AI替咱打工搞翻译,到底谁家最好用?
终于,有人来统一翻译江湖的标准了:首个应用型AI翻译测评榜单TransBench在OpenCompass上线。
它由阿里国际AI Business团队联合上海人工智能实验室、北京语言大学共同发布。

与传统的翻译测评体系相比,TransBench增加了幻觉率、文化禁忌词、敬语规范等指标,专门针对大模型翻译最容易出错的关键问题进行实战考核。
比如:
- 翻得挺溜但张口就编,这就得算“幻觉”;
- 翻得准确却冒犯了当地文化,那也是“翻译事故”;
- 甚至你在客服场景里少说一句“please”,都可能让用户不爽。
这是首次针对行业的细分领域构建评测数据和评测方法。这些指标均来自真实场景的使用反馈,由此来测评大模型是否符合大规模应用的标准。
目前,TransBench评测方法与数据集已全面开源,也已发布了首期测评结果。
欢迎各个AI翻译机构去打榜,一较高下~
GPT-4o稳坐“翻译AI天花板”
官网表示,TransBench数据集中涵盖中、英、法、日、韩、西班牙等多种语言。
此外,还在不断持续更新海量小语种。
TransBench评测体系中的数据集,根据“通用标准”“电商文化”“文化特性”三个大类,整理了不同的数据集。

目前,TransBench多语言翻译评测榜单首期已经出炉。
评测榜单从“综合得分”“通用标准”“电商文化”“文化特性”四个维度来给每个模型的翻译能力打分。
其中,综合得分是模型在评测数据集的三大维度的综合平均得分。为了保证数值可被平均,榜单对不同得分进行了数值缩放。
我们查看并整理了“英语翻译为其它语言”和“中文翻译为其它语言”两个榜单的模型能力。
英语翻译为其它语言
这个条件下,综合得分和通用标准的得分前三,都分别是:
- 第一:GPT-4o
- 第二:DeepL Translate
- 第三:GPT-4-Turbo
其中比较特别的是DeepL Translate,上个月底刚刚发布。
和前三名的另外两位不同,这是一个专门的机器翻译(MT,Machine Translation)模型,而不是通用大语言模型。

