开发Agent的工程师们都曾面临同一个棘手问题:当任务步骤增多,你的Agent就像患上"数字健忘症",忘记之前做过什么,无法处理用户的修改请求,甚至在多轮对话中迷失自我。不仅用户体验受损,token开销也居高不下。TME树状记忆引擎通过结构化状态管理方案,彻底解决了这一痛点,让你的Agent像拥有完美记忆力的助手,在复杂任务中游刃有余,同时将token消耗降低26%。


当前LLM Agent的致命弱点
当前的大语言模型(LLM)Agent在执行多步骤任务时存在一个致命弱点:它们缺乏对任务状态的结构化理解,往往只能依靠简单的线性提示拼接或浅层的记忆缓冲区。这种局限导致了Agent在执行复杂任务时表现脆弱,频繁产生幻觉,并且难以维持长期一致性,尤其是在需要回溯、修正或分支执行的场景中。如果你正在开发Agent产品,你很可能已经遇到了这些痛点:Agent忘记之前的步骤、无法处理用户对之前步骤的修改、或者在多轮对话中逐渐偏离任务目标。
TME:专为多步骤任务设计的记忆引擎
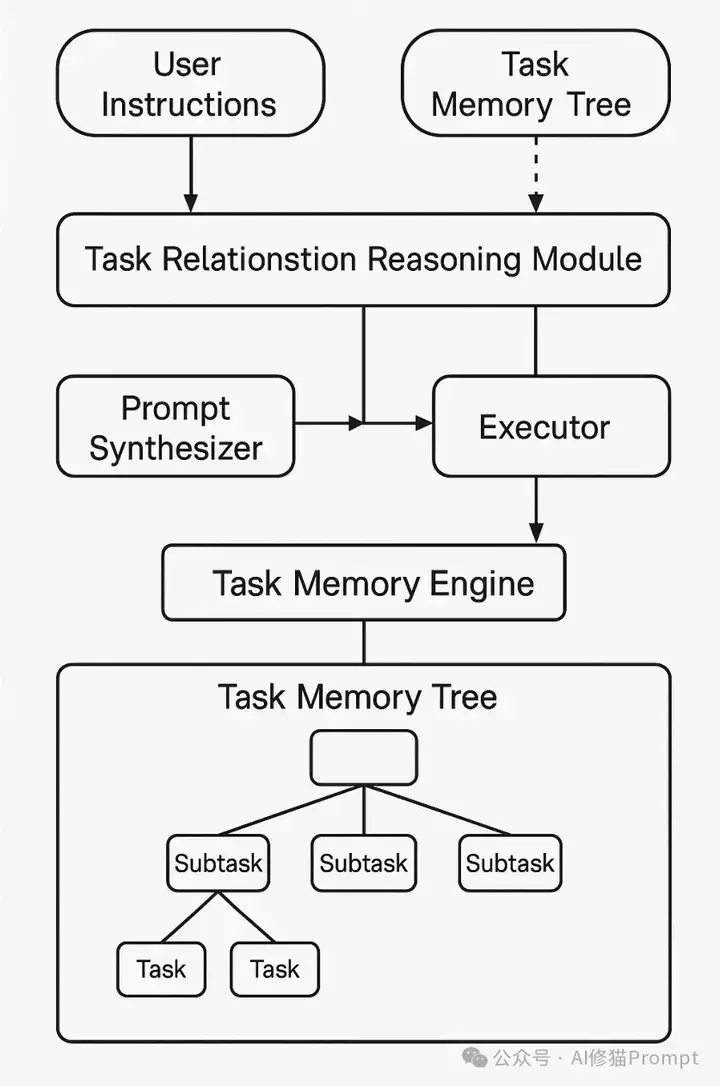
研究者提出了Task Memory Engine(TME),一个轻量级且结构化的记忆模块,通过层次化的Task Memory Tree(TMT)来跟踪任务执行状态。TME由三个紧密集成的组件构成:Task Memory Tree(TMT)、Task Relationship Inference Module(TRIM)和Prompt Synthesizer,它们共同工作以增强Agent的状态感知能力和执行一致性。与传统的线性历史记录或基本向量检索不同,TME能够捕捉任务执行的复杂性,包括时间依赖关系和上下文特定的细微差别,从而显著提高执行一致性和上下文理解能力。
为什么传统记忆机制会失效?
传统的LLM Agent记忆机制如简单的历史记录缓冲区(如LangChain的BufferMemory)、工具执行日志(如AutoGPT)或向量存储(如Pinecone、Weaviate)都未能提供任务状态的正式表示。这些方法要么简单地追加前面的交互,要么只追踪工具调用而不跟踪任务的逻辑进展,要么允许检索但不模拟当前状态,导致在复杂任务中难以保持连贯性。更重要的是,这些方法在面对任务修正、回溯或分支执行时表现尤为糟糕,因为它们缺乏对任务结构和状态转换的建模能力。
TME的核心:Task Memory Tree(TMT)
Task Memory Tree(TMT)是一种层次化的数据结构,设计用于支持LLM Agent的一致且高效的任务跟踪。TMT中的每个节点代表任务中的一个步骤,包含行动(如"搜索航班")、输入/输出(相关数据)、状态(执行状态)、父/子关系(显式层次关系)以及依赖关系(描述任务间逻辑关系的可选跨链接)等结构化元数据。随着Agent完成任务进程,节点被动态创建和更新,同时专用的Prompt Synthesizer遍历从根到当前叶子的活动节点路径,生成简洁且上下文相关的提示。
TRIM:关系推理的核心
TRIM(Task Relationship Inference Module)作为TME的中枢逻辑引擎,负责维护任务执行的结构化表示,实现高效导航、回滚和提示构建。它通过将每个任务步骤明确记录为Task Memory Tree中的节点,附带父子关系、执行状态和内容注释,使Agent能够推断哪些步骤处于活动、完成或无效状态。TRIM支持五种核心任务关系:依赖(depends-on)、并行(parallel-with)、替换(replaces)、合并(merge)和回滚(rollback),以及子任务(child_of),通过混合提示模板、关键词匹配和逻辑规则进行推断。
增强的关系推理:超越简单的相似性启发式
为了提升超越相似性启发式的推理能力,TRIM引入了一个轻量级的分类模块用于任务关系预测。给定当前步骤S和历史节点Ni,分类器输出关系类型:重复、超集、依赖于、冲突或无关。这一分类器使用紧凑的transformer编码器(如MiniLM或DistilBERT)实现,能够实现精确的任务节点合并、依赖感知更新和冲突检测与回滚路由。研究者还提出了未来可能的扩展方向:基于跨度的覆盖模型、图神经网络和LLM增强推理,以实现跨越多个路径、依赖和层次级别的关系推理。
非线性导航和灵活工作流
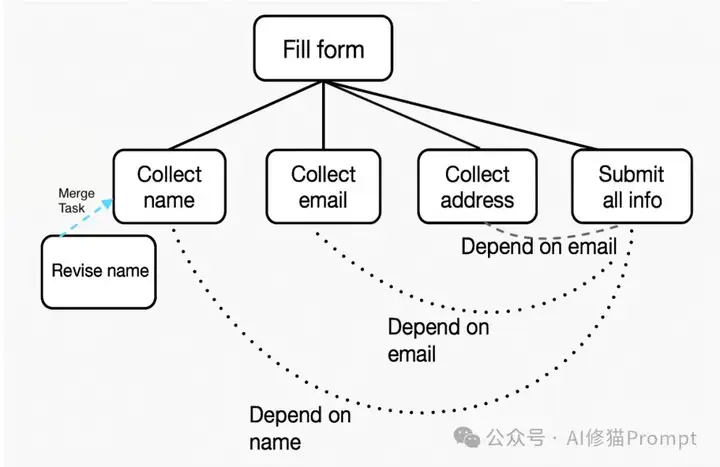
TME支持灵活的工作流通过非线性导航实现,用户可以重新访问和编辑以前的步骤(例如,纠正错误或更改偏好)。TRIM确保只有受影响的子树被更新,避免了完整序列的重新计算,这使得TME特别适合在动态环境中运行的Agent。当出现冗余或语义相似的任务分支时,TRIM将它们合并为统一节点以最小化重复;而无效或不可访问的分支则被修剪以最小化执行和提示开销,进一步提高效率。
Prompt Synthesizer:Token效率的关键
传统Agent在每个步骤都将完整的对话历史传递给模型,导致token使用效率低下。TRIM与Prompt Synthesizer合作,仅提取相关的节点路径(从根到当前叶子),确保在保持逻辑连贯性和上下文保真度的同时最小化token使用。这种设计使TME比基线方法减少了显著的token使用量,特别是在涉及长期记忆、部分更新或多路径执行的实际Agent工作流中。
案例研究:表单填写助手
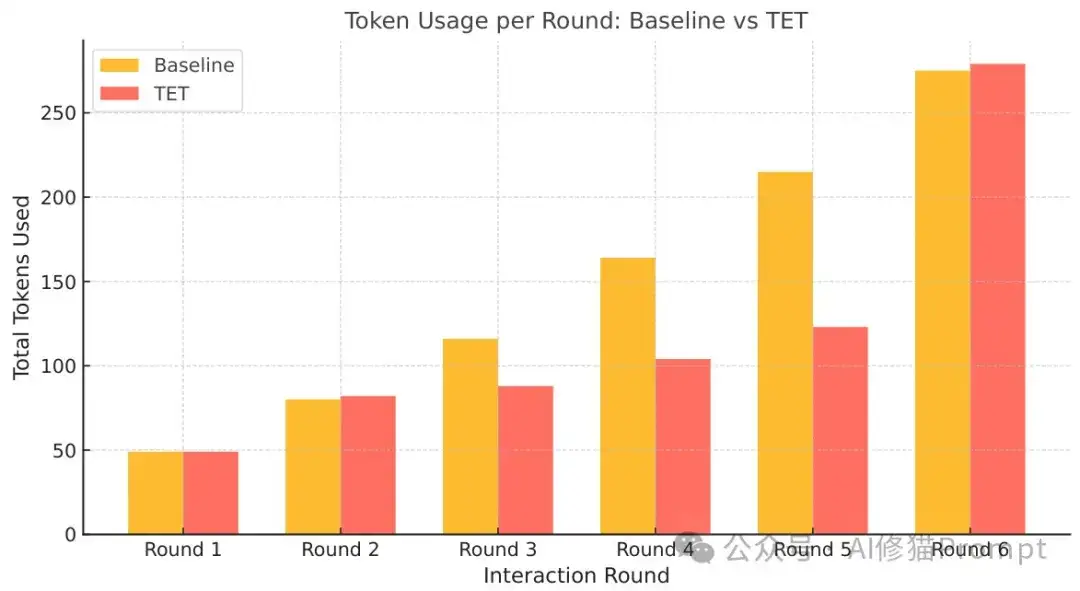
研究者模拟了一个多轮表单填写任务,涉及在六个交互回合中收集、纠正和确认用户信息。表单填写任务被结构化为六个逻辑节点,包括信息收集(姓名、电子邮件、地址)、姓名纠正步骤和最终提交。与传统方法不同,Task Execution Tree将修订合并到各自的节点中,使效率更新成为可能,同时保留历史记录,无需重放完整的交互历史就能进行更正和重新提交。
研究复现:处理复杂商业文档编辑
我根据TME树状记忆引擎写了一个处理复杂商业文档编辑的py代码,以下是实际运行效果。可以清晰看到系统如何跟踪文档各部分的修改历史、版本变化和依赖关系,特别是在用户要求修改执行摘要和回滚时间线部分时,TME能精确定位相关节点并保持上下文一致性。注意观察每轮交互的token使用量对比——传统方法会线性增长,而TME通过结构化记忆实现了高效提示管理。这一实现证明了TME不仅能解决Agent的"记忆问题",还能在保持高质量输出的同时显著降低API调用成本。

Token效率分析:显著的性能提升
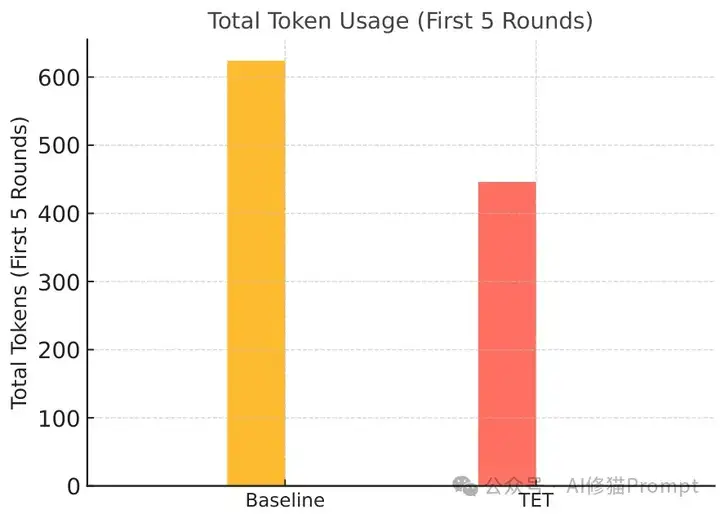
为了评估效率,研究者比较了TET与一个在每轮简单地追加完整历史的基线方法。结果表明,TET在6轮中减少了174个token(19.4%),在前5轮中减少了178个token(26.4%)。这些节省主要源于避免了全历史重复,特别是在纠正和重新查询期间。TET的优势在于避免了冗余的提示拼接,保持了跨更新的任务一致性,并实现了token高效的多轮交互。
Tree vs. DAG记忆结构
虽然当前的实现使用基于树的记忆结构(TMT),但更一般的任务执行工作流可能自然地表现出类似图的模式。例如,同一个子任务(如"验证用户身份")可能被多个父任务引用。有向无环图(DAG)表示能够实现共享子任务重用而无需复制、跨分支的多路径依赖解析以及计划评估中的细粒度信用分配。然而,基于DAG的记忆在状态跟踪和回滚推理方面引入了复杂性,而树提供了更简单的模型,具有确定性导航和本地更新的特点。
如何在你的Agent项目中利用TME
如果你正在开发Agent产品,可以考虑利用研究者发布的TME参考实现,该实现包含任务树跟踪、提示合成器和规划器组件。TME可以嵌入到各种Agent系统中,特别适合需要维护一致状态、支持非线性交互或需要高效token使用的应用场景。将TME集成到你的项目中可以带来token高效的修订和重规划能力、清晰的分支切换(同时保留历史记录)以及避免冗余重新评估过时任务的优势。
走向更强大的Agent记忆系统
研究者提出了若干值得关注的未来方向,包括将基于树的记忆扩展为DAG结构以模拟跨步骤依赖关系、集成可视化调试工具以检查和重放任务流程、将TME嵌入到ReAct/AutoGPT风格的规划循环中进行实时适应、设计规划器模块进行长期目标分解,以及支持循环建模、子树合并和版本感知的记忆导航。如果你对Agent的未来发展感兴趣,这些方向都值得深入探索,它们共同指向了更加智能、自主和高效的Agent系统。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。

【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


