照这个发展速度,不远的将来AI不仅能模仿你的行为,还能理解你为何做出这些选择。PB&J框架正是这一突破性技术的代表,它通过引入心理学中的"支架"概念,使AI能够构建合理化解释,深入理解人类决策背后的动机。本文将带您探索这一创新框架如何在有限数据条件下显著提升AI角色扮演能力,揭示原始世界信念支架的卓越表现,以及如何将其应用于实际场景。

当前AI角色扮演的局限性
大型语言模型(LLM)在模拟用户角色方面取得了显著进展,但仍面临诸多挑战。当前的方法主要依赖用户的人口统计学特征(如年龄、性别、教育程度等)或先前判断(已知的用户回答),却往往忽略了用户判断背后的内在心理逻辑和思考过程。
这种方法导致的结果是AI模拟的用户角色经常表现出表面化的特征,无法捕捉真实用户行为背后的深层次动机和逻辑,从而在需要深入理解人类决策过程的场景中表现不佳。
心理支架的基本概念
在深入探讨PB&J框架之前,我们需要先理解"心理支架"这一核心概念。
在心理学中,"心理支架"(psychological scaffolds) 是一个比喻性的说法,意思是:在学习、成长或面对挑战的时候,给人一种临时的心理支持或引导,帮助他们更好地应对或发展。
我们可以把它想象成盖楼时搭的脚手架。脚手架不是永久的,但在盖楼时特别重要,它帮你爬得更高、稳得住,等楼盖好了,脚手架就可以撤掉。
通俗举例说明:
- 孩子学走路时,父母牵着手:孩子一开始不会走,父母牵着手,就是一种"心理支架",既让孩子不怕跌倒,又鼓励他尝试。等他走稳了,支架就不需要了。
- 学生学新知识时,老师提供提示或结构:比如解数学题时,老师先一步步引导学生怎么分析题目、列公式。这个过程中的"引导"就是一种心理支架。等学生掌握了方法,就能独立解题了。
- 情绪支持时的心理支架:当一个人失落、焦虑或者面对难题时,亲朋好友的安慰、鼓励或共情,可以暂时稳住他的情绪,让他慢慢恢复。这种支持也可以看作心理支架。
总结:心理支架就是在你还没完全独立应对问题时,别人(或环境)提供的临时帮助,帮你慢慢过渡到可以自己处理。
在AI领域,特别是在角色扮演和个性化服务中,心理支架概念被创新性地应用,为模型提供了理解人类心理和行为的结构化框架。
PB&J框架:心理合理化的突破
南加州大学和苹果公司的研究者们提出了一个名为PB&J(Psychology of Behavior and Judgments,行为与判断心理学)的创新框架,旨在通过添加合理化解释来增强LLM角色扮演能力。
这个框架的核心是为用户的判断提供后验合理化解释,解释用户为什么会做出特定判断,这些解释基于用户的经历、性格特质或信念系统等心理因素。通过这种方式,PB&J框架不仅能利用用户的表面特征,还能揭示这些特征背后的心理动机,从而创建更加立体、更具深度的AI角色。
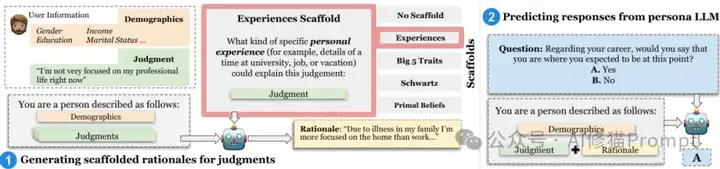
PB&J框架概览
心理支架:合理化的结构化工具
研究者引入了"心理支架"(psychological scaffolds)的概念,这是一种基于心理学理论的结构化框架,用于指导LLM生成关于用户判断的合理化解释。
论文中探索了几种不同类型的心理支架:
- 无支架:自由形式的合理化
- 经验支架:基于生活经历的解释
- 大五人格特质支架:开放性、尽责性、外向性、宜人性和神经质
- 施瓦茨基本人类价值理论支架:权力、成就、享乐主义等
- 原始世界信念支架:安全世界、诱人世界和活力世界信念
这些不同类型的支架为AI提供了多角度理解人类行为的能力,使其能够从心理学视角解释用户行为。

心理支架总结
原始世界信念:表现最佳的心理支架
在所有测试的心理支架中,原始世界信念(Primal World Beliefs) 表现最为出色。
原始世界信念是关于人们对世界的基本假设,例如:
- 世界是否安全(Safe)
- 是否充满吸引力(Enticing)
- 是否充满生机(Alive)
这些基本信念深刻影响着人们的行为和决策过程,通过引导AI从这一角度解释用户行为,能够创建更接近真实人类思维的角色扮演。
研究表明,与其他支架相比,原始世界信念支架在跨任务和跨模型上表现最为稳定且效果最好。
技术实现:如何构建PB&J增强的LLM角色
PB&J框架的技术实现包括三个关键步骤:
- 基础角色设置:包含用户的人口统计学特征和一系列种子判断(用户对特定问题的已知回答)
- 为种子判断生成后验合理化:对每个种子判断,系统使用特定的心理支架指令引导LLM生成合理化解释
- 从增强的角色中生成回应:将这些增强的角色描述作为系统提示,指导LLM生成与用户行为一致的预测回应
这种技术实现方式不需要对底层LLM进行微调,而是通过巧妙的提示工程来实现角色扮演能力的提升。

提示和回答示例
利用有限判断最大化性能
实验结果显示,PB&J框架在有限的用户历史数据条件下表现尤为出色。随着种子判断数量的增加,各方法的性能都有所提升,但PB&J能够在更少的判断数量下达到更高的准确率。
这对于开发人工智能代理产品的工程师尤为重要,因为在实际应用中,获取大量用户历史数据往往困难且成本高昂。通过PB&J框架,即使只有两个用户判断,也能显著超越仅使用人口统计学或仅使用判断的基线方法,这大大提高了在数据有限情况下的应用可能性。
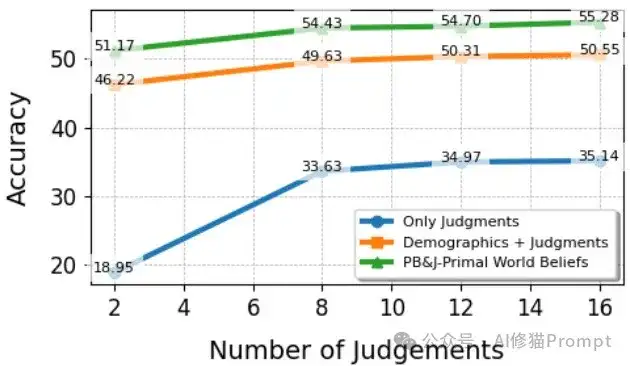
判断数量对性能的影响
跨人群一致性提升
PB&J框架在不同人口统计学群体中都表现出一致的改进,这表明其适用性广泛且不依赖特定人群特征。
研究者对教育程度、种族、收入和性别等不同人口统计学变量进行了分析,发现PB&J在所有这些群体中都能提供显著改进。这种跨人群的一致性表明,通过结构化的心理合理化,AI能够适应多样化的用户视角,而不仅仅是针对特定人群进行优化。
这对于开发需要服务于广泛用户群体的AI代理尤为重要。
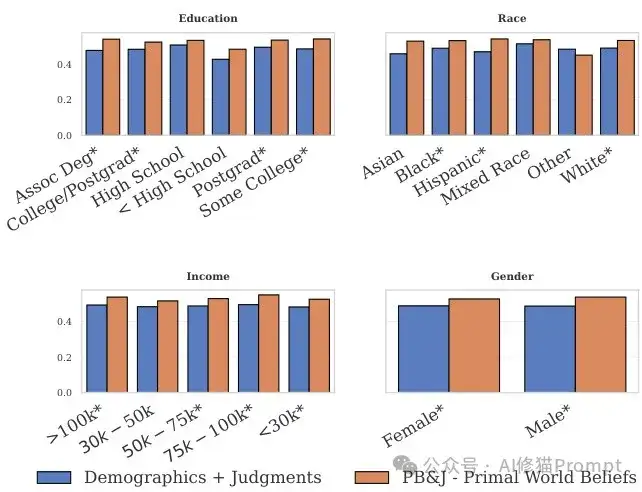
不同人口统计学群体的性能改进
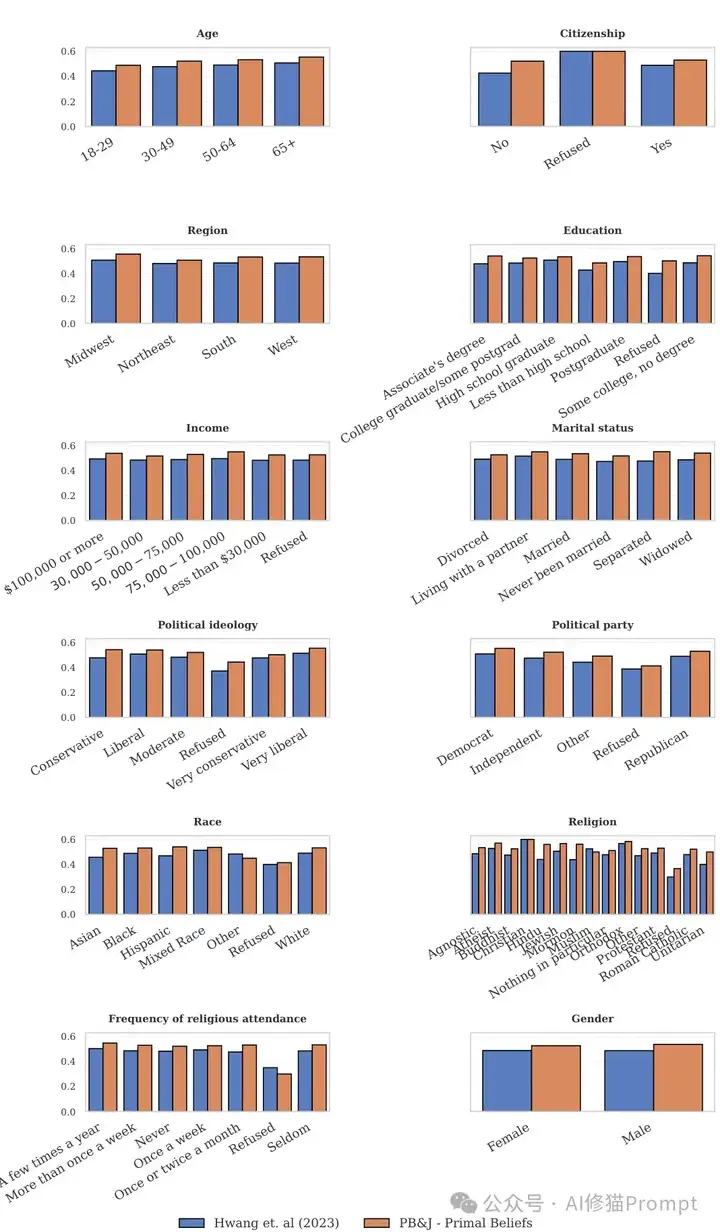
跨所有人口统计学群体的详细性能改进
实验验证:公众意见与电影偏好预测
研究者在两个不同类型的任务上评估了PB&J框架:
- OpinionQA(公众意见预测):PB&J框架比最佳基线方法提高了9.7%-10.8%的准确率
- MovieLens(电影偏好预测):PB&J同样表现出色,特别是使用原始世界信念和施瓦茨价值理论支架时
这两个实验覆盖了不同类型的个性化任务,证明了PB&J框架在多样化场景中的适应性和有效性。
对于开发个性化AI代理的工程师来说,这意味着可以在不同应用场景中应用相同的框架,获得一致的性能提升。
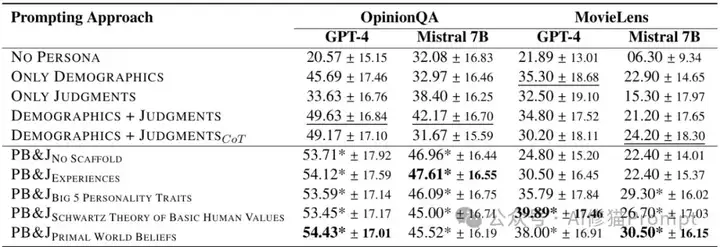
实验结果表
人类撰写的合理化与LLM生成的合理化
一个关键问题是LLM生成的合理化解释与人类撰写的合理化相比如何。
研究者进行了一项试点研究,收集人类撰写的合理化解释并与LLM生成的解释进行比较。结果表明:
- 人类撰写的合理化确实表现最佳
- 使用原始世界信念支架的LLM生成合理化与人类撰写的合理化相差无几,这种差异在统计上并不显著
这一发现突显了精心设计的心理支架能够使LLM生成的合理化接近人类质量,为实际应用提供了可行的替代方案。
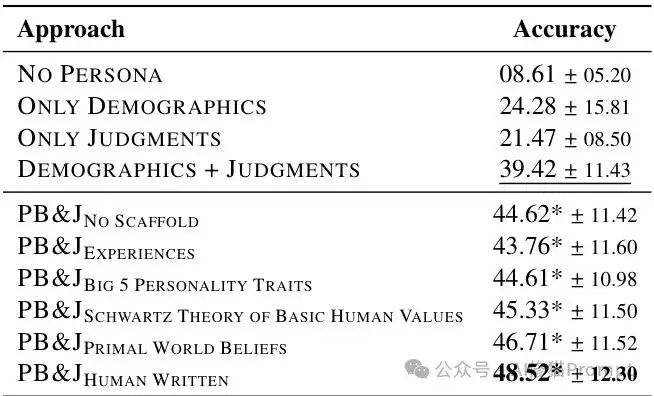
人类撰写的合理化与LLM生成的合理化比较
无需人口统计学的改进
在某些情况下,用户的人口统计学信息可能不可用,或者使用这些信息可能引起偏见问题。
研究表明,即使不使用人口统计学信息,PB&J框架仍能显著改善角色扮演性能:
- 仅对判断进行原始世界信念合理化,在OpinionQA上可获得11.64%的绝对改进
- 在MovieLens上获得1.1%的改进
这一结果表明,深入思考用户行为本身可能会减少对粗略且可能带来偏见的人口统计学信息的需求,为构建更公平、更私密的AI代理提供了新的可能性。
技术实现细节与开发者指南
作为开发AI代理产品的工程师,你需要了解PB&J框架的具体实现细节。实现PB&J框架需要两个主要步骤:
1. 生成合理化解释
使用如GPT-4或Mistral 7B等现成的大型语言模型,通过提供用户的人口统计学信息、判断以及特定的心理支架指令来生成合理化解释。以下示例中我使用的是腾讯混元大模型hunyuan-t1-latest。
2. 基于增强角色生成预测
同样使用LLM,但输入包含增强的角色描述(包含合理化解释)和目标问题。
研究者提供了详细的提示模板,可以直接应用于实际开发中。
实践案例:基于PB&J框架的职业决策支持
