新的亿级大规模图文对数据集来了,CLIP达成新SOTA!
格灵深瞳最新发布的高质量数据集RealSyn,不仅规模大——包含1亿组图文对,而且每张图片都同时关联多个真实和合成文本。
所有的图像和句子都基于冗余进行了严格过滤,在确保数据质量的同时,引入基于簇的语义平衡采样策略,构建了可满足多样工作需求的三种规模大小的数据集:
15M、30M、100M。
这下CLIP终于可以大展身手了!
RealSyn所展现的超强扩展性,以及在视觉语言表征学习中极为优越的表现,让模型性能在多任务中达到了新的SOTA。
目前,该数据集已全面开源,可点击文末链接一键获取~

以下是RealSyn的更多相关细节。
相关工作
大规模预训练数据集
近年来,多个从互联网收集的大规模图像-文本数据集陆续发布。
YFCC100M数据集提供了自 Flickr 2004 年创立至2014年初期照片和视频记录及分享演变的全面概览。
由于下载失败和非英语标题,DeCLIP重新处理 YFCC15M 数据集并提出了一个新版本。
此外,LAION400M数据集包含从 Common Crawl 收集的4亿个图像-文本对并被广泛的应用到视觉-语言预训练。
最近还推出了几个大规模图文交错文档数据集。
OBELICS数据集使用全面的过滤策略,包括1.41亿个网页、3.53亿张相关图片和从 Common Crawl 提取的1150亿文本标记。
然而,由于数据格式的限制和训练效率的低下,图文交错文档目前不适用于视觉语言对比表示学习。
视觉语言预训练
作为视觉语言预训练领域的开创性工作,CLIP因其强大的零样本识别能力和卓越的迁移学习表现而受到广泛关注。
受 CLIP 启发,近年来诞生了大量视觉-语言预训练研究。
SLIP通过结合自监督学习与 CLIP 预训练提高性能。DeCLIP通过整合跨模态的多视角监督和来自相似对的最近邻监督,提高了预训练效率。
为了减轻噪声数据的影响,ALIP引入了一种动态样本权重分配的门控机制。
尽管这些方法取得了显著的进展,但它们主要依赖于从互联网上爬取的大规模图像-文本对。
