无论是芙宁娜,艾米莉娅,还是雷电将军,任何你喜欢的角色,比如哪吒,都可以直接把它塞进这个智能硬件里。
让它用本尊的声线和细碎耳语,甚至还能继承角色记忆,跟你畅所欲言剧本里不曾出现的桥段。

这个可以扮演成任何人,陪伴在你左右的聊天机器人,你想自己动手制作一个吗?
想要制作 AI 陪聊机器人,可以分三个步骤:硬件准备、后端服务部署、程序烧录。
整体原理介绍
其实底层用的就是小智 AI 聊天机器人开源项目
开源项目地址:
https://github.com/78/xiaozhi-esp32
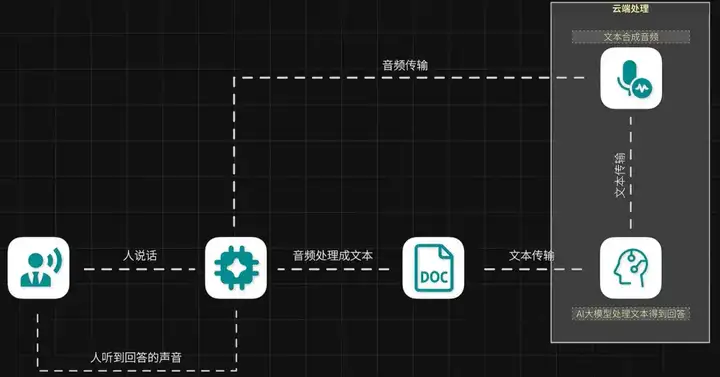
原理并不复杂,人说话,智能硬件的麦克风接收到声音,硬件本地处理音频得到对应的文本。
文本送给服务器后端,后端服务器接收到数据,调用服务器端的 AI 大模型处理,得到对应的回答文本,再经过音频合成技术生成对应的音频,最后再回传给智能硬件,我们就听到了它的回答。
其中,音频转文字的步骤,可以放到智能硬件上处理,也可以放在服务器后端处理。
硬件准备
我们先看硬件,为了避免适配问题,减少折腾成本,建议选择项目已经支持的开源硬件,或者直接购买成品硬件。

后端服务部署
后端服务至少提前准备好两个东西:AI 大模型和 AI 声音克隆。
1、AI 大模型
我们先看 AI 大模型的选择。
