就在昨天,深耕语音、认知智能几十年的科大讯飞,发布了全新升级的讯飞星火推理模型 X1。不仅效果上比肩 DeepSeek-R1,而且我注意到一条官方发布的信息——
基于全国产算力训练,在模型参数量比业界同类模型小一个数量级的情况下,整体效果能对标 OpenAI o1 和 DeepSeek R1。
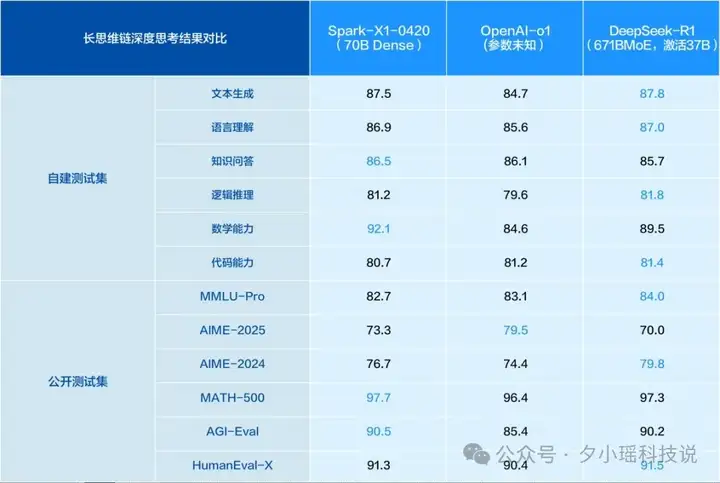
好家伙,训个类 o1 模型已经很难了,但算法工程师更懂“基于全国产算力训练”这句话的含金量和意义。
在这个算力受限、芯片卡脖子随时可能发生、甚至连老黄都愈发无奈的特殊时期,任何一个基于国产算力的自研 AI 大模型的进展都值得关注。
但,星火 X1,究竟能不能成为中国 AI 在国产算力下的又一张王牌,只有测试了才知道!
一手实测
根据讯飞官方的模型能力特点介绍,本文在数学、逻辑推理、文学能力这几个方向进行了重点体验。
数学
数学能力是大模型基础能力的试金石,也是衡量其严谨性和计算能力的重要维度。对于推理模型 X1,其在数学领域的表现自然是我们关注的重点。我们选择了几个不同类型的数学问题进行测试。
提示词(误导型连续对话):
2.8 和 2.12 哪个大
我下了个软件,有俩版本,2.8 和 2.12,哪个新


可以,竟然完全没被忽悠瘸。
接下来,来个更有挑战的。
提示词:删去正整数数列 1,2,3......中的所有完全平方数,得到一个新数列。这个新数列的第 2003 项是多少?
这道题考验的是对数列、完全平方数概念的理解,以及如何建立原数列位置与新数列位置之间的关系。它需要一定的数学建模和求解能力。
星火 X1 的思考过程和答案是这样的:

星火 X1 的回答非常清晰,它准确地抓住了问题的核心:新数列的第 n 项对应的原数 m,满足关系 m - floor(sqrt(m)) = n。 它的推导过程严谨,通过估算和验证,最终得出了正确答案 2048。
整个过程逻辑流畅,没有绕弯子,每一步都有理有据。对于这种类型的数学问题,星火 X1 表现出了非常扎实的基本功。
逻辑推理
逻辑推理问题往往没有标准公式,更能体现模型的真实“智商”。
先来一道难倒 99% 人类的推理问题——
提示词:笑死,我的猫叫呆呆,然后我把它绝育了,我朋友说它现在可以改名叫小林同学,哈哈哈哈哈哈。
笑点在哪?推断出是公猫还是母猫绝育
X1 的回答:

星火 X1 的回答可以说相当到位。它不仅准确地捕捉到了笑点核心——中文语境下的谐音梗(“林”与“铃”或“零”),还基于这个梗和相关的文化背景(“铃铛”梗常用于指代公猫绝育),精准地推断出了猫的性别是公猫。更进一步,它还分析了名字从“呆呆”到“小林同学”带来的“反差萌”效果。
接下来看看 X1 模型在更深层次的规划和决策能力方面的表现。
来看下面这个经典的“钻石问题”:
提示词:一楼到十楼的每层电梯门口都放着一颗钻石,钻石大小不一。你乘坐电梯从一楼到十楼,每层楼电梯门都会打开一次,只能拿一次钻石。问怎么才能拿到最大的一颗?
X1 的回答:

星火 X1 这个回答也是非常专业的。它准确地识别出这是一个经典的“最优停止问题”(Optimal Stopping Problem),并给出了标准且有效的解决策略:观察前 k 层(基于 n/e 规则估算,n=10 时 k≈3),记录下最大值 M,然后从第 k+1 层开始,选择遇到的第一个比 M 大的钻石;如果一直没遇到,则选择最后一层的钻石。
星火 X1 模型不仅对特定算法(秘书问题解法)的了解,更重要的是体现了其能够理解问题背后的概率、期望等数学问题,说明其核心的逻辑推理能力是在线的。
接下来,再来看看 X1 的知识问答 + 联网搜索能力。
联网知识问答
众所周知,一个模型的推理能力再强,也可能导致幻觉率居高不下,在知识问答上经常出差。就连近期 OpenAI 发布的 o3、o4-mini 系列模型都被不少网友吐槽幻觉率爆炸(比 o1 还要高不少)。
为此,我随手拿了个时效 query,加测一下星火 X1 在这方面的表现——

经过数据比对,星火 X1 关于本题的回答确实没有出现幻觉,在本题数字众多的情况下,能稳定输出每个细小的信息点还是有一定难度的。
文学能力
作为科技编辑,大模型的文学能力当然也是我重点关注的能力维度,推理模型也不例外。
我尝试让星火 X1 解释“时间是最公平的法官”这句话的深层含义——
提示词:解释"时间是最公平的法官"的深层含义,基于人性和现实世界运作方式给出客观真实的答案。并提供几个最有价值的问题来测试理解程度,附带这些问题的答案。

星火 X1 给出的答案远超预期!它不仅解释了时间“一视同仁”的表面公平,更深入挖掘了其作为“法官”的本质:
- 剥离伪装: 时间让谎言、投机失效,暴露真实后果。
- 拷问人性: 它放大矛盾,迫使个体面对自身行为的长期影响。
- 因果必然: 它确保代价与收益最终配比。
- 信息完整: 它推动事件发展,让多维度信息显现。
甚至还结合了社会评价与自我评价的关系,以及如何理解“篡改历史”的局限性。这已经不是简单的理解,而是一种较为深刻的洞察和哲学思辨。感觉它真的“读懂”了这句话,并且能用清晰、有条理的方式表达出来。
评测总结
经过这几个维度的实际体验,我觉得讯飞星火 X1 的亮点可以归纳成如下三点:
- 核心能力扎实: 在数学、逻辑推理、语言理解等推理和分析型任务上,讯飞星火 X1 展现出了非常高的水准,特别是在那个逻辑题上,它甚至比我测过的 DeepSeek-R1 表现更好。虽然它的参数量更小,但在这些关键能力上,它确实做到了能与 DeepSeek-R1 一战的水准。
- 基于国产算力: 这一点是它最独特的标签。在当前美国在芯片/算力大力限制出口的大背景下,一个完全基于国产算力平台训练出来的深度推理模型,其战略意义不言而喻。它又一次证明了,在国内算力被制约的环境下,我们依然有能力训练出能力出色的大模型。
- 效率与性能的平衡: 用更少的参数量实现对标效果,这背后是算法和工程上的巨大突破。
关于模型训练,这里我要强调下,X1 采用了多阶段强化学习,根据问题难度进行训练,并动态优化强化学习过程,提升了在复杂任务上的深度思考能力。同时,它还融合了快思考与慢思考的统一训练,模型能根据指令灵活切换思考模式,方便下游应用高效部署,满血版星火 X1 仅需 4 张卡(华为 910B)就能部署。
更重要的是,通过一系列工程技术创新(如显存动态卸载、训推协同、推理引擎冬眠等),有效保障了在国产算力平台上也能高效、稳定地完成整个强化学习训练过程。
这套组合拳是它能用更小参数实现出色性能的关键。
可以毫不夸张地说,在完全国产算力的训练限制下,讯飞星火 X1 是目前国内的最强推理模型之一。
讯飞在过去一年多,不仅发布了星火大模型,更与华为等伙伴深度合作,建成了国内首个万卡国产算力平台“飞星一号”、“飞星二号”。并在这样的国产“底座”上,训练出了星火 X1 这样的高性能推理模型。
这也证明了基于国产算力训练出业界顶尖水平的大模型是完全可行的,我们对外部的依赖会越来越少,抵御外界负面冲击的底气也会越来越足。
因此,星火 X1 也不仅仅是一个大模型产品和技术突破,其也是国产 AI 走向成熟和自立自强,产业进一步自主可控的一步。
写在最后
AI 大模型的发展,是一场技术、算力、应用乃至国家级力量的全面较量。国产算力的突破和在此基础上训练出比肩国际巨头的模型,是我们必须走也正在走的关键一步。
讯飞星火 X1 的发布,让我们看到了这条路径的可行性和巨大潜力。它不仅仅是讯飞的成绩,更是整个中国 AI 生态协同创新的缩影。
未来已来,期待国产 AI 继续加速奔跑!
最后,贴一下星火 X1 的体验入口:
- 网页端:https://xinghuo.xfyun.cn/desk
- APP 端:应用市场搜索并下载“讯飞星火”APP
文章来自微信公众号 “ 夕小瑶科技说 “,作者 夕小瑶编辑部

【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

