你信任的AI排行榜,可能只是一场精心策划的骗局!震惊业界的Cohere Labs最新研究彻底撕破了Chatbot Arena这一所谓"黄金标准"的华丽面纱,揭露了科技巨头们如何肆无忌惮地操控评估系统、掠夺社区资源、扼杀开源创新。数据显示,谷歌和OpenAI仅凭两家就攫取了近40%的测试数据,而全部83个开放权重模型却只能分享不到30%的残羹。作为Agent开发者,你很可能正在根据这些被操纵的数字做出错误决策!这不只是学术不端,更像是科技巨头系统性的数据殖民。请继续阅读,了解LLM评估“潜规则”,看清这个游戏的真相,找回你作为开发者的独立判断力!

排行榜权力游戏
人工智能模型的质量评估不再只是技术问题,而已演变为一场赤裸裸的权力游戏。来自Cohere Labs、普林斯顿大学、斯坦福大学、MIT等大学的研究者对当前最受欢迎的AI模型评估平台Chatbot Arena进行了系统性审查,揭露了一系列令人震惊的结构性问题和精心掩盖的操纵手段。作为正在开发AI产品的工程师,你必须清醒认识到这些隐藏的评估机制如何扭曲了我们对AI模型真实能力的认知。所谓的"公开透明"排行榜已然沦为影响投资决策、引导研究方向和塑造公众认知的强大杠杆,而这一杠杆正被少数科技巨头牢牢把控。

什么是Chatbot Arena:AI模型的"格斗场"
首先,我们得了解Chatbot Arena。这是由LMSYS组织(一个由加州大学伯克利、斯坦福、加州大学圣地亚哥等多所大学合作创建的非营利机构)于2023年推出的大型语言模型评估平台。最近,Chatbot Arena 已成为比较生成式 AI 模型的事实标准,对媒体、AI 行业和学术界产生巨大影响,它允许任何人提交题目,然后对来自不同模型的两个匿名答案进行排名,从而对大语言模型 (LLM) 进行评级。截至2025年,Chatbot Arena(https://lmarena.ai/?leaderboard)已吸引数百万参与者,收集了近300万次投票,成为业界和媒体评判AI模型能力的主要参考标准。以下截图是该论文发表后lmarena.ai回应后的结果,数据可能和论文里披露的并不一致。
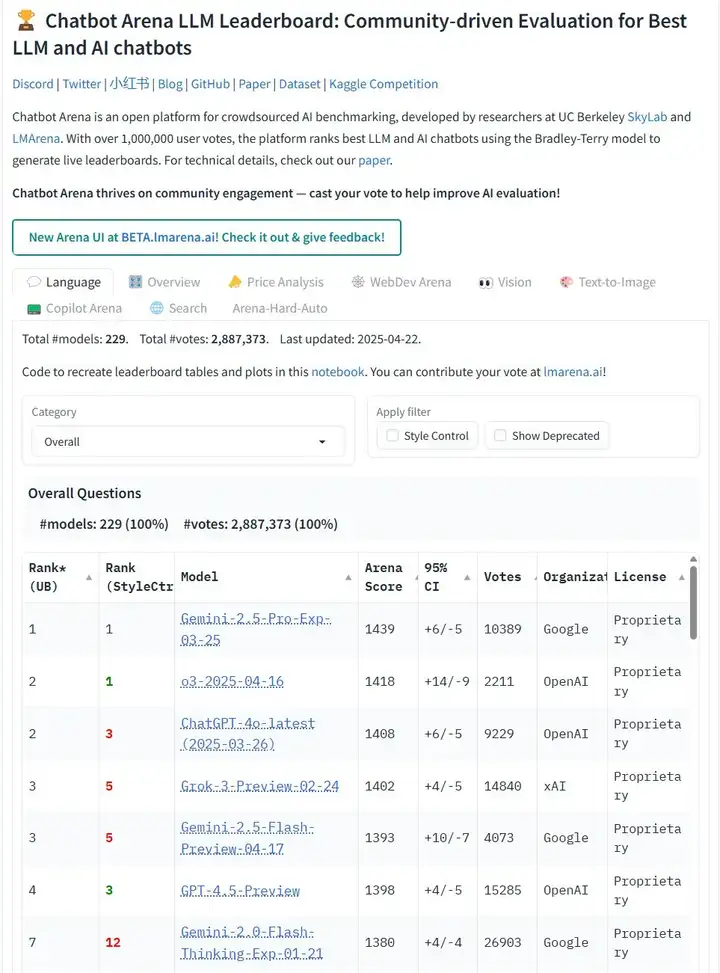
运作机制:用户主导的盲测评价
Chatbot Arena的评估过程类似于盲测:用户提交一个问题,系统随机选择两个匿名模型进行回答,用户根据回答质量选择更好的一方或平局。这种匿名对战机制旨在减少品牌偏见,确保评价基于实际表现而非名气。平台使用Bradley-Terry概率模型计算模型的相对能力分数,这种算法原本用于体育比赛和游戏排名,能够根据对战结果推断模型间的相对强弱关系。
影响力:为何Chatbot Arena如此重要
Chatbot Arena在AI评估领域迅速崛起有其独特原因:它能评估模型在开放式、真实世界任务中的表现,而非仅限于预设的多选题测试。随着大语言模型能力的迅速提升,传统学术评估方法(如MMLU、HumanEval等)已难以全面反映这些模型在实际场景中的能力差异。Chatbot Arena的人类反馈机制和持续更新的问题库使其成为追踪最新模型进展的动态窗口,这也是为何它对投资决策、研究方向和公众认知有如此重大的影响力。
研究背景:华丽外表下的系统性腐败
理论上,Chatbot Arena这种开放式评估框架应该是公平竞争的典范,随着模型能力的提升而不断进化,避免静态评估集容易过拟合的问题。然而,真相令人震惊:研究者分析了覆盖42家提供商、243个模型、超过200万次对战的数据后,发现了一个被精心设计的不公平游戏场。数据获取严重不对称、评分选择性报告和模型弃用策略暗箱操作等系统性缺陷不仅彻底扭曲了排行榜的可信度,更使得开源和开放权重模型处于一场从根本上就不公平的比赛中。所谓的"科学评估"实际上成了少数巨头的技术营销工具。
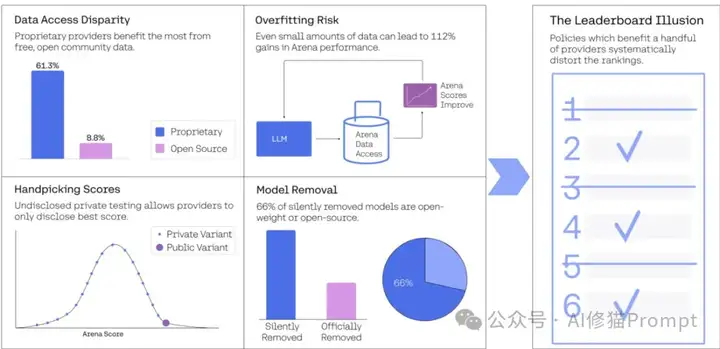
私人测试与选择性报告:明目张胆的排名操纵
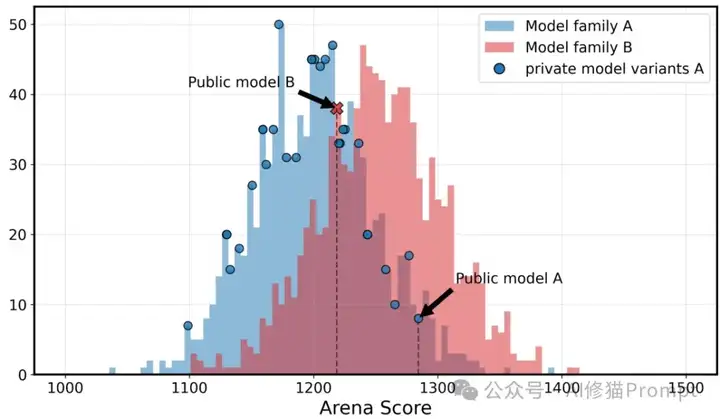
研究揭露了Chatbot Arena不为人知的黑幕:存在一个未向公众和大多数参与者公开的特权政策,允许特定提供商(主要是Meta、Google、OpenAI和Amazon)同时测试多个私有模型变体,然后只公开表现最佳的那个,完全抹去其他尝试的痕迹。这种"挑选最佳"策略公然违反了Bradley-Terry评分模型的最基本假设,系统性地膨胀了科技巨头的模型评分。最荒谬的是,研究者发现Meta在Llama-4发布前夕同时测试了多达27个私有变体,相当于多进行了27次"摇骰子"机会,而绝大多数开源提供商甚至不知道这样的特权存在。