最近的研究表明,随着高质量图像-文本数据集的扩展,CLIP的能力也在增强。因此迫切需要开发新的数据构建范式以进一步扩大高质量图像-文本数据的规模。
合成标题
最近的研究表明,从网站获得的图像-文本对含有内在噪声,这直接影响视觉-语言预训练的有效性。
为提高现有数据集的质量,LaCLIP利用大型语言模型的上下文学习能力重写与每张图片相关的文本描述。
CapsFusion使用大型语言模型精炼来自网络的图像-文本对和合成标题信息,提高多模态预训练数据的质量。
类似地,DreamLIP 使用预训练的大型多模态模型为3000万张图片生成详细描述。
然而,这些方法主要关注合成数据的增强,忽视了现实世界数据的重要性。此外,这些方法生成的合成标题的多样性和分布本质上受到所用生成模型能力的限制。
RealSyn数据集
真实世界数据抽取
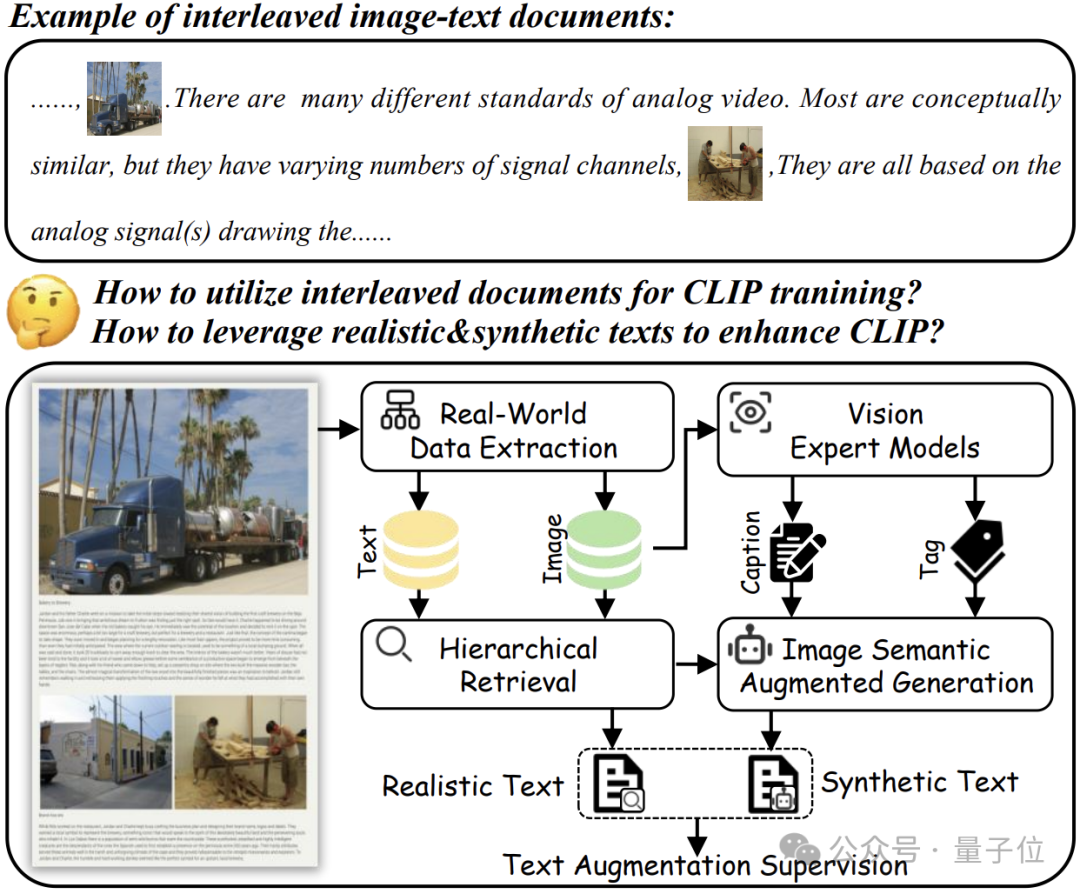
为了将图文交错文档转换为视觉-语言表示学习的形式,团队建立了一个真实世界数据提取Pipeline以提取高质量的图像和文本。
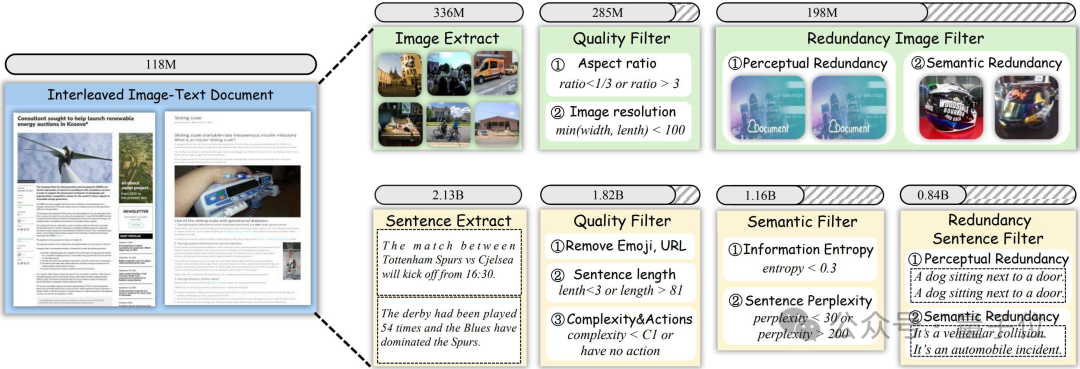
该流程包括三个步骤:数据提取、图像过滤和句子过滤。
数据提取:
团队使用来自OBELICS的1.18亿个图文交错文档作为主要数据源。
所有图像都被提取并存储在专用的图像数据库中,句子则使用自然语言工具包(NLTK)进行分割,并存储在单独的句子数据库中。
这个过程共计从多模态文档中抽取了3.36亿张图像和21.3亿个句子。
图像过滤:
在提取了3.36亿张图像后,团队设计了一个两阶段的过滤过程,以提升数据质量并降低冗余。
首先,丢弃符合以下任一条件的图像:
1.图像短边长度少于100像素。
2.宽高比超过3或低于1/3。
这一步去除了5100万张低质量图像。
接下来,参考CLIP-CID,使用EVA02-CLIP E/14-plus模型来提取图像嵌入,并应用Union-Find算法来消除感知和语义上的冗余图像。
这一步去除了额外的8700万张图像,最终得到了一组精炼的1.98亿张高质量图像数据集。
句子过滤:
从图文交错文档中提取了21.3亿个句子后,研究人员基于质量、语义和冗余进行严格过滤。
首先,根据以下标准来过滤低质量句子:
1.包含表情符号或URL;
2.句子包含少于3个或多于81个单词;
3.根据CAT,保留至少具有C1复杂度并包含动作的样本。
这一阶段将语料库规模从21.3亿减少到18.2亿。
然后,对剩余的句子进行语义过滤,研究人员通过信息熵来排除掉语义信息较少的句子:
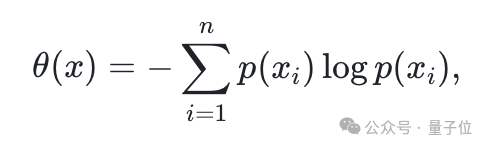

研究人员保留困惑度分数在30到200之间的句子。经过整体语义过滤后,语料库缩减至11.6亿个句子。
在最后阶段,类似于冗余图像过滤,对句子进行了感知和语义去重。
这一过程最终得到了一个包含大量现实世界知识的精炼语料库,共计8.4亿个句子。
检索和生成框架
在从文档中提取高质量图像和句子后,团队提出了一个高效且可扩展的框架,
用于为每个图像检索多个语义相关文本,并利用大型语言模型将检索的真实文本与细粒度的视觉信息整合,生成合成文本。
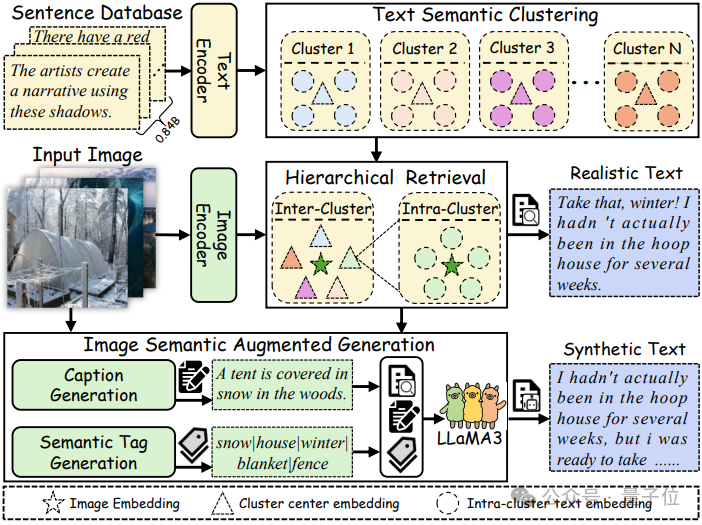
框架的架构主要包括三个组件:文本语义聚类、层次化检索和图像语义增强生成。
- 文本语义聚类:
为了有效地为每个图像检索多个语义相关文本,首先使用EVA02-CLIP E/14-plus模型对所有句子进行编码。
受Unicom启发,研究人员利用标准的K-means算法离线将8.4亿个文本通过高效特征量化划分为200万个簇。
- 层次化检索:
考虑到直接从8.4亿个句子中检索语义文本的计算开销过高(在8个A100 GPU上超过10,000小时),团队设计了一种层次检索方法来优化计算效率。
首先执行簇间检索,找到每个图像最相关的簇中心。然后,研究人员将共享相同簇中心的图像分组,并执行簇内检索,以获取多个语义相关句子。
这种方法能够在40小时内使用8个A100 GPU完成对1.98亿图像和8.4亿句子的检索。
- 图像语义增强生成:
尽管检索到的真实文本表现出满意的性能,但它们在捕捉细粒度视觉语义方面存在限制。为了解决这个问题,团队引入了图像语义增强生成模块。
该模块最初采用OFA模型为每张图片生成一个简洁的标题。然后,团队集成了开放集图片标签模型RAM++,该模型提取对象检测标签。
考虑到RAM++仅支持4000个标签,研究人员通过加入额外的4000个来自真实世界句子的标签,将这个集合扩展到8000个标签。
参考CapsFusion,团队利用ChatGPT4 Turbo将检索到的真实文本与简洁标题和图片标签合并,构建一个 10 万条指令的数据集。
随后,使用LLaMA Factory对 LLaMA3-8B模型进行微调,并部署vLLM进行大规模推理。
最终,将1.18亿多模态交错文档转换为1.98亿图文对,其中每张图片都与多个检索到的真实文本和合成文本相关联。
语义均衡采样
为了进一步提升数据集的质量和多样性,团队在1.98亿图文对中进行语义均衡采样。
具体来说,使用EVA02-CLIP E/14-plus来编码并计算图像和合成文本之间的余弦相似性。
为了减少在预训练期间因OCR相关或不匹配对的影响,研究人员过滤掉余弦相似度高于0.61或低于0.51的2970万对数据。
受到MetaCLIP的启发,还引入了一种简单但高效的基于簇的语义平衡采样策略,并将剩余的 1.683亿对中的图像嵌入聚类到100万个中心。
为了增强数据集的语义多样性,团队从超过这些阈值的簇中随机选择20,35和180个样本,同时保留较小簇中的所有样本。
这种方法最终构建了 RealSyn15M、RealSyn30M和RealSyn100M数据集。
实验
实现细节

为了验证RealSyn数据集的有效性,团队将RealSyn与之前的数据集在不同模型和数据规模上进行比较,将RealSyn15M与DeCLIP过滤的YFCC15M进行比较。
遵循ALIP的方法,还与LAION15M、LAION30M和LAION100M(从LAION400M随机选取的子集)进行比较。
主要结果
- 线性探测:
在下表中,展示了ViT-B/32模型在20个下游数据集中的线性探测性能。

当在1500万规模上预训练时,RealSyn15M在20个数据集中的16个中超过了YFCC15M,平均性能提高了6.9%。
此外,RealSyn15M在20个数据集中的18个中表现优于LAION15M,平均改进了 1.6%。
当数据集扩展到3000万和1亿时,RealSyn分别在LAION上实现了平均1.3%和1.4%的性能提升。
这些结果证明了RealSyn数据集在视觉-语言表示学习中的有效性。
- 零样本迁移:
团队使用与SLIP相同的提示模板,评估了ViT-B/32模型在20个分类基准测试中的零样本迁移性能。
如表所示,RealSyn15M在20个数据集中的18个上超过了YFCC15M,平均性能提高了14.3%。
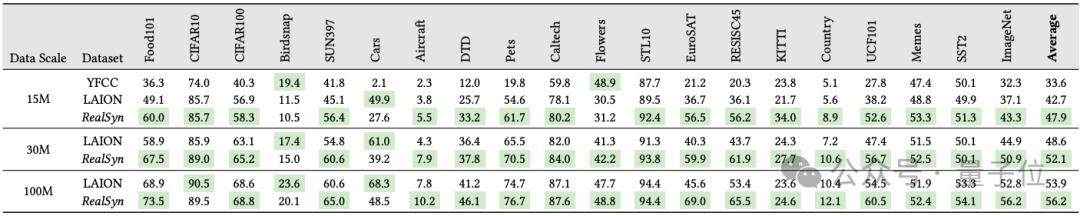
与LAION15M相比,RealSyn15M在20个数据集中的18个上表现优异,平均改进了 5.2%。
当数据集规模扩大到3000万和1亿时,RealSyn分别比LAION实现了平均3.5%和2.3%的性能提升,凸显了其效率和可扩展性。
- 零样本图文检索:
在表中,展示了ViT-B/32模型在不同规模数据集上预训练后的零样本图文检索性能。
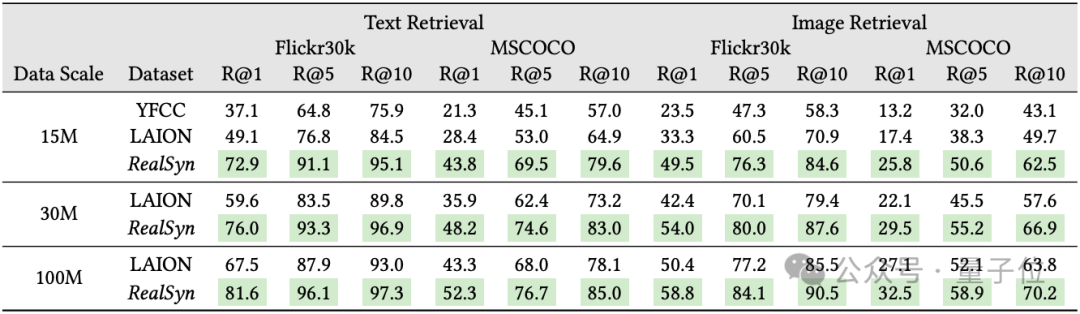
RealSyn 在所有评估指标上均取得了优异的结果。具体而言,RealSyn15M在Flickr30K上将召回率提高了35.8%&26%,在MSCOCO上提高了22.5%&12.6%。
RealSyn30M在Flickr30K上将召回率提高了16.4%&11.6%,在MSCOCO上提高了12.3%&7.4%。
这种在跨模态检索性能上的显著提升表明,RealSyn数据集通过利用真实和合成文本有效地改善了视觉-语言表示学习,从而实现了健壮的表示和增强的跨模态对齐。
- 零样本鲁棒性:
在下表中,展示了零样本鲁棒性性能。结果显示,RealSyn显著提升了视觉-语言预训练模型的鲁棒性。
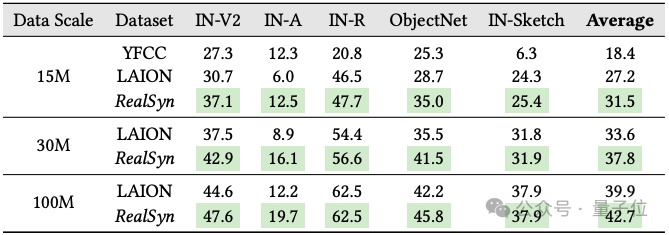
具体而言,与LAION相比,RealSyn分别在15M、30M万和100M的数据集上平均性能提高了4.3%、4.2%和2.8%。
这一显著的性能提升主要源自于使用检索到的真实文本,这些文本不受生成模型限制,
并且与YFCC和LAION相比具有更优越的概念多样性,从而大幅增强了模型的鲁棒性。
- 通过MLLM进行图像描述
图中展示了使用不同数据集(LAION与RealSyn)训练的LLaVA-1.5在图像描述性能上的表现。
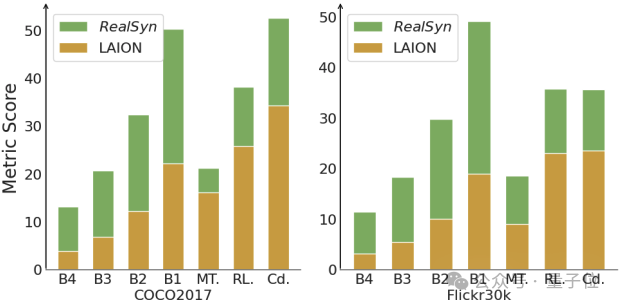
最初,团队首先使用LLaVA-1.5的初始558k数据集将视觉特征映射到文本特征空间。然后,他们从LAION和RealSyn开发了一个图像描述数据集进行指令调优。
具体来说,从每个数据集随机选择100万样本,并进行了两个周期的训练。
由此可见,RealSyn在COCO2017和Flickr30k基准测试的所有评估指标上均显著优于LAION。
这一显著的性能提升证实了RealSyn数据集的更高质量和更好的图像-文本对齐。
分析
统计分析
- 基于主题的评估:
参考MMC4的方法,团队在随机抽取的100万图像-真实文本对上运行了LDA,涵盖30个主题。
下图中展示了六个主题的比例和示例:动物、食物、飞机、花卉、汽车和地标。
值得注意的是,数据集中与“花卉”和“汽车”主题相关的样本极少,分别仅占总数的0.4%和0.9%。
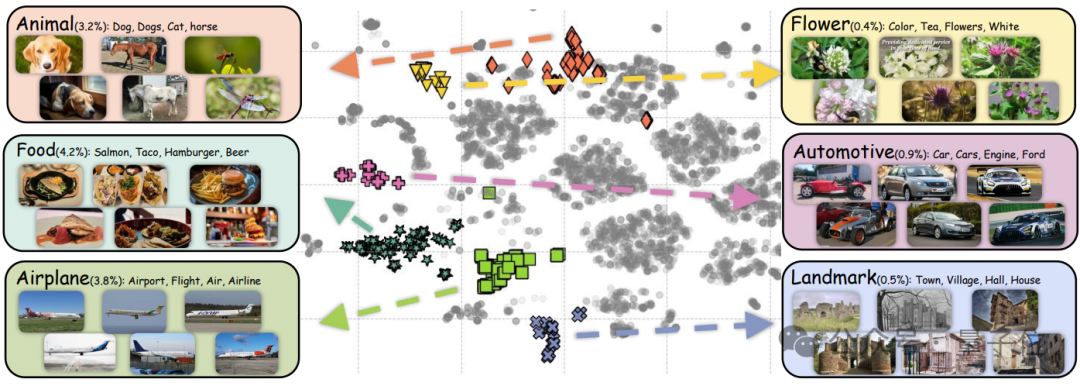
这种样本的稀缺限制了模型充分学习这些概念的能力,从而在Flower和Car数据集的线性探针和零样本迁移评估中影响了其性能。
- 丰富性评估:
图中展示了来自YFCC15、LAION、RealSyn-R1(检索到的最相关真实文本)和 RealSyn-S1
(基于RealSyn-R1的语义增强合成文本)的1500万样本的图文相似性和文本令牌分布。
