SuperCLUE-Fact是专门评估大语言模型在中文短问答中识别和应对事实性幻觉的测试基准。测评任务包括知识、常识、对抗性和上下文幻觉。
# 榜单概览
# 总榜单
# SuperCLUE-Fact事实性幻觉测评总榜
# SuperCLUE-Fact事实性幻觉测评总分及四大任务分数
# 测评背景
大模型的“幻觉”(Hallucination)是指模型在生成内容时,脱离输入信息或现实知识,自行编造看似合理但实际错误、虚假或无关内容的现象。大模型生成的这些信息在表面上可能显得流畅、连贯,但本质上存在根本性错误。
为了全方位地衡量大语言模型的事实性幻觉问题,我们设计了一个在中文领域的事实性幻觉测评基准:SuperCLUE-Fact,该基准重点考察大语言模型在中文简短事实问答中的准确性,以及识别与判断事实性幻觉的能力。不涉及文本生成及内容创作等方面的考察,后续将推进相关生成类幻觉问题以及忠实性幻觉问题的测评。本次事实性幻觉测评选取了国内外13个模型,均为非联网版本,以下是详细的测评报告。
排行榜地址:www.SuperCLUEai.com
SuperCLUE-Fact测评摘要
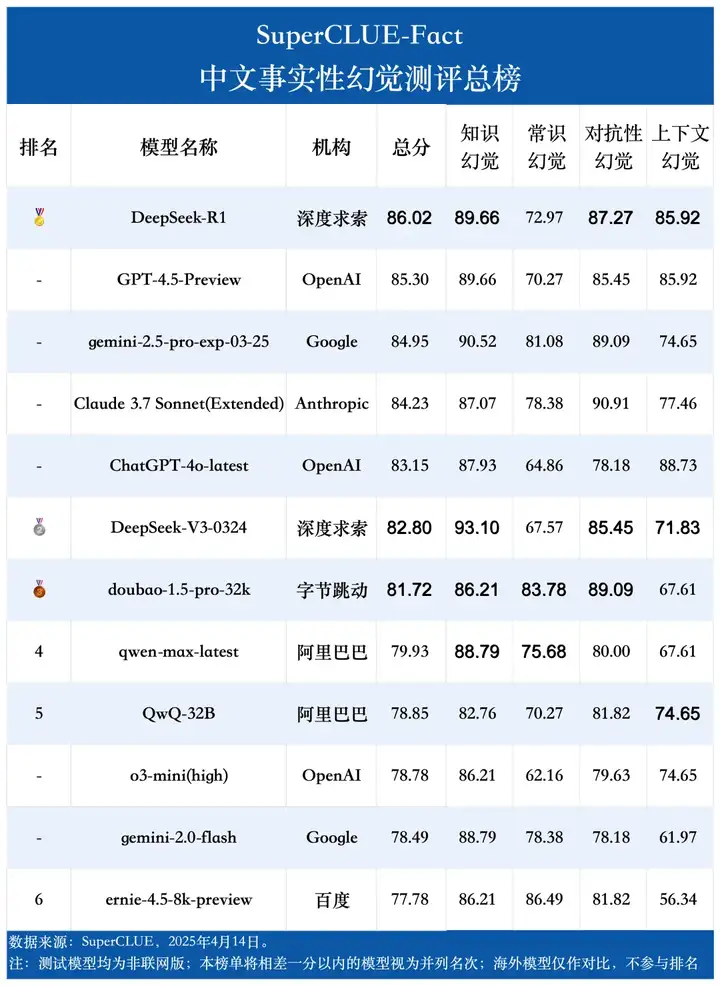