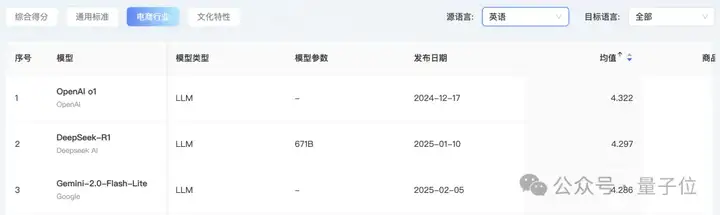
在电商行业,DeepSeek-R1的翻译能力杀入榜单前三:
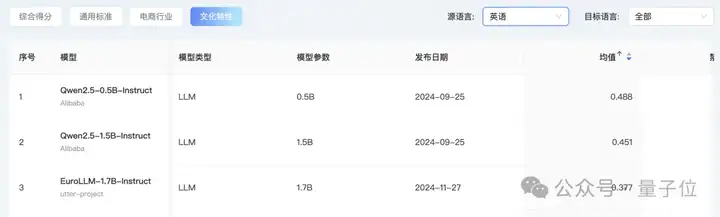
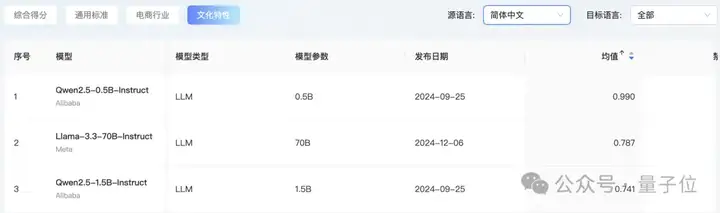
而在文化特性方面,Qwen系列一马当先。
Qwen2.5-0.5B-Instruct和Qwen2.5-1.5B-Instruct分别位居第一第二,同时第三名花落EuroLLM-1.7B-Instruct。
大家可能对EuroLLM-1.7B-Instruct相对陌生,它是由多个欧洲研究机构联合开发的开源多语言大模型,涵盖35种语言,旨在支持所有欧盟官方语言以及其他主要语言。
中文翻译为其它语言
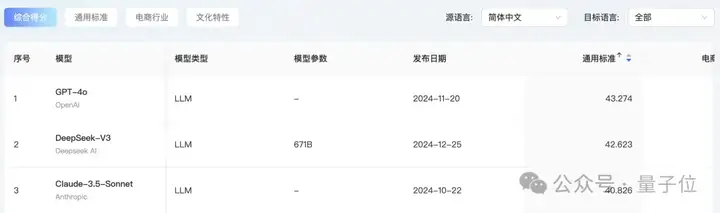
同样,在中文翻译为其它语言这条赛道上,综合得分和通用标准的排名相同:
- 第一:GPT-4o
- 第二:DeepSeek-V3
- 第三:Claude-3.5-Sonnet
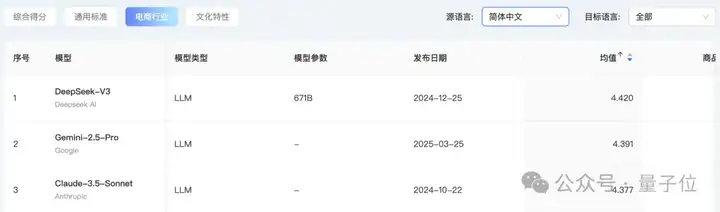
在电商行业,拿下第一的是均值得分4.420的DeepSeek-V3。
紧随其后的才是Gemini-2.5-Pro和Claude-3.5-Sonnet。
最后一项文化特性,Qwen系列的表现同样出色。
榜单前三分别是Qwen2.5-0.5B-Instruct、Llama-3.3-70B-Instruct、Qwen2.5-1.5B-Instruct。
三大维度打造翻译大模型实战考卷
随着AI大模型加速落地,翻译模型也进入“比谁更好用”的时代。
相应的,业内也对大模型翻译效果有了更高的要求,比如要符合不同地区的文化特性、能体现不同行业的语言特色等。
但问题来了——怎么判断一个AI翻译模型到底好不好用?
传统的翻译测评维度,主要关注通用质量(如BLEU、COMET),难以反映真实使用场景中对语义准确性、文化合规性、用户体验的高要求。
并且,大模型时代的AI翻译往往面临幻觉等更多问题。
也就是说,传统的翻译测评维度在今天已经不适用了。
为此,阿里国际AI Business团队联合上海人工智能实验室、北京语言大学一起,构建了更全面、最新的评测标准和规范TransBench。
它从三大维度,重新定义翻译测评:
第一,全面的通用标准。
不仅包括通用质量,还新增幻觉率和鲁棒性评测。
第二,行业垂直标准。
这是首次针对行业的细分领域构建评测数据和评测方法,数据均来自行业细分领域真实数据,并利用语言专家在应用中的标注数据训练面向行业的打分模型。
第三,跨文化特性标准。
首次提出文化禁忌和敬语规范的评测数据和评测方法。
举个例子!
电商场景下的用户投诉,通常与敬语、禁忌语等相关。
这些翻译结果从字面意思看无误,但会直接影响到对话人的体验,应该被纳入到测评的范围中。
从阿里国际自研翻译大模型真实用户反馈中总结提炼
其实,早在去年10月,阿里国际的AI Business团队就发布了首个大规模商用的翻译大模型Marco MT,其效果赶超Google、DeepL等头部AI翻译工具。
截至目前,Marco MT的日均调用量为6亿次,是电商领域使用量最大的翻译大模型。
而TransBench的测评体系,正是基于Marco MT在全球真实用户反馈中总结提炼而来。
因此,构建TransBench这件事中有阿里国际的身影就很好理解了。
当然,除了有业界认可的领先技术外,业务需求也是其中原因之一。
阿里国际旗下有Aliexpress、Lazada、Alibaba.com、Trendyol及Daraz等电商业务,覆盖全球200多个国家和地区,多语言翻译是助力业务发展的重要一环。
根据公开信息,2023年3月,阿里国际成立了AI Business,基于全球化电商场景探索AI技术。
现在,阿里国际的所有电商平台均已广泛应用AI能力,已服务了超50万卖家,形成了以服务中小企业出海为核心,覆盖全球多元市场、多种电商模式的规模级AI应用。
目前,TransBench的测评方法进行了开源,评测结果也将持续更新。
BTW:
最近启动的2026届校招中,阿里国际放出的岗位,80%是AI岗位,包括AI算法、研发、AI产品经理等。
有兴趣的同学欢迎投递~
测评网址:
https://transbench.com/#/?lang=zh-cn
文章来自于“量子位”,作者“衡宇”。

【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/