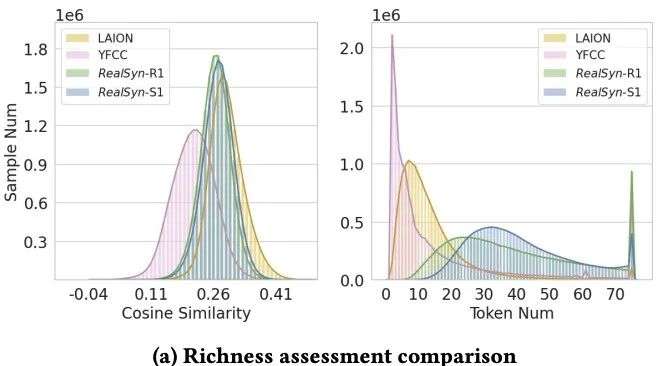
与从互联网收集的数据集相比,即使在移除OCR数据之后,RealSyn仍展示出稳健的相似性指标。
此外,检索到的真实文本和合成文本都包含更多的词汇量,这可以提供更丰富的文本环境,从而增强视觉-语言表示学习。
- 多样性评估:
RealSyn是基于现实世界中交错的图文文件构建的,包含了广泛的多样性信息。
遵循之前的研究,团队随机选择了20万样本来计算标题中独特实体的数量,以评估不同数据集的数据多样性。
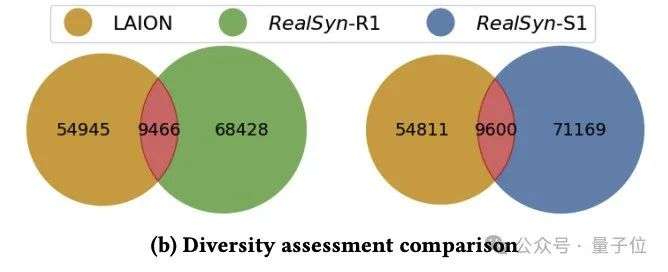
如图所示,检索到的真实文本和图像语义增强的合成文本均展示了更高数量的不同实体。
这种多样性丰富了数据集,有助于模型获得全面的知识,并提升了性能和鲁棒性。
- 数据缩放分析:

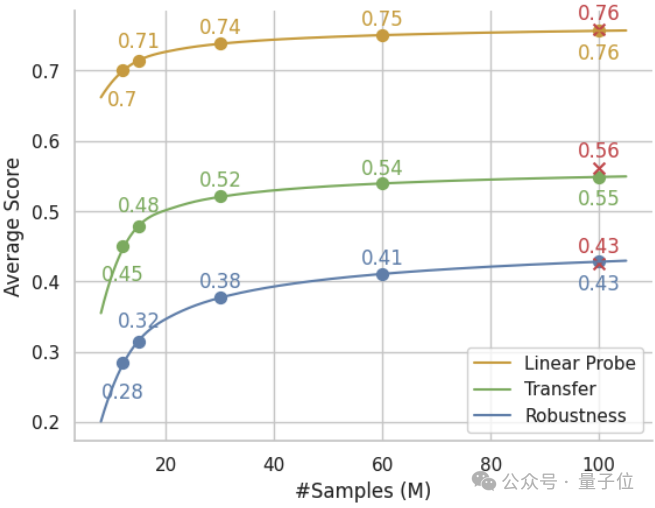
值得注意的是,如方程中所示的系数所指示的那样,
这些性能规律也可能表明通过团队提出的视觉-语言预训练范式以及多模态交错文档,ViT-B/32可能达到的模型能力的上限:
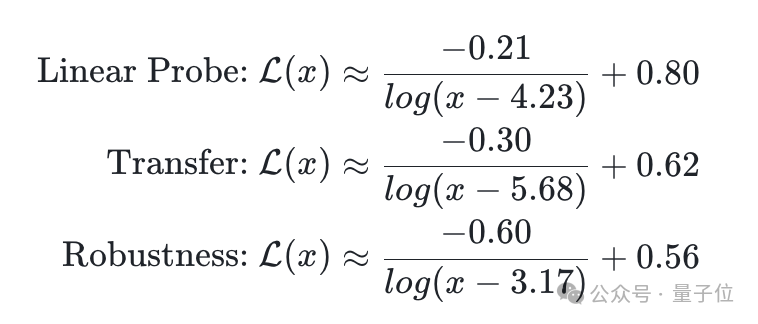
- 模型缩放分析:
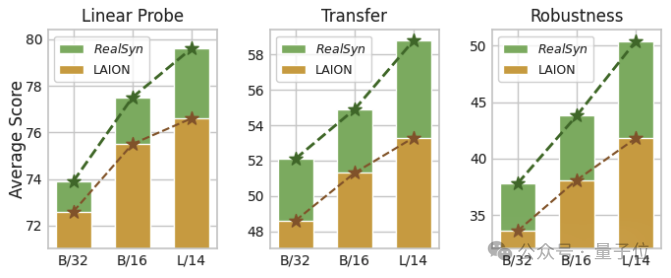
为了进一步探索模型扩展能力,研究人员在图中展示了三种模型的下游任务性能。
值得注意的是,与LAION相比,RealSyn在线性探测、零样本迁移和鲁棒性的性能曲线上显示出更陡峭的斜率,这表明其具有更优越的模型扩展能力。
消融实验
- 语义平衡采样的消融研究:
为了展示所提出的语义平衡采样方法的有效性,团队将其与随机采样进行比较。
如表所示,概念平衡采样在线性探测、零样本迁移和鲁棒性中分别提高了0.7%、1.1% 和1.0%的性能。

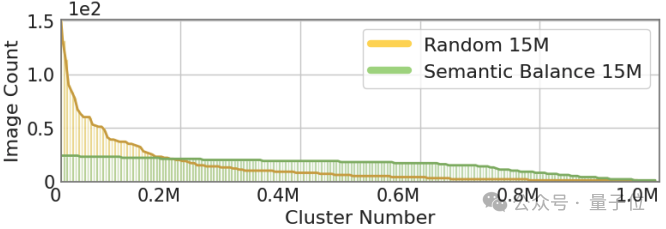