这种选择性报告机制造成的不公平是实实在在的数学优势。研究证明,仅测试10个变体就能使最高分提升约100分——这相当于整个排行榜前十名之间的分数差距。更具讽刺意味的是,研究者在实际Arena平台上的实验表明,即使是完全相同的模型,由于统计波动,也能获得显著不同的分数(1052分对1069分)。如此巨大的随机波动中,谁能测试更多变体,谁就能在这场"概率游戏"中占尽优势。
数据掠夺:社区反馈的不平等瓜分
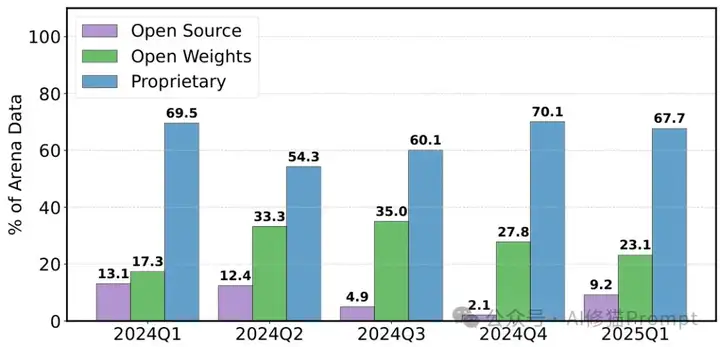
Chatbot Arena作为一个由社区无偿贡献数百万评测数据的平台,理应让所有参与者平等受益,然而现实是赤裸裸的数据掠夺。研究者揭示了触目惊心的不平等:谷歌和OpenAI这两家巨头凭借特权地位分别攫取了约19.2%和20.4%的所有测试数据,而83个开放权重模型(占模型总数的三分之一)加起来仅获得了29.7%的数据,41个完全开源模型更是只能分享8.8%的数据残羹。这一不平等如此极端,简直可以称为数据殖民。
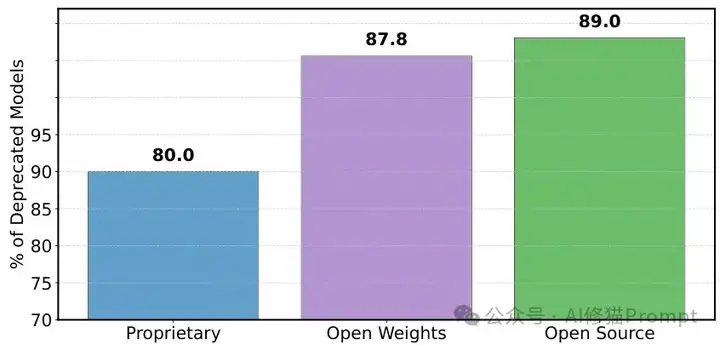
这种掠夺式不平等源于三个系统性机制:科技巨头可以部署大量私有变体(相当于在同一块蛋糕上插更多叉子)、其模型获得高得离谱的采样率(某些巨头模型每日采样率高达34%,而非特权提供商仅为3.3%),以及针对开源模型的歧视性弃用政策。最令人愤慨的是,在243个公开模型中,多达205个被"静默弃用"(减少采样率至接近零)而没有任何通知,这种操作对开源和开放权重模型的打击尤为沉重。
数据优势的实际影响:游戏规则的根本颠覆
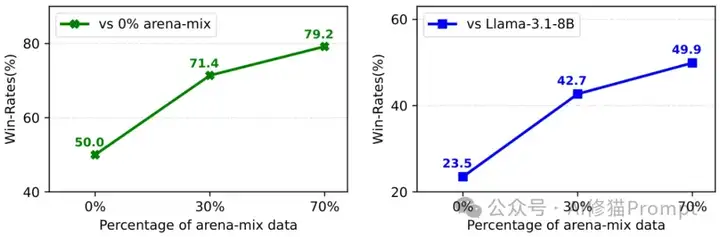
这种数据获取差异究竟产生了多大影响?研究通过铁证如山的实验彻底打破了"这只是小问题"的幻想。在严格控制的条件下,仅仅通过增加Arena数据在训练集中的比例(0%→30%→70%),模型在ArenaHard测试集上的胜率就从23.5%飙升至49.9%,相对提升高达112%。而这只是使用研究者有限数据集的结果——想象一下掌握了数十倍此数量数据的科技巨头究竟获得了何等巨大的不公平优势!
最具讽刺意味的是,这种耗费巨资获得的"提升"仅限于Arena测试分布,对更通用的MMLU基准测试几乎毫无影响,这一发现直接揭穿了"排行榜提升等同于真实能力提升"的巨大谎言。更令人不安的是,Arena的提示分布在不断变化,非英语提示的比例从2023年4月的23.9%暴增至2025年1月的43.5%,结合高达26.5%的提示重复率,进一步扩大了数据不对称的致命影响,使得"后来者"几乎不可能赶上握有历史数据优势的先行者。
模型弃用的黑箱操作:排名可靠性的彻底崩塌
排行榜分数的可靠性还面临着另一个致命威胁:不透明且具歧视性的模型弃用政策。研究揭示,在不断变化的任务分布下,模型"被消失"的现象严重违反了Bradley-Terry模型最基本的数学前提:评估条件保持不变和比较网络完全互连。
当任务分布随时间变化(如非英语提示比例激增),已弃用模型无法在新条件下重新评估,使其历史比较结果完全失真。同时,大规模的不平等弃用切断了比较图的连接性,彻底摧毁了BT模型的有效性基础。研究通过严密的模拟实验无情地展示了这一机制如何使排名完全不可靠:在任务分布变化的情况下,模型弃用可以完全颠覆最终排名顺序;而在比较图稀疏的情况下,排名与真实技能水平之间的关系几乎成了随机噪声。这意味着整个排行榜的科学基础已经彻底崩塌。
拯救公信力:重建公平透明的评估框架
面对这一系列系统性操纵,研究者提出了五项刻不容缓的措施,拯救Chatbot Arena的科学完整性和公信力:
- 禁止提交后撤回分数:所有模型评估结果(包括私有变体)必须在提交后永久公开,彻底杜绝现有的"多次尝试、只公布最好结果"的不公平优势。这不是可选项,而是恢复排行榜最基本信任的必要条件。
- 严格限制每个提供商的私有模型数量:私有测试必须设置透明且严格的上限(如每家提供商最多同时测试3个变体),杜绝任何提供商(无论规模大小)通过海量变体测试来操纵统计结果的可能性。
- 执行公平的模型移除政策:彻底改革当前对开源模型极度不公的弃用政策,对专有、开放权重和开源模型采用完全相同的弃用标准,如统一对各组的底部30%模型进行弃用,不再允许任何形式的特殊对待。
- 实施真正公平的采样机制:立即纠正目前被严重扭曲的采样体系,确保每个模型(无论背后是科技巨头还是学术机构)都获得公平的展示机会,消除当前高达10倍的采样率差异。
- 全面公开模型移除信息:对所有205个被"静默弃用"的模型予以公开说明,并建立透明的模型状态报告机制,确保任何模型的状态变化都有明确记录和合理解释。
谁在掌控AI进步的评判权?
本研究揭露的真相对每一位AI产品开发者都具有警醒意义:你所依赖的排行榜可能是一场精心设计的幻象,一个被少数几家科技巨头暗中控制的"公平竞争"假象。这不仅关乎技术评估的客观性,更是关乎谁能定义AI的未来发展方向、谁能获得投资和关注、最终谁能在这场技术革命中站稳脚跟的根本问题。
作为开发者,我们必须认清这些系统性偏见背后的权力结构。Chatbot Arena的问题绝非简单的技术缺陷,而是反映了AI领域日益扩大的不平等鸿沟。在追求更强大的AI技术的同时,我们必须同等重视评估体系本身的公正性、透明度和科学完整性,否则我们都只是在一个被精心操控的游戏中盲目追逐幻影。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。

【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

