GPT-4o带火的漫画风角色生成,现在有了开源版啦!
腾讯混元携手InstantX团队合作打破次元壁,开源定制化角色生成插件——InstantCharacter。

以往针对角色驱动的图像生成方法,都存在一定的缺陷。
例如,基于适配器的方案虽然基本实现主体一致和文本可控,但在泛化性、姿势变化和风格转换的开放域角色方面仍然存在困难。
基于微调则需对模型进行重新训练,从而浪费过长的时间。更不必说,费用高昂的推理时间的微调。
而现在这个插件基于DiTs(Diffusion Transformers),能在保证推理效率和文本可编辑性的同时,完美实现角色个性化创作。

那么一起看看它具体是如何实现的?
方法介绍
现代 DiTs与传统的UNet架构相比,展现出前所未有的保真度和容量,为生成和编辑任务提供了更强大的基础。
基于此,InstantCharacter扩展了DiT,从而用于强泛化性和高保真的角色驱动图像生成。
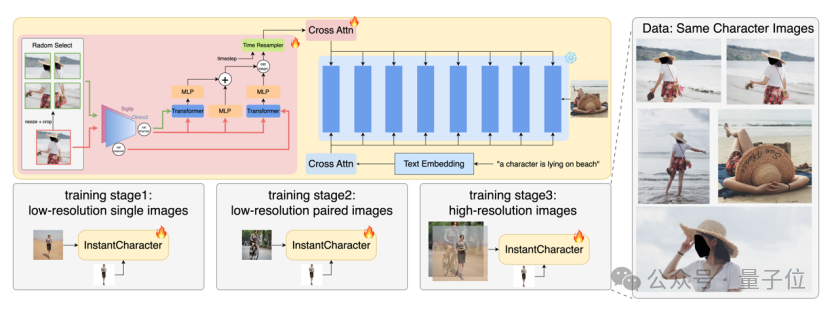
InstantCharacter的架构围绕两个关键创新展开:
1.可扩展适配器 :开发了一个可扩展的适配器模块,有效解析角色特征并与DiTs潜在空间无缝交互。
2.渐进训练策略:设计了一个渐进式三阶段训练策略,以适应收集的多功能数据集,使角色一致性和文本可编辑性的分开训练成为可能。
可扩展的适配器设计
传统的定制适配器,例如IPAdapter或ReferenceNet,在DiT架构中往往失效,因为它们是专为基于U-Net的模型设计的,缺乏可扩展性。
为了更好地适应DiT模型,研究员提出了一种可扩展的full-transformer适配器,
它作为角色图像与基础模型潜在生成空间之间的关键连接,通过增加层深度和隐藏特征尺寸实现可扩展性。
该适配器由三个编码器块组成:
1.通用视觉编码器:
首先利用预训练的大型视觉基础编码器来提取通用角色特征,从它们的开放域识别能力中受益。
以前的方法通常依赖于CLIP,因为它对齐了视觉和文本特征。
然而,虽然CLIP能够捕捉抽象的语义信息,但它往往会丢失对维持角色一致性至关重要的详细纹理信息。
为此,研究者用SigLIP替代CLIP,SigLIP在捕捉更细粒度的角色信息方面表现出色。
此外,引入DINOv2作为另一个图像编码器来增强特征的稳健性,减少背景或其他干扰因素导致的特征损失。
最后,通过在通道维度的拼接整合DINOv2和SigLIP特征,从而获得更全面的开放域角色表示。
2.中间编码器:
由于SigLIP和DINOv2是在相对较低的384分辨率下预训练和推理的,在处理高分辨率角色图像时,通用视觉编码器的原始输出可能会丢失细粒度特征。
为了缓解这个问题,采用双流特征融合策略分别探索低级特征(low-level features)和区域级特征(region-level features)。
首先,直接从通用视觉编码器的浅层提取low-level features,捕捉在更高层次中常常丢失的细节。
其次,将参考图像分割成多个不重叠的区块,并将每个区块输入视觉编码器以获取region-level features。
然后,这两种不同的特征流通过专用的中间transformer编码器进行分层整合。
具体来说,每个特征路径都由独立的transformer编码器单独处理,以与高级语义特征整合。
随后,来自两个路径的精炼特征沿着token维度连接,从而建立一个全面的融合表示,捕捉多层次的互补信息。
3.投影头:
最后,精炼的角色特征通过投影头投射到去噪过程,并与潜在噪声交互。
通过时间步感知的Q-former实现这一点,它将中间编码器输出作为键值对处理,同时通过注意力机制动态更新一组可学习的查询向量。
转换后的查询特征随后通过可学习的交叉注意力层注入去噪空间。最终,适配器可以实现强身份保持和复杂文本驱动的灵活适应。
训练策略
为了有效训练该框架,研究者首先精心构建了一个高质量的数据集,
包含1000万张多样化的全身人类/角色图像,包括用于学习角色一致性的配对图像和用于实现精确文本到图像对齐的非配对数据集。
其次,精细设计了训练方案,以优化角色一致性、文本可控性和视觉保真度。
为了实现角色一致性,首先使用未配对数据进行训练,其中角色图像作为参考引导进行自重建,以保持结构一致性。
同时研究发现使用512的分辨率比1024更为高效。
在第二阶段,继续以低分辨率(512)进行训练,但切换到配对训练数据。
为生成不同动作、姿势和风格的角色图像,研究者通过将角色图像作为输入,生成新场景中的角色。
这个训练阶段有效消除了复制粘贴效应,增强了文本可控性,确保生成的图像准确遵循文本条件。
最后一个阶段涉及使用配对和非配对图像进行高分辨率联合训练。团队发现有限数量的高分辨率训练迭代可以显著提高图像的视觉质量和纹理。
这一阶段利用了高质量图像实现高保真和文本可控的角色图像。
实验结果
作者对基于FLUX的先进方法进行定性比较:OminiControl、EasyControl、ACE+和UNO;以及大型多模态模型GPT4o。
为了评估,作者收集了一组不存在于训练数据中的开放域角色图像。
现有方法存在局限性:OminiControl和EasyControl无法保留角色身份特征,而ACE++仅在简单场景中保持部分特征,但在面对动作导向的提示时表现不佳。
UNO过度保持一致性,这降低了动作和背景的可编辑性。可以看到,InstantCharacter达到了与GPT4o相当的结果,但它不是开源的。
相比之下,InstantCharacter始终表现最佳。
具体而言,InstantCharacter在保持精确的文本可控性的同时,实现了更出色的角色细节保留和高保真度,即使是针对复杂的动作提示。


InstantCharacter还可以通过引入不同的风格loras来实现灵活的角色风格化。
如图所示,InstantCharacter可以在吉卜力和Makoto风格之间切换,同时不影响角色一致性和文本可编辑性。然而,Jimeng和GPT4o很难灵活地保持这些风格。

本文插件代码及项目均已开源,鼓励更多的人积极参与相关工作探讨。
论文地址:https://arxiv.org/abs/2504.12395
代码地址:https://github.com/Tencent/InstantCharacter
项目地址:https://instantcharacter.github.io/
文章来自于微信公众号 “量子位”,作者 :InstantCharacter

【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

