在今年 ICLR 会议上,我们被问到最多且最有意思的问题是:
像 Jina AI 这样的向量搜索模型提供商,除了在 MTEB 上做基准测试,会不会做些氛围测试 (Vibe-testing)?
MTEB 全称是 Massive Text Embedding Benchmark (海量文本向量基准测试),在大量数据集(涵盖 112 种语言)上对文本向量模型进行测试,
包括分类、聚类、信息检索和语义相似性等任务。这是我们在训练向量模型重排器时一个重要的参考标准。
但如同任何的基准测试一样,MTEB 也有一定的局限性:即在面对无标注样本、新领域、新问题时我们无法直接评测。
无论你是否承认,当你拿到一个新的模型时,模型输出的第一直觉和第一印象非常重要,这就涉及到了所谓的氛围测试。
严格来说,氛围测试在人工智能领域中并不是一个新词。
在早期的学术论文中,研究员经常会以 Visual Inspection(肉眼比较), Qualitative Evaluation(定性分析)的方式含蓄的出现,以避免给人草率和随便的印象。
随着去年来 Vibe Coding(氛围编程)的兴起,Vibe Testing 也就大大方方的站了出来。
尤其是大模型、Agent 应用、长文本应用的兴起和迭代,Vibe Testing 变成了最直接最快的测试方式。
谷歌 Gemini Deep Research 的产品经理 Aarush Selvan 在被问及如何测评 Deep Research 的报告质量时,
无奈地提到"深度研究报告的 Entropy 往往太高了所以很难定量评测,我们内部会先做做 Vibe Testing。"
今天,我们和大家分享一款我们内部用于调试可视化向量的小工具:Correlations。
你可以把它看作是 Jina AI 内部的氛围测试工具,我们在定性分析 DeepSearch 和 Late Chunking 时都用到了它。现已在 GitHub 上开源。
Github: https://github.com/jina-ai/correlations

设计
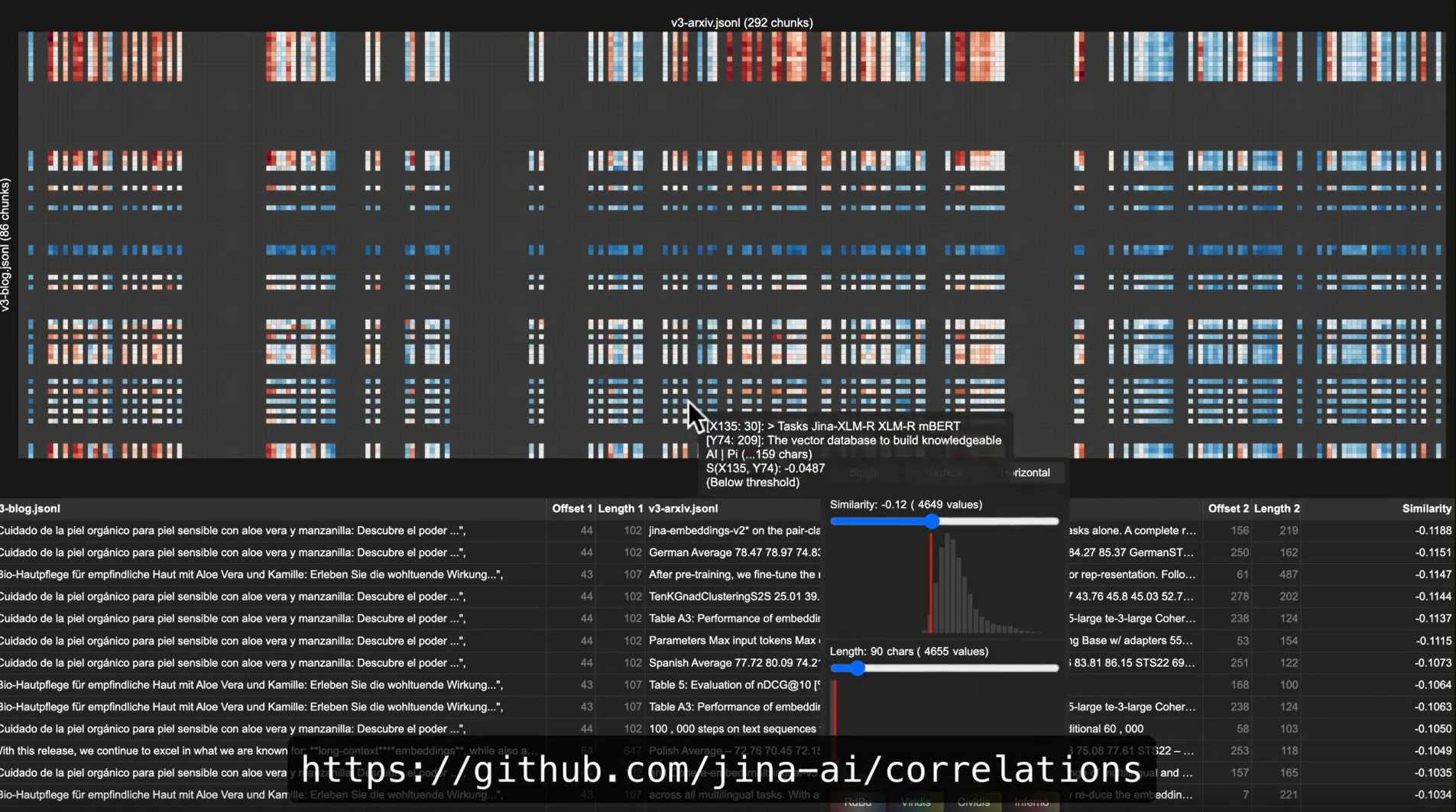
那么,Correlations 究竟是如何工作的呢?其核心在于生成交互式的热图。 在这张热图上,每一个小格子都清晰地展示了任意两段内容之间的余弦相似度。
这些内容片段(chunks)的来源可以非常灵活:它们既可以源自同一个文档集合,也可以来自不同的文档集合;
可以是不同的内容类型(例如文本与图像,即多模态);甚至可以用来比较不同超参数配置或不同模型产生的向量效果。
为了方便用户进行深入分析,Correlations 还提供了多种交互方式:
- 悬停检查:鼠标轻点,即可查看原始内容(文本或图像)及其间的相似度分数。
- 区域选择:框选热图特定区域,可以集中分析局部内容的相似性模式。
- 阈值过滤:根据相似度与文本长度来过滤,用来减少噪声。
这款工具的工作过程分成两个步骤:
第一步:npm run embed
先调用 Jina Embeddings API 生成向量,它提供了多种灵活的内容分块策略,可以按换行符、标点符号、固定字符数,也可以按自定义的正则表达式模式切分输入。
第二步:npm run corr
这一步会在你的浏览器中启动一个用户界面(UI),以动态交互的热图形式直观展示向量间的相关性。
快速上手体验:
npm install
export JINA_API_KEY=your_jina_key_here
npm run embed -- https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model -o v3-blog.jsonl -t retrieval.query
npm run embed -- https://arxiv.org/pdf/2409.10173 -o v3-arxiv.jsonl -t retrieval.passage
npm run corr -- v3-blog.jsonl v3-arxiv.jsonl
JINA_API_KEY 主要是在你需要利用 Jina API 生成向量或从网络链接(URL)读取内容时派上用场。工具本身也完全支持直接读取本地的文本文件。
如果你手头已经有了预先计算好的向量数据(遵循特定的 JSONL 格式),那么完全可以跳过第一步,直接运行 npm run corr 命令进行可视化分析。
这种情况下,自然也就不再需要 JINA_API_KEY 了。
无论是对单一数据集内部的内容进行自相关分析,还是比较两个不同数据集之间的互相关性,Correlations 都能轻松拿捏。
用例
1. 内容去重和对齐分析
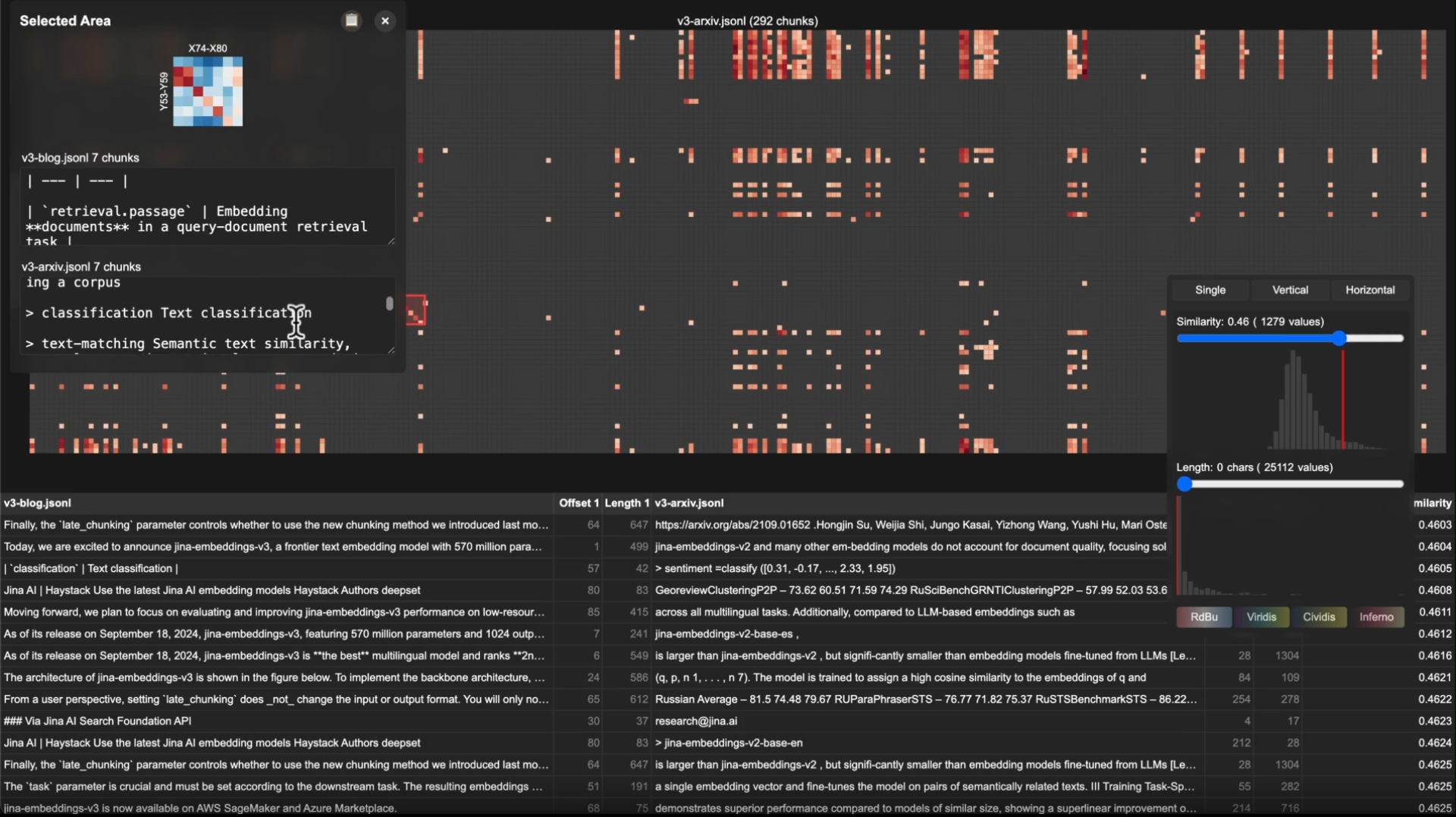
譬如,以我们自家 jina-embeddings-v3 模型的学术论文和对应的官方技术博客为例。通过 Correlations 生成的热图,可以观察到,它呈现出清晰的对角线模式。
这种对角线模式直观地显示了两份文档间内容块的高度对齐,也说明技术章节中存在内容复用,尤其是在描述 LoRA 任务类型的技术部分中。
这种直观的验证,比单纯的数字报告更具说服力。
2. 验证引文和参考文献
在检索增强生成(RAG)系统中,一个绕不开的问题是:如何确保检索到的段落确实支持了模型生成的内容?
Correlations 在这里提供了一种直观的校验方法,它计算并展示检索段落与生成声明之间的相似度,帮助我们判断引文是否准确。
实际上,这种基于相似性的分析方法本身就十分强大且直观,尤其是在探索大规模数据集时。
它能帮助我们把相似的东西归到一起,从而发现数据中隐藏的模式和规律。
3. 分块策略探索
如何对内容进行分块(chunking)是一个很讲究的事情,不同的分割方法(比如是否启用迟分(Late Chunking))会直接影响语义的连贯性。
Correlations 能直观地展示出不同策略下相似性模式的变化,帮助评估和选择更合适的内容块边界,
也让优化分块这件事更有依据,能省去不少反复调试分块策略的功夫。
4. 跨模态分析
现在多模态应用越来越普遍,一个基本的需求就是分析文本和图像之间的关联性。
当配合 jina-clip-v2 这类多模态模型时,Correlations 的能力就不再局限于文本,同样可以处理图像向量。
这样一来,我们就能直观地分析文本与图像间的相关性模式,也为多模态应用提供了一种实用的可视化分析途径。

向量模型可视化相关工作
当我们在处理高维向量时,一个老大难问题,就是它们的可解释性。市面上已经有不少向量模型的可视化技术,各有各的侧重点和适用场景。
这些方法大致可以这么归类:
- 有些是 基于降维的方法:大家可能都熟悉 PCA、t-SNE、UMAP 这些,它们做的事情就是把高维空间“压扁”到我们能直观感受的 2D 或 3D。
- 还有些是 基于交互式探索的方法:比如 Parallax 和 TextEssence 这样的工具,用户可以直接操作和探索数据,自己去发现里面的门道。
- 另外,也有 特定领域的解决方案:像 Clustergrammer,主要针对生物数据这种特定类型的数据。
- 最后一种,就是 直接相似性可视化:Correlations 采用的就是这种思路,通过热图来直接展示。
这种方法的特点是,它力求保留所有内容片段之间的完整成对关系信息。
也就是说,当我们需要细致地调试文本相似性,或者分析不同内容块之间的对齐情况时,Correlations 能提供一个非常直接的视角。
比如当你想知道“这两个具体的东西到底有多像”并且想看到“所有东西两两之间有多像”时,它就派上用场了。
这与那些依赖降维(可能会丢失一些细节信息)或者侧重宏观探索的方法形成了有益的补充。
为了更清晰地了解 Correlations 在整个可视化工具生态中的位置,我们可以看看下面这个表,它列举了一些常见工具及其主要特点和用途:

为何选择直接相似性可视化?
在众多的向量可视化方案中,我们为什么更倾向于直接展示相似性矩阵呢?
目前市面上可视化工具的主要做法是把向量变成一个个的点,然后投射到二维或三维空间里去(比如用 PCA、t-SNE 这些降维方法)。
这样做的好处是能给你一个大概的印象,但它也有个绕不开的局限性,那就是可能会把向量之间两两对应的关键关系信息给弄丢了。
而且,这些工具多数是为分析单个向量空间设计的。
当我们需要比较不同来源、不同内容类型(比如文本和图像),
或者用了不同向量策略(比如有没有开启迟分(Late Chunking)功能)产生的向量效果差异时,它们用起来就不是那么顺手了。
在 Jina AI 的日常工作中,我们就经常碰到要看两组不同向量集合之间关系的情况。
举个例子,在我们的 DeepSearch 产品里,我们得交叉验证报告里的内容和原文段落是不是真的匹配;
或者在做多模态检索的时候,要看看图片和对应的文字描述到底对没对齐。
在这两种情况下,我们都需要探索两个向量集合之间的关系。
Correlations 就派上用场了,它能帮我们直观地感受到匹配的对齐程度,并通过热图上那些高相关性的区域,来验证它们是不是真的对应了语义上正确的匹配。
结论
往小了说,Correlations 就是一个 Vibe testing,图个乐子。
往大了说,我们其实还能从相关矩阵的热图上提取出一些指标,来量化地描述这些内容之间的关系。比如:
- 矩阵密度:在所有内容片段两两之间的相似度里,有多少比例超过了我们设定的某个门槛。它能告诉我们整体的语义内聚性怎么样。
- 特征值分布:通过主成分分析(PCA)这类方法,找出相似性结构里那些最主要的、起主导作用的模式。
- 矩阵秩:指相似性关系中真正有效的维度有多少。它能告诉我们这些关系背后潜在的结构有多复杂,是不是有很多冗余的信息。
- 条件数:这个数值衡量的是计算的稳定性,在基于这些相似度数据做进一步分析时,结果会不会因为一些微小的变化就天差地别。
更进一步地,我们甚至可以尝试从这张大热图里,找出那些最具代表性的“核心语义簇”或“子结构”。
这在数学上对应一个典型的组合优化问题:从一个 n 阶实数矩阵中提取 k 阶最大和主子矩阵。
在我们的应用场景中,就是在相关性矩阵里,找到一个 k 行 k 列的子矩阵,使其内部所有相似度值的总和达到最大。
这种方法能够帮助我们精准定位到数据中最具代表性的语义簇。
总而言之,Correlations 提供了一条从氛围测试到辅助定量分析的完整路径。
我们希望它能帮助开发者和研究者更好地理解、调试和优化他们的向量模型及应用,让大家在探索语义这个复杂空间的时候,能多一个得心应手的工具。
文章来自于微信公众号 “Jina Al”,作者 :Jina Al

【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI

