
当你在搜索“中国队在多哈乒乓球锦标赛的成绩”时,一篇新闻报道的文本部分和你的查询的相关性是 0.7,配图的相关性 0.5;另一篇则是文本相关性为 0.6,图片也是 0.6。那么,哪一篇报道才是你真正想要的呢?
这正是当前多模态搜索领域的一大核心挑战:如何给这些既有图像又有文字的文档一个公平且准确的“综合相关性”评分?
其根本困难在于,文本与图像的评分来自不同维度,尺度各异,缺乏直接可比性。简单比较或组合这些分数,很难得到一个合理的结果。那么,如何才能有效排序这些多模态文档呢?
针对这一困境,本文将提出一个简洁有效的解决思路。但在深入探讨我们的方案之前,我们有必要先理解:
那些想当然的简单方法,为什么会失效?
其症结在于,jina-clip-v2 乃至几乎所有 CLIP 类模型都存在 模态鸿沟(modality gap),这个特性导致任何你可能想到的简单粗暴的方法都行不通。
简单来说,“模态鸿沟”指的是不同模态(比如图像和文本)的向量在共享的向量空间中彼此分离的现象,不同模态产生的相似度分数可能处于不同的“尺度”或“分布范围”。
这样一来,如果你只是 简单地选取文字和图片分数中较高的那个,就会发现文字分数通常集中在 0.2 到 0.8 之间,而图片分数则集中在 0.4 到 0.6 之间。 这就意味着,一个表现平平的文字匹配(0.6 分)总是会压过一个匹配度很高的图片匹配(0.5 分),这显然不合理。
那么,取平均分呢? 同样行不通。就算你算出 (0.7 + 0.3) / 2 = 0.5,这个数字又代表什么呢?你只是在对一些根本没有可比性的数值求平均,这本身就是没有意义的。 同理,任何固定的加权方式都显得很武断,有时候文本更重要,有时候图片更重要,这完全取决于具体的查询和文档本身。
即使你 先把分数进行归一化(Normalization)处理,也解决不了核心问题。你仍然是在试图组合那些本质上就不同,并且是从不同维度衡量相关性的相似度值。
到底发生了什么?
为了更好地理解我们面临的问题,让我们看一个来自 EDIS 数据集的示例文档:它包含一张图片(一场德国足球比赛)和一段文字说明(“One More Field Where the Content Trails Germany”,意指又一个欧洲大陆不如德国的领域)。

图 1:这是一个包含图像和文字的多模态文档示例。
由于我们有两种模态,对于任何给定的查询,我们实际上会面临两个潜在的语义鸿沟:查询与文本之间的鸿沟,以及查询与图像之间的鸿沟。那么,为了获得最佳结果,我们应该侧重于文档的文字内容,还是图像内容呢?
在 EDIS 数据集中,通过jina-clip-v2 评估时,我们观察到一个普遍现象:“Query-to-text”的相似度通常高于“Query-to-image”的相似度。 这部分源于模型的训练方式,也与数据集本身的特性有关。
