自 OpenAI 发布 Sora 以来,AI 视频生成技术进入快速爆发阶段。凭借扩散模型强大的生成能力,我们已经可以看到接近现实的视频生成效果。但在模型逼真度不断提升的同时,速度瓶颈却成为横亘在大规模应用道路上的最大障碍。
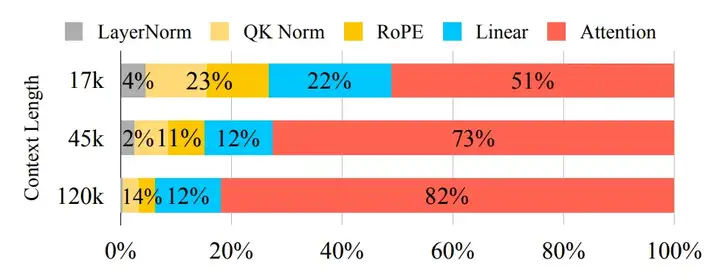
当前最好的视频生成模型 Wan 2.1、HunyuanVideo 等,在单张 H100 GPU 上生成一个 5 秒的 720p 视频往往需要耗时 30 分钟以上。主要瓶颈出现在 3D Full Attention 模块,约占总推理时间的 80% 以上。
为了解决这个问题,来自加州伯克利和 MIT 的研究者们提出了联合提出了一种新颖的解决方案:Sparse VideoGen。

- 论文标题:Sparse VideoGen: Accelerating Video Diffusion Transformers with Spatial-Temporal Sparsity
- 论文链接:https://arxiv.org/abs/2502.01776
- 代码:https://github.com/svg-project/Sparse-VideoGenn
- 网页:https://svg-project.github.io/
这是一种完全无需重新训练模型的视频生成加速方法。通过挖掘注意力机制中的空间与时间稀疏性,配合自适应稀疏选择与算子优化,成功将推理时间减半。令人惊讶的是,它生成的视频与 Dense Attention 方法相比,几乎没有肉眼可见的差别,保持极高的像素保真度 (PSNR = 29)。Sparse VideoGen 也是第一个能够达到这种级别的像素保真度的方法。
目前,Sparse VideoGen 已经支持了 Wan 2.1, HunyuanVideo, CogVideoX 等多种 SOTA 开源模型,并且 T2V(文生视频),I2V(图生视频)都可以加速。他们的所有代码均已开源。该工作已经被 ICML 2025 录取。

扩散式视频生成的性能瓶颈
扩散模型(Diffusion Models)已经成为图像与视频生成的主流方案。特别是基于 Transformer 架构的 Video Diffusion Transformers(DiTs),在建模长时空依赖与视觉细节方面具有显著优势。然而,DiTs 模型的一大特征 ——3D Full Attention—— 也带来了巨大的计算负担。每个 token 不仅要考虑当前帧的空间上下文,还要参与跨帧的时间建模。随着分辨率和帧数的提升,Attention 的计算复杂度以二次增长,远高于普通图像生成模型。
例如,HunyuanVideo 和 Wan 2.1 在 1×H100 上生成 5 秒 720p 视频需要 29 分钟,其中 Attention 计算占据超过 80% 的时间。如此高昂的代价,大大限制了扩散视频模型在真实世界中的部署能力。
Sparse VideoGen 的核心设计
抓住 Attention 中的稀疏性