为了展示PB&J框架的实际应用,我实现了一个生涯决策支持Agent,帮助一位35岁的男性软件工程师从软件开发转向人工智能产品管理的职业转变决策。这个案例完美展示了如何在冷启动场景(有限用户数据)中,通过心理支架生成深度合理化解释,从而提供高度个性化的决策支持。
案例背景与用户信息
该用户具有以下人口统计学特征:

我们收集了用户对三个关键问题的判断(种子判断):
1. "你更喜欢团队合作还是独立工作?"
- "我更偏向于独立工作,虽然我也能在团队中表现良好"
2. "你是否愿意冒险尝试一个全新的职业方向?"
- "我持开放态度,但需要确保这个方向有长期发展潜力"
3. "工作与生活平衡对你有多重要?"
- "非常重要,我不希望工作完全占据我的生活"
代码实现示例
以下是基于PB&J框架的职业决策支持Agent实现的核心代码,全部代码近700行。我将分享在我的赞赏群里,需要的话后台私信“加赞赏群”:

if __name__ == "__main__":
try:
# 初始化代理
agent = CareerDecisionAgent(
api_key="sk-", # 混元 APIKey
base_url="https://api.hunyuan.cloud.tencent.com/v1", # 混元 endpoint
verbose=True,
max_retries=3,
retry_delay=5,
default_timeout=120
)
# 用户人口统计学信息
demographics = {
"age": "35",
"gender": "男",
"education": "硕士学位,计算机科学",
"work_experience": "8年IT行业经验,主要担任软件开发工程师",
"current_position": "高级开发工程师",
"location": "北京",
"family_status": "已婚,无子女"
}
# 用户种子判断
judgments = [
{
"question": "你更喜欢团队合作还是独立工作?",
"answer": "我更偏向于独立工作,虽然我也能在团队中表现良好"
},
{
"question": "你是否愿意冒险尝试一个全新的职业方向?",
"answer": "我持开放态度,但需要确保这个方向有长期发展潜力"
},
{
"question": "工作与生活平衡对你有多重要?",
"answer": "非常重要,我不希望工作完全占据我的生活"
}
]
# 生涯决策问题
career_question = """
我目前正考虑从软件开发转向人工智能产品管理。这将需要我放弃部分技术深度,
转而发展更多的业务和管理技能。这个转变可能意味着短期内收入下降和工作时间增加,
但长期可能有更大的发展空间。考虑到我的背景和价值观,你认为这是一个明智的职业转变吗?
我应该如何规划这个转变以最大化成功的可能性?
"""
# 执行完整流程
result = agent.process_full_career_support(demographics, judgments, career_question)
# 保存结果到文件
agent.save_results_to_file("career_decision_results.json")
PB&J框架实现过程
应用PB&J框架的过程包括以下几个关键步骤:
1. 收集用户人口统计学特征和种子判断:这些基础信息构成了用户角色的基本轮廓。
2. 生成合理化解释:对每个种子判断,我们使用经验支架(EXPERIENCES)生成深度合理化解释,揭示用户判断背后的心理动机和逻辑。例如,对于"独立工作"的偏好,系统生成了详细的解释,包括用户的学术训练形成的独立性、技术专家路径的职业发展选择、效率导向的工作方式等多个维度。
3. 构建增强用户角色:将人口统计学特征和带有合理化解释的判断整合,形成一个立体、深度的用户心理模型。
4. 基于增强角色生成决策支持:针对用户提出的具体职业转变问题,系统基于增强后的用户角色生成了高度个性化的决策支持建议。
实际运行结果
系统成功生成了针对用户职业决策问题的深度个性化建议。以下是关键环节的实际输出:
1. 生成的合理化解释示例(部分)
对于用户偏好独立工作的判断,系统生成了详细的合理化解释:
对于「你更偏向于独立工作,虽然我也能在团队中表现良好」这一判断,结合其背景和过往经历,合理的解释可能包含以下逻辑链条:
1. 学术与早期职业训练形成的独立性
他在计算机科学硕士阶段可能长期参与需要自主设计的课题,这类研究通常要求独立完成文献调研、实验验证和论文撰写。
这种训练强化了他独立解决问题的思维习惯。
2. 技术专家路径的职业发展选择
在8年IT从业中,他可能多次被委派负责关键模块开发或技术攻坚任务。这类工作往往需要深度专注和较少干扰的独立工作时间。
3. 效率导向的工作方式
他重视工作生活平衡的价值观与独立工作模式存在内在关联。相较于需要协调多人进度的协作模式,
他更擅长通过独立工作快速完成任务,从而减少会议沟通等时间损耗。
2. 生成的决策支持建议(部分)
系统生成了一份全面的决策支持建议,包括决策与价值观的一致性评估、行动建议、潜在挑战与应对策略以及决策评估框架:
基于你的背景与价值观的深度分析
一、决策与价值观的一致性评估
1. 技术深度与长期主义的兼容性
你的技术背景(8年开发经验+硕士理论积累)是转向AI产品管理的核心优势,但需警惕「技术深度稀释」的风险。
- 一致性验证:你过去在技术攻坚中展现的「有限独立+关键节点协作」模式,与AI产品经理所需的
「技术可行性判断+跨职能协调」能力高度契合。
- 矛盾点:产品管理需要高频次沟通,可能压缩你的独立工作时间。需通过角色定义保留技术决策主导权。
2. 风险控制与长期潜力的平衡
你要求「确保长期潜力」的决策原则在此场景中需分层验证:
- 行业潜力:AI行业复合增长率高于传统软件开发,但细分领域差异大。
- 个人潜力:你的技术背景可转化为差异化竞争力,但需验证业务敏感度是否可通过短期学习补足。
案例分析与价值展示
这个实践案例充分展示了PB&J框架在关键生涯决策支持中的独特价值:
1. 深度个性化:系统不仅考虑了用户的基本特征和明确表达的偏好,更通过合理化解释深入挖掘了用户决策背后的价值观和动机,生成的建议高度符合用户的内在需求和思维模式。
2. 冷启动能力:仅基于有限的用户数据(3个种子判断和基本人口统计学信息),系统就能构建出深度的用户心理模型,并提供高质量的决策支持。
3. 结构化输出:基于增强的用户角色,系统生成了结构清晰、多维度的决策支持,包括一致性分析、具体行动建议、潜在挑战及应对策略,以及定量与定性结合的决策评估框架。
4. 心理支架的有效性:案例中使用的经验支架(EXPERIENCES)成功引导模型生成了丰富、合理的解释,揭示了用户偏好和决策背后的复杂心理动机,从而提供了超越表面特征的深度洞察。
通过这个案例,我们可以看到PB&J框架如何在实际应用中为数据稀缺的冷启动环境提供深度个性化的决策支持,这对于开发智能代理产品的工程师具有重要的参考价值。
写在最后
PB&J框架代表了AI角色扮演领域的重要突破,通过引入心理支架指导的合理化解释,显著提升了LLM角色与真实用户行为的一致性。
对于开发AI代理产品的工程师来说,这一框架提供了一种实用且有效的方法,可以在有限的用户数据条件下创建更加真实、更具深度的AI角色。特别是原始世界信念支架的出色表现,为理解和预测用户行为提供了新的视角,帮助你的产品更好地理解和服务用户。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。

【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