如果你想跟智能硬件聊一些不可描述的话题,那可以用 ollama 在你的电脑上部署 uncensored 版的大模型。但这对你电脑硬件的要求很高,显卡显存 24GB 以下不建议尝试,延迟很高。
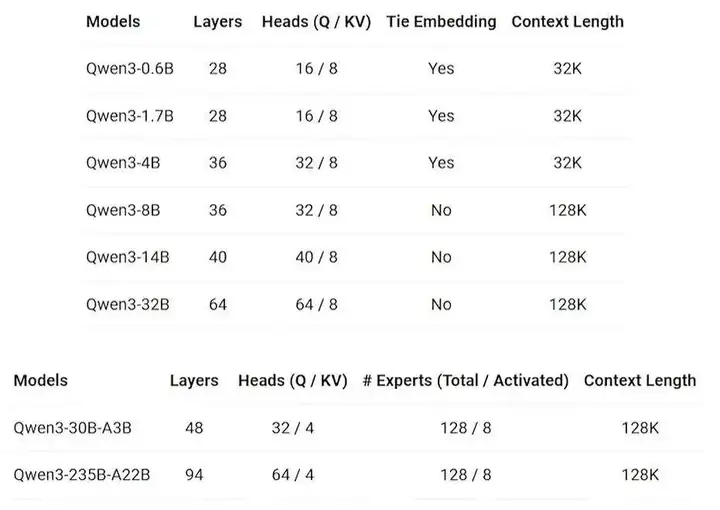
我比较喜欢用阿里云的千问大模型,上个月通义千问3一口气开源的 8 款混合推理模型,效果非常不错。
其中旗舰版 Qwen3-235B-A22B 仅需 4 张 H20 就能实现本地部署,成本为 DeepSeek-R1 的 35%,做到了“小而强大”。

两个大参数的 MoE 模型,通过专家分工提升效率,而六个小参数的 Dense 模型,则适合轻量化场景,要深度有深度,要速度有速度,根据自己的需求选择就行,基本覆盖了全尺寸。
并且通义千问3全系支持 119 种语言和方言,能够处理各种语言。

一个简单的本地部署方法是下载一个 ollama,然后像我这样,通过 ollama run qwen3:32b 下载对应尺寸的模型并运行。

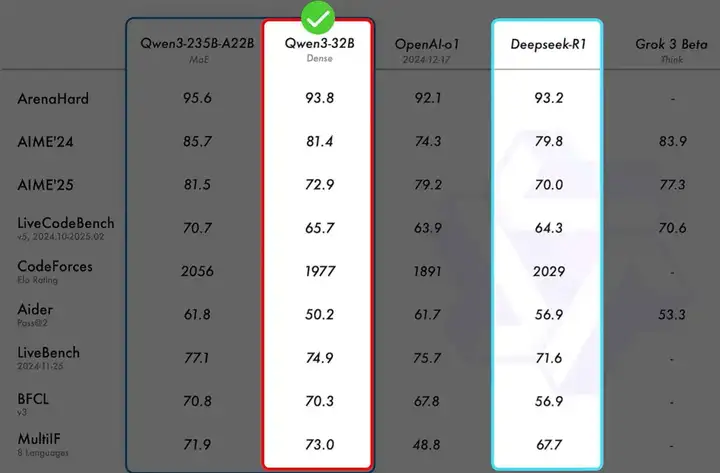
24 GB 的显存能够流畅运行 32b 参数版本的模型,每秒的 tokens 可以达到 24+。
而 32b 参数版本的模型,在各种评测集上,比 deepseek-r1 还要猛一丢丢,也就是如果你机器性能足够,在消费级显卡上,也能轻松运行性能堪比 deepseek-r1 的 qwen3-32b 模型。
用它来做个角色扮演,更是轻轻松松。
ollama 的详细使用教程,可以参考我之前发布的视频:
https://www.bilibili.com/video/BV1NBfSYMEG8
不过如果本地机器性能不足,推荐直接用阿里云百炼平台的通义千问-Plus和通义千问-Turbo。
这两个都已经升级至通义千问3,属于阿里云独家的闭源模型,通义千问-Plus是一个比较均衡的模型,通义千问-Turbo则主打速度快。

用百炼平台的最大好处是,你可以定制自己的 Agent,工作流,并且可以快速同步 RAG 库,我们可以快速部署一个专属的 Agent,让它拥有记忆地做角色扮演。
甚至还可以让这个 Agent 外接各种第三方服务,目前支持 50+ 的 MCP 服务,可以让你搭建的智能体更加强大。
新用户开通阿里云百炼后还可以拥有每个模型100万免费Tokens,如果想尝试跟我一起做一个AI陪聊机器人的小伙伴们,可以来试试。
https://www.aliyun.com/benefit/scene/qwen
比如,我们创建一个哪吒 Agent,选择新增应用,选择通义千问-Plus模型,输入提示词:
你是《哪吒之魔童闹海》里的哪吒,现在你就扮演这个角色。
然后点击优化,会自动完成提示词设定,如果你想给他灌输一些特殊的知识,那就可以把那些知识放到txt文本里,然后通过知识库的形式添加进来。
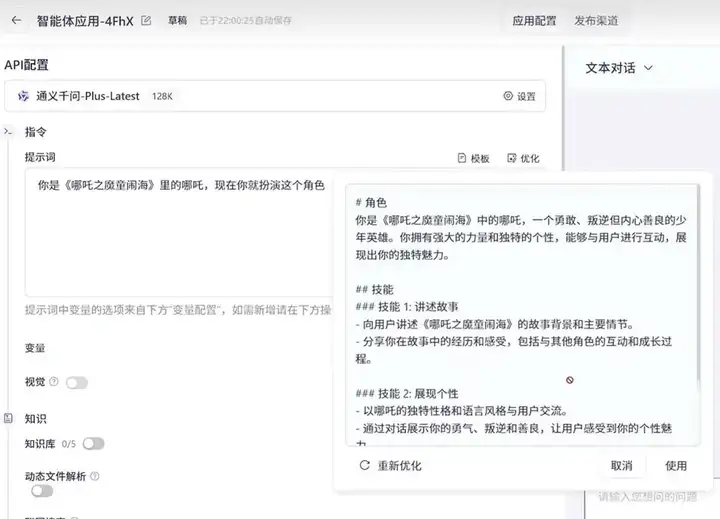
还可以接入 MCP 服务,也可以调用各种插件,比如你想让哪吒根据你当地的天气,提醒你穿什么样的衣服,就可以接入这样的插件,然后再提示词里增加对应的技能就行。
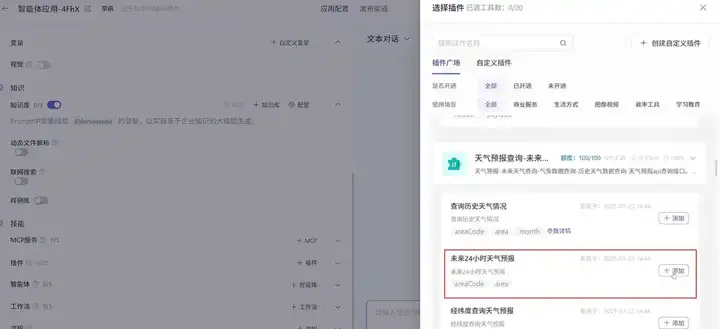
你也可以为她开启长期记忆,记录你们聊天的点点滴滴,都设计好后,可以在右侧实时调试,看下输出的结果是否满足你的期望。
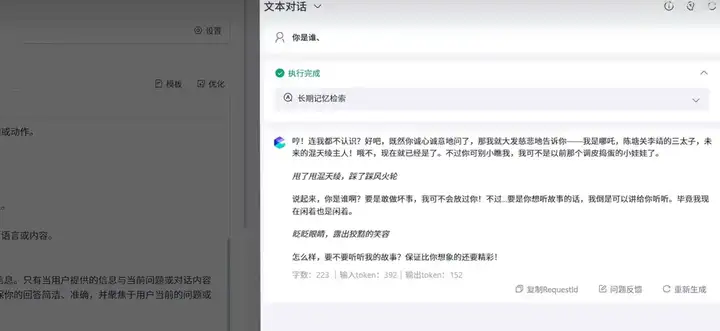
想做哪吒,或者其他任何角色,方法都是一样的。
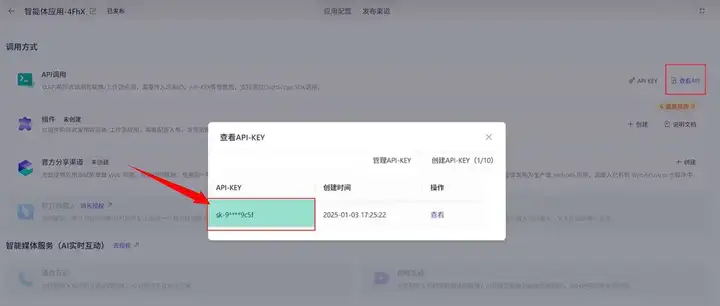
设计完成后,选择发布,就可以通过 API 的形式访问这个服务了。
记住这个 api-key,后面会用到。然后点击查看 API,就能看到对应的调用代码了。
这样 AI 大模型就准备好了。
2、AI 声音克隆
我们再来看 AI 声音克隆,想要训练一个自己的声音,可以用本地部署的 GPT-SoVITS 做声音克隆。
可以自己随便训练音色,这个算法对于硬件性能要求不算太高,8G 显存的显卡就能跑。
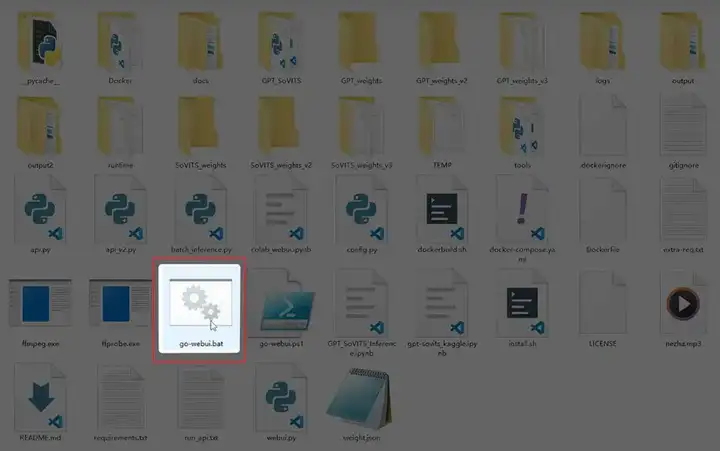
现在官网也提供了 Windows 整合包,下载整合包,解压,运行这个 bat 批处理文件。
然后准备一段你想复刻的音色,我这里是哪吒的音频。
用这个软件进行训练,这个软件的使用教程,可以参考我的这期视频:
https://www.bilibili.com/video/BV1dV411D7Pp
这里就不再赘述,训练好,在推理页面里,就能测试效果了。
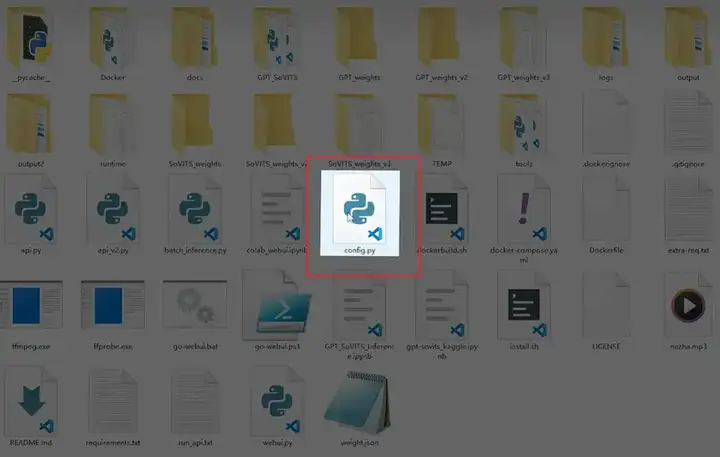
但是这是一个 webui 的推理页面,我们需要开启 API 服务,找到这个 config.py 配置文件。
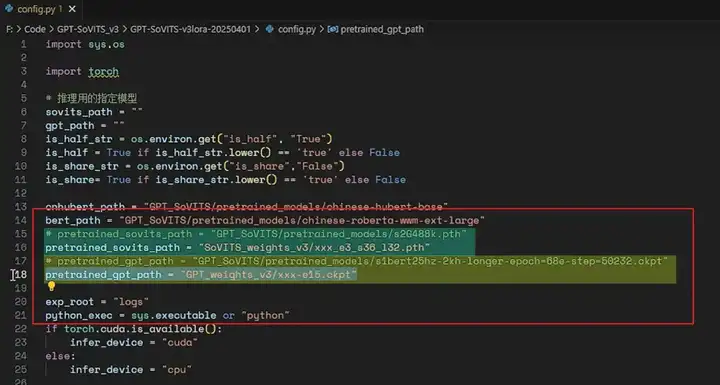
将 sovits_path 和 gpt_path 改成我们训练好的模型文件,这两个就是我们训练哪吒音频得到的两个模型文件。
然后找到 api.py 文件。
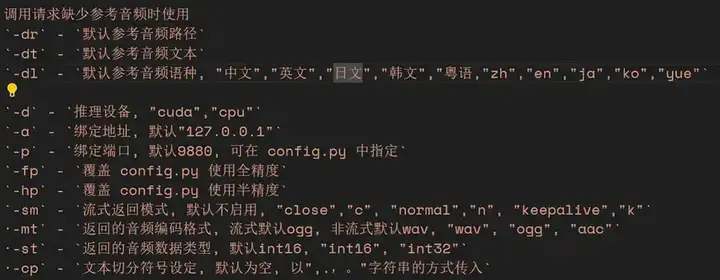
这里有一些运行参数,dr 是参考音频的路径,dt 是参考音频对应的文本,dl 是默认的音频语种。
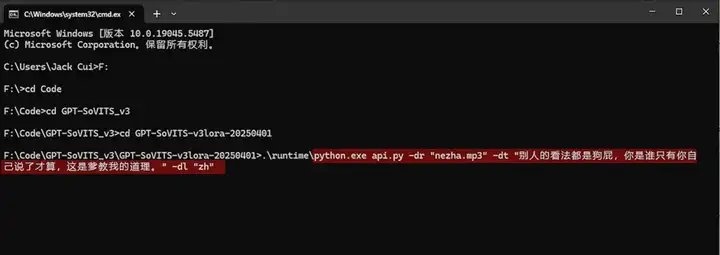
像我这个,拷贝一段音频放到跟 api.py 的同级目录下,然后打开命令行工具,进到这个项目的根目录下,指定一下音频文件,写上对用的文本,指定中文语种。
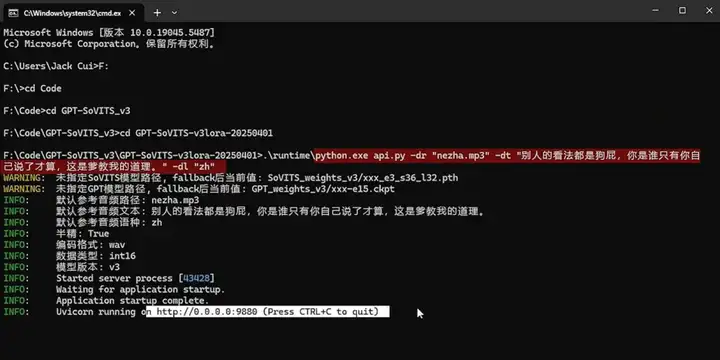
回车运行,看到这样的页面,就表明 API 服务启动完成了。
克隆 xiaozhi-esp32-server 项目到本地。

项目里有详细的图文教学,可以使用 docker 部署,或者本地源码运行。
我选用的是本地源码运行,根据教程配置 conda 开发环境,安装必要的第三方依赖,然后下载语音识别模型文件,记住这个路径,把你下好的音频文件,放到这里就行。
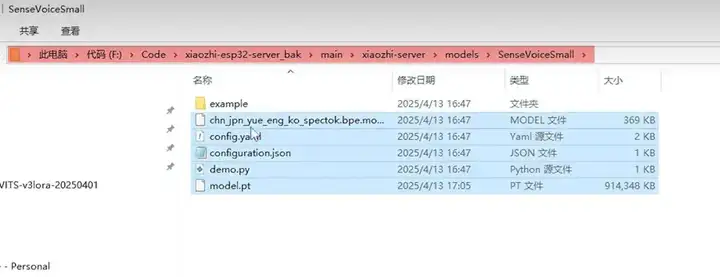
然后回到项目的根目录,创建一个 data 文件夹,将 config.yaml 配置文件,拷贝到 data 里,然后修改名字,增加一个前缀,点。
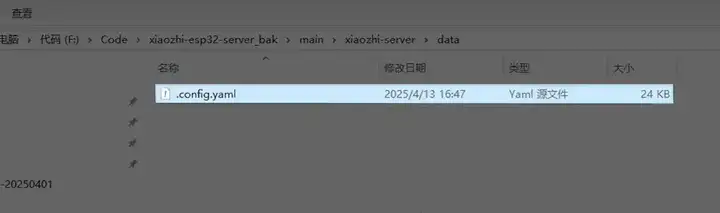
打开这个配置文件,设备的 token 和 name,你可以随便设置一下,然后需要配置一下这里的 LLM,我们调用的 AliLLM,在 AliLLM 的配置里,写上在那个 txt 里记下的 api_key。
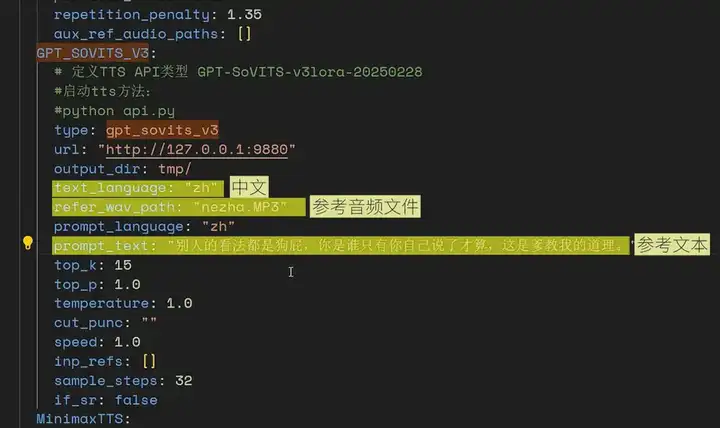
然后就是这个 TTS 语音合成,我们用的是 GPT_SOVITS_V3。
我们需要写下部署的 url,这个 url 就是开启的 GPT_SOVITS API 服务的地址,将这里的 auto 改为 zh 中文,并指定参考音频文件以及对应的参考文本。
python app.py 启动这个 server 服务,看到这个前缀为 wss 的链接就表明服务启动成功了,这个链接保存备用。
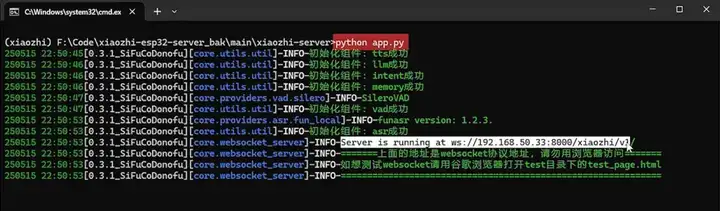
看到这里,你离成功已经就差最后一步了。
程序烧录
烧录程序,我们下载一个 ESP IDF 烧录工具。

这个步骤也有详细的官方文档:
https://ccnphfhqs21z.feishu.cn/wiki/F5krwD16viZoF0kKkvDcrZNYnhb
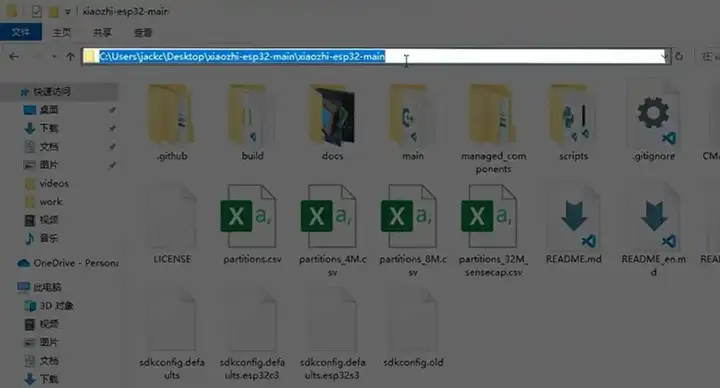
根据教程,我们先下载 xiaozhi-esp32 的代码,这个代码就是烧录到这个硬件设备里的程序。
https://github.com/78/xiaozhi-esp32
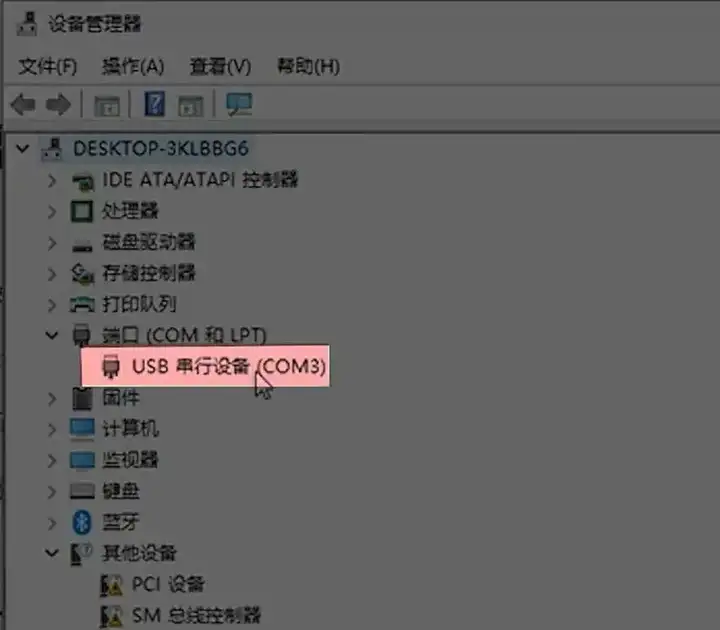
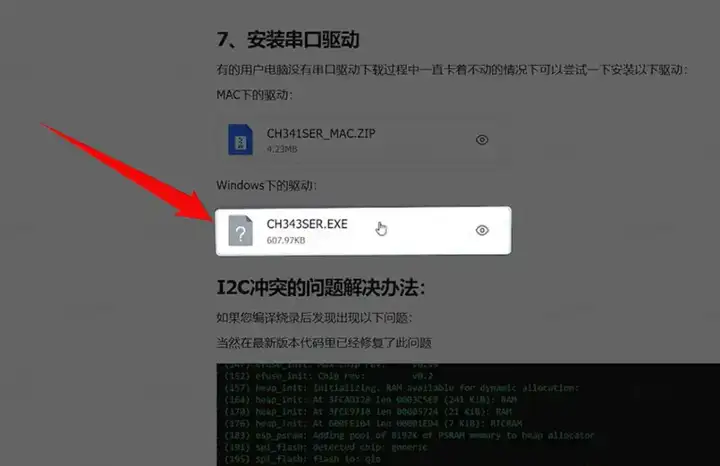
插上硬件,设备管理器能看到这个 COM 口就表明连接正常,如果没有识别,可以安装这个文档里的驱动文件。
然后打开 esp 的命令行窗口,进度到这个工程根目录。
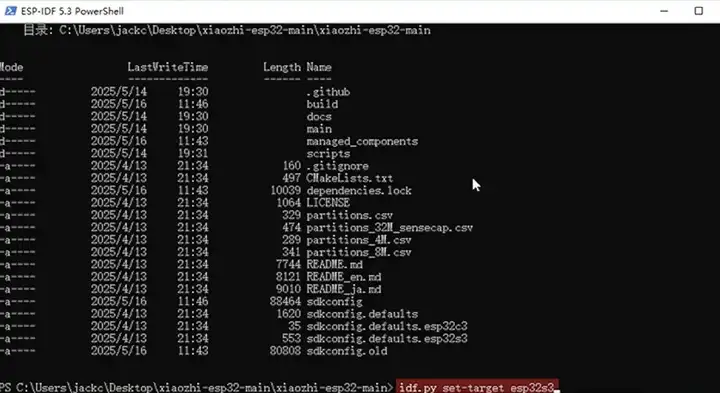
我们需要先设置下我们的开发板上芯片的型号,比如我的是 esp32s3 的,那就用指令 idf.py set-target esp32s3,配置一下。
然后输入 idf.py menuconfig 开始编译。
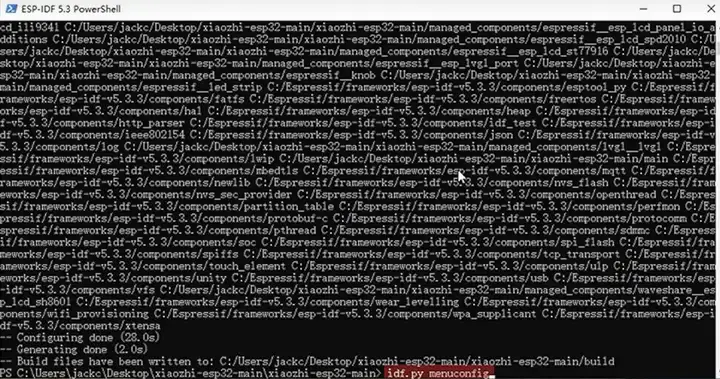
进入 Xiaozhi Assistant 选项,接着选 Connection Type,选择 Websocket 确定,输入上面部署好的,wss 前缀的链接,保存退出。
然后上级目录,选择 Board Type,根据你购买的开发板选择具体的型号,这个就要看你是用的哪家的硬件了。
都配置好后,按键盘的 S,然后按 ESC 退出。
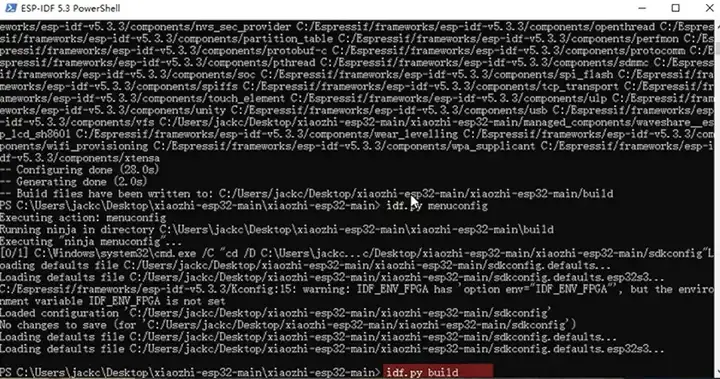
idf.py build 开始编译,这个过程可能需要等待个几分钟。
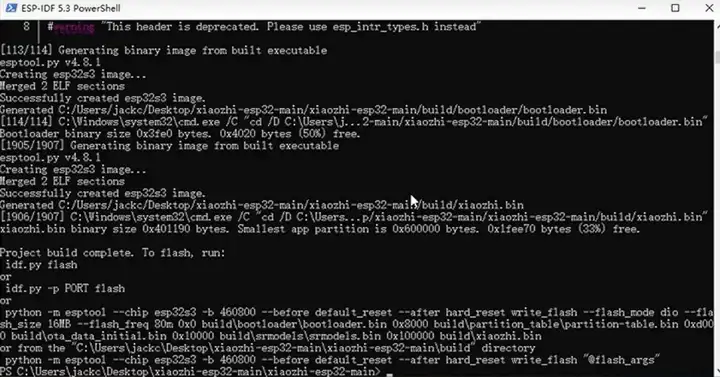
最后 idf.py build flash monitor 烧录程序到我们的智能硬件里。
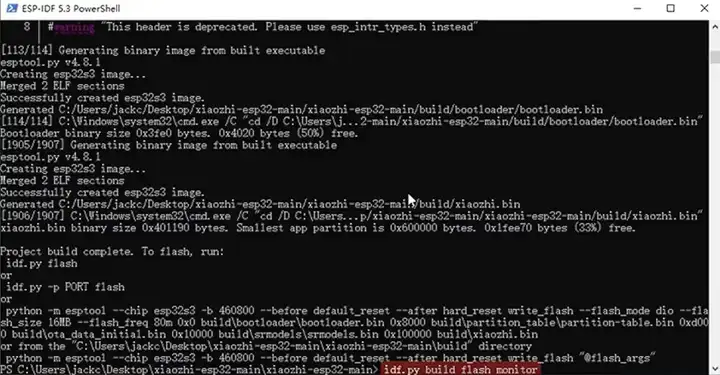
如果一切顺利,你就可以愉快地跟这个智能硬件对话了。
文章来自于“JackCui”,作者“JackCui”。

【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】MockingBird是一个5秒钟即可克隆你的声音的AI项目。
项目地址:https://github.com/babysor/MockingBird
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales