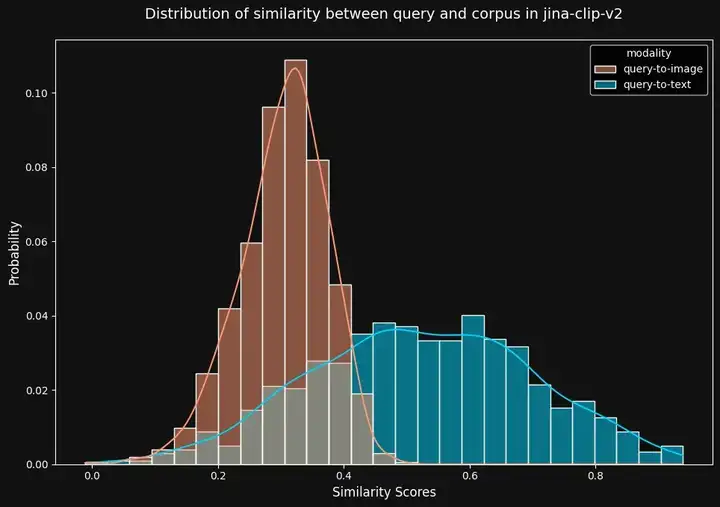
图 2:使用 jina-clip-v2 时,“Query-to-image”相似度分数(红色)与“Query-to-text”相似度分数(蓝色)的分布情况。
从直觉上看,这似乎意味着基于文本检索文档更为可靠。例如,在下图的案例中,当我们使用查询文本“... for undocumented immigrants helping to establish legal status in the United States (意指为帮助在美国建立合法身份的无证移民)”去匹配语料库中的文本内容时,确实能获得更好的结果。
事实上,如果仅通过图像进行搜索,根本无法检索到真实的目标文档(下图黄色高亮部分):

图3:一个例子,展示了使用 jina-clip-v2 进行“Query-to-text”检索、且 top_k 设为 3 时,才能找回真实的目标文档(黄色边框高亮)。
然而,事情并非如此简单。尽管“Query-to-text”显示出更高的相似度分数,但关键在于,这两个模态的相似度分数是不可直接比较的。
这一点,从我们使用 jina-clip-v2 从 EDIS 数据集中检索 32 个文档时的 recall@10(召回率前 10 名)可以清晰地看出来。“Query-to-Image”的召回率反而明显更高:

另一个例子更能凸显这种矛盾:如果我们使用数据集中的一个查询,“Ear ear An elephant is decorated with Bhartiya Janta Party symbols near the BJP headquarters in New Delhi.(意指耳朵 耳朵 一头大象在新德里印度人民党总部附近用该党标志装饰起来。)”,我们只能通过其图像内容来检索到真实的目标文档。如果只通过文本内容搜索,则完全找不到任何匹配项:
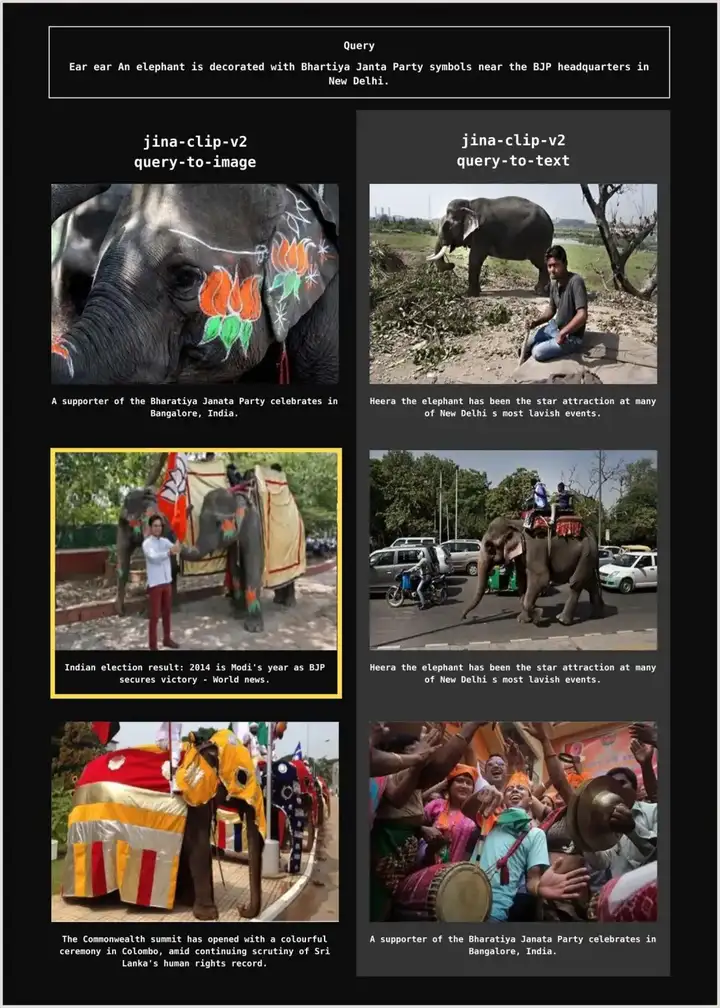
图4:一个例子,展示了用 jina-clip-v2 进行“查询-图像”检索、且 top_k 设为 3 时,才能找回真实的目标文档(黄色边框高亮)。
至此,我们面临一个两难的境地:相似度分数暗示我们应该优先从文本检索文档,而召回率又指示我们应该从图像检索文档。
那么,到底哪种模态才能真正反映查询与目标文档之间的最佳匹配呢?
更进一步,如果我们想合并“Query-to-text”和“Query-to-image”两种检索方式的候选结果,在分数根本不具备可比性的情况下,我们又该如何有意义地选出最佳匹配呢?
显然,仅仅使用 jina-clip-v2 是不够的。我们需要引入另一个模型来帮忙。
引入 jina-reranker-m0 的两阶段处理流程
针对上述挑战,我们在 2025 年 4 月发布了 jina-reranker-m0,这是一款多语言、多模态的文档重排序模型,专门用于对包含图像的文档进行检索和排序优化。
从下图可以看出,它的模态鸿沟明显窄了很多,不像 jina-clip-v2 那样差异巨大,jina-reranker-m0 的“Query-to-text”与“Query-to-image”相似度分数分布非常接近,模态鸿沟显著减小:
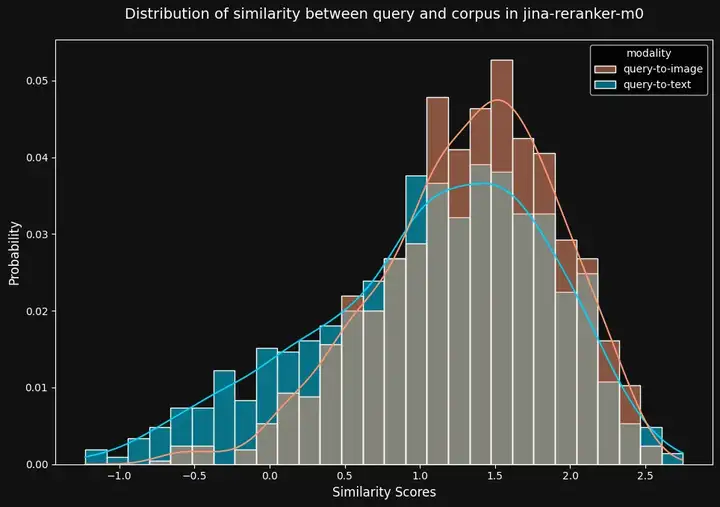
图6:与 jina-clip-v2 相比,jina-reranker-m0 在“查询-图像”(红色)和“Query-to-text”(蓝色)相似度分数上的差异要小得多。
基于 jina-reranker-m0 这一特性,我们可以设计一个简洁而有效的两阶段检索流程:
第一阶段:多路候选召回
- 使用 jina-clip-v2 分别通过文本搜索和图像搜索各检索一定数量的候选文档(例如,各 16 个,合计 32 个)。
- 这个阶段,我们先广泛收集候选的相关文档,暂不纠结其原始分数的直接可比性。
第二阶段:统一的多模态重排序(reranking)
- 把每个“查询 + 完整文档”的组合都输入给 jina-reranker-m0 处理。
- 这个重排器会综合考量文档中的文本和图像信息与查询的整体匹配度。
- 输出结果:一个在统一尺度下的相关性分数,用于最终排序。
下图清晰地展示了多模态文档的索引过程,以及结合 jina-clip-v2 和 jina-reranker-m0 的两阶段多模态检索流程:
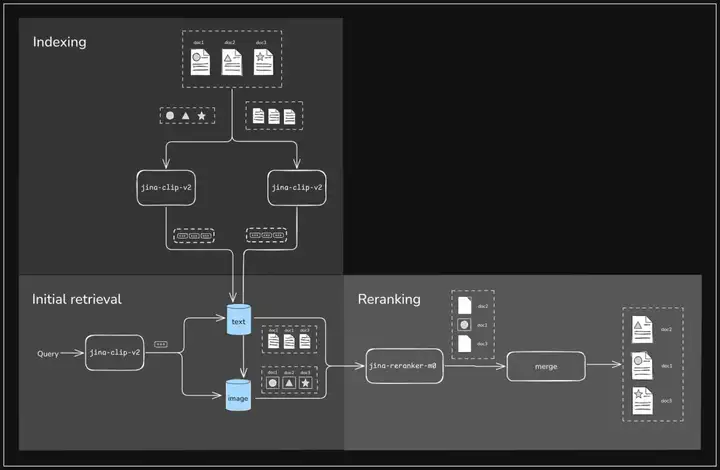
多模态文档索引及两阶段检索流程示意图
为了验证这一两阶段流程的有效性,我们进行了一系列实验。
实验流程遵循“先检索后重排”的两阶段模式:首先使用 jina-clip-v2 从包含文本和图像的完整语料库中召回候选文档,然后利用 jina-reranker-m0 对这些候选文档进行精细化的重排序。
实验对比了以下四种不同的检索与重排序策略:
1. 文本召回与文本重排
- 检索: 通过 jina-clip-v2 的“Query-to-text”召回评分最高的 32 个候选文档。
- 重排序: jina-reranker-m0 对这些候选的“Query-to-text”相关性进行重排。
2. 图像召回与图像重排:
- 检索: 通过 jina-clip-v2 的“Query-to-image”召回 32 个候选文档。
- 重排序: jina-reranker-m0 对这些候选的“Query-to-image”相关性进行重排。
3. 混合召回与单模态重排
- 检索: 通过 jina-clip-v2 的“Query-to-text” 和 “Query-to-image”各召回 16 个候选文档,共 32 个。
- 重排序: jina-reranker-m0 根据各候选的召回路径(文本或图像),对其相应的单模态(Query-to-text 或 Query-to-image)相关性进行重排。
4. 混合召回与统一多模态重排:
- 检索: 同策略三,混合召回。
- 重排: jina-reranker-m0 对每个候选,综合评估“查询”与“完整文档(文本+图像)”的整体相关性,输出一个统一的多模态分数进行最终排序。
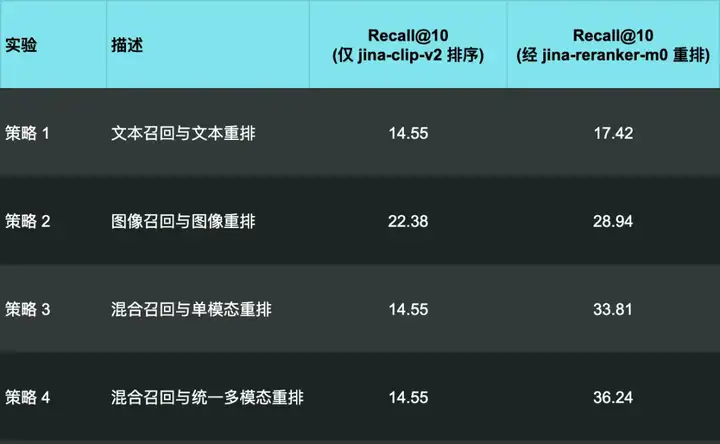
💡 值得注意的是,在上表中,第一列里策略 1、3 和 4 的结果均为 14.55。这是因为前文提到的,jina-clip-v2 的“Query-to-text”分数总是高于“Query-to-image”分数,前 10 名的结果几乎完全被通过文本检索路径的文档所占据,其 Recall@10 表现将远不如纯图像。
可以看到,通过 jina-reranker-m0 进行第二阶段的重排序后,所有策略下的 Recall@10 均获得了显著提升。
其中,当结合了通过文本和图像两种方式检索到的文档进行重排序时(实验 4),提升幅度最大,recall@10 达到了 36.24。
下图展示了一个直观的例子,无论用户的原始查询意图更偏向文本还是图像内容,jina-reranker-m0 都能将真实的目标文档排在第一位:
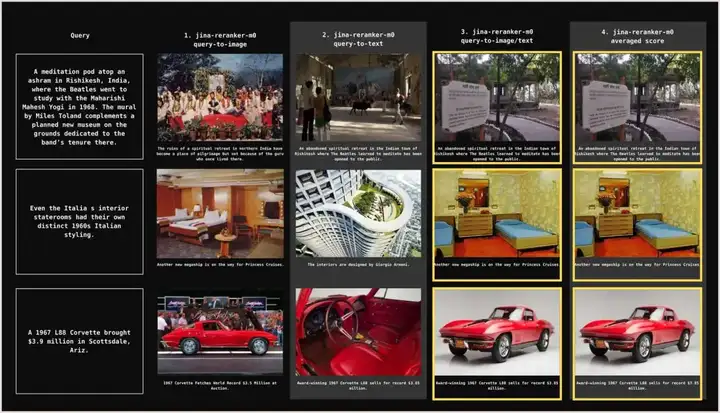
图7:查询示例(左侧)和每种重排序方法对应的 top_k 为 1 的结果(右侧四列),显示结合图像和文本相似度分数能始终将真实目标文档排在第一位。
💡 图 3 和图 4 展示了不同检索方法 top_k 为 3 的情况,而图 7 出于版面考虑,每种查询只展示了 top_k 为 1 的结果。
总结
这种看似简单的两阶段处理方式,之所以能带来高达 62% 的召回率提升,核心在于它终于学会了人类天生就会做的事情:结合我们看到和读到的信息,来共同判断相关性。
这个经验不光适用于搜索领域,对于更广泛的多模态 AI 系统设计也具有重要的启发意义。那些试图将不同模态分开处理、最后再简单捏合分数的单阶段方法,往往会受困于不同模态间度量标准不统一的“模态鸿沟”问题。因此,先进行广撒网式的多路召回,再进行统一的、能够理解跨模态信息的模块进行重排序的两阶段架构,正变得越来越重要。
欢迎大家通过我们的官方 API 或在 AWS、GCP 和 Azure 等云平台上体验 jina-reranker-m0 的强大功能。
- Jina AI API: https://jina.ai/models/jina-reranker-m0/
- GCP: https://console.cloud.google.com/marketplace/product/jinaai-public/jina-reranker-m0
- AWS: https://aws.amazon.com/marketplace/pp/prodview-ctlpeffe5koac
- Azure: https://azuremarketplace.microsoft.com/en-us/marketplace/apps/jinaai.jina-reranker-m0
文章来自于“Jina Al”,作者“Jina Al“。

【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI

