hi 家人们,端午假期开心嘛!
除了休息工作,这次假期,我还和一位好久不见的老朋友约了一个聊天局。
先说下这位朋友的情况,00 后,清华博士,创业公司第一年就跑出千万年营收。
我们约的见面时间是下午一点半,一直聊到五点,从当前特别火的 Agent 聊到底座模型能力,从产品应用聊到算力 Infra,从团队管理聊到招人经验...
虽然创业做的事情方向不同,但是聊到最后,我俩简直是一拍即合,找到了无数相同的槽点和泪点。
特别感同身受的是,身为公司的 1 号位角色,对外看着是光鲜亮丽,但实际上每天眼睛一睁,就是铺天盖地的和各个线条对接,什么都得操心,还得在无数个不确定性中做出最关键的决策,错了可能就万劫不复。
更别提那永远悬在头上的“钱”字,融资、现金流,哪一样不让人焦虑。聊到“钱”这个话题,他和我说:
“你猜国内现在哪些 AI 应用真正在赚钱?”
和他聊了很多行业“内幕”后,我总结了一下:
不是那些听起来高大上、动辄改变世界的 AI 大模型应用,反而是那些扎根在细分场景、看起来不那么起眼,但实实在在解决用户某个小痛点,能快速产生现金流的“小生意”。
我好奇地问:“你怎么知道的?”
他笑着说:“因为这些应用,很多都跑在我们平台上。 我们的目标就是服务搞AI创新的人,尤其是那些有想法的小团队和个人开发者,不能让他们因为算力和运维喘不动气。”
聊了之后我发现,为啥人家能做出来千万的营收,是真真戳中了现在 AI 应用落地的一个大痛点——算力,而且解决方案还很巧妙。不只有便宜,还有同为创业者的感同深受。
“创业之初我们就认为,算力是托起创新的基石、斧子,不是拦路虎,所以我们一直在做一个真正普惠、易用的GPU算力基座,让创新者把精力放在产品和用户上。”
所以这篇文章,我决定聊聊他们的产品。
现在各种开源模型、低代码平台这么多,AI 应用的门槛其实在降低。很多个人开发者或者小团队,都能快速搞出一些有意思、能解决实际问题的 AI 应用。
但是,最大、也是最怕的问题就是算力成本和运维问题。
具体来说,我这朋友他们做的产品,是一个专门给 AI 推理场景用的GPU Serverless 平台,尤其适合 AI 初创公司、小型开发团队、一人 AI 团队。
先放传送门:
suanli.cn
第一个问题,什么是 Serverless?
理解这个问题之前,得搞明白以前“非 Serverless”的平台是怎么搞 AI 推理的?
- 第一种,自己买卡,自己组装服务器,自己装系统、配驱动、搭环境、写代码。这种属于土豪玩家,有钱又有团队。
- 第二种, 从阿里云、腾讯云这些云厂商那儿按月或按年租带 GPU 的虚拟机,虽然不用买硬件了,但是服务器的管理、应用部署还得自己来,想租到又便宜、又稳定、又能弹性扩缩的卡几乎不可能。
Serverless,你可以把它想象成用“共享充电宝”,需要时扫码借一个,用完插回去,用多少,付多少。
你只需要把你的 AI 模型代码(打包成 Docker 镜像)往平台上一扔,选择好用几块卡,就能跑起来了。
“那这不就是国外的 Runpod 吗?” 我当时就想到了这个。
Runpod 在国外 AI 圈子里挺火的,它提供了 Serverless GPU 的服务模式,让很多独立开发者和小型团队能用上便宜又弹性的 GPU 资源。但因为是国外的平台,网络、支付、技术支持这些,对国内用户来说还是有些不方便。
而他们就是在做“中国的 Runpod”,只不过,做的更适合国内开发者。
第二个问题,为啥是他们解决了 AI 推理算力的痛点问题?
首先是开发者最关心的问题——价格。
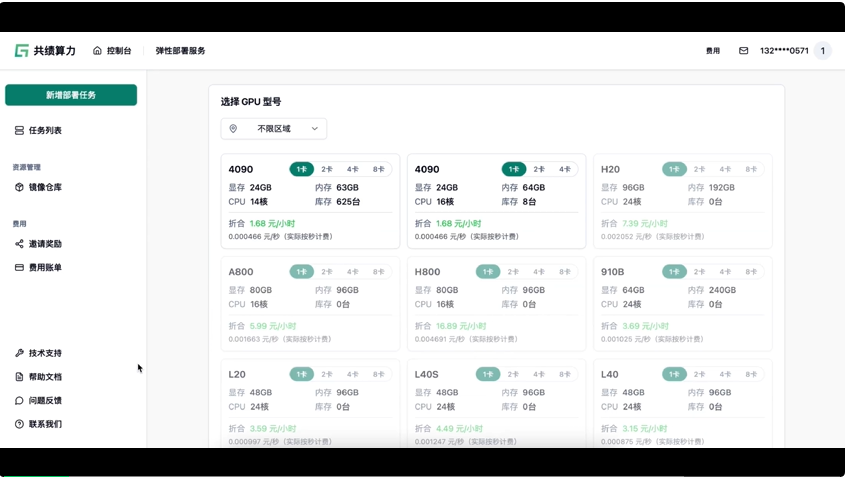
GPU 价格贵,还常常没好卡,特别是像 4090 这种明星卡,要不就是一卡难求,要么太贵了,项目还没开始赚钱,就已经被成本劝退了。
但是在他们平台上,4090 单卡推理最高才 1.68 元/小时,这价格是目前市面上我见过最便宜的。(PS:他们产品的海报真的好抽象 hh)
看一个更直观的价格对比——
聊到这里我就好奇了,现在 4090 这么紧俏,你们怎么能保证有卡呢?他解释说,他们家最核心的其实是一套自研的“闲时算力智能调度平台”。
这套系统特别牛,它能把金山云、火山引擎等等国内 26 多家智算平台、甚至是个人手里的闲置算力都整合起来。
所以不止便宜,还资源管饱!
然后是部署超级简单,几乎 0 成本运维。
他们把所有 AI 模型都容器化了(支持 Docker),你只需要把你的模型打包成 Docker 镜像,往他们平台一扔,两步操作就能搞定,然后就可以直接提供在线推理服务了。
第一步:选择 GPU;
第二步:提供镜像地址,或者是选择平台上提供的现成可以直接玩的镜像;
第三步:点击部署服务即可。
我自己跑了一下,不到 1 分钟就拉起一个图生视频的服务。
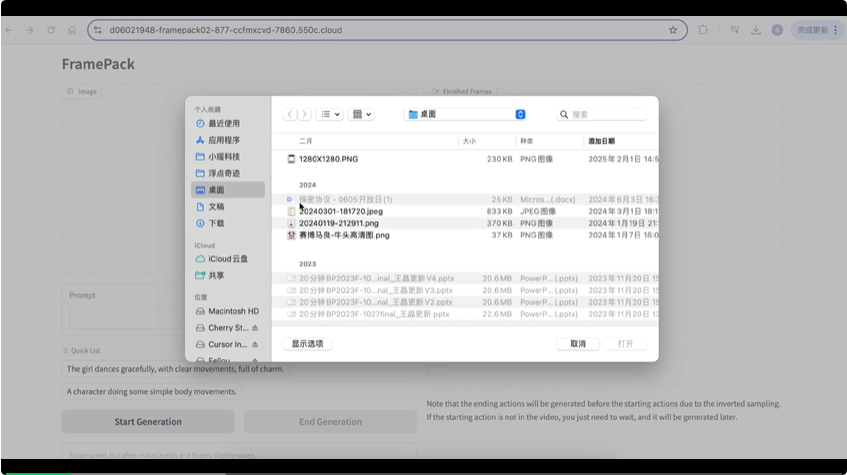
我当时就觉得,这简直是解放生产力啊,终于可以把宝贵的精力用到模型和业务上了!
最后一点是弹性!弹性!还是 TMD 弹性!
比如你的 AI 应用,白天用户多,晚上没人用,或者突然来了个大流量活动。你如果提前租一堆 GPU,那波峰的时候可能不够用,用户卡顿流失;波谷的时候呢,又浪费大把钱,看着闲置的 GPU 心疼肉疼。
在他们平台上,你不用预估流量,不用提前租卡。比如当你的 AI 应用请求增加时,只要在页面上点一下,增加到两个节点,就能秒级拉起新服务,按秒级计费。流量回落了,同样也能秒级释放。完全不用操心后台的扩缩容和资源管理。
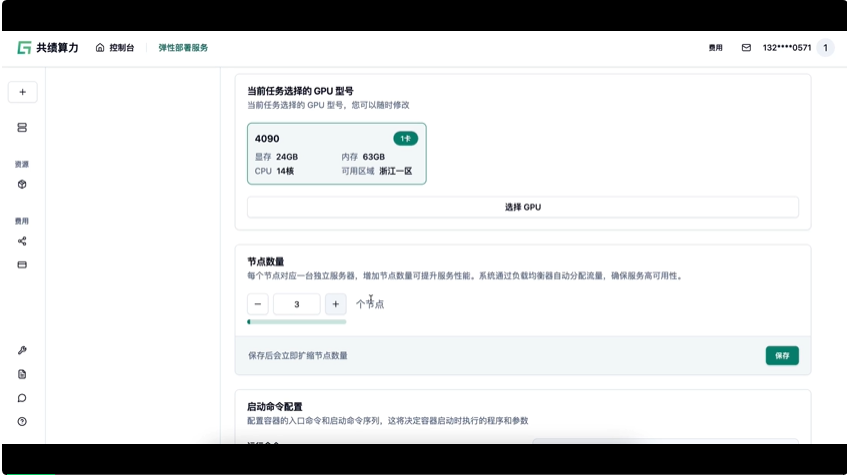
另外,服务启动/停止、扩容/缩容等操作,都支持了 API 脚本控制,在本地写一个 python 或者 Linux 脚本,批量操作所有任务,不必要上平台手动点击,也是相当方便。
算力场景下,有一个不可能三角, "弹性、稳定、低价"。
- 弹性:根据需求快速增加或减少算力,就像弹性橡皮筋一样,灵活应对不同的负载。
- 稳定:算力供应可靠,保持连续和不断稳定的运行,不会频繁中断。
- 低价:用户可以用更少的钱获得弹性& 稳定的 GPU。
想要稳定,你需要长期锁定资源,租金就不会便宜;
想要弹性,随用随停,还要保证稳定,价格也会上去了。
他们做这个平台,就是想打破这个“魔咒”。让 AI 推理的算力真正做到“弹性、稳定、低价”,这在以前,基本是个“不可能三角”。
共绩算力(suanli.cn)这样的 Serverless GPU 平台,它也不是说能完美地让三者都达到极致(那真是神仙了),但它通过技术创新(智能调度闲置算力)和模式创新(Serverless 按需付费),努力找一个平衡点,给开发者一个性价比更高、更省心的选择,尤其是在 AI 推理这种对弹性、成本、效率都有很高要求的场景下。
在 AI 应用爆发的这个鼓点上,他们真的有在解决那些敏捷迭代的小型 AI 团队,最头疼的推理算力问题。
总的来说,如果你也有 AI 推理服务的算力需求:
- 成本低到感人
- 弹性好到想哭
- 部署简单到起飞
- 运维省心到可以摸鱼(开玩笑)
那我觉得,共绩算力(suanli.cn)这个平台,你真的可以去了解一下。
(悄咪咪: 这几天还有羊毛可以薅)
文章来自于“夕小瑶科技说”,作者“夕小瑶编辑部”。

【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md

