该研究对 LLM 常见的失败模式贪婪性、频率偏差和知 - 行差距,进行了深入研究。
大语言模型(LLMs)的成功激发了人们对各种智能体的兴趣。将 LLM 用于智能体的一个关键假设是,LLMs 利用常识和思维链(Chain-of-Thought, CoT)进行推理,从而智能体可以有效地探索并高效地解决复杂领域的问题。
然而,LLM 智能体存在次优探索和知 - 行差距(knowing-doing gap)的问题,即无法有效地将模型中的知识转化为行动。
本文,来自谷歌 DeepMind 的研究者系统地研究了为什么 LLM 在决策场景中表现次优的原因。特别是,本文深入研究了三种常见的失败模式:贪婪性、频率偏差和知 - 行差距。
在此基础上,本文提出通过强化学习对自动生成的 CoT 推理过程进行微调,以缓解这些不足。实验表明 RL 微调能有效提升 LLMs 的决策能力 —— 既增强了智能体探索性行为,又缩小了知 - 行差距。

本文系统性地分析了中小规模 LLMs 存在的三种典型缺陷:贪婪性策略、频率偏差以及知行差距。分析表明,由于 LLMs 过早陷入贪婪动作选择策略,导致动作覆盖率停滞(最高达 55% 未探索),最终性能持续低于最优水平。
具体而言,本文发现小规模 LLMs(2B)倾向于机械复制上下文中的高频动作(无视其奖励差异),这种现象被定义为频率偏差。
相比之下,大规模 LLMs(27B)虽能显著减弱频率偏差,但依旧维持贪婪行为。
同样值得注意的是,本文通过量化知 - 行差距发现:LLMs 虽能正确理解任务要求,却因执着于贪婪动作而无法有效执行所知方案。
为克服这些缺陷,本文提出在自动生成思维链(CoT)推理的基础上进行强化学习微调方法(RLFT)。
RLFT 方法依赖于从环境交互中获得的奖励,对自生成的 CoT 原理进行微调。在 RLFT 过程中,模型会学习迭代地优化其推理过程,从而倾向于选择能够带来更高奖励的 CoT 模式和动作(参见图 1)。本文方法更专注于决策场景。
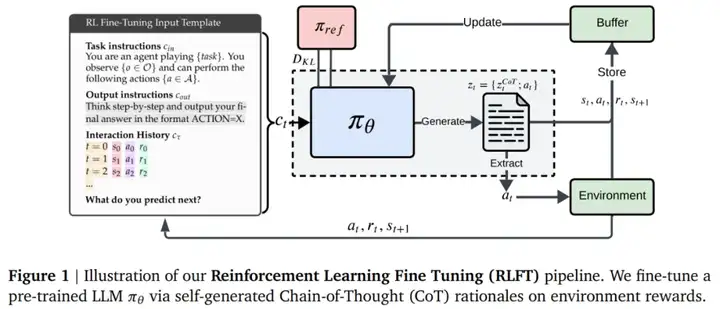

比较模型:实验比较了 Gemma2 模型的三种尺寸大小:2B、9B 和 27B 。
环境:多臂老虎机(MAB,Multi-Armed Bandit)以及井字棋游戏。

先前的研究发现,LLM 智能体在交互环境中表现欠佳,且探索不足。因此,本文首先研究模型表现欠佳的原因,并确定了三种常见的故障模式:(1) 贪婪,(2) 频率偏差,以及 (3) 知 - 行差距。发现三种故障模式在各个模型尺寸上均持续存在。
贪婪是第一个也是最普遍的故障模式,其特征是 LLM 过度偏向于迄今为止看到的一小部分操作中表现最佳的操作。为了说明这种故障模式,本文展示了 Gemma2 2B/9B/27B 在启用和禁用 CoT 的情况下,在 64 个 MAB(包含 10 个和 20 个分支)上,并且在 50 个交互步骤中实现的平均操作覆盖率(见图 3 a 和 b)。
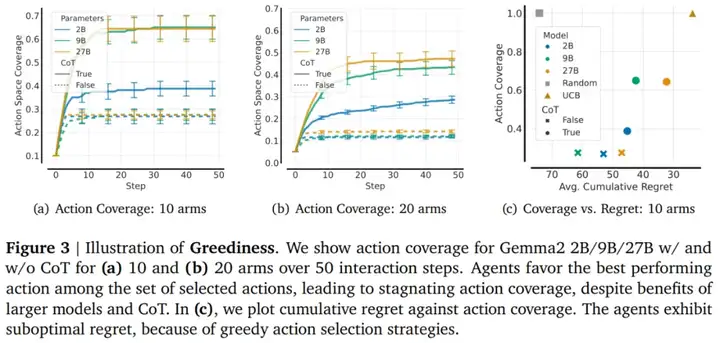
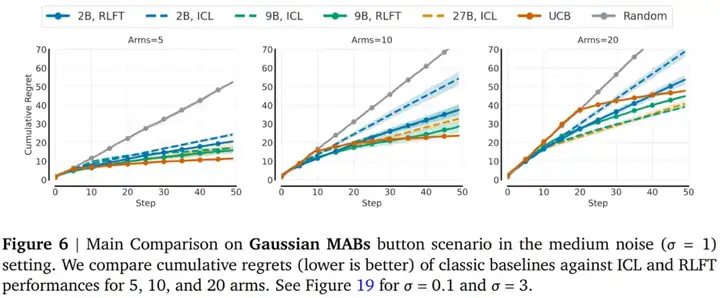
结果显示模型过早地采用贪婪策略,导致动作覆盖率在 10 步之后停滞不前。增加分支数量会使贪婪更加明显,最大的模型仅覆盖了所有动作的 45%。因此,尽管这些模型比随机智能体有显著改进(参见图 3c),但与 UCB ( Upper-confidence Bound )相比,遗憾值仍然很高。
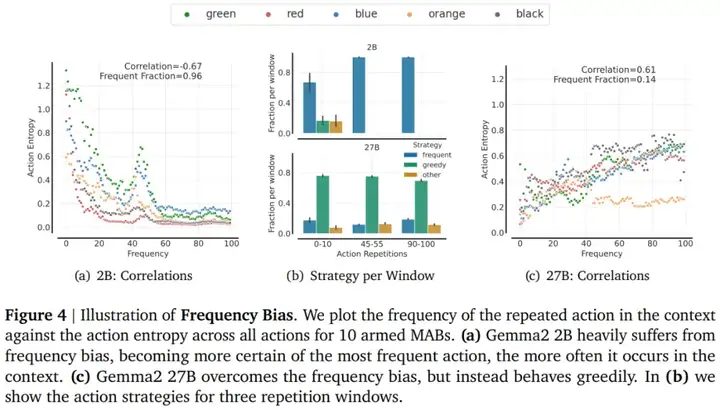
本文探索的下一个常见故障模式是频率偏差,其特点是模型重复选择上下文中出现频率最高的动作,即使该动作的奖励很低。
结果显示,Gemma2 2B 严重受到重复动作的影响,随着重复次数的增加,熵值不断降低(见图 4a)。相反,27B 模型摆脱了频率偏差(见图 4c)。事实上,对于 2B 来说,频率偏差随着重复次数的增加而不断增加。虽然 27B 摆脱了频率偏差,但它严重受到贪婪的影响。
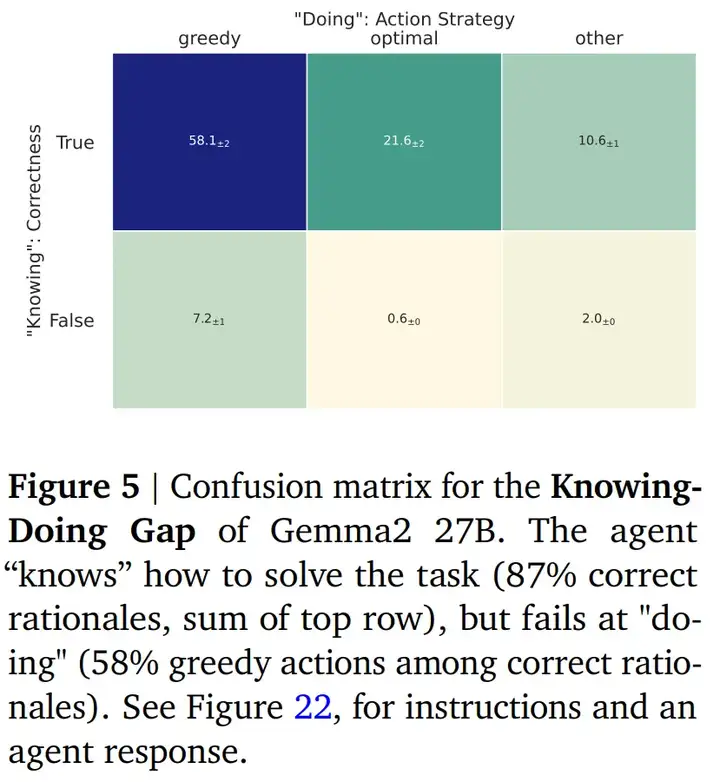
知 - 行差距。智能体清楚地知道如何解决任务,所有推理中有 87% 是正确的(见图 5)。然而,即使对于正确计算的推理,模型也经常会选择贪婪动作(58%)而不是最优动作(21%)。这种差异凸显了 LLM 在了解算法的情况下采取行动不一的缺陷。
接下来,本文研究 RLFT 对累积遗憾的影响(相对于最优策略),以及它是否能缓解这些故障模式。
结果显示 RLFT 降低了遗憾值。在各种环境中,LLM 的表现明显优于随机基线,并且 RLFT 降低了 2B 和 9B 的遗憾值。
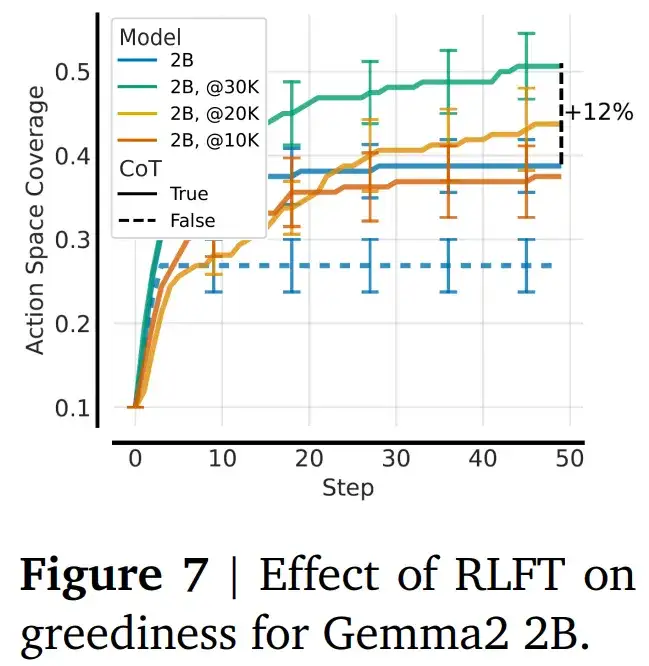
此外,RLFT 可缓解贪婪性,通过 RLFT,智能体学会了探索,从而缓解了贪婪性。
文章来自于“机器之心”,作者“陈萍”。

【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner


