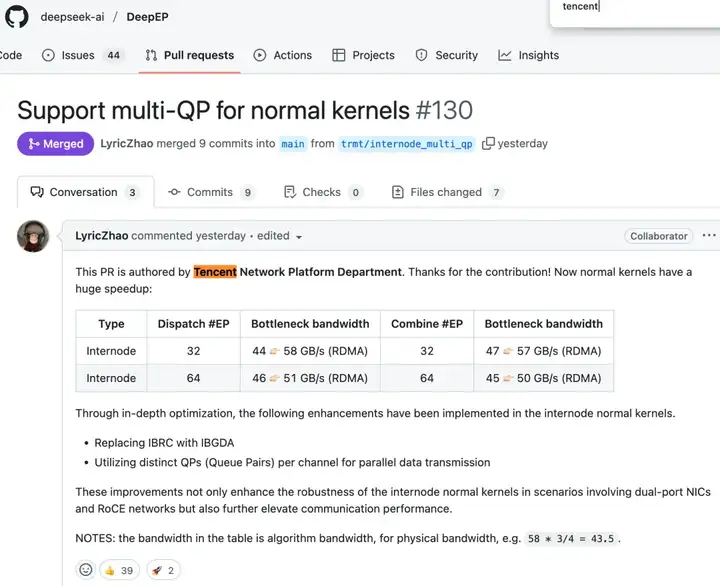
最近,DeepSeek工程师在GitHub上高亮了来自腾讯的代码贡献,并用“huge speedup”介绍了这次性能提升。
什么样的优化技术让顶尖AI团队如此兴奋?
简单来说,是腾讯多年来调教数据中心和GPU通信沉淀下来的TRMT技术,帮助DeepSeek开源的网络通信神器DeepEP性能再上一个台阶。
这项合作的起点要追溯到今年2月——DeepSeek开源了包括DeepEP在内的五大代码库,揭秘了他们如何用1/5硬件资源实现传统万卡集群效能的核心技术。
其中,DeepEP作为突破NCCL性能瓶颈的通信框架,通过300%的通信效率提升,成功让众多MoE架构的大模型摆脱了对英伟达NCCL的依赖。
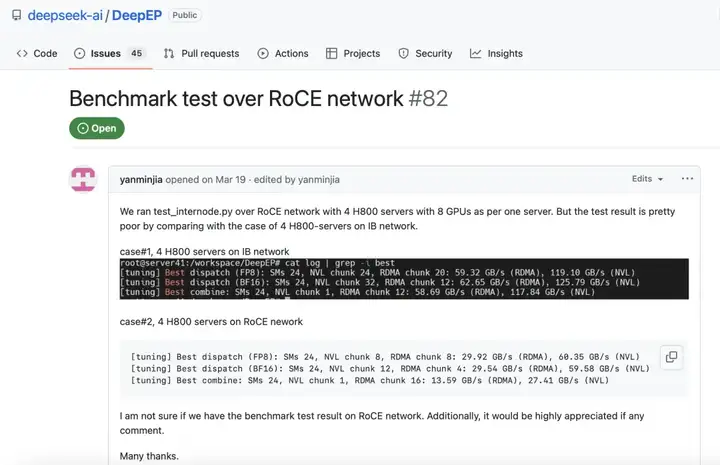
但这项技术存在“富贵病”:在成本较高的InfiniBand(IB)专用网络中如鱼得水,却难以适配更普适的RoCE网络环境。就像超级跑车只能在专业赛道驰骋,开上普通公路就性能缩水,这让大多数使用普通网络的企业机构面对DeepEP往往看得着、用不上。
DeepEP的Github主页上,也出现了关于RoCE网络环境中性能表现不佳的讨论,相关问题一直没有找到理想的解法。
但腾讯在RoCE网络领域可是老司机,多年来在数据中心沉淀了丰富的经验,在DeepEP开源后立即展开验证,迅速锁定两个关键突破点:
- 车道利用率低下:RoCE网卡普遍采用双端口架构,但既有系统无法智能分配流量,常出现单车道拥堵、双车道闲置的窘境,就像快递公司面对双向八车道却只使用一侧车道。
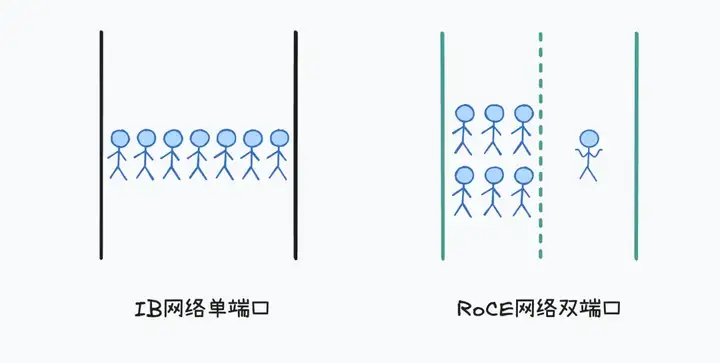
- CPU控制瓶颈:虽然DeepEP通过RDMA技术实现了GPU直连通信,但在控制面交互层面仍依赖CPU中转,存在时延和能耗优化空间。
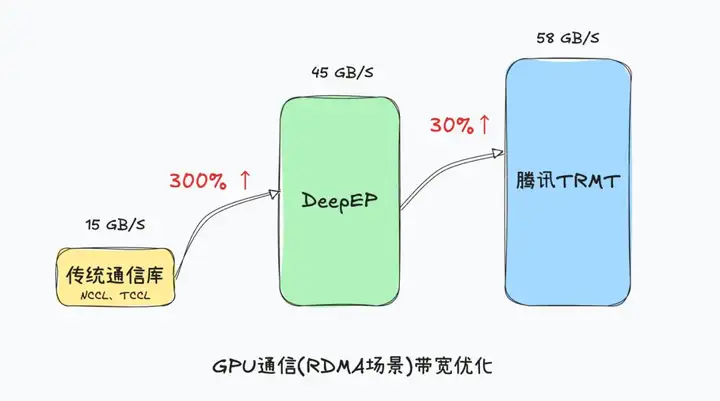
于是,腾讯基于TRMT技术体系开始对DeepEP进行三个方面的优化👇
//双车道充分用起来:拓扑感知的多QP建链
本质上是利用动态分配算法来最大化双端口网卡的带宽利用率。
在 AI 模型启动时,多个 GPU 之间会建立通信组。每个 GPU 组内,GPU 之间都要建立通信链接,并且每个 GPU 对需要建立多组 QP(队列对)。
这种架构涉及革新类似于智慧交通管理系统:当2048辆特种车辆(GPU数据包)需要在城市路网(RoCE网络)中高效通行时,控制系统为每类物资运输开辟专属路线(QP绑定端口)。
通过动态分配起始匝道口(UDP源端口),确保双车道物理通道(网卡端口)的车流均衡,从根本上避免了多车队汇入同条车道引发的堵塞,让双端口网卡带宽利用率达到理论峰值。
//进一步绕过CPU:基于 IBGDA 的多 Channel 负载均衡数据传输
RDMA直连GPU进行数据交互就像港口运货,货物到港后不用停下来卸货装车,可以直接运到市区。
但在“控制面”场景还是无法让GPU绕过CPU的控制。“控制面”类似港口处理哪个批次的货物到港、货物是什么、运货的车牌号是多少等等,这种“控制面”场景的信息还是需要CPU来处理。
腾讯基于IBGDA(InfiniBand GPU Direct Accelerator)技术,让控制面场景的CPU也绕过了,控制时延降低至硬件极限。
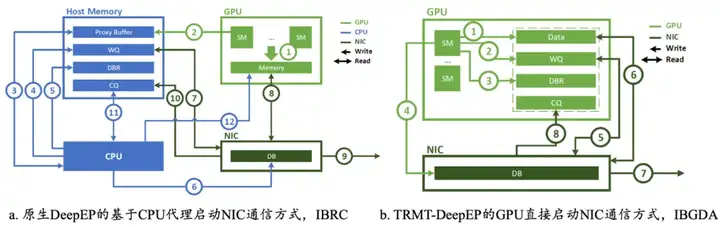
(看这清爽的右图,就知道IBGDR这种让控制面绕过CPU的方法提升了多少效率)
同时,腾讯还让每个 GPU 都能同时用多个“通道”来发送数据,而且这些通道会自动分配数据,不会让某个通道太忙而其他通道闲着。
//排好队不出错:原子化信令协同
在GPU直接通信时还存在一个关键难题:当A GPU直接把数据写入B GPU内存时(类似隔空投送),B GPU并不知道数据何时到达。如果多个数据传输任务同时进行,可能会发“先发的包后到”的混乱情况。
鹅厂工程师提出了一种叫做“QP内时序锁”机制,类似一种智能快递签收机制:每次传输数据时,通过网卡硬件自动生成数字指纹(类似快递单号加密),收件方必须按正确顺序“签收”。
现在,就算同时处理1000多个数据传输任务,系统也能自动理顺先后顺序。
这三板斧下来,DeepEP不仅在RoCE网络上实现性能翻倍,当DeepSeek将这套方案反哺到IB网络时,原本已经很优秀的通信效率竟然又提升了30%。
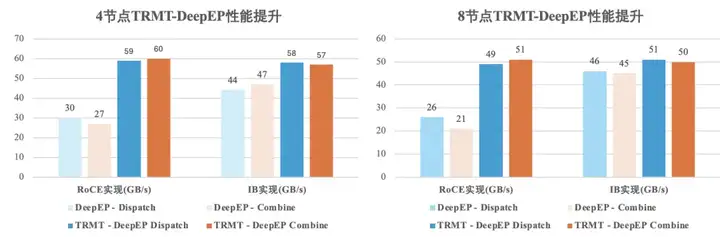
目前,这些技术成果都已经全面开源至DeepEP社区,并深度应用于腾讯混元大模型等项目的训练推理。在星脉网络与H20服务器构建的高性能环境中,这套方案同样展现出卓越的通用性。
最后,感谢DeepSeek工程师以及我的同事们,对GPU通信瓶颈难题的探索。
还有,感谢开源。
文章来自于“鹅厂技术派”,作者“拥抱开源的”。


