最近在看 Agent 方向的论文和产品,已经被各种进展看花了眼。但我发现,真正能超越 demo,能在 B 端场景扎实落地的却寥寥无几。
前两天跟阶跃的朋友聊起来,朋友说阶跃的多模态模型,已经在诸多智能终端 Agent 上落地了,涵盖了车端、手机端、具身智能和 IoT 四大场景。
这个后面再讲,因为,我发现光阶跃近期悄悄发布的 3 款多模态模型,就够写一篇文章的了。
而这 3 个模型,也是促进多模态 Agent 应用落地的重要模型。
这 3 个模型涵盖了三个方向:
1.图像编辑模型 Step1X-Edit(开源)
2.多模态推理模型 Step-R1-V-Mini
3.图生视频模型 Step-Video-TI2V(开源)
先来重点讲下昨天阶跃刚刚开源的改图模型——
真正开发上线过图像类应用的小伙伴都知道,在图像的应用落地方面,比起从头开始“文生图”,大众对手里现有的图片/照片的编辑需求其实更为广泛。
但,开源好用的图像编辑模型实在太少了。
可能阶跃也洞察到了这个需求,索性昨天发布了 Step1X-Edit 这个图像编辑模型,而且——
发布即开源,开源即 SOTA。
Step1X-Edit:图像编辑领域的开源 SOTA
图像编辑,听起来好像比文生图更简单。但实际上,如果让 AI 来做,特别是通过自然语言指令来编辑,会变得很难。
大模型不仅要精准理解用户上传图像的语义与细节,还要保证图像中人物、物体、背景的高度一致性,
还要充分遵循自然语言指令,在保证改图真实感的同时实现可控生成,以及文本-图像模态的深度融合,缺一不可。
阶跃这次的 Step1X-Edit,官方总结了三个关键能力,恰好就对应了上面说的三个方面。
- 语义精准解析:能理解比较复杂的、组合式的自然语言指令,能够灵活应对多轮、多任务编辑需求。
- 身份一致性保持:编辑后能稳定保留人脸、姿态与身份特征,在虚拟人、电商模特,这些高一致性场景里特别重要。
- 高精度区域级控制:支持对图片里的特定区域进行定向编辑,比如换材质(把木桌子换成大理石)、改颜色、调整光照等,同时保持整体风格统一。
用一句话总结就是:
Step1X-Edit,不只能“改图”,更能“听得懂、改得准、保得住”。
先贴一下传送门,感兴趣的小伙伴可以一起测试:
阶跃 AI网页端:
stepfun.com
APP 端:
直接搜索「阶跃 AI」APP 即可。
比如,我们尝试把夕小瑶全身照换成像素风格。
提示词:换成像素风格

突然有一种想把像素风版夕小瑶做成小霸王游戏的冲动...
再来一个复杂换背景色的中文指令——
创建一张色彩鲜艳的手工簇绒地毯图片,放置在简单的地板背景上。地毯设计大胆、有趣,具有柔软蓬松的质地和粗纱线细节。
从上方拍摄,在自然日光下,带有略微古怪的 DIY 美学风格。色彩鲜艳、卡通轮廓、触感舒适的材料——类似于手工簇绒艺术地毯。

材质、颜色、风格都遵循地挺到位的。这个模型尤其擅长中文,用中文指令调整图片元素,可能会更顺手。
我进一步研究了下,发现这个模型支持 11 个高频的图像编辑任务类型——
包括但不限于文字替换、风格迁移、材质变换、人物修图等。

