做如下
假设:
- 请求并发度为 1
- 不考虑框架的额外开销,并且 Verification Stage 的开销为 0
- LLM 的输出足够长,可以忽略 Prefill 阶段的影响
小模型为 GPT 模型
此处假设小模型也为GPT模型,每轮迭代小模型提议k步(实际情况中,k通常为10以内的较小值),小模型单轮Decode的耗时为Tq,大模型单轮Decode和对k个token进行Score的耗时均为Tp(k比较小), 此时投机采样单轮的耗时为 Tq* k + Tp,假设平均接收长度为L,那么每个token的平均接收耗时为 (Tq* k + Tp) / L ,除以大模型单次Decode的耗时 Tp即可得到理论加速比:(Tq* k + Tp) / L * Tp
举个例子,小模型单次 Decode 耗时 7ms, 大模型单次 Decode 和对 5 个 token 进行 Score 的耗时均为 18ms,小模型每次提议 5 个 token,那么每轮投机采样的耗时为 5 * 7 + 18 = 53ms,假设每轮迭代平均接收的 token 为 3 个,那么生成每个 token 的平均耗时是 53/3=17.66ms,加速比为 18/17.66=1.02,同理,如果平均接收的 token 为 4 个,那么生成每个 token 的平均耗时是 53/4=13.25ms,加速比为 18/13.25=1.35。
由此可见,决定投机采样模型加速比的主要因素有两个:
- 小模型单轮 Decode 的延迟,越低越好,对于某些规则模型,该项延迟可以忽略不计
- 小模型提议 token 的接受率,越高越好
小模型为规则模型
在某些投机采样方法中,小模型可以通过简单的规则(比如n-gram token匹配)就可以提议token,这种通过规则匹配提议token的过程耗时可以几乎忽略不计,因此我们可以假设小模型提议token的耗时Tq为0。对于这一类模型,我们可以把k设置的很大,但是当k比较大(比如1024)情况下,大模型单次Decode和单次对k个token进行Score的耗时的差异不可以忽略,此时上述理论的加速比会变成(Tp-score-k) / L * Tp-decode
这里Tp-score-k表示大模型对k个token进行Score的耗时,Tp-decode 表示大模型单次Decode的耗时考虑其极限情况,假设小模型预测的token都能被大模型完美接收,此时k就等于L,在这种情况下,我们可以得到所有投机采样方法加速比的极限:max Tp-score-k/(Tp-decode * k), k=1,2,...+∞
拿 A100 卡举例,当模型为 qwen72b 时, 开启 TP=2 的情况下,在 RTP-LLM 框架下:
- 对 128 个 token 进行逐个 token 逐个 token 的 Decode 的耗时为 51*128=6528ms,对 128 个 token 进行 Score 的耗时为 65ms,此时投机采样加速比为 100。
- 对 2048 个 token 进行逐个 token 逐个 token 的 Decode 的耗时为 54*2048=104448ms,对 2048 个 token 进行 Score 的耗时为 701ms,此时投机采样加速比为 148。
总结下,在请求并发度为 1 时,投机采样在我看来 GPU 资源充裕的情况下追求极致低延迟的技术,在使用规则模型并且接收率非常高的情况下,投机采样可以把一个原本是访存瓶颈的 Decode 任务转化计算瓶颈 Score 的任务,后面 Aone Copilot 能够实现 1000 tokens 一秒的输出也是基于这个理论。
请求并发度>1
在上面对投机采样延迟分析过程中,我们假设请求并发度为 1,但这个假设太严苛了,在很多时候都是不成立的。目前主流的推理框架都已经实现了 continous batching,在实际运行的过程中请求并发度经常会大于 1 的情况,当请求并发度大于 1 时,投机采样框架对延迟的提升就会快速下降,甚至可能会出现比不开投机采样还要差的情况,在下图中可以看到,随着 QPS 上升,投机采样的的延迟快速上升,在 QPS 为 10 的时候,它比不开投机采样还要慢 1.8 倍 (下图来自于 vllm)。
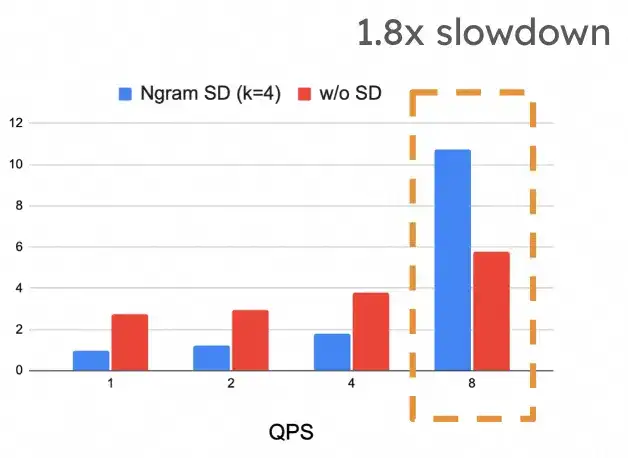
但是这也并不意味着投机采样只要在请求并发度>1 的时候就一定会带来负面收益,在上图中可以看到,在低 QPS 的时候,投机采样还是更好的利用到 GPU 空闲算力,从而达到比非投机采样更低的延迟。具体到我们的实际业务场景中,会有以下两种场景:
- 在线任务中,用户流量确定,GPU 资源不太充裕,每个请求的输入比较长,想要在保证在一定延迟的情况下,尽可能提升提升吞吐。由于用户的资源不太充裕,不能够部署 PD 分离实例。此时为了保证用户服务的延迟,每张 GPU 卡上分配的用户请求的并发度就不能开的太高,否则会出现大量 a 请求的 Decode 被 b 请求的 Prefill 拖慢的情况,为了避免这种情况,我们可以开启 chunked_prefill,但是模型比较大的情况下,chunked_prefill 增加的 batch_size 还是太大了,它还是会拖慢 Decode 的执行效率,最终,用户还是需要更多的 GPU 才能满足他们的服务需求。投机采样的好处是,它可以在每张 GPU 卡保持较低的请求并发度的情况下,通过设置比较小的 k 值,在不对延迟产生大影响的情况下来提升吞吐,从而满足这部分用户的需求。
- 在线任务中,用户流量确定且比较小,GPU 资源充裕,用户想要追求极致且稳定的低延迟。由于用户的 GPU 资源比较充裕,我们可以通过部署 PD 分离来获得稳定的低延迟。用户想在此基础上追求更加极致的低延迟,并且用户的流量又比较小,无法充分利用起 Decode 实例的算力,此时就可以在 Decode 实例上通过投机采样来进一步降低用户的延迟。
总结下,在流量确定的情况下,通过调节投机采样的 k 值,我们可以有效地平衡用户对于延迟和吞吐量的需求。在流量不确定的情况下,我们也可以让投机采样能够依据实时流量负载动态调整 k 值来让它的延迟在最坏情况下也比非投机采样好。在这个角度上来看,投机采样是一项能赋予单机计算灵活性的关键技术。当请求的并发度很大,算力已接近饱和时,投机采样的增益较为有限,此时应适当减小 k 值,以免影响延迟表现。相反,若请求的并发度较小,GPU 算力尚未完全利用,通过调整 k 值,投机采样可提议出更多 token 供大模型并行 Score,从而大幅提升算力利用率。
吞吐分析
以下对吞吐影响的讨论主要是在小模型为规则模型(即 Prompt Lookup) 的基础上进行讨论的,它的提议过程耗时可以几乎忽略不计,我们只需要考虑大模型 Score 的耗时。
在不开投机采样的情况,通过加大请求的并发数可以让算力使用达到极限情况,此时就达到了最大吞吐。如果此时我们开启投机采样后,按照同样的请求并发数,吞吐会出现一定程度的下降,这主要是因为投机采样不能保证每一个提议 token 会被成功接受,但是无论接受与否,每一个提议的 token 都会通过大模型的 Score 验证,对于那些没有被接受,计算是浪费的。上文中 QPS 很高的时候延迟下降也是同理。
通过上述简单的分析,我们可以得到一个结论,投机采样对于 LLM 推理的吞吐是有害的,这个结论是大部分人的共识,我最初的认知也是如此,但事实真的是这样嘛?投机采样对于吞吐是有害的这一结论在长期极限压力并且显存是完全充裕的情况下基本上是没问题的,但是实际使用的场景中,这一场景的假设并不总是成立的:
- 显存有时候比算力更快达到瓶颈。为了让吞吐尽可能提高,我们会把并发调到最大,直至显存的上限。但是在内部业务场景中,有各种各样类型的 GPU 卡,有些卡的显存很小,比如 L20,它的显存是 48G,当我们把一个 Qwen-32B-int8 模型加载上去后,留给 KV Cache 的显存就不是特别多了,在这种情况下,如果请求的输出特别长,请求并发度就不能打的特别高(运行期大部分的显存都会被每个请求的 KV Cache 占据,它跟输入输出的长度呈线性关系),此时如果再把请求并发度打更高,会让部分请求在运行过程中因为分配不到 KV Cache 而被淘汰,导致吞吐降低。在这种情况下,由于存在显存瓶颈,GPU 的算力不能被充分使用,投机采样在这种情况下就可以在不增加请求并发度的情况进一步提高算力的利用率。
- 由于推理引擎框架层的限制,通过提升请求的并发度来让 GPU 卡打满算力有时候并不是一件容易的事情,特别是对于尺寸比较小的模型。如下图所示,以 RTP-LLM 在 Qwen 1.8b 模型为例,要想让 A10 完全打满算力,需要请求的并发度达到 1024(此后 seq_len 和 prefill latency 的关系是系数为 1 的线性关系,对于算力更强的卡比如 A100,需要的请求并发度更高),这样 Decode 阶段凑的 batch size 才能够达到算力瓶颈,但在真实场景下达到这样的并发度会对推理框架本身的实现提出非常高要求,比如凑批流程,tokenizer,PB 序列化,Python 的 GIL 锁等任何一个环节都可能成为瓶颈。投机采样可以在请求并发度较低的情况下,通过调整 k 值来进一步提升 batch size,更好的利用显卡算力。
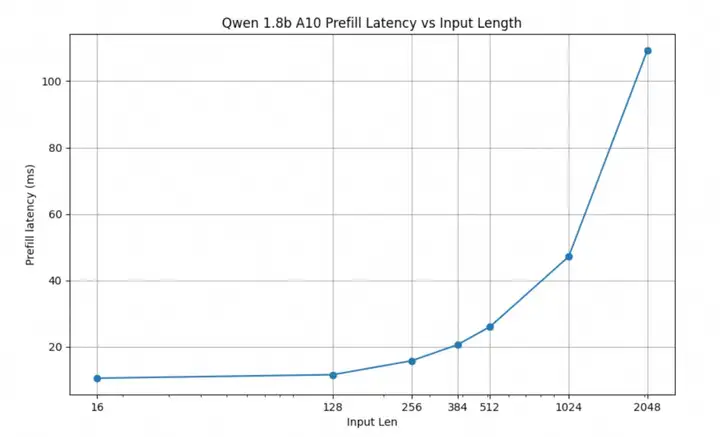
- 对于超长 sequence,通过投机采样增大 batch_size 对于 attention 的历史 KV Cache 访存更加友好一些。非投机采样为了凑大 batch_size,只能加大请求的并发度,考虑 128 个请求凑批的情况,128 个请求在 attention 阶段都要访问一下自己历史所有的 KV Cache,这会严重降低 attention 计算阶段的计算强度,sequence 特别长的情况下甚至可能在这一阶段打不到计算瓶颈。但是,如果用投机采样来增大 batch_size 的话,可以不增加请求的并发度,比如对于 1 个请求,我们可以直接将 k 设置为 128,此时也会凑满 128 的 batch_size,但是在 attention 阶段只需要访问这一个请求的历史 KV Cache,可以获得更大的计算强度,进而带来吞吐的提升。
总结下,对于提升吞吐而言,在许多情况下受限于显存大小,推理框架本身实现,访问历史 KV Cache 等的限制,我们不能将 GPU 算力充分利用起来。此时投机采样可以通过调整 k 值,从另一个维度提升 batch_size,进而充分利用起 GPU 的算力。
RTP-LLM 通用投机采样框架实现
投机采样一直是大语言模型领域学术界和工业界关注的热点,有各种各样的投机模型,比较主流的有:
- 朴素投机采样:拿小尺寸的 GPT 模型作为小模型 M~q~
- Medusa:在 last hidden state 上面添加几个额外的 lm head 来预测未来若干个 token
- Eagle:训练一个新的 Auto-Regression Head 来预测未来的 hidden state,根据未来的 hidden state 去预测未来的 token
- Prompt Lookup: 去历史 prompt 中进行 n-grams 匹配,将 n-grams 匹配成功后面的若干个 token 作为提议 token
可以看到,当前阶段有非常多的投机采样模型需要支持,同时未来可能还有树采样,动态投机采样等需求。为此,我们在 RTP-LLM 中实现一套通用的投机采样框架,它能够很好应对未来可能增加的各种投机采样需求的拓展,同时这套投机采样框架尽可能复用了原来的 GenerateStream,BatchStreamProcessor,NormalExecutor 等模块组件,以减少开发的工作量。
