你是否有过这样的体验:和ChatGPT聊得正欢,它突然就"失忆"了,忘记了你们之前讨论的内容?或者想让AI分析一份长文档,却发现它只能"看"一小部分?
这并非AI有意为之,而是受限于大语言模型固有的上下文窗口限制。无论是8k、32k还是128k tokens的容量,一旦超过这个阈值,先前的对话内容就会被截断丢失,导致交互体验严重受损。
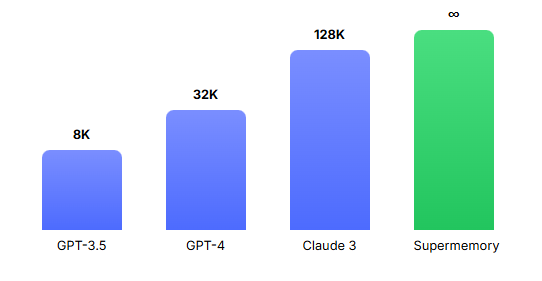
没错,即使是最强大的大语言模型也有"健忘症"!但现在,Supermemory提出的创新解决方案横空出世,声称只需一行代码,就能让任何AI拥有"无限记忆"能力。这到底是怎么回事?今天我们就来一探究竟!
为什么大语言模型会"健忘"?
想象一下,如果你的大脑只能同时记住最近看过的10页书的内容,超过这个范围的信息就会被自动"删除"——这就是大语言模型的现状。
大语言模型的"健忘症"源于一个叫做"上下文窗口"(Context Window)的限制。这个窗口决定了模型一次能处理的最大文本量,就像是AI的"工作记忆"容量。
即使是最先进的GPT-4,其上下文窗口也只有128K tokens(大约10万汉字)。虽然看起来不少,但在复杂对话或长文档处理中,这个限制很快就会被触及。
为什么不直接扩大这个窗口呢?主要有三大障碍:
1.计算成本爆炸:Transformer架构的计算复杂度是序列长度的平方,窗口翻倍,成本就会增加4倍!
2.内存消耗惊人:长上下文需要更多GPU内存,超长上下文可能直接导致显存不足。
3.位置编码困境:模型难以理解超出训练长度的序列位置,就像你让一个只学过100以内加法的小学生计算1000+2000一样困难。
这些限制导致了AI在长对话、文档分析、知识管理等场景中的短板,严重制约了其应用潜力。
Supermemory:AI的"无限记忆外挂"
面对这一挑战,Supermemory推出了一个令人惊叹的解决方案——Infinite Chat API,它承诺可以扩展任何模型的上下文长度,让AI拥有"无限记忆"能力,且无需开发者重写任何应用逻辑。
核心解密:智能代理 + 记忆系统 = 永不失忆!
这项技术的核心在于其创新的智能代理架构,主要包含三个关键环节:
首先是透明代理机制。Supermemory充当中间层,只需将原有OpenAI等API的请求URL更改为Supermemory的地址,系统就会自动将请求转发给相应的LLM。这意味着开发者几乎无需更改代码,就能立即获得"无限记忆"功能。
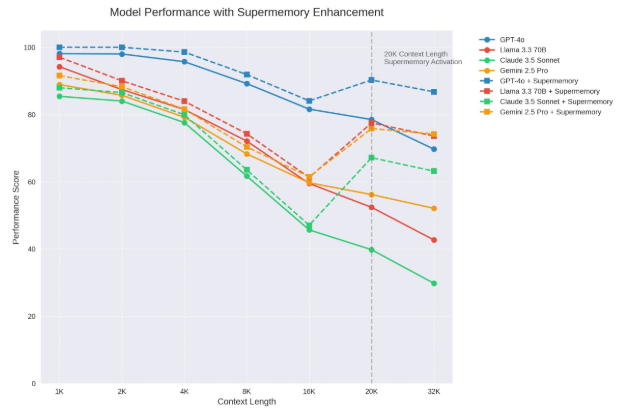
其次是智能分段与检索系统。该系统会将长对话内容分成保持语义连贯性的块,并在需要时只提取与当前对话最相关的上下文片段传给大模型,而非全部历史记录,这极大提高了效率并降低了资源消耗。
第三是自动Token管理。系统能根据实际需求智能控制token使用量,避免因上下文过长导致的性能下降,同时防止成本失控及请求失败。
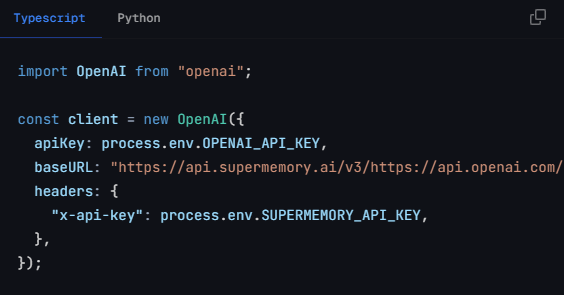
最令人震惊的是其使用方式的简单程度。只需将原来的Python 代码调用类OpenAI API端口地址:
constclient = newOpenAI({
baseUrl:"https://api.openai.com/v1/"
})
换成Supermemory的地址:
constclient = newOpenAI({
baseUrl:"https://api.supermemory.ai/v3/https://api.openai.com/v1/"
})
就这样,一行代码的改变,你的AI应用立刻获得了"超级记忆力"!
与传统解决方案的对比
在Supermemory出现之前,开发者们通常采用这些方法来解决大模型的"健忘症":
向量数据库检索:实现复杂,维护成本高,检索精度有限
手动分段管理:需要开发者自行切分文档,管理上下文,增加开发负担
定制微调模型:成本高昂,且仍受限于基础架构的限制
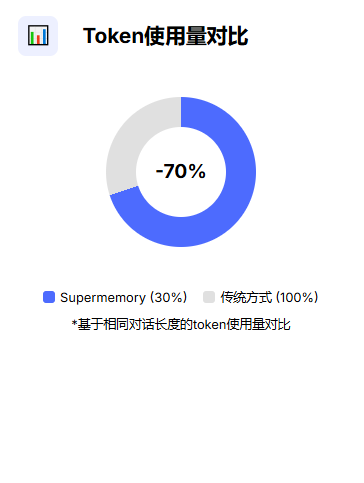
相比之下,Supermemory的优势显而易见:一行代码集成、零维护成本、适用于所有OpenAI兼容模型,同时还能节省90%的token消耗。
Supermemory的核心优势包括:
节省90%的token和成本:通过智能压缩历史对话,大幅降低API调用费用
无缝集成:对业务代码零入侵,支持所有兼容OpenAI API的模型
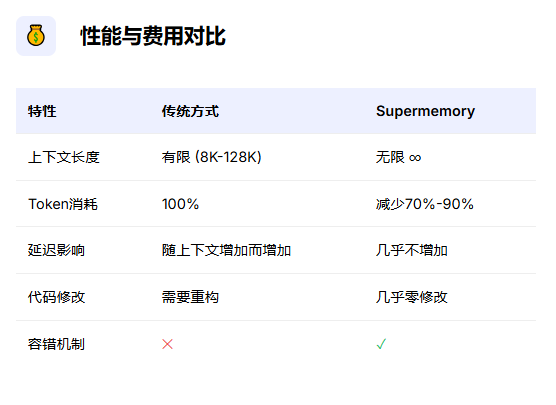
自动记忆管理:智能压缩对话内容,动态提取关键信息
几乎零延迟:额外处理几乎不增加响应时间
实际应用场景
Supermemory的出现,为AI应用开辟了全新的可能性:
1.无限长对话:客服机器人可以记住用户的完整历史,提供连贯一致的服务体验
2.长文档分析:轻松处理长篇报告、论文或书籍,无需人工分段
3.知识库问答:将整个知识库作为上下文,回答更精准、更连贯
4.创意写作:AI可以记住整个故事情节和人物设定,创作更连贯的长篇内容
目前,已有多家企业开始应用Supermemory:Mixus用它构建协同智能代理平台,MedTech Vendors用它搜索50万供应商信息,Flow则用它增强写作助手的连贯性。
开源与自托管
值得一提的是,Supermemory是完全开源的,在GitHub上已获得9.5k星标。这意味着你不仅可以免费使用它,还可以根据自己的需求进行定制和部署。
对于注重数据隐私的企业用户,Supermemory提供了详细的自托管指南,让你可以在自己的服务器上部署这一强大工具,确保敏感数据不出企业内网。
文章来自微信公众号 “ 微知AI ”,作者 Crow

【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