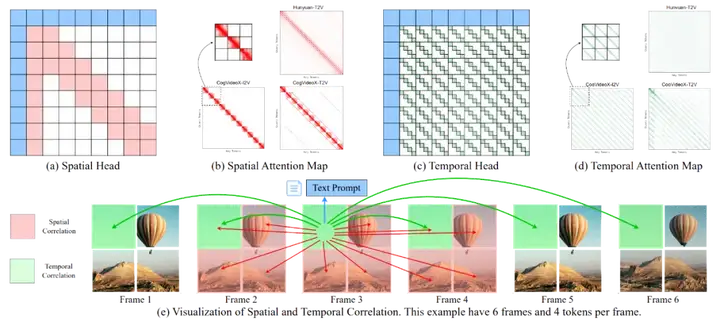
在 Video Diffusion Transformer 的 Attention Map 中存在两种独特的稀疏模式:空间稀疏性 (Spatial sparsity) 和时间稀疏性 (Temporal sparsity)。大多数 Attention Head 都可以归类为其中之一,并可以相应地定义两类 Attention Head:Spatial Head 和 Temporal Head。
Spatial Head - 关注空间邻近的 Token
Spatial Head 主要关注相同帧及相邻帧中的 Token,其 Attention Map 呈块状布局,集中于主对角线附近。它负责建模局部空间一致性,使得图像生成在帧内连贯。
Temporal Head - 关注不同帧中的相同 Token
Temporal Head 主要用于捕捉帧间的 Token 关系。其 Attention Map 呈斜线式布局,并具有恒定步长。这种机制确保了时间一致性,即同一物体在多个帧中保持连贯。
这种 Attention 模式的解构,帮助模型在计算过程中识别哪些 token 是「重要的」,哪些可以忽略,从而构建稀疏注意力策略。
实现无损像素保真度的关键
动态自适应的稀疏策略
尽管 Spatial Head 和 Temporal Head 分别解决了空间和时间一致性问题,但真正实现无损像素保真度的关键在于最优地组合它们。
在不同的去噪步骤(denoising steps)以及不同的生成提示(prompts)下,最优的稀疏策略可能会发生显著变化。因此,静态的稀疏模式无法保证最佳效果,必须采用动态、自适应的策略。
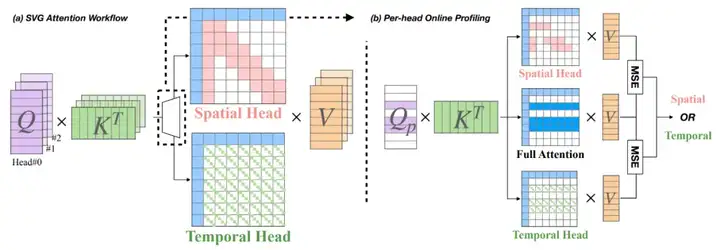
为此,Sparse VideoGen 采用了一种在线稀疏模式优化方法(Online Profiling),通过动态的决定 Attention Mask,用于动态决定每个注意力头所采用的稀疏策略。
其方法如下:
1. 每一步推理过程中,随机采样极少量(仅 0.05%,约 64 个)的 Query Token;
2. 分别使用 Spatial 和 Temporal 两种稀疏模式计算其注意力结果,并与 Dense Attention 对比误差;
3. 为每个 Attention Head 选择误差最小的稀疏模式。
仅使用 64 个 Query Token(占全部 token 总数的 0.1%),即可准确预测最优的稀疏模式。这种轻量级探索 + 局部误差拟合的策略,几乎不增加额外计算开销(<3%),但可在不同步骤下精准选取最优稀疏模式,从而最大限度保证画质(PSNR > 29)且实现有效加速。
从算子层优化稀疏计算
Layout Transformation + Kernel 加速
尽管利用稀疏性能够显著提升 Attention 速度,但如何达到最优的加速效果仍然是一大问题。尤其是 Temporal Head 的非连续内存访问模式仍然对 GPU 的性能构成挑战。
Temporal Head(时间注意力头)需要跨多个帧访问相同空间位置的 token。然而,传统的张量布局通常是以帧为主(frame-major)的顺序存储数据,即同一帧的所有 token 连续存储,而不同帧的相同位置的 token 则分散开来。
为了解决这一问题,Sparse VideoGen 引入了一种硬件友好的布局转换方法。该方法通过将张量从帧为主的布局转换为 token 为主(token-major)的布局,使得 Temporal Head 所需的 token 在内存中呈现连续排列,从而优化了内存访问模式。具体而言,这种转换通过转置操作实现,将原本分散的 token 重组为连续的内存块,符合 GPU 的内存访问特性。
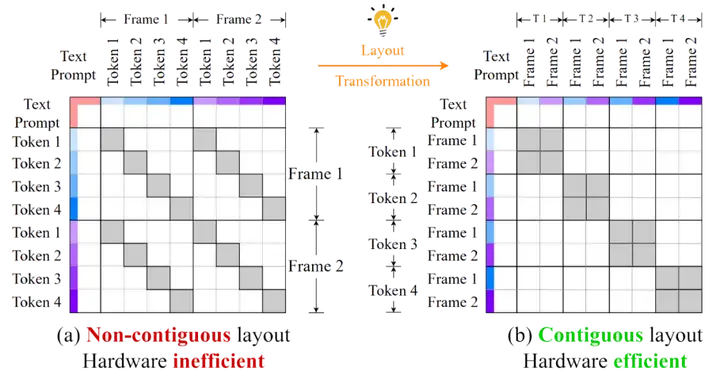
这种布局转换不仅提高了内存访问效率,还使得稀疏注意力计算能够更好地利用 GPU 的并行计算能力。实验结果表明,经过布局转换后,Sparse VideoGen 在 Temporal Head 上实现了接近理论极限的加速效果,显著提升了整体推理速度。
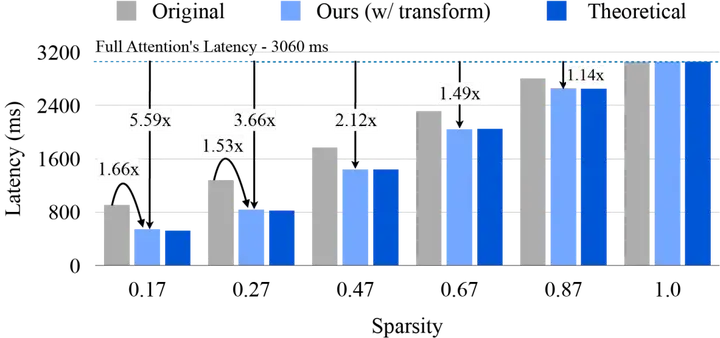
除了注意力机制的优化,Sparse VideoGen 还对 Query-Key Normalization(QK-Norm)和 Rotary Position Embedding(RoPE)进行了定制化优化,以进一步提升推理效率。在标准实现中,QK-Norm 和 RoPE 的计算开销较大,成为推理过程中的性能瓶颈之一。为此,研究者对这两个模块进行了算子优化,QK-Norm 的吞吐量在所有场景下均优于 PyTorch 的标准实现,平均加速比为 7.4 倍,。同样地,定制化的 RoPE 实现也在所有帧数下表现出更高的吞吐量,平均加速比为 14.5 倍。

实验成果
媲美原模型的画质,显著的推理速度提升
在 Wan2.1、HunyuanVideo 和 CogVideoX 上,Sparse VideoGen 展现出强大性能:
1. 在 H100 上将 HunyuanVideo 的推理时间从约 30 分钟降至 15 分钟以内;将 Wan 2.1 的推理时间从 30 分钟将至 20 分钟;
2. 保持 PSNR 稳定在 29dB 以上,接近 Dense Attention 输出画质;
3. 可无缝接入多种现有 SOTA 视频生成模型(Wan 2.1、CogVideoX、HunyuanVideo);
4. 同时支持 T2V(文本生成视频)和 I2V(图像生成视频)任务。
在未来,随着视频扩散模型的复杂度进一步上升,如何在不损失视觉质量的前提下提升效率,将是核心问题之一。SVG 的工作展示了一条重要方向:结构理解 + 自适应稀疏性可能成为视频生成推理优化的黄金组合。
这一研究也在提示我们:视频生成模型不必一味追求更大,理解其内部结构规律,或许能带来比扩容更可持续的性能突破。
文章来自于“机器之心”,作者“机器之心”。

【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