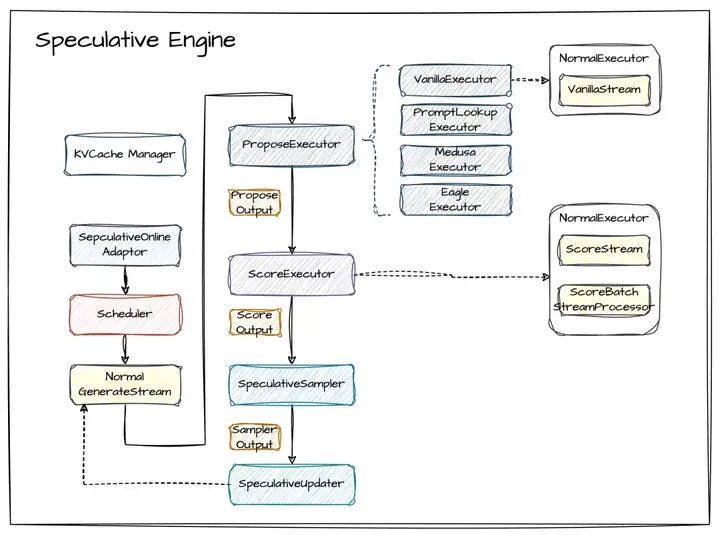
我们根据投机采样的三个阶段 (Propose, Score, Verification),在实现时将投机采样分为四大类模块组件:
- ProposeExecutor:小模型提议 token,根据不同投机采样算法有多种实现,比如朴素投机采样,PromptLookup,Eagle 和 Medusa 等
- ScoreExecutor:大模型对小模型提议的 token 进行打分
- SpeculativeSampler:对小模型大模型的输出的 token 进行验证来决定接收多少个 token
- SpeculativeUpdater:将接收的 token 更新到最初的 strema 上面
四个模块组件都有明确的输入输出并且各自都是无状态的,从而实现功能的接触耦合。
RTP-LLM 投机编辑实现与业务提升
Prompt Lookup 投机采样简介
在正式介绍投机编辑前,我们首先介绍下 Prompt Lookup 投机采样。
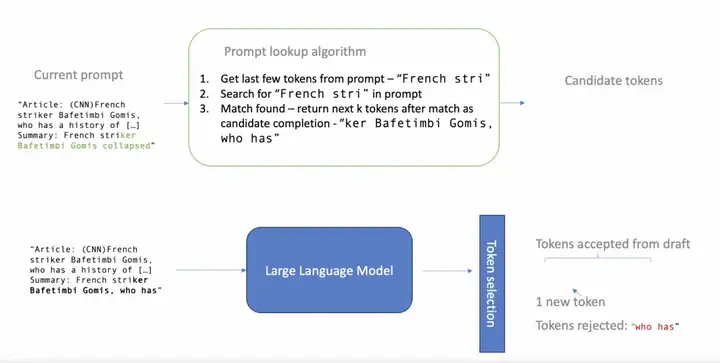
Prompt Lookup 投机采样每一轮的基本流程如下:
- 根据最近几个生成的 token 在 prompt 中进行 n-gram token 匹配
- 如果匹配命中,则把命中位置之后的 k 个 token 作为 Propose token(上图中叫做 candidate tokens),到此完成小模型提议 token 阶段
- 将小模型提议的 tokens 交给大模型打分
- 验证算法根据小模型和大模型的输出来决定当轮迭代接受多少个 token
对于抽取式场景,Prompt Lookup 的加速效果非常明显,主要是由于小模型提议的 token 接收率特别高。
基于 Prompt Lookup 的投机编辑实现
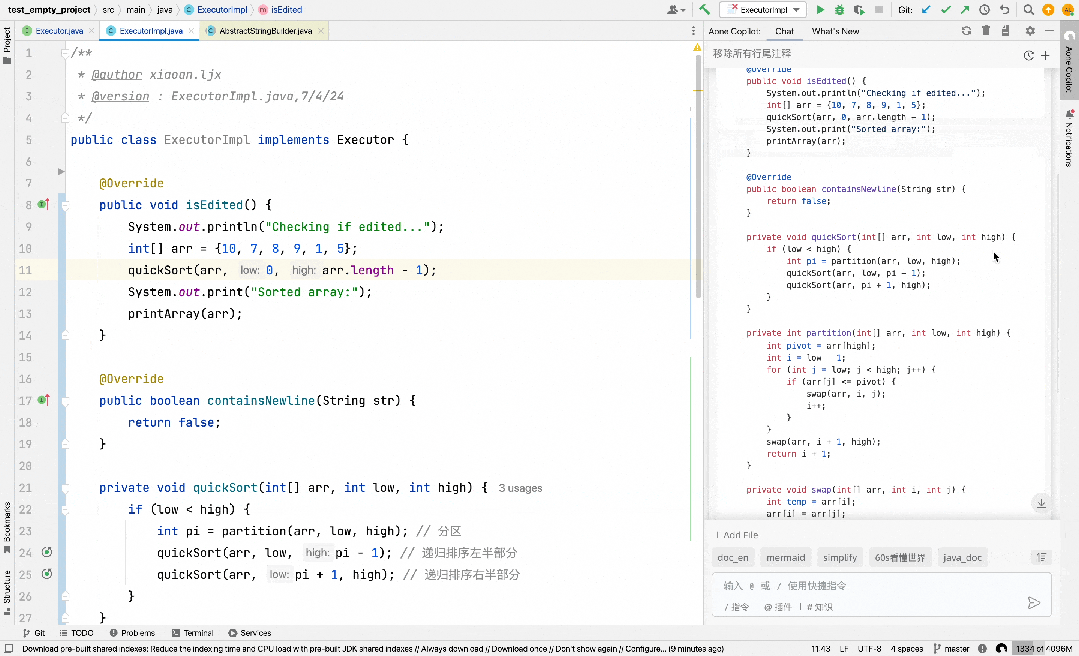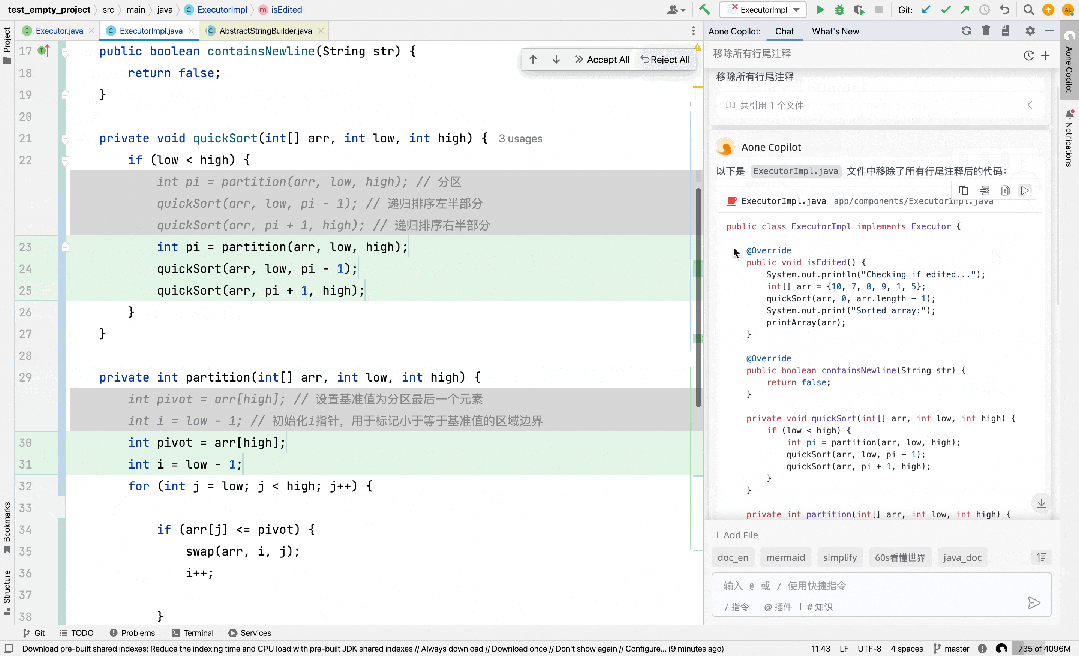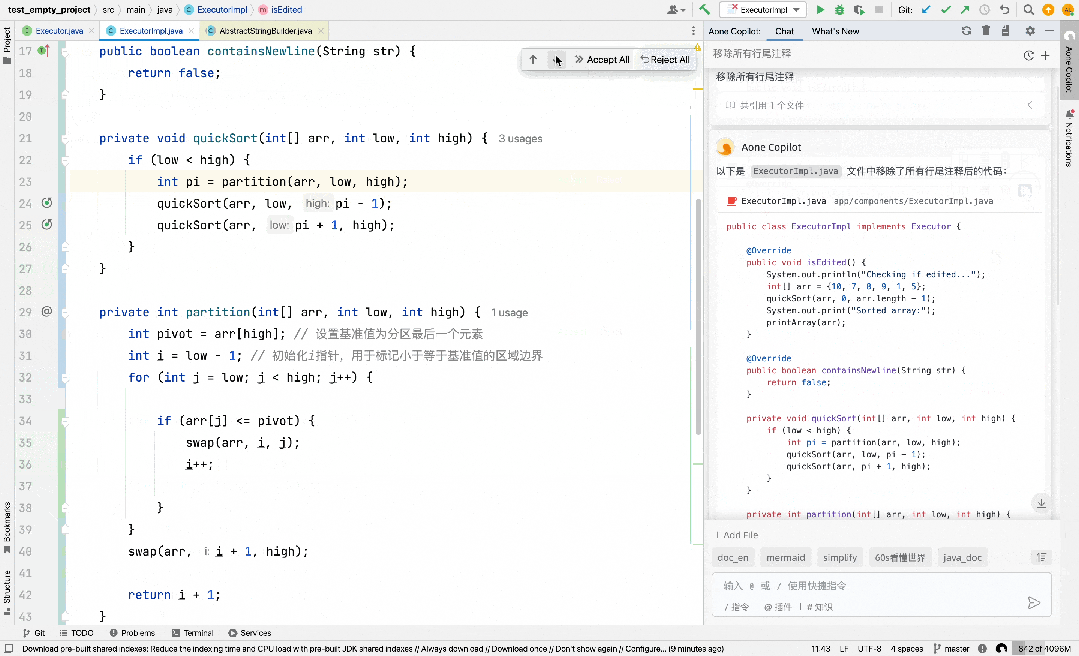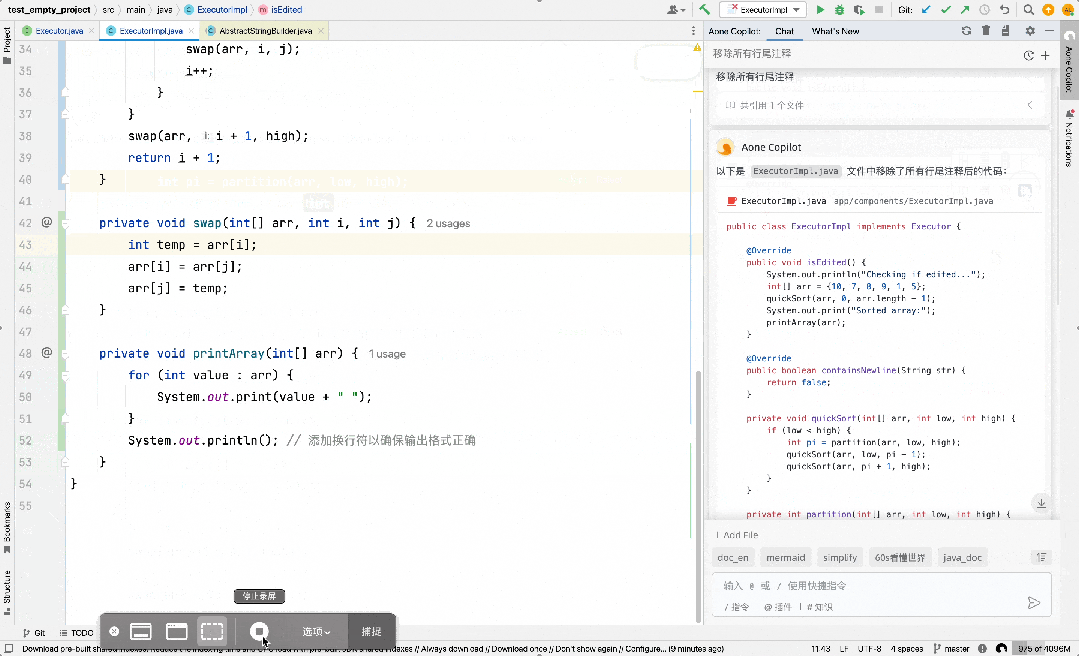
代码编辑也是这样一类抽取式场景,比如下图中,我们实现了一个快速排序算法,想要通过大模型把其中的 arr 变量的 long 类型改成 int 类型,并且要求模型输出修改完后的完整代码,此时大部分的模型输出都可以直接从输入中摘抄即可,仅在发生差异的地方特殊处理一下即可,Aone Copilot 的 Fast Apply 实现一键应用修改功能也是类似的场景。
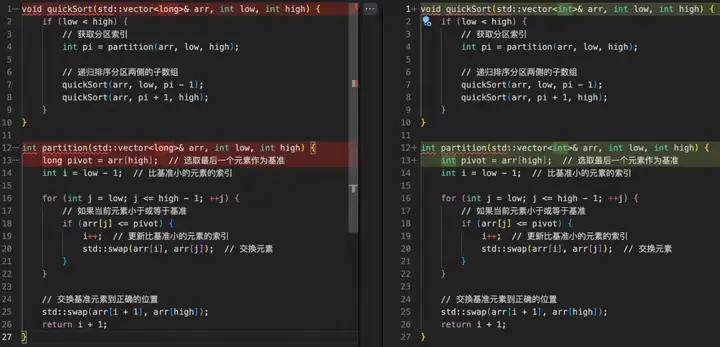
除此之外,编辑这一类特殊的抽取式场景还有一个特点,大模型在做摘抄的时候会满足一个前后顺序关系,比如上图中假设大模型当前阶段的摘抄到了第 7 行的 quickSort(arr, low, pi - 1); ,下次摘抄的起始位置一定是从之后的位置(第 8 行)开始的,基于这个特性,我们对 prompt lookup 做了如下改进来提高它在投机编辑场景的性能:
- 额外维护一个游标来记录上次 prompt lookup 成功的位置,每次匹配都以游标作为起始位置,从之后的位置开始进行寻找 n-grams token 匹配,在每轮投机采样迭代后也会把游标的位置往后面更新。
- 第一轮迭代时跳过 n-grams token 匹配,直接将最开始的 k 个 token 作为提议 token。
投机编辑对业务的性能提升
延迟提升
- Aone Copilot 基于投机编辑技术实现了 Fast Apply 功能。该功能的输入是原始代码及需修改的部分,输出则是重新编写的代码。由于需要重写全部代码,因此对延迟提出了很大的挑战。借助投机编辑技术,我们在 32B 规模的模型上实现了单个请求每秒可以推理 1000 条 token,相比未使用投机编辑之前提升了 10 倍性能,满足了 Aone Copilot 上线业务的需求。
- 公司内部的大模型业务广泛采用了结构化输出方式,这些业务的 LLM 输出内容大部分都是比较固定的,对于固定的输出部分可以直接通过投机编辑去进行“摘抄”即可。在使用投机编辑技术之后,这部分业务的延迟得到了显著的降低。具体而言,在一项使用 72B 规模模型的结构化输出业务中,输出长度约为 100 个字符,在应用投机编辑后,Decode 部分的延迟从原来的 3 秒降至 1.2 秒,实现了大约 60% 的 Decode 延迟提升。
吞吐提升
公司内部有一个训练数据清洗的业务,相比传统的规则匹配方法,使用大模型能够显著提高数据清洗的效果,从而更好地支持后续的训练任务。大语言模型的输入是未经处理的原始语料,输出则是经过清洗后的干净语料。输入语料的平均长度约为 3000 个 token,而输出语料的平均长度约为 1000 个 token。通过使用投机编辑技术进行加速后,单张 GPU 卡的每秒请求率(RPS)从 3 提升到了 10。
未来方向
投机采样的优化跟场景密切相关,在使用时自身也有许多参数需要配置,目前在阿里的内部业务中只有一部分业务使用上了投机采样,对于大多数业务方来说投机采样使用起来还是有一定的门槛。在未来, 我们将增强 Prompt Lookup 投机采样并将其设置为一种默认开启的功能,让它能够开箱即用且能够根据线上流量做自适应调整,使所有业务方都能享受其性能优势。
最后,Prompt Lookup 投机采样方法能够在很大程度上加速 LLM 输出的前提是大部分内容都能被准确预测。然而在不少场景下 (比如对话场景),该假设并不总是成立。此时需要借助一个额外的小型神经网络来预测未来的 token 以进一步提升接收率。得益于 RTP-LLM 通用的投机采样框架的支持,我们将很轻松地集成其他先进的投机采样方法,例如近期备受关注的 DeepSeek 的 MTP。在未来,我们也会在 RTP-LLM 中将 Prompt Lookup 投机采样和 Deepseek MTP 的结合起来,对较为简单的预测采用 Prompt Lookup 直接完成,而对于更为复杂的预测,则利用 MTP 进行预测,从而进一步加快 Deepseek 的生成速度。
参考文献
https://flashinfer.ai/2024/02/02/introduce-flashinfer.html
https://pearl-code.github.io/
https://docs.google.com/presentation/d/1wUoLmhfX6B7CfXy3o4m-MdodRL26WvY3/
https://github.com/apoorvumang/prompt-lookup-decoding.git
文章来自于“InfoQ”,作者“赵骁勇 阿里巴巴智能引擎事业部”。

【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