此外,团队通过将1500万样本聚类到100万个中心,使用不同的采样方法可视化数据分布。如图所示,来自语义平衡采样的分布更为平滑,有助于学习长尾概念。
- 扩展到纯图像:
研究人员发现本文所提出数据构建范式除了应用到图文交错文档以外还可以直接用于纯图像,为此他们在ImageNet上进行实验。
首先从本文构建的句子数据库中为每个ImageNet图像检索语义相关的真实文本,并生成图像语义增强的合成文本。
然后,随机从检索到的真实文本和合成文本中选择一个文本作为监督信号来对ResNet50进行预训练。

与SimCLR在相同条件下进行比较分析显示,使用团队构建的数据,在12个数据集上的线性探测平均性能提高了2.1%。
- 真实文本和合成文本消融实验:
团队进行了消融实验来评估真实文本和合成文本数量变化对CLIP-B/32模型性能的影响。
如表所示,真实文本量从一增加到三,模型性能得到提升,这归功于集成了广泛的现实世界知识的文本增强。
然而,将这一数量从三增加到五时,由于信息饱和和噪声引入,性能略有下降。相反,合成文本的数量从一增加到五,性能逐渐下降,反映了噪声引入的增加。
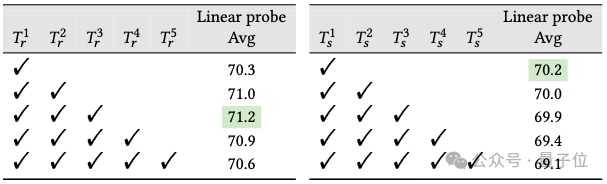
值得注意的是,仅使用真实文本进行训练可以显著提升性能,
与使用LAION15M数据集的69.8%相比,达到了71.2%的准确率,突显了现实世界知识在推进视觉-语言表征学习中的重要作用。
论文链接:https://arxiv.org/pdf/2502.12513
代码链接:https://github.com/deepglint/RealSyn
项目链接:https://garygutc.github.io/RealSyn/
数据集链接:https://huggingface.co/datasets/Kaichengalex/RealSyn100M
文章来自于微信公众号 “量子位”,作者 :RealSyn团队

【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

