
1、介绍
1.1为什么AI硬件现在很重要
AI无处不在——从聊天机器人、推荐引擎到语音助手和ChatGPT或谷歌Gemini等工具。但在所有这些智能技术的背后,有一样东西经常被忽视:使这一切成为可能的硬件。
传统CPU对于一般任务来说是很好的,但是它们在深度学习所需的大量、复杂的计算中无法胜任。随着AI模型变得越来越大,越来越强,我们需要能够跟上的硬件。这就是GPU和TPU的用武之地。
- GPU(图形处理器)最初是为电子游戏而设计的,结果却非常适合训练AI模型。
- TPU(张量处理器),由谷歌构建,是定制设计的,可以更有效地运行AI工作负载,特别是在规模上。
现在,随着AI模型在世界各地的实时应用中得到应用,一个巨大的转变正在发生——朝着谷歌所说的“推理时代”。本文将分析GPU和TPU是如何演变的,以及为什么最新的TPU(Ironwood)可能会改变游戏规则。
1.2 TPU和GPU在AI中的作用
AI模型主要经历两个阶段:
- 训练——模型从数据中学习。
- 推理——模型根据它学到的东西做出预测或回答。
每个阶段都有不同的硬件需求:

到2025年,GPU和TPU对现代AI都至关重要。但是它们的设计、优势和最佳用例是完全不同的——了解这些差异有助于为AI工作负载选择正确的工具。
2、AI计算的进化
2.1 GPU对AI的重要性
起初,GPU主要用于图像处理,比如渲染视频游戏和3D效果。但在2000年代中期,研究人员意识到GPU也非常擅长处理并行数学运算,这也用于AI。
这导致了GPGPU (GPU上的通用计算)的想法。当NVIDIA在2006年发布CUDA时,它为开发人员提供了一种为GPU编写AI友好代码的方法——这开启了深度学习革命。
2.2深度学习创造对新芯片的需求
随着深度学习在AlexNet、ResNet和后来的transformer等模型上的普及,对硬件的需求也在增加。GPU功能强大,但它们并不是专门为机器学习而设计的,所以像能耗和可扩展性这样的问题就成了一个问题。
这为专门为AI设计的专用芯片打开了大门。这就是谷歌的TPU的用武之地。
2.3 谷歌的TPU:为AI打造的芯片
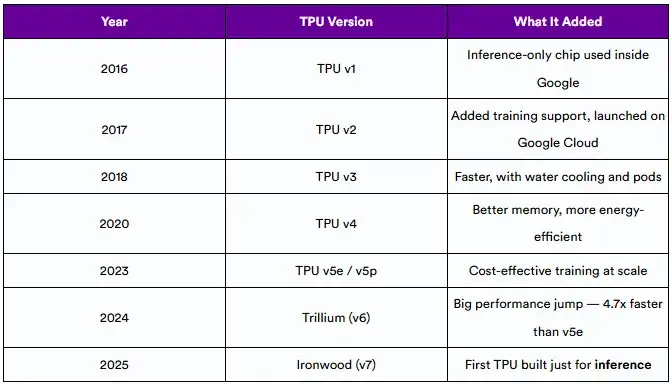
谷歌在2016年推出了首款TPU,以帮助更有效地运行AI任务。TPU是ASIC,这意味着它们是为一项任务而构建的。
每一代新的TPU都增加了更多的速度、内存和效率:
2.4改变游戏的里程碑
以下几项活动让AI硬件成为人们关注的焦点:
- AlphaGo (2016): 谷歌的DeepMind使用TPU击败了围棋世界冠军——向世界展示了定制AI硬件的能力。
- 云TPU发布(2017年):谷歌以外的开发人员现在可以使用TPU进行培训。
- LLM(2018-2024):像GPT-3、PaLM和Gemini这样的大模型推动了对更多更好硬件的需求。
这些时刻帮助证明了硬件和模型本身一样重要。
2.5 新的焦点:大规模推理
过去,大多数AI硬件都专注于训练大型模型。但现在,这些模型正在运行数十亿人使用的实时应用程序,重点正在转向推理。
推理意味着模型正在实时完成工作——回答问题,检测垃圾邮件,推荐视频。这意味着硬件需要:
- 快速(低延迟)
- 可扩展(服务数百万或数十亿用户)
- 高效(特别是在大型数据中心)
谷歌于2025年推出的Ironwood TPU就是为此专门设计的。它是为实时推理、处理搜索、翻译和即时响应的AI代理等任务而设计的。
3. 了解硬件:TPU和GPU基础知识
3.1 什么是GPU?

GPU是一种最初用于加速游戏和3D渲染的并行处理器。它的架构——数千个核并行运行——使其成为训练神经网络等工作负载的理想选择,在这些工作负载中,矩阵运算占主导地位。
像A100和H100这样的NVIDIA GPU现在是AI的主力,由成熟的软件堆栈(CUDA, cuDNN)和PyTorch和TensorFlow等框架支持。
3.2 什么是TPU

TPU是谷歌设计的专门芯片,用于加速机器学习工作负载,特别是深度学习中使用的张量代数。
与GPU不同,TPU不是通用的。它们被设计成在一件事上做得特别好:高效地运行ML模型。某些代(v2-v5)同时支持训练和推理;其他的,比如Ironwood,只进行推理,但优化到了极致。
3.3 主要架构差异
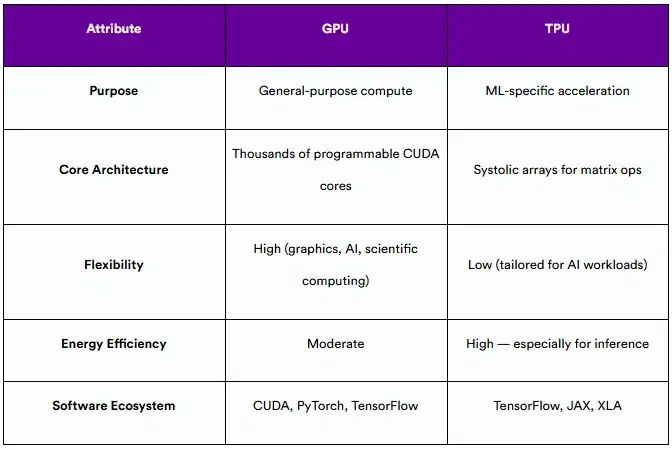
结论:GPU是瑞士军刀;TPU类似于手术刀——效率高,并且在推理繁重的环境中日益占主导地位。
3.4 今天在哪里使用它们
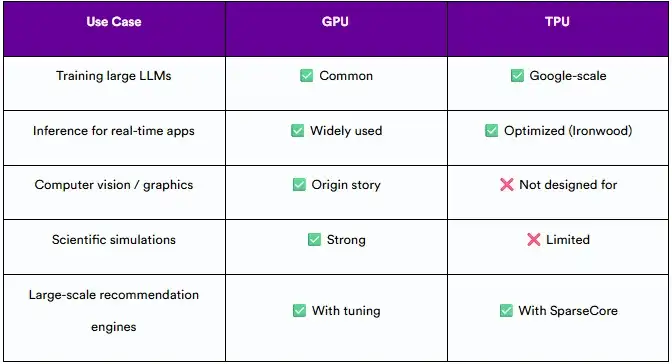
4. 架构比较:TPU vs GPU
了解TPU和GPU之间的架构差异是评估它们在真实AI工作负载中的性能、效率和用例的关键。虽然两者都旨在加速机器学习任务,但它们的计算设计、内存结构和功耗差异很大。
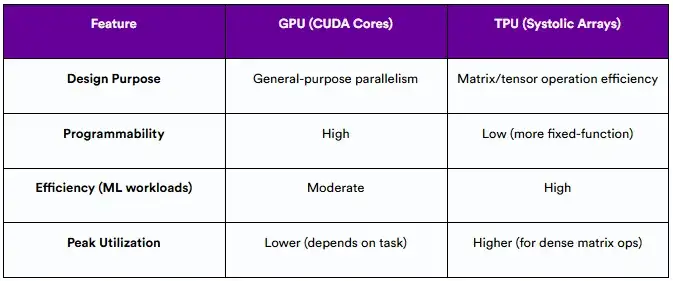
4.1 计算设计(Systolic阵列vs CUDA核心)
GPU是围绕数千个小型处理核心(NVIDIA GPU中的CUDA核心)设计的,可实现高并行性。这些核心是可编程的,灵活的,支持AI以外的广泛计算。
相比之下,TPU使用Systolic阵列,这是一种硬件设计,可以有节奏地在相互连接的处理元素网格上传递数据。这种结构是高度优化张量操作,如矩阵乘法-深度学习的基础。
4.2 内存层次和带宽
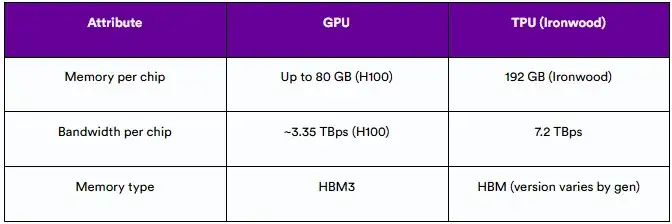
在需要快速移动和处理大型张量的AI工作负载中,高效的内存访问至关重要。
- GPU使用具有高带宽的内存层次结构(全局、共享、缓存)在处理器和内存之间移动数据。
- TPU,特别是像Ironwood这样的下一代TPU,将高带宽内存(HBM)紧密集成到芯片中,从而最大限度地减少延迟并提高吞吐量。
4.3 对接与通信
现代AI模型通常会在数百或数千个芯片上运行,因此快速的芯片间通信至关重要。
- GPU使用NVLink和NVSwitch等技术进行多GPU设置。
- TPU使用谷歌的定制芯片间互连(ICI),支持在大量TPU之间进行高带宽,低延迟的通信。

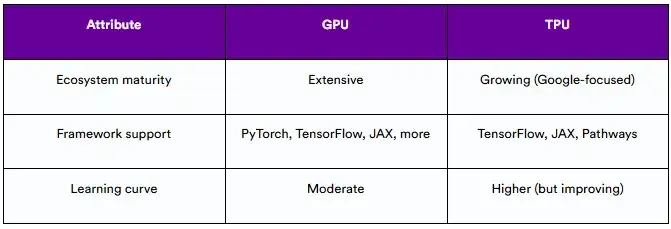
4.4 软件生态系统
- GPU有一个成熟的生态系统,主要由CUDA驱动,在PyTorch、TensorFlow和JAX等框架中得到广泛支持。
- TPU与谷歌的ML堆栈深度集成,包括TensorFlow, JAX和Pathways运行时。
4.5 功耗和热效率
随着计算需求的增加,对能耗和散热的关注也在增加。
与GPU相比,TPU一直致力于更高的每瓦特性能,特别是在推理方面。Ironwood是谷歌最新的TPU,其性能是其前身Trillium的两倍,并通过先进的液冷解决方案进行冷却。

5. 性能
本节探讨TPU和GPU如何在实际AI性能的各个维度上进行比较。
5.1 训练性能
GPU仍然是最常用的训练硬件,特别是对于使用PyTorch的研究人员和开发人员。例如,NVIDIA的H100 GPU针对混合精度训练进行了优化,并支持大规模多GPU设置。
从TPU v2开始,TPU也支持培训。谷歌的路径堆栈可以在数千个TPU之间进行大规模训练。对于像Gemini或PaLM这样的大模型,TPU通常是硬件的选择。
5.2 推理性能
Ironwood TPU专为大规模推理而设计,在搜索排名、语言模型和推荐等工作负载上提供低延迟、高吞吐量和高效的性能。
GPU也很好地支持推理,特别是使用TensorRT优化。然而,它们通常消耗更多的功率,并且需要更多的调优来匹配大规模的TPU级效率。
5.3 可扩展性和并行性
TPU和GPU都提供强大的可扩展性:
- GPU通过NVLink/NVSwitch扩展,通常用于DGX系统或超级计算机。
- TPU通过pod(由数千个芯片紧密集成的集群)进行扩展。Ironwood每个pod最多支持9,216个TPU,总计算能力达到42.5 ExaFLOPs。

5.4 每瓦性能分析
能效正在成为差异化竞争的一个因素:
- TPU在设计上可以减少AI特定工作负载的功耗。据报道,Ironwood的效率比第一代TPU高出近30倍。
- GPU虽然功能强大,但通常提供较低的每瓦特性能,除非使用较低的精度和节能技术进行微调。
6. TPU世代:从v1到Ironwood
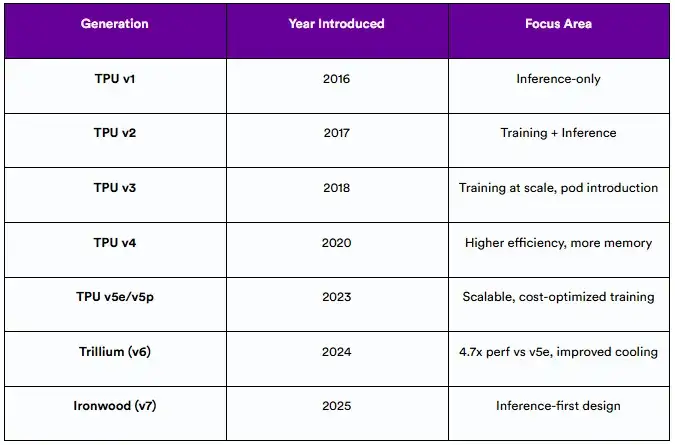
自2016年首次亮相以来,TPU已经发生了巨大的变化。每一代都引入了以性能、灵活性和现在的推理为重点的体系结构改进。
6.1 TPU演进时间表
6.2 每一代TPU的创新
每一代新的TPU带来了独特的进步:
- TPU v2:支持训练;在谷歌Cloud上提供
- TPU v3:液体冷却,改进pod连接
- TPU v4:注重能源效率,更好的内存带宽
- TPU v5e/v5p:针对多用户环境中的成本和可扩展性进行了优化
- Trillium: perf/watt和混合精度计算的重大飞跃
- Ironwood:从头开始建造,用于超大规模的推理
6.3 Ironwood (TPU v7)深度解析
6.3.1推理优先架构
Ironwood旨在处理复杂的推理工作负载,包括大型LLM,MoE模型以及实时思考和响应的AI代理。
6.3.2 计算、内存和网络进展
- 计算:每芯片4,614 TFLOPs
- 内存:每片192GB HBM
- 带宽:7.2 TBps内存,1.2 TBps互连
- Pod规模:高达9,216个芯片→42.5 ExaFLOPs
- 冷却:先进的液体冷却
6.3.3 用例:Gemini、AlphaFold、Ranking等。
Ironwood支持高级工作负载,如:
- Gemini 2.5——谷歌的前沿LLM
- AlphaFold -蛋白质结构预测
- 搜索和YouTube排名系统
- 使用实时推理的生成式AI agent
7. AI硬件生态系统和现实世界的采用
理论上的性能基准只是故事的一部分。对AI硬件的真正考验在于生产环境——在生产环境中,可扩展性、成本效率和开发人员可访问性与原始计算一样重要。在本节中,我们将探讨TPU和GPU是如何在整个行业中部署的,以及它们采用路径的区别。
7.1 谷歌的TPU生态系统
TPU是谷歌AI基础设施的核心,为从日常应用到世界级研究的一切提供支持。TPU专为高吞吐量、低延迟推理而设计,适用于需要扩展到数十亿用户和请求的工作负载。
以TPU为动力的谷歌服务举例:
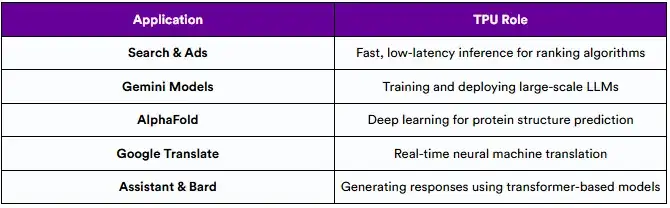
添加图片注释,不超过 140 字(可选)
较新的一代,如TPU Ironwood,带来了改进的内存带宽,能源效率和计算密度,使它们成为大规模训练和推理的理想选择。
7.2 GPU据点超过谷歌
虽然TPU在谷歌占主导地位,但GPU仍然是更广泛的AI社区的行业标准。从学术实验室到初创公司和企业研发团队,GPU——尤其是NVIDIA的A100和H100——是首选的硬件。
值得注意的GPU部署
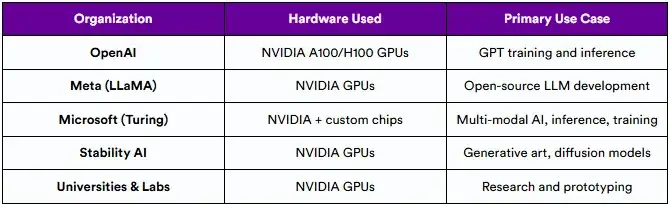
GPU因其灵活性,成熟的软件堆栈(CUDA)和跨云可用性而受到青睐,使其更易于访问,对开发人员更友好,可用于通用AI任务。
7.3 云可用性和开发者访问
可访问性在硬件采用中起着重要作用。TPU目前是谷歌Cloud独有的,这使得AWS或Azure上的团队无法访问它们。相比之下,GPU得到了几乎所有主要云供应商的广泛支持。
云供应商提供的AI硬件可用性:
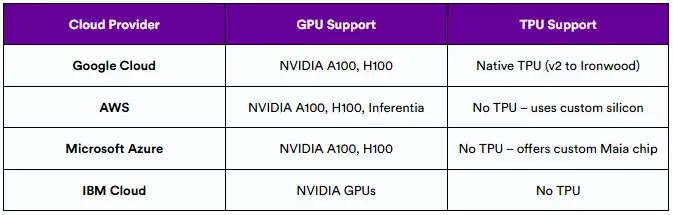
如果在GCP内构建或利用Gemini或AlphaFold等模型,TPU可以提供深度集成。对于其他来说,由于GPU的普遍性和工具链兼容性,GPU仍是首选。
7.4 谁在引领定制AI芯片竞赛?
AI硬件领域不再是一匹马的竞赛。一些云供应商现在正在投资定制芯片,以寻求对成本、能效和性能的更好控制。
领先定制AI芯片的比较:
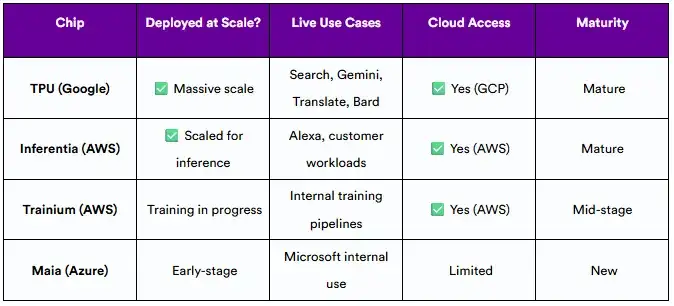
谷歌在成熟的TPU部署方面处于领先地位,而AWS正在追赶以推理为重点的Inferentia和训练优化的Trainium,两者都已经在Amazon EC2实例上可用。微软的Maia芯片仍在开发之中。
8. 利与弊:TPU vs GPU
每种硬件都有其优点和局限性,在TPU和GPU之间进行选择意味着要了解它们各自的长处和不足之处。
8.1 TPU的优势和权衡
TPU是高度专业化的。它们的设计目的只有一个:加速机器学习工作负载,特别是那些涉及大规模张量操作的工作负载。
它们的主要优势是效率——不仅在性能上,而且在功耗上。对于推理任务尤其如此。像Ironwood这样的新一代处理器在这方面更进一步,通过液冷和定制网络,减少了延迟,提高了数千个芯片的吞吐量。
然而,TPU有其局限性。它们紧密地集成到谷歌的生态系统中,这意味着如果您的堆栈依赖于PyTorch或您想要多云支持,则灵活性有限。对于不熟悉TensorFlow或JAX的团队来说,学习曲线也更陡峭。
8.2 GPU的通用性
另一方面,GPU是计算硬件中的瑞士军刀。无论是在做深度学习、科学模拟、视频渲染,甚至是区块链计算,GPU都可以处理这一切。
它们由一个成熟的生态系统支持——尤其是NVIDIA的CUDA平台——并得到每个主要AI框架的支持。这种灵活性使它们非常适合实验、原型设计和广泛的生产用例。
也就是说,这种通用特性是有代价的。GPU往往会消耗更多的功率,并且可能需要更仔细的调优才能达到与TPU相同的推理效率。
9. 决策指南:应该选择哪一个?
在TPU,GPU和其他自定义AI加速器之间进行选择取决于技术和实际考虑。本节提供了一个结构化的框架,以帮助开发人员、研究人员和决策者基于性能、成本效益、可扩展性和生态系统兼容性来评估最适合他们的AI工作负载。
9.1 模型类型和工作量需求
AI工作负载变化很大——从大规模语言模型训练到推荐系统的高吞吐量推理。以下是硬件通常在哪些任务上表现出色的细分:
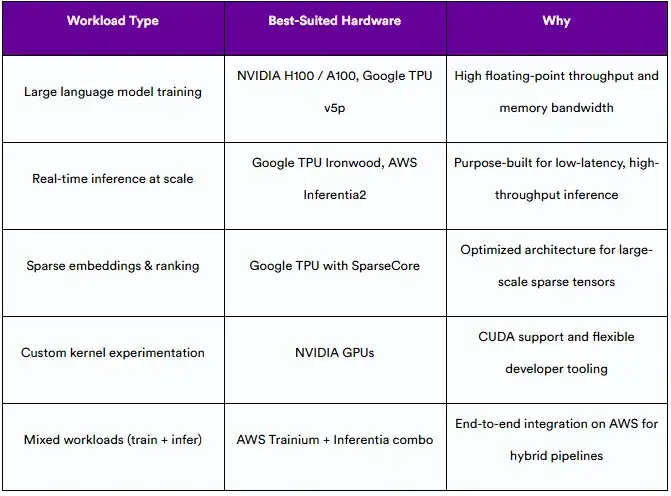
9.2 预算和运营成本
在大规模部署时,价格仍然是最重要的因素之一。以下是我们根据2025年常用加速器的公开定价得出的数据:
估计按需小时定价
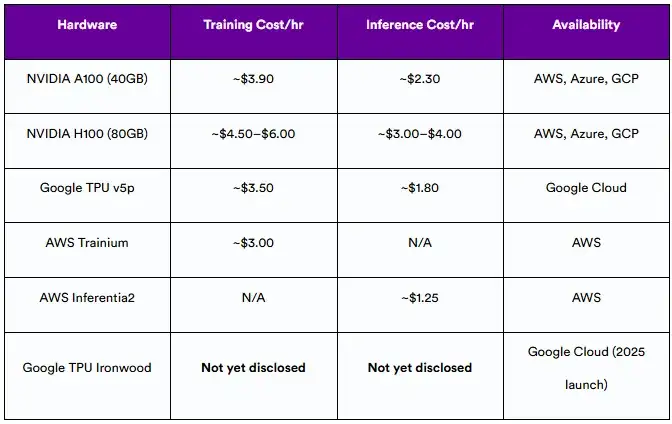
注:谷歌TPU Ironwood的定价尚未正式发布。上述值反映了前几代和同类加速器的公开可用信息。
9.3 可扩展性和可用性
无论是一家尝试新模式的初创公司,还是一家在全球范围内扩展的企业,你都希望评估这些平台在生产环境中的可扩展性。
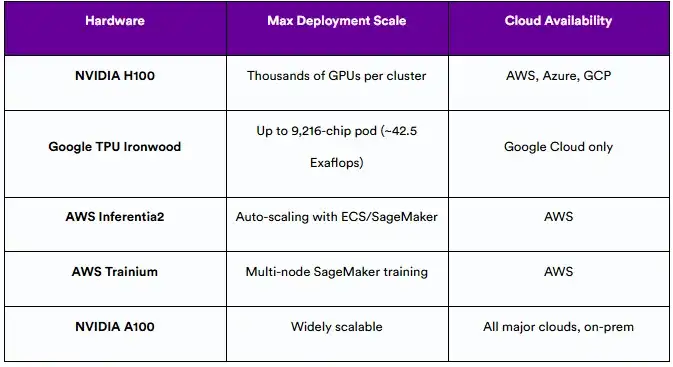
Ironwood引入了新的扩展标准,但其可用性目前仅限于谷歌云基础设施。
9.4 框架兼容性和开发人员体验
与领先的ML框架的兼容性以及是否易于集成到堆栈中是影响开发人员生产力的关键因素。
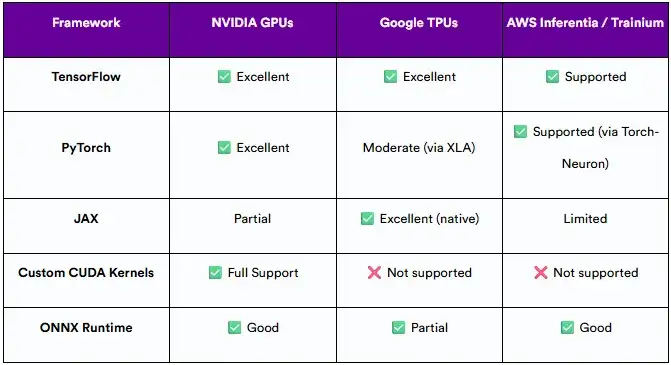
如果在PyTorch上投入了大量资金或需要深度定制,NVIDIA GPU可以提供最广泛的灵活性。另一方面,谷歌TPU在TensorFlow和JAX上大放异彩,特别是在大规模分布式训练方面。
9.5 决策总结
下面是一个快速参考表,根据具体要求总结最佳选择:
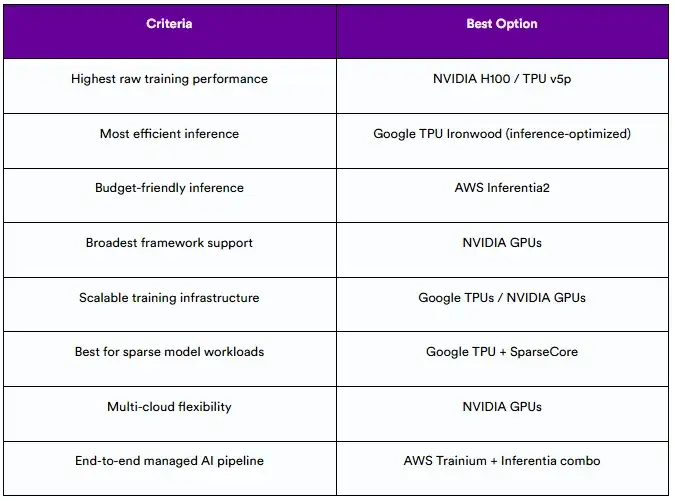
虽然GPU仍然是最通用和最广泛支持的选项,但专用加速器(如TPU Ironwood、AWS interentia和Trainium)为目标工作负载提供了卓越的成本效益和性能,特别是推理和大规模排名任务。
正确的选择最终取决于:
- 模型架构(密集vs稀疏);
- 框架栈(TensorFlow, PyTorch, JAX),
- 训练与推理的预算;
- 需要可扩展性和多区域部署。
在选择之前,强烈建议对实际工作负载进行基准测试,并咨询各自云供应商提供的定价计算器。
10. 展望未来:AI计算的未来
随着AI继续快速发展,为其提供动力的硬件正在经历一场平行的变革。从研究实验室到企业级云环境,AI计算的下一个前沿将由四股主要力量塑造:推理优先设计、多智能体推理系统、定制芯片竞赛,以及建立可持续基础设施的压力。
10.1 以推理为中心的AI的兴起
多年来,AI硬件的重点完全放在训练大规模模型上。但是随着这些模型的成熟并开始为实时用户查询服务,瓶颈已经转向了推理——模型的响应速度和效率。推理优先硬件(如谷歌TPU Ironwood和AWS interentia2)的出现反映了这种转变。
现代推理工作负载需要低延迟响应时间、优化的精度(例如,FP8、INT8)和可扩展的吞吐量。随着通过聊天机器人、搜索和推荐进行的数十亿次日常互动,经济高效的推理正成为云供应商和企业AI用户的核心优先事项。
10.2 多智能体系统与推理
AI的下一个阶段涉及代理系统,而不是单一的整体模型。这些多智能体系统将相互作用、委派任务、协同推理,甚至对自己的输出进行反思。硬件将需要适应这种计算风格——需要更快的互连、高内存带宽和跨分布式环境的实时数据共享。
预计加速器将进一步专门用于以下任务:
- 多模态上下文切换
- Agent编排和调度
- 动态内存管理和跨代理通信
10.3 定制芯片竞赛
虽然英伟达继续在通用AI计算领域处于领先地位,但对特定领域硬件的推动正在加剧。现在,每个云供应商都在构建适合其独特基础设施和AI目标的芯片:
- 谷歌的TPU强调大规模语言模型和密集计算。
- AWS interentia /Trainium专注于可扩展的、节能的推理和训练。
- 微软的Maia芯片正在针对Azure的AI服务进行调整。
苹果、特斯拉、Meta和其他科技巨头也在大力投资定制芯片。
这不再仅仅是速度的问题;它涉及到紧密的软硬件协同设计、与云堆栈的集成,以及从模型训练到实时服务的垂直优化。
10.4 能耗、可持续发展和AI基础设施
AI计算中最紧迫的挑战之一是能耗。今天,训练一个大型基础模型可能会消耗数百兆瓦时的电力。随着AI用例在全球范围内的扩展,基础设施需要变得更环保、更可持续。
未来的硬件将优先考虑:
- 提高了每瓦性能比;
- 先进的液体冷却系统(如TPU Ironwood所使用的);
- 低精度计算效率;
- 模块化数据中心设计,实现能源优化。
原文链接:
https://www.cloudoptimo.com/blog/TPU-vs-GPU-what-is-the-difference-in-2025/
文章来自于“SSDFans”,作者“帅呆”。

【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