阶跃也放出了这个模型的技术报告:
https://arxiv.org/pdf/2504.17761
我觉得有几个点值得关注——
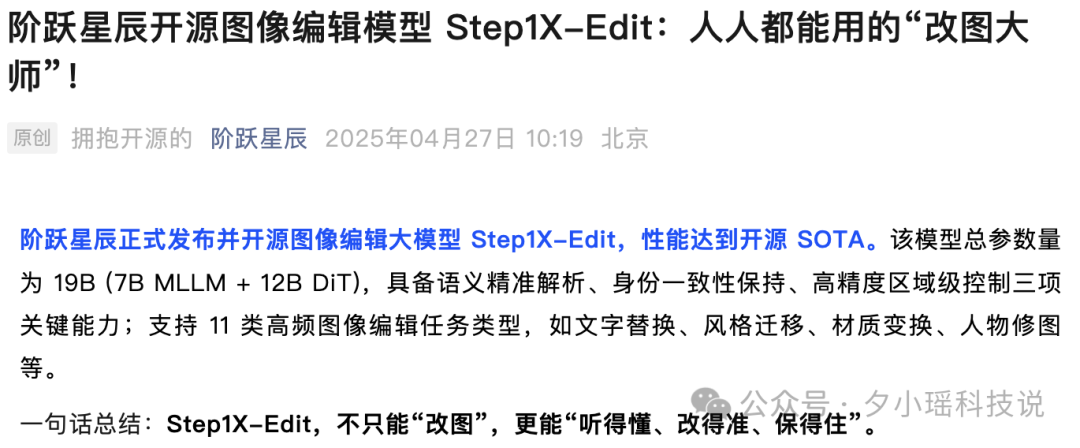
技术实现上,Step1X-Edit 用了 MLLM(多模态大语言模型)+ Diffusion 的架构。
MLLM 负责理解你的指令和图像内容(相当于大脑),Diffusion 模型则完成图像的修改和生成(相当于画手)。
这种分工让模型在理解复杂指令和控制生成细节上更有优势。
官方还特别构建了一个规模超大的图像编辑训练数据集(筛选后百万量级),包含 11 类常见编辑任务,比如文字替换、风格迁移、背景调整等。
模型总参数量只有 19B (7B MLLM + 12B DiT),但在性能上,拿到了开源 SOTA,表现很接近 GPT-4o 和 Gemini 2.0 Flash。
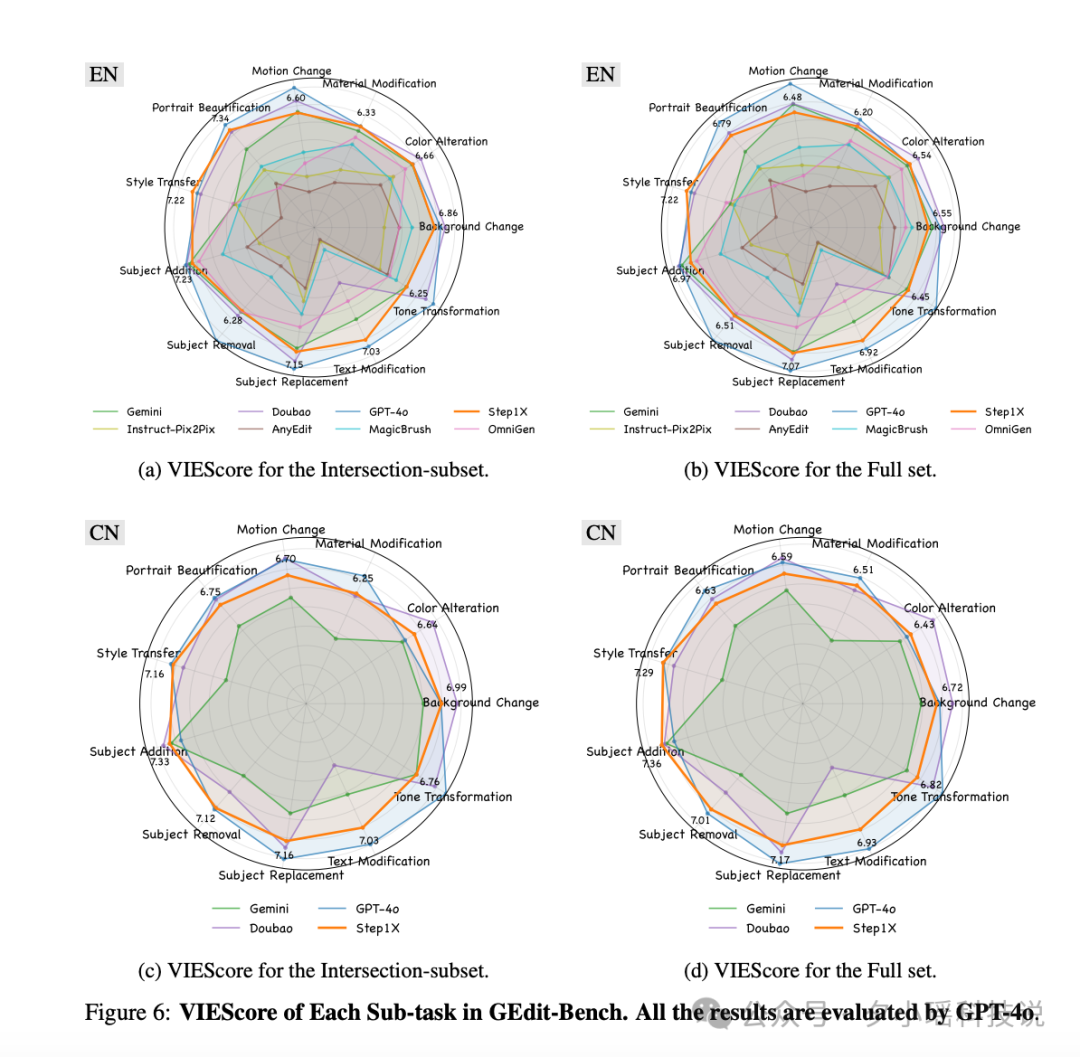
个人觉得,Step1X-Edit 的开源,对于整个 AI 图像编辑领域是个不错的贡献。不仅提供了技术上的思考(比如那个解耦架构),也真实地解决用户痛点。
贴下开源传动门:
Github:
https://github.com/stepfun-ai/Step1X-Edit
HuggingFace:
https://huggingface.co/stepfun-ai/Step1X-Edit
ModelScope:
https://www.modelscope.cn/models/stepfun-ai/Step1X-Edit/summary
再来讲下多模态推理模型Step-R1-V-Mini。
Step-R1-V-Mini:让 AI 不止“看图说话”,还能“看图思考”
看懂图片是多模态模型的“视力”,对图片进行思考和推理,则是多模态模型的“智力”。
4 月初,阶跃新出的 Step-R1-V-Mini,就是专门冲着这个“多模态推理”来的,集成了多模态理解 + 深度推理两种能力。
我们前些阵子的文章提过,o3 和 o4-mini,凭借“福尔摩斯”般的图片推理能力,可以快速定位图片里的地点。
我们用类似的题目,测一下 Step-R1-V-Mini是否具备类似的能力。
这是网友温布利球场的实拍图片,看它能不能猜对这是哪儿——

推理正确!
再比如,根据照片推理宇航员离地高度——

地球占据视野约一半,有明显地球曲率,符合低地球轨道特征,估算合理。
这个模型也已经可以在阶跃的官网和开放平台上体验了,感兴趣的小伙伴可以去测测。
阶跃 AI 网页端:
https://yuewen.cn/chats/new
阶跃星辰开放平台:
https://platform.stepfun.com/docs/llm/reasoning
今年 2 月份的时候,我们曾报道过,阶跃同时开源了两个模型,一个是文生视频模型 Step-Video-T2V,一个是支持实时语音对话的语音模型Step-Audio。
没想到这么快的速度,又开源了图生视频模型Step-Video-TI2V。

这次主打“运动幅度可控”和“镜头运动可控”两大特点。

生成的视频分辨率是 540P,时长大约 5 秒(102 帧)。不算特别高清和长,胜在开源和可控性。
对于快速制作一些动态效果、社交媒体素材或者创意原型来说,够用了。
附开源传送门:
https://github.com/stepfun-ai/Step-Video-TI2V
真·多模态卷王
阶跃这次密集“上新”,其实并不让我意外。
回顾他们过去一年的动作,你会发现这完全符合他们一贯的打法——在多模态领域持续深耕、快速迭代。
“多模态卷王”,这个称号某种程度上是他们自己“卷”出来的。我列了一个表:
粗略算了下,公司成立 2 年,截至目前一共发布了 21个模型,15个是多模态模型,比例超过七成!
这投入程度,说他们是“多模态卷王”都不过分。而且在多模态的各个主要技术方向上,阶跃基本都有布局。
我查了下,Step-1V、Step-1o Vision 等模型,之前在国内外知名的多模态评测榜单
(比如 OpenCompass、LMSYS Chatbot Arena 视觉榜)上拿到过比较靠前的位置,甚至是中国大模型里的第一名。
更有说服力的是,是来自商业客户的反馈。
比如茶百道门店已经用上了他们的 Step-1V 模型做智能巡检。

网红 AI 应用“胃之书”的开发者公开表示,"测试了一圈国内模型,发现阶跃的付费率最高。"

所以,阶跃在多模态领域的“卷”,是建立在全面布局、快速迭代、性能实力和商业落地上的。
不止于模型:阶跃的 Agent“触手”伸得有多快?
当然,模型本身只是“弹药”,最终还是要看打向哪个“战场”。阶跃的多模态能力,显然不仅仅是论文或榜单。
今年 2 月,阶跃明确提出了要发力智能终端 Agent,瞄准了车、手机、具身智能、IoT 这四大关键场景。
这个战略,就是要把强大的多模态理解、推理和生成能力,赋能到我们日常接触的各种智能设备上,让它们变得更“聪明”、更“有用”。
更值得注意的是他们的落地速度。
官宣战略才几个月,就已经看到了一系列实实在在的进展:
- 智能汽车: 和吉利汽车集团、以及千里科技深化技术合作。
在 4 月的上海车展上,吉利展示了一颗充满科技感的蛋形智能座舱,由阶跃星辰多模态大模型提供底座技术支持。

- 手机终端: 和 OPPO 合作,多模态模型已经落地到了 OPPO 的多款旗舰机型上,
实现了像“一键问屏”(拍照或截屏提问)、“一键全能搜”(语音指令跨 App 操作)这样的创新功能。
- 具身智能: 这个领域现在非常热。阶跃动作也很快,先后和机器人领域的“当红炸子鸡”智元机器人、以及专注于物理世界推理的原力灵机签署了战略合作。
目标很明确,就是要探索“大模型 + 机器人”的融合,打造能在物理世界理解和行动的 RoboAgent。
- IoT 终端: 和 TCL 这样的家电和 IoT 平台大厂合作,推动设备智能化和互联互通体验升级。
大家可以留意一下这些合作伙伴,都是各自行业里的重量级玩家或领先者。这就说明了阶跃的技术实力和商业拓展能力得到了市场的认可。
写在最后
说实话,作为天天泡在这个圈子里的人,看到这种“爆肝”式的迭代速度,既觉得兴奋,又有点‘卷不动’的感觉。
兴奋的是,技术边界又被往前推了一大步,我们能玩的东西更多了;“卷不动”是感叹这进步速度,真是稍不留神就可能被拉下。
扒完阶跃这波密集的上新,感觉非常地过瘾。从图像编辑、多模态推理,图生视频,到智能终端 Agent 的初见成效,真的是火力全开。
多模态这块,他们一直在稳定输出,没掉过链子,而且路径清晰且有竞争力。
继续期待蹲下一个惊喜吧。
文章来自于微信公众号 “夕小瑶科技说”,作者 :夕小瑶编辑部

【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales

