想训练属于自己的高性能推理模型,却被同步强化学习(RL)框架的低效率和高门槛劝退?AReaL 全面升级,更快,更强,更好用!
来自清华大学交叉信息院和蚂蚁技术研究院的联合团队,正式开源全异步强化学习训练系统 —— AReaL-boba² (AReaL v0.3)。
作为 AReaL 里程碑版本 AReaL-boba 的重磅升级,AReaL-boba² (正式全名:A-ReaL-double-boba) 坚持 boba 系列 “全面开源、极速训练、深度可定制” 的开发理念,再次加量:除了更全的功能和更详细的文档说明,更以全异步 RL 为核心,发布 SOTA 代码模型,全面奔向 Agentic RL:
- 🚀 效率再突破: 全面实现异步 RL 训练,完全解耦模型生成与训练,效果不变的前提下训练速度对比上一版本最高提升 2.77 倍,GPU 资源利用率大幅优化。
- 📚 上手零门槛: 新增详细教程 (Step-by-Step Tutorials) 和深度文档 (Comprehensive Documentation),覆盖安装、核心概念、算法 / 模型定制化到问题排查,新手友好,老手高效。
- 🏆 代码任务新 SOTA 诞生! 基于 Qwen3 系列模型 RL 训练,8B/14B 模型在 LiveCodeBench, Codeforce, Codecontest 等 benchmark 上达到 SOTA 水准!
- 🤖 Agentic RL 支持 :原生支持多轮智能体强化学习 (Multi-Turn Agentic RL) 训练,拥抱 Agentic RL 浪潮。
- 🎁 开箱即用:开源代码、数据集、脚本及 SOTA 级模型权重。
异步强化学习(Asynchronous RL)是一种重要的 RL 范式,它将数据生成与模型训练完全解耦,以不间断的流式生成和并行训练,极大提高了资源使用率,天然适用于多轮次交互的 Agent 场景。
AReaL-boba² 通过强化学习算法和训练系统的共同设计(co-design),在完全不影响模型效果的同时,实现了稳定高效的异步 RL 训练,不断朝全面支持 Agentic AI 的最终目标冲刺。
本次 AReaL 升级为用户提供更完善的使用教程,涵盖详细的代码框架解析、无需修改底层代码即可自定义数据集/算法/Agent 逻辑的完整指南,以及高度简化的环境配置与实验启动流程,如果你想要快速微调推理模型,快试试双倍加量的 AReaL-boba² 吧!
- 🚀 立即体验 AReaL-boba² :https://github.com/inclusionAI/AReaL/ (包含教程/文档/代码)
- 🤖 下载 SOTA 代码推理模型:https://huggingface.co/collections/inclusionAI/areal-boba-2-683f0e819ccb7bb2e1b2f2d5
- 📄 AReaL 技术论文: https://arxiv.org/pdf/2505.24298
- 🔗 AReaL-boba 回顾: 200 美金,人人可手搓 QwQ,清华、蚂蚁开源极速 RL 框架 AReaL-boba
最强最快 coding RL 训练
AReaL-boba² 基于最新的 Qwen3 系列模型,针对 8B 和 14B 尺寸进行 coding RL 训练,并在评测代码能力的榜单 LiveCodeBench v5 (LCB),Codeforce (CF) 以及 Codecontests (CC) 上取得了开源 SOTA 的成绩。
其中,基于部分内部数据的最强模型 AReaL-boba²-14B 在 LCB 榜单上取得了 69.1 分,CF rating 达到 2044,CC 取得 46.2 分,大幅刷新 SOTA。
此外,AReaL 团队还基于开源数据集发布了完全开源可复现的 AReaL-boba²-Open 系列模型,同样能在 8B 和 14B 尺寸上大幅超过现有基线。
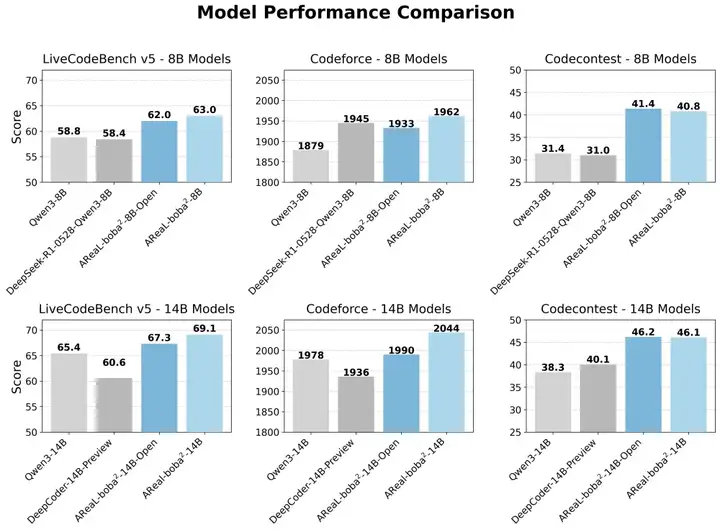
Table 1: AReaL-boba²-8B/14B 在 LiveCodeBench, Codeforce, Codecontest 等 benchmark 上达到同尺寸 SOTA 水准。
AReaL 团队还在数学任务上进行了异步 RL 训练的扩展性分析(scaling analysis):针对不同模型尺寸(1.5B,7B,32B)以及不同 GPU 数量,基于异步 RL 的 AReaL-boba² 系统的训练效率都大幅超过了采用传统同步 RL 的训练系统。相比于共卡模式,AReaL-boba² 所采用的分卡模式显存碎片更少,在更大模型尺寸下(32B)依然能够保持良好的扩展性。
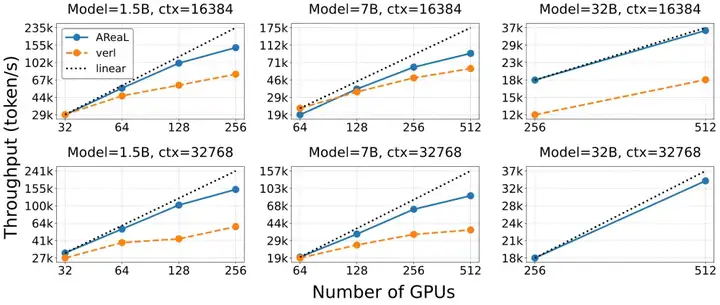
Fig. 1 异步 RL(蓝色,AReaL 系统)和同步 RL(橘红色,采用 verl 系统的官方实现)的训练效率对比。采用异步 RL 的 AReaL 系统的训练吞吐在不同模型尺寸(1.5B, 7B, 32B)下都有着更好的 GPU 扩展性(scaling)。
为何需要异步 RL 训练?同步 RL 痛点剖析
在传统同步 RL 训练流程中,算法采用当前模型产生批量的输出(batch output),然后用收集的输出对当前模型计算损失函数并更新参数。同步 RL 训练中每一个批次(batch)的数据都是由同一个模型版本产生,因此模型参数更新需要等待批次中数据全部生成完成才能启动(Fig 2 左图)。由于推理模型的输出长短差异极大,在同样的批大小(batch size)下,RL 训练必须等待批次中最长的输出生成完才能继续进行训练,以及进行下一个批次的数据收集,造成极大 GPU 资源浪费。

Fig. 2 左图(示意图):同步 RL 训练的计算过程,同批次输出(蓝色)需要等待最长的输出生成完成,存在大量 GPU 空闲;右图(示意图):采用 1 步重叠(1-step overlap)的 RL 训练计算过程,单步模型训练与单批次数据收集同时进行。同批次内依然存在大量 GPU 空闲。
上图展示了几种常见的 RL 训练数据流。
左图为传统共卡同步 RL 系统计算模式,即 RL 生成和训练阶段分别使用全部 GPU 交替进行。由于训练任务需要完全等待生成完成,而生成阶段所花费的时间取决于最长的输出所完成时间,很容易造成 GPU 空闲。
右图为 1-step Overlap RL,是一种同步 RL 的常见改进,由 DeepCoder 和 INTELLECT-2 项目采用。Overlap RL 采用分卡模式,收集一批次输出的同时在不同的 GPU 上进行模型训练,平衡了生成和训练所需要的计算资源并避免了切换成本。但是,在 Overlap RL 系统中,每一个批次的训练数据依然要求全部由同一个版本模型生成,生成时间依然会被最长的输出所阻塞,并不能解决同步 RL 训练效率低的问题。
AReaL-boba² 的高效秘诀:完全异步 RL 训练
AReaL-boba² 通过算法系统 co-design 的方式实现了完全异步 RL 训练(fully asynchronous RL),从根本上解决了同步 RL 的各种问题。在 AReaL-boba² 的异步训练框架中,生成和训练使用不同 GPU 并完全解耦。生成任务持续流式进行以保证 GPU 资源始终满载运行,杜绝了 GPU 空闲。训练任务持续接收生成完成的输出,在训练节点上并行更新参数,并将更新后的参数与推理节点同步。
AReaL-boba² 的系统设计可以在保证稳定 RL 训练的同时,参数同步的通信和计算花销仅占总训练时间的 5% 以内。
此外,由于全异步 RL 中同批次数据可能由不同版本的模型产生,AReaL-boba² 也对 RL 算法进行了升级,在提速的同时确保模型效果。

Fig. 3 全异步 RL 系统 (fully asynchronous RL system) 的计算流程示意图
使用 128 卡对 1.5B 模型在 32k 输出长度、512 x 16 批大小设定下进行 RL 训练,我们列出了每一个 RL 训练步骤(模型参数更新)所需要的时间,异步 RL 相比同步 RL 相比,每个训练步骤耗时减少 52%:

全异步 RL 训练的系统架构:全面解耦生成与训练
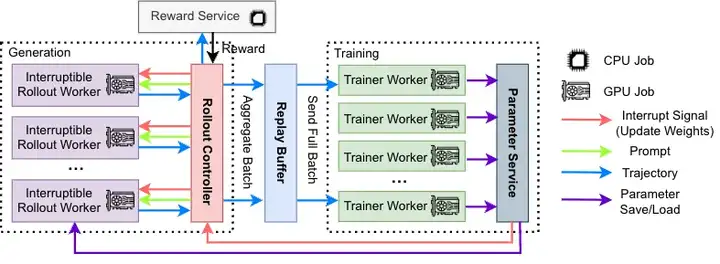
Fig. 4 AReaL-boba² 的异步 RL 系统架构。生成模块(紫色)和训练模块(绿色)完全分离。
AReaL-boba² 系统架构的围绕不同计算任务采取全面解耦的模块化设计。对于模型输出、模型训练、和奖励函数计算,采用不同计算资源彻底分离,实现全流水线异步执行。整体设计包含四个核心组件:
1. 可中断轨迹生成器(Interruptible Rollout Worker):
- 支持生成请求(generate request)和权重更新请求(update_weights request)。
- 收到权重更新请求时,会中断正在进行的生成任务,丢弃旧权重计算的 KV 缓存。加载新权重后重新计算 KV 缓存并生成剩余轨迹。
2. 奖励服务(Reward Service):
- 负责评估生成轨迹的正确性(如:在代码任务中提取代码并执行单元测试以验证其正确性)。
3. 训练器(Trainer Workers):
- 持续从回放缓冲区采样训练数据,随后执行 RL 算法更新,并将最新模型参数存入分布式存储。
4. 生成控制器(Rollout Controller):
- 系统的 “指挥中枢”:控制器从数据集中读取数据,向轨迹生成器发送生成请求,随后将生成完整的轨迹发送至奖励服务以获取奖励值。带有奖励值的轨迹数据会被存入回放缓冲区,等待训练器进行训练。当训练器完成参数更新后,控制器会调用轨迹生成器的权重更新接口。
算法改进保障收敛性能
虽然异步系统设计通过提高设备利用率实现了显著的加速,但也引入一些问题导致收敛性能不如同步系统:
- 数据陈旧性。由于训练系统的异步特性,每个训练批次包含来自多个历史模型版本的数据。数据陈旧会导致训练数据与最新模型的输出之间存在分布差异,从而影响算法效果。
- 模型版本不一致。由于采用了可中断轨迹生成,单个轨迹可能包含由不同模型版本产生的片段。这种不一致性从根本上违背了标准 on-policy RL 的设定前提 —— 即假定所有动作都由单一模型生成。
为了解决这些问题,团队提出了两项关键算法改进。
方法 1:数据陈旧度控制(Staleness Control)
对于异步 RL 算法,有一个重要的参数叫 staleness,可以用来衡量训练数据的陈旧性。
staleness 表示当采用一个批次的数据进行模型训练时,生成最旧的一条数据的模型版本和当前更新的模型版本之间的版本差(比如,一个批次中最旧的一条数据由 step 1 产生的模型输出,当前模型由 step 5 产生,则该批次 staleness=4)。同步 RL 的批次 staleness 固定为 0。staleness 越大,则数据陈旧性越严重,对 RL 算法的稳定性挑战也越大,模型效果也更难以保持。
为避免数据陈旧性带来的负面影响,AReaL 在异步 RL 算法上设置超参数 max staleness 𝜂,即只在 staleness 不超过预设值 𝜂 时,提交进行新的数据生成请求。
具体来说,轨迹生成器在每次提交新的请求时,都会通过生成控制器进行申请;控制器维护当前已经被提交的和正在运行的请求数量,只有当新的请求 staleness 不超过 𝜂 限制时才允许被提交到生成引擎处。当 𝜂=0 时,系统等价于跟同步 RL 训练,此时要求用于训练的采样轨迹一定是最新的模型生成的。
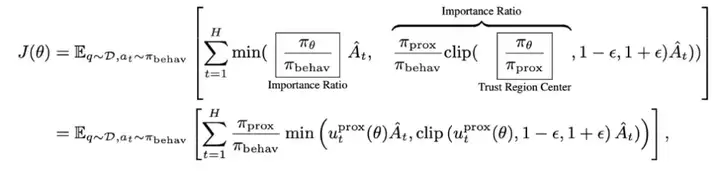
方法 2:解耦近端策略优化目标(Decoupled PPO Objective)
为了解决旧数据与最新模型之间的分布差异带来的问题,团队采用了解耦的近端策略优化目标(Decoupled PPO Objective),将行为策略(behavior policy)与近端策略(proximal policy)分离。其中:
- 行为策略(behavior policy)表示用于轨迹采样的策略
- 近端策略(proximal policy)作为一个临近的策略目标,用来约束在线策略的更新
最终,可以得到一个在行为策略生成的数据上进行重要性采样(importance sampling)的 PPO 目标函数:

效果验证:速度 Max, 性能依旧强劲!
AReaL 团队基于 1.5B 模型在数学任务上设置不同 max staleness 𝜂 进行 Async RL 训练,得到如下训练曲线。在 AReaL 的训练设定中,经典的 PPO 可以清晰看到随着 staleness 增大效果下降,而采用 decoupled PPO objective 后,即使 𝜂 增加到 8,算法依然能够保持训练效果好最终模型性能。
注:max staleness 的绝对值和具体实验设定(learning rate,batch size 等)相关,这里仅比较 AReaL-boba2 系统改进所带来的相对提升。
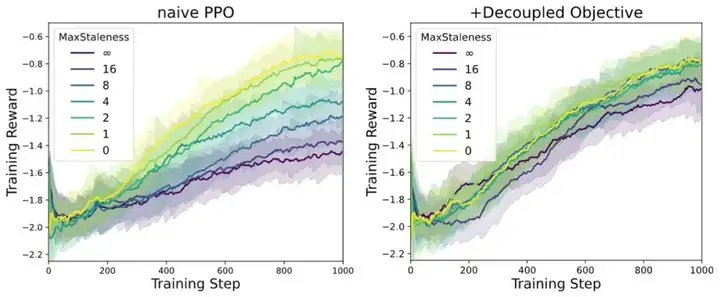
Fig. 5 针对不同 staleness 的算法稳定性结果。左图:经典 PPO 算法在异步 RL 场景下模型效果很容易退化。右图:采用 decoupled PPO objective,在 staleness=8 的情况下模型效果依然无损。
AReaL 团队还把采用不同 max staleness 训练的模型在 AIME24 和 AIME25 数据集上进行评测,采用 decoupled objective 的算法都能在 𝜂 更大的情况下保持更好的模型效果。
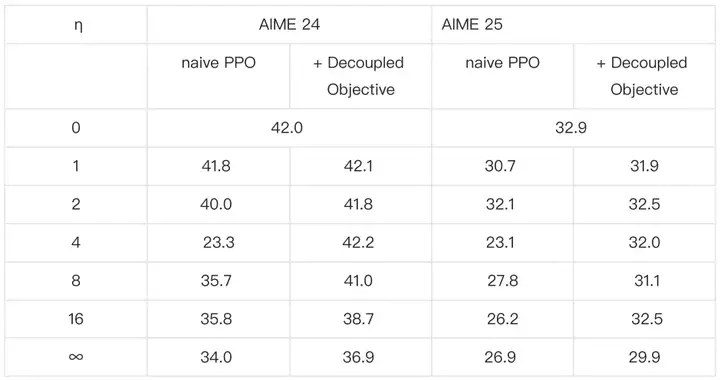
Table 2: 在数学任务(AIME24 & AIME25)上对于不同 max stalness,采用经典 PPO 算法和 decoupled PPO 进行异步 RL 训练最终产生的模型效果比较,decoupled PPO 始终有更好效果。
想深入了解算法原理与实验细节? 请访问原论文查看更多算法细节:https://arxiv.org/pdf/2505.24298
开源助力:轻松复现 SOTA 代码模型
除了强大的 AReaL-boba² 训练系统,团队也带来了训练数据、训练脚本和评估脚本。团队也提供了完整的技术报告,确保可以在 AReaL 上复现训练结果以及进行后续开发。技术报告中呈现了丰富的技术细节,包括数据集构成、奖励函数设置、模型生成方式、训练过程中的动态数据筛选等等。
快来用 AReaL-boba² 训练你自己的 SOTA 代码模型吧!
彩蛋:拥抱 Agentic RL 浪潮
本次 AReaL-boba² 发布也支持多轮 Agentic RL 训练!开发者可以根据自己的需求自由定制智能体和智能体环境,并进行 Agentic RL 训练。目前,AReaL-boba² 提供了一个在数学推理任务上进行多轮推理的例子。
AReaL 团队表示,Agentic RL 功能也正在持续更新中,未来会支持更多 Agentic RL 训练的功能。
结语
AReaL 项目融合了蚂蚁强化学习实验室与清华交叉信息院吴翼团队多年的技术积累,也获得了大量来自蚂蚁集团超算技术团队和数据智能实验室的帮助。AReaL 的诞生离不开 DeepScaleR、Open-Reasoner-Zero、OpenRLHF、VeRL、SGLang、QwQ、Light-R1、DAPO 等优秀开源框架和模型的启发。
如同其代号 “boba” 所寓意,团队希望 AReaL 能像一杯奶茶般 “delicious, customizable and affordable” —— 让每个人都能便捷、灵活地搭建和训练属于自己的 AI 智能体。
AReaL 项目欢迎大家加入,也持续招募全职工程师和实习生,一起奔向 Agentic AI 的未来!
文章来自于“机器之心”,作者“机器之心编辑部”。

【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

