一项新的强化学习方法,直接让Qwen性能大增,GPT-4o被赶超!
来自加拿大滑铁卢大学与TikTok新加坡,M-A-P的华人团队提出了一种全新训练框架:General-Reasoner。
结果直接让Qwen系列大模型的跨领域推理准确率提升近10%,在多个基准测试中甚至超越GPT-4o。
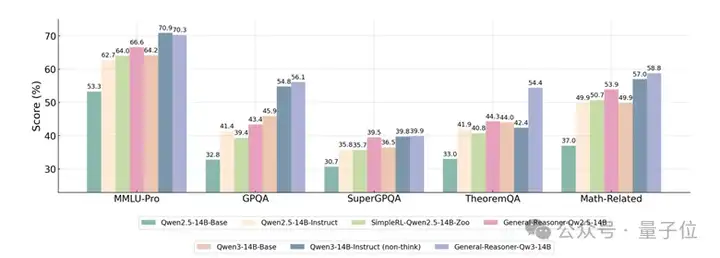
上图显示出General-Reasoner在多项跨领域评测中显著提升基础模型推理能力。
当前,强化学习(RL)被视为提升模型推理能力的关键手段。其中,Zero-RL方法通过直接训练基础模型,已在数学和编程等结构化任务上展现出强大效果。
问题是,这些方法往往局限于数据丰富、答案结构清晰的领域,在面对物理、金融或人文社科等更广泛的领域时,模型难以有效泛化。
接下来看看研究团队是如何解决这些推理难题的?
相较现有方法的关键革新
目前的Zero-RL框架如SimpleRL通常聚焦于单一领域数据,采用简单的规则式答案验证,存在以下不足:
- 数据单一多为数学竞赛或代码任务,泛化能力有限;
- 验证方式僵化仅能识别明确结构化答案,无法灵活处理多样化的答案表述。
针对这些问题,General-Reasoner提出两个核心创新:
全领域推理数据集(WebInstruct-verified)
通过大规模网络爬取与严格筛选,创建了覆盖物理、化学、金融等多个领域约23万个高质量、可验证的推理问题。
为了支持更广泛的跨领域推理能力,研究团队构建了一个大规模、多样且高质量的可验证推理任务数据集。
数据最初来源于WebInstruct,其中包含约500万个从StackExchange和教育门户网站爬取的自然指令。这些数据虽然适用于一般的指令调优,但大部分缺乏可验证答案或推理结构。
研究人员追溯数据源网页提取问题-答案对,并剔除没有明确人类答案的问题以确保质量。
随后利用Gemini-1.5-Pro识别具有简洁答案的可验证问题,获得100万个候选问题。再通过Gemini-2.0-Flash进行元数据标注,并适当减少简单的数学问题以保持数据平衡。
进一步质量筛选时,研究人员使用Gemini-2.0-Flash生成8个候选答案:
- 剔除所有8个候选答案均错误的问题(模糊或噪声);
- 剔除所有8个候选答案均正确的问题(过于简单)。
最终的高质量示例用于训练此框架的模型验证器。
生成的数据集涵盖约23万道具有不同答案格式和主题的推理问题。
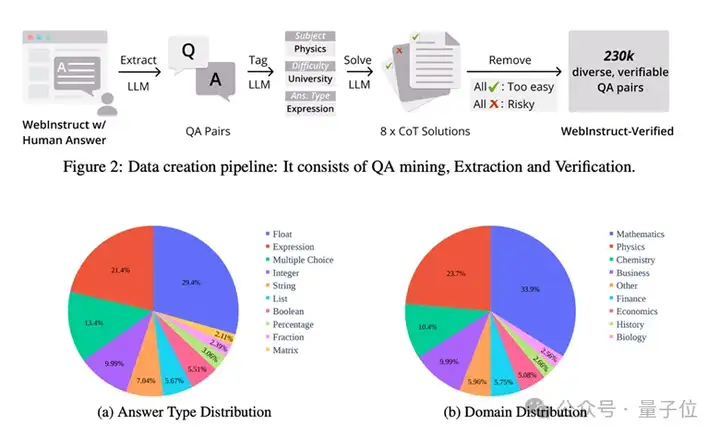
上图为WebInstruct-Verified数据生成过程以及最终答案种类和学科种类的分布
生成式答案验证器(General-Verifier)
以仅有1.5B参数的小型生成式模型,取代传统规则式验证,大幅提高了不同领域答案的验证准确率。
传统的规则式验证器通常依赖严格匹配或符号比较进行答案判定,虽然适合数学任务,但在更广泛的推理领域存在明显不足,如匹配规则僵化,缺乏语义理解,难以适应复杂领域。
为克服这些局限,研究人员开发了一个紧凑的生成式模型验证器(General-Verifier)。此模型以仅1.5B参数,通过团队自建的数据集从Qwen2.5-Math-1.5B模型微调而成。
General-Verifier接收问题、标准答案和模型生成的答案后,生成一个推理过程,随后输出一个二元(对/错)判定结果,为强化学习提供准确且可解释的反馈信号。
实测显示,这种新型验证器与Gemini-2.0-Flash高度一致,并显著超越传统规则式方法,具有更高的鲁棒性与泛化能力。
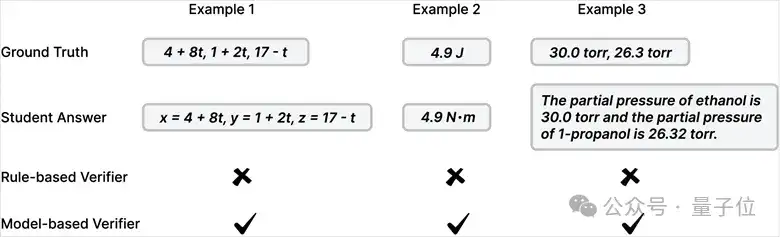
△传统规则式答案验证与生成式模型验证的比较
性能实测
团队以Qwen2.5/Qwen3系列模型(4B/7B/14B)为基础,进行了包括MMLU-Pro、GPQA、SuperGPQA、TheoremQA等12个基准测试,结果表明:
- 在跨领域任务中,General-Reasoner相比基础模型提升约10%。例如,基于Qwen2.5-7B-Base的General-Reasoner在MMLU-Pro的准确率达到58.9%,高于基础模型(47.7%)和指令模型(57.0%);
- 在数学推理任务中,表现略优于专业的数学强化学习框架SimpleRL;
- 最优模型General-Reasoner-Qw3-14B在多个基准测试中可匹敌甚至超越GPT-4o。例如,General-Reasoner-Qwen3-14B在GPQA任务中的准确率达56.1%,在TheoremQA任务中达54.4%,均超越GPT-4o。
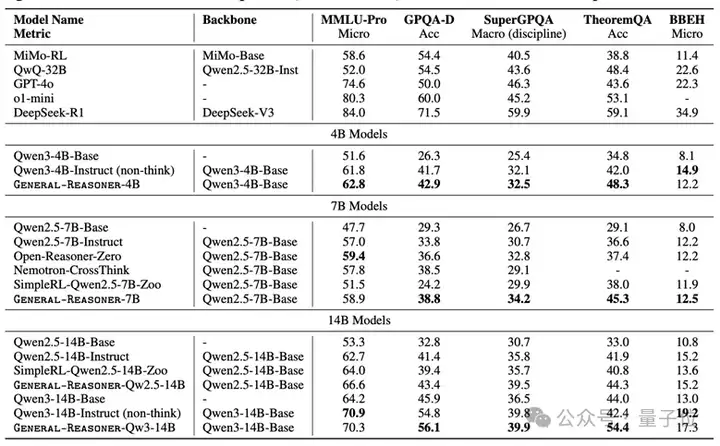
上表为General-Reasoner与基准方法在MMLU-Pro,GPQA,SuperGPQA,TheoremQA和BBEH测试集上的详细比较。
未来展望
研究团队表示,将继续优化模型性能,扩展更多领域的高质量推理数据,并持续提升验证器鲁棒性,推动大语言模型在更复杂现实任务中的广泛应用。
相关论文与项目资源已公开发布,感兴趣的读者可进一步探索。
论文链接:https://arxiv.org/abs/2505.14652
资源链接:https://tiger-ai-lab.github.io/General-Reasoner/
文章来自于“量子位”,作者“General-Reasoner团队”。

【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner