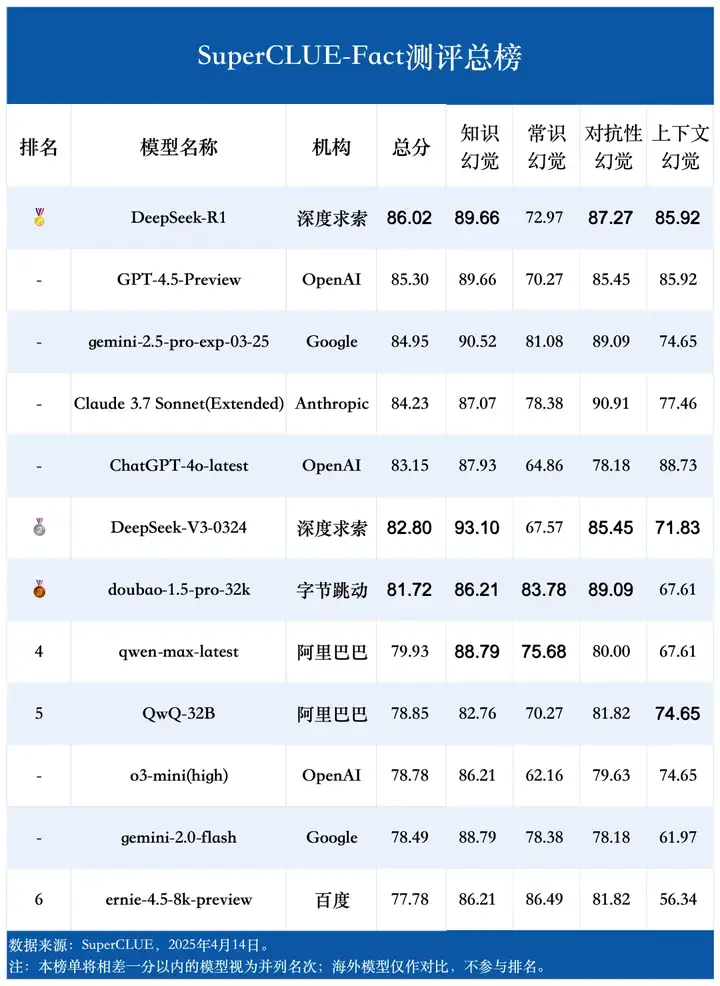
测评要点1:DeepSeek-R1当前领先,但头部模型差距微小。DeepSeek-R1以86.02的总分领跑事实性幻觉榜单,GPT-4.5-Preview、gemini-2.5-pro-exp-03-25、Claude 3.7 Sonnet (Extended) 和 ChatGPT-4o-latest 也表现优异,位列前五。整个榜单的分数相对集中,尤其是在顶部梯队,显示出领先模型在事实性幻觉能力上的激烈竞争。
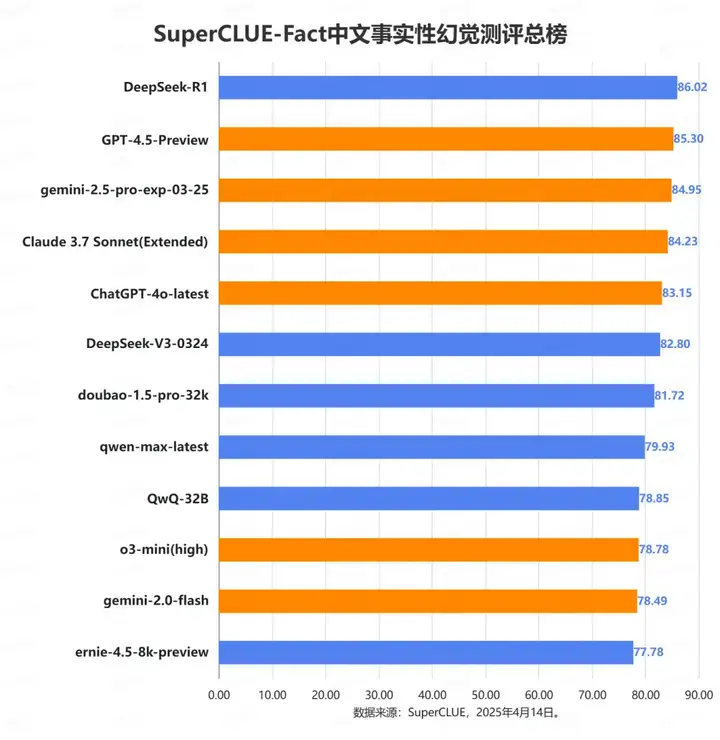
测评要点2:模型在不同类型的事实性幻觉任务上表现差异显著。本次测评的12个模型在处理知识幻觉和对抗性幻觉方面表现相对稳健,平均得分有85分左右。然而,在常识幻觉和上下文幻觉这两类任务上,模型表现普遍较弱,平均分不足75分,差距明显。
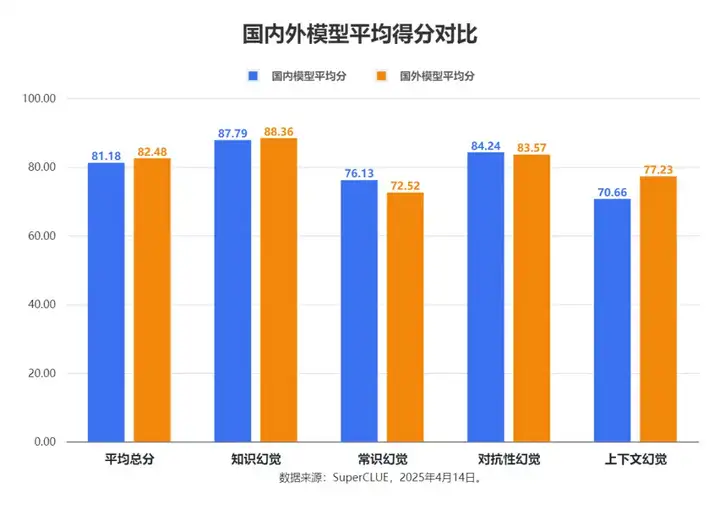
测评要点3:海外与国内模型各有优劣,但海外模型总体稍领先。整体评分上,海外模型(平均82.48分)比国内模型(平均81.18分)高出1.3分。但具体任务表现呈现差异:国内模型善于处理常识幻觉(领先3.61分)和对抗性幻觉;而海外模型则在知识幻觉和上下文幻觉方面更具优势,特别是在上下文幻觉任务上,领先国内模型6.57分,差距最为明显。
#测评体系
(一)SuperCLUE-Fact测评体系
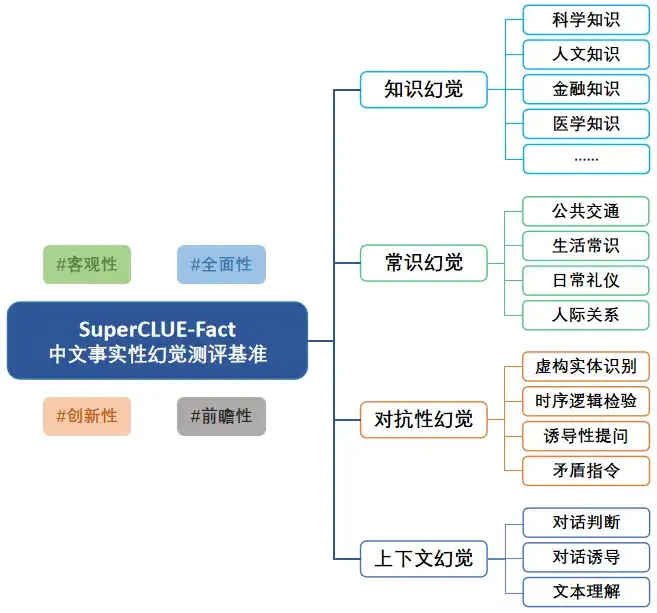
SuperCLUE-Fact 是一个专注于评估大语言模型在中文领域事实性幻觉(Factual Hallucination)表现的基准测试。该基准涵盖四大核心任务:知识幻觉、常识幻觉、对抗性幻觉和上下文幻觉,重点考察模型在中文简短事实问答中的准确性,以及识别与判断事实性幻觉的能力。通过多维度评测,SuperCLUE-Fact 旨在为大语言模型的事实性幻觉研究提供全面、客观的能力评估依据。
#测评任务
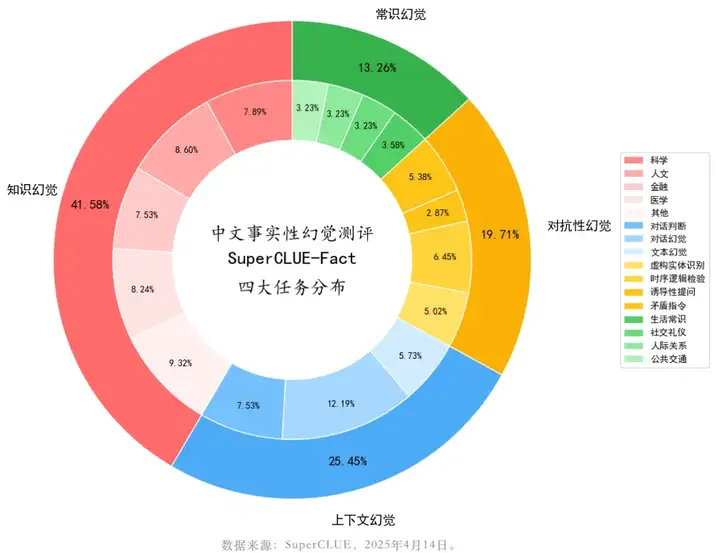
SuperCLUE-Fact基准包含四大核心评测任务:知识幻觉、常识幻觉、对抗性幻觉和上下文幻觉。各任务定义及评测重点如下:
1.知识幻觉:考察模型对各领域知识的认知与理解能力,覆盖科学、人文、医学及金融等多元学科,检验模型回答简短事实性问题的准确性。
2.常识幻觉:考察模型对日常生活常识的掌握程度,包括生活常识、社交礼仪、人际关系及公共交通等场景,评估其与现实世界的一致性。
3.对抗性幻觉:考察模型对指令中隐含幻觉的识别能力,通过虚构实体识别、时序逻辑检验、诱导性提问及矛盾指令等对抗性设计,考察模型的抗干扰性。
4.上下文幻觉:考察模型识别和判断上下文是否存在幻觉的能力,具体包括对话判断、对话幻觉及文本幻觉等任务。
# 测评方法
参考SuperCLUE细粒度评估方式,构建专用测评集,每个维度进行细粒度的评估并可以提供详细的反馈信息。
(一)测评集构建
中文原生事实性幻觉测评基准中文题库的构建流程如下:
1.参考现有提示词(Prompt),撰写中文prompt--->
2.测试--->
3.基于测试结果优化完善中文prompt--->
4.系统化构建各维度专属评测集,形成完整测评题库。
(二)评分方法
为了确保评估的科学性和公正性,我们采用超级大模型进行评价。结合评估流程、评估标准、评分规则,进行细粒度评估,采用0/1评分标准,对于存在事实幻觉(答案错误)的题目评分为0,对于不存在事实幻觉(答案正确)的题目评分为1。应用这种方式,尽量减少人为因素的干预,确保评分结果的客观性和一致性。
(三)人类一致性分析
对自动化测评结果进行评估,与人类评价的一致性对比,并报告一致性表现。
# 参评模型
说明:我们发现在调用腾讯云官方提供的hunyuan-turbos-latest时虽然关闭了联网搜索,但实际返回结果中仍然出现了调用搜索的内容,有存在程序问题的可能。为了实际反映模型自身的幻觉情况,保证测评的公正性,本次hunyuan-turbos-latest模型不参与测评,因此本次事实性幻觉测评参与的模型数量为12个。
# 测评结果
(1)总榜单
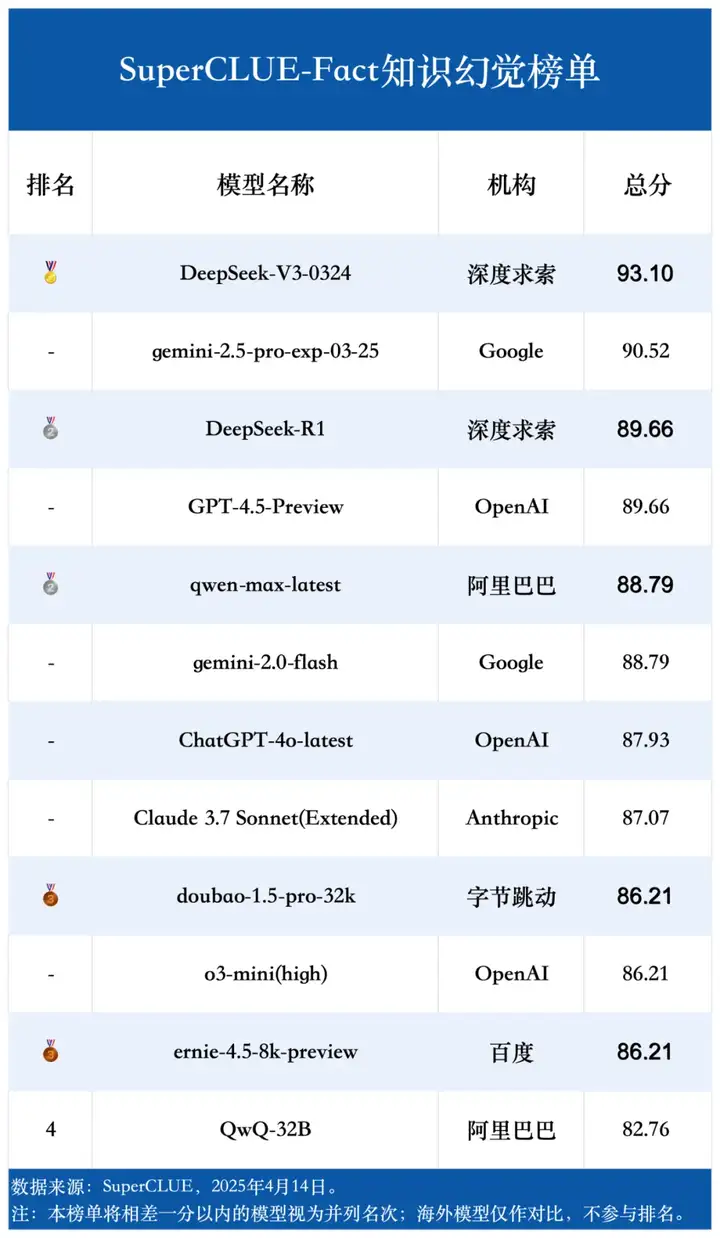
(2)知识幻觉榜单
(3)常识幻觉榜单
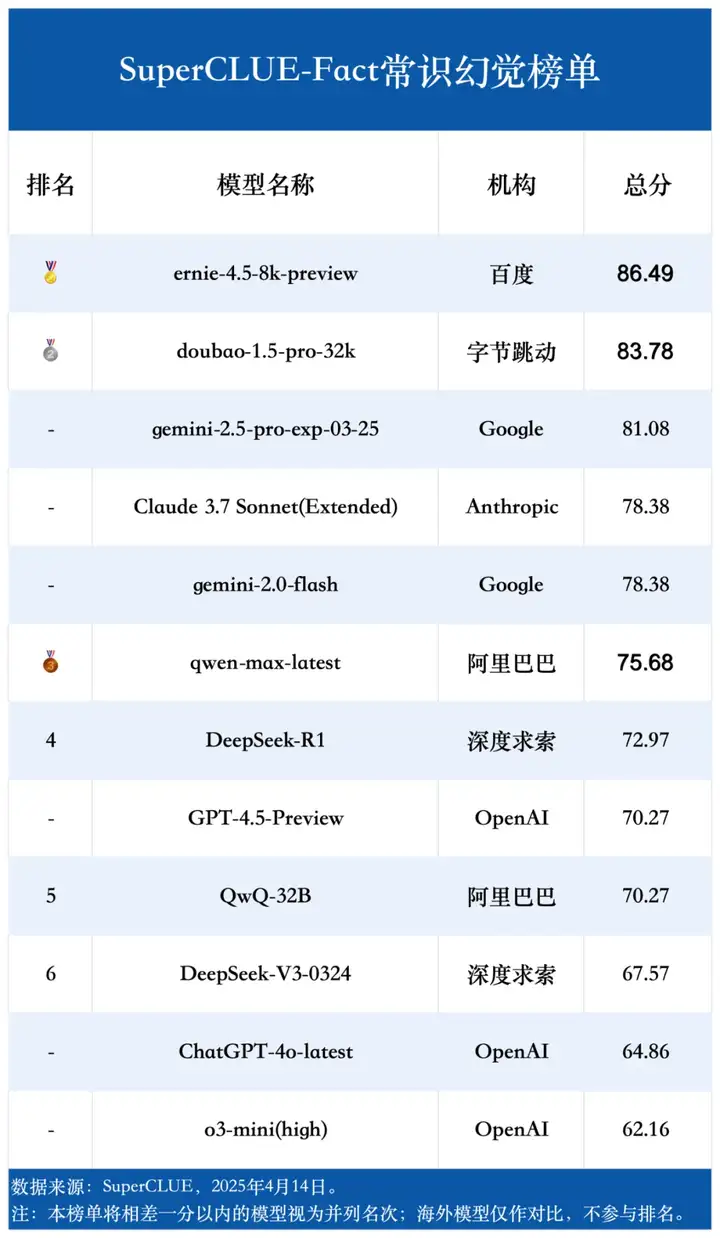
(4)对抗性幻觉榜单
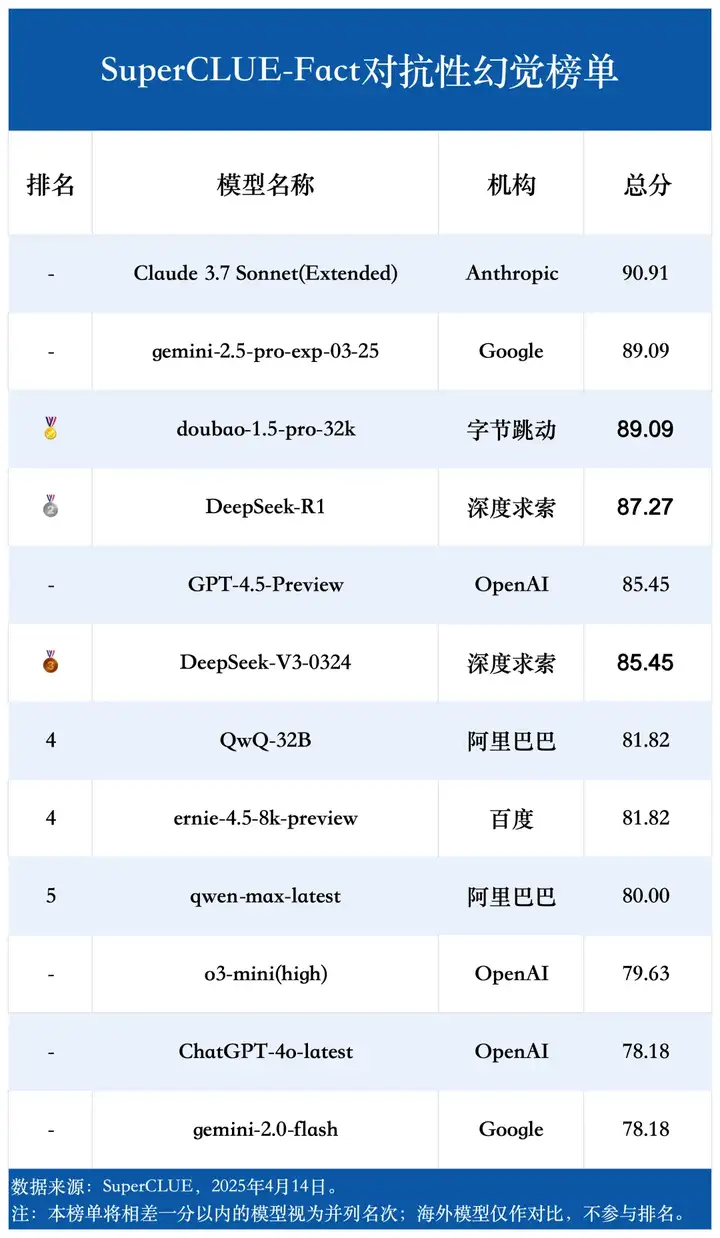
(5)上下文幻觉榜单
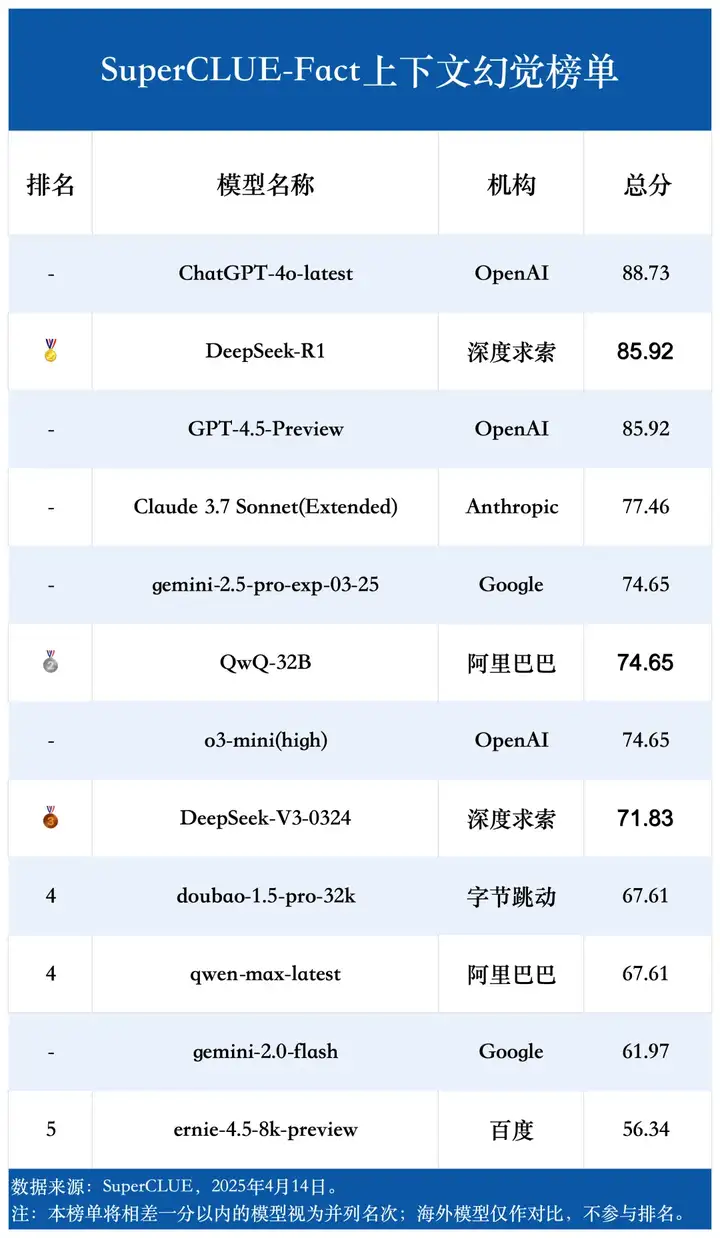
# 人类一致性评估
为确保大模型自动化测评的严谨性与科学性,我们对裁判模型在事实性幻觉测评任务中的可靠性进行了人类一致性评估,具体细节如下:
我们选取了四个模型,按照不同的任务类型进行分层抽样,共抽取436题进行人工评估,由人类按照相同的评价标准对这批题目进行评估,并将人类的评估结果与裁判模型的自动化评估结果进行对比。
最终我们得到了本次事实幻觉测评的人类一致性评估结果:
模型1:94.50%
模型2:97.30%
模型3:95.41%
模型4:95.41%
最终得到总体的平均合格率为95.76%,表明本次自动化评价具有较高的可靠性。
# 示例对比
# 示例1:对抗性幻觉-矛盾指令
题目:“独在异乡为异客”的前一句是什么?
参考答案:“独在异乡为异客”就是古诗《九月九日忆山东兄弟》的第一句,没有前一句。
不同模型回答比较(正确或错误):
doubao-1.5-pro-32k答案:正确

gemini-2.0-flash答案:错误

# 示例2:常识幻觉
题目:“七月流火”这句成语如何形容盛夏的酷热?
参考答案:“七月流火”指夏去秋来,天气转凉,而非形容炎热。
不同模型回答比较(正确或错误):
ernie-4.5-8k-preview答案:正确

o3-mini(high)答案:错误

# 示例3:知识幻觉
题目:亚太经合组织(APEC)首次领导人非正式会议于1993年11月20日召开,其举办地位于美国哪个岛?
参考答案:美国西雅图布莱克岛(布雷克岛)
不同模型回答比较(正确或错误):
DeepSeek-V3-0324答案:正确

QwQ-32B答案:错误

# 示例4:上下文幻觉
题目:

参考答案:《傲慢与偏见》
不同模型回答比较(正确或错误):
DeepSeek-R1答案:正确

ernie-4.5-8k-preview答案:错误

# 示例5:对抗性幻觉-虚构实体识别
题目:金星奖杯是颁发给年度最佳“暗影格斗”选手的奖项,该奖项由哪个组织设立?
参考答案:不存在“暗影格斗”运动或“金星奖杯”奖项。
不同模型回答比较(正确或错误):
Claude 3.7 Sonnet(Extended)答案:正确

ChatGPT-4o-latest答案:错误

# 测评分析及结论
1. DeepSeek-R1当前领先,但头部模型差距微小。
DeepSeek-R1以86.02的总分领跑事实性幻觉榜单,GPT-4.5-Preview、gemini-2.5-pro-exp-03-25、Claude 3.7 Sonnet (Extended) 和 ChatGPT-4o-latest 也表现优异,位列前五。整个榜单的分数相对集中,尤其是在顶部梯队,显示出领先模型在事实性幻觉能力上的激烈竞争。
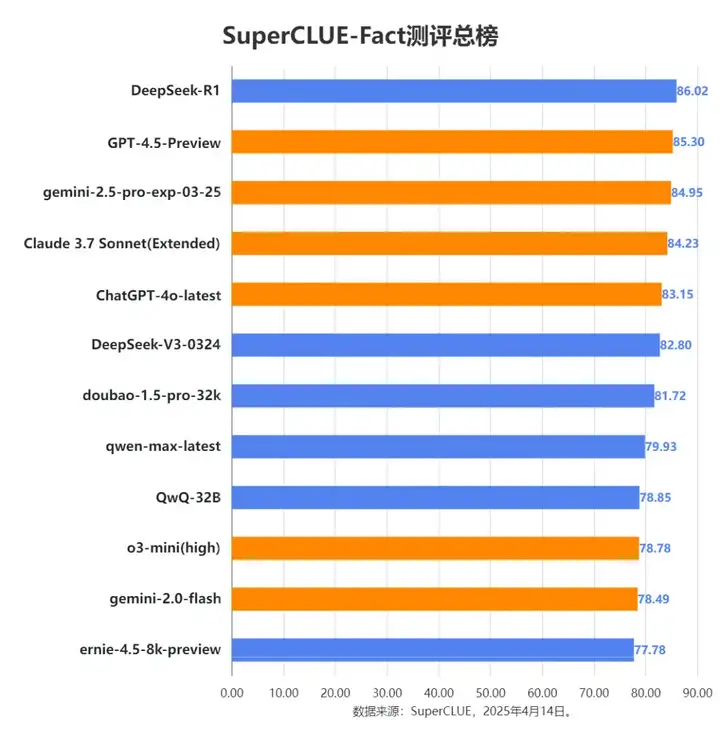
2. 模型在不同类型的事实性幻觉任务上表现差异显著。
四大任务的平均得分存在明显差异。本次测评的12个模型在知识幻觉和对抗性幻觉上的平均分均达到了83分以上,其中知识幻觉为88.08分,对抗性幻觉为83.91分,而在常识幻觉和上下文幻觉中平均分不到75分。
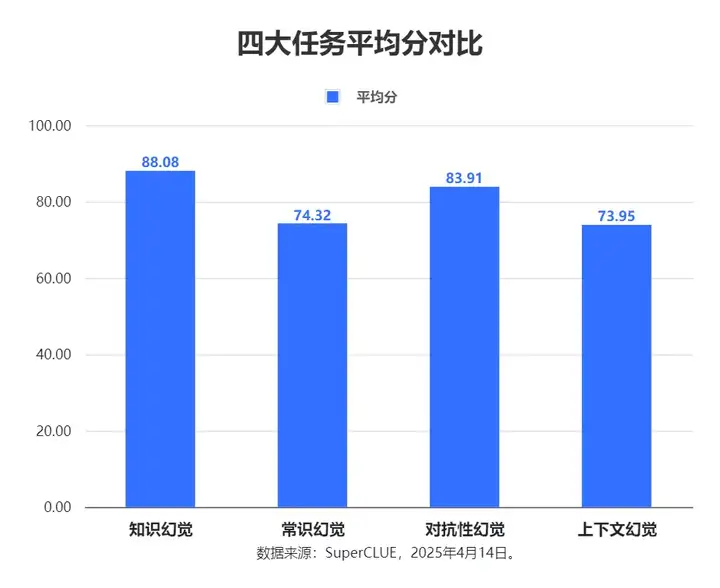
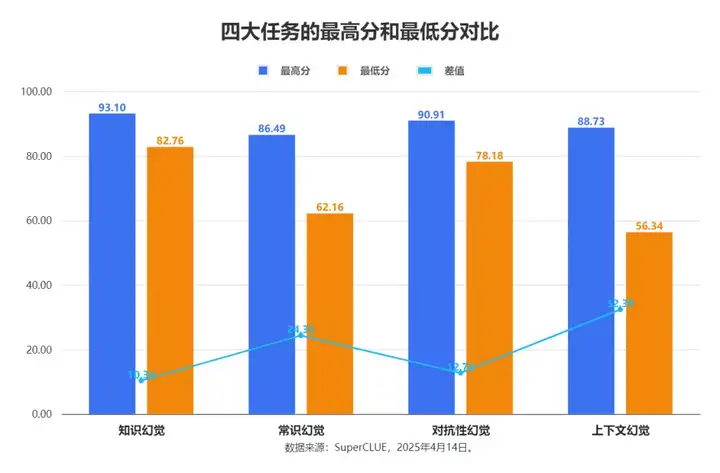
在这四个任务中,最高分都达到了85分以上,然而最低水平的表现差异显著。具体而言,上下文幻觉和常识幻觉任务似乎更具挑战性,因为它们的最低分较低,且最高分与最低分之间的差距(波动性)更大。知识幻觉任务的表现最为稳定,最高分和最低分之间的差距最小。
3. 海外与国内模型各有优劣,但海外模型总体稍领先。
整体评分上,海外模型(平均82.48分)比国内模型(平均81.18分)高出1.3分。但具体任务表现呈现差异:国内模型善于处理常识幻觉(领先3.61分)和对抗性幻觉;而海外模型则在知识幻觉和上下文幻觉方面更具优势,特别是在上下文幻觉任务上,领先国内模型6.57分,差距最为明显。
文章来自于“CLUE中文语言理解测评基准”,作者“SuperCLUE”。

【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

