在人工智能领域,跨模态生成(如文本到图像、图像到文本)一直是技术发展的前沿方向。现有方法如扩散模型(Diffusion Models)和流匹配(Flow Matching)虽取得了显著进展,但仍面临依赖噪声分布、复杂条件机制等挑战。
近期,Meta 与约翰霍普金斯大学联合推出的 CrossFlow 框架,以全新的技术路径实现了跨模态生成的突破性进展,为生成式 AI 开辟了更高效、更通用的可能性。该文章已经被 CVPR 2025 收录为 Highlight。

- 论文标题:Flowing from Words to Pixels: A Noise-Free Framework for Cross-Modality Evolution
- 论文地址:https://arxiv.org/pdf/2412.15213
- 项目主页:https://cross-flow.github.io/
- 代码地址:https://github.com/qihao067/CrossFlow
- Demo地址:https://huggingface.co/spaces/QHL067/CrossFlow
核心创新:从 “噪声到数据” 到 “模态到模态”
基于 Diffusion 或者流匹配的生成模型通常从高斯噪声出发,通过逐步去噪或优化路径生成目标数据。然而,对于噪声的依赖限制了这类算法的灵活性和潜能。
近期,不少工作在探索如何摆脱对噪声的依赖,比如使用基于薛定谔桥的生成模型。然而这些算法往往很复杂,并且依旧局限于相似模态之间的生成(比如人类转猫脸等)。
而 CrossFlow 则深入分析了流匹配,并基于流匹配提出了一种非常简单跨模态生成新范式,可以直接在模态间进行映射,无需依赖噪声分布或额外条件机制。例如,在文本到图像生成中,模型直接使用流匹配学习从文本语义空间到图像空间的映射,省去了复杂的跨注意力机制(Cross-Attention),仅通过自注意力即可实现高效的文本到图像生成。
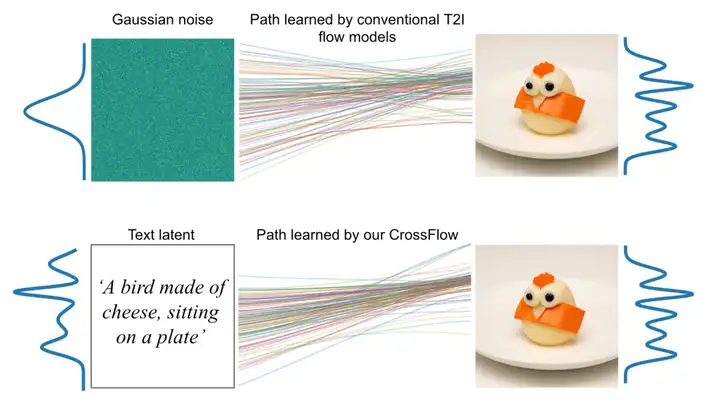
通过直接使用流匹配做模态间的映射,本文提出的模型在仅使用由自注意力和前向层组成的 transformer 的情况下,不需要基于任务的特定设计,便在多个任务(图像生成、字幕生成、深度估计、超分辨率)上实现了媲美乃至超过最优算法的性能。

作者发现,使用流匹配做模态间映射的核心在于如何形成 regularized 的分布。
为了实现这一点,作者提出使用变分编码器(Variational Encoder):将输入模态(如文本)编码为与目标模态(如图像)同维度的正则化潜在空间,确保跨模态路径的平滑性和语义连贯性。然后,作者发现:仅需要训练一个最简单的流匹配模型,就可以实现这两个空间的映射。
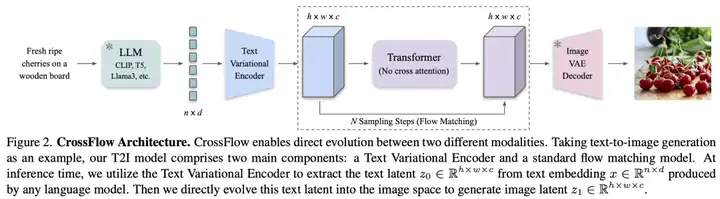
同时,现在的图片生成模型往往依赖无分类器引导(Classifier-free guidance)。这种引导通过改变额外输入的 condition 来实现。为了在无额外条件机制的情况下实现无分类器引导,作者通过引入二元指示符,在单模型中实现条件与非条件生成的灵活切换,显著提升生成质量。
实验表现
作者通过大量实验证明了新范式的优势:
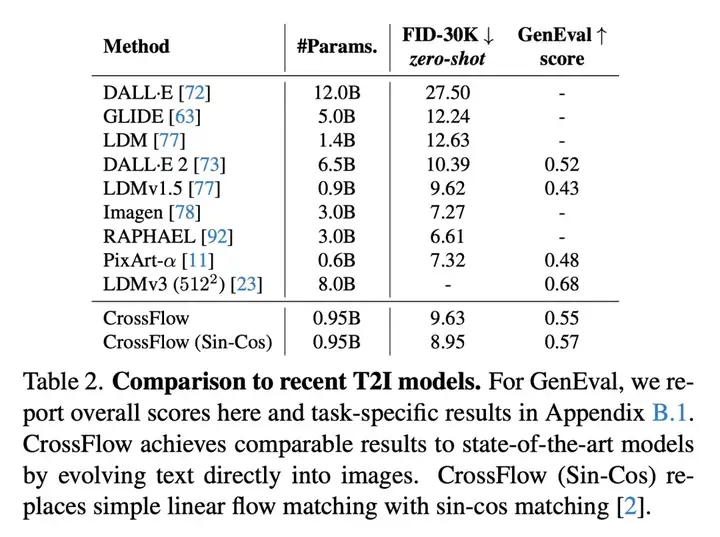
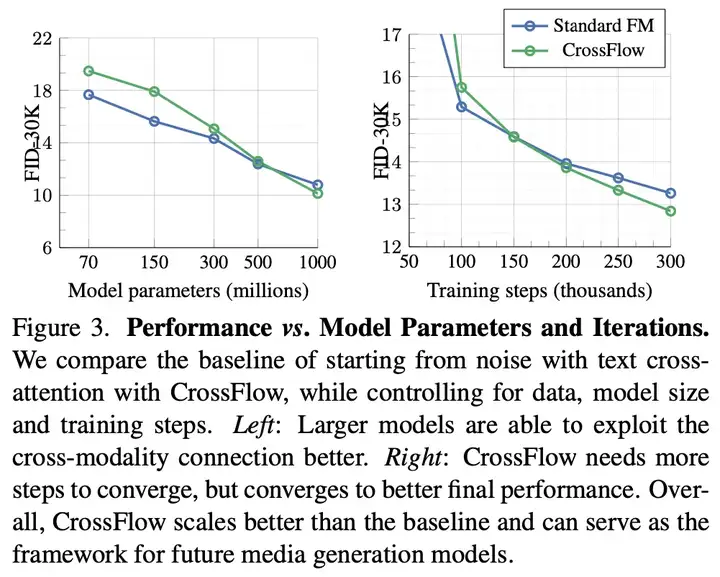
1. 在文本到图像生成任务上,相比于主流的使用跨注意力增加 text condition 的方法,CrossFlow 取得了更好的生成效果,并且有更好的 scaling 特性。

2. latent space 的差值算术操作:支持语义层面的加减运算(如 “戴帽子的狗”+“墨镜”-“帽子”=“戴墨镜的狗”),为生成内容提供前所未有的可控性,同时为图像编辑、平滑的视频生成等任务提供了新思路。




3. 源分布可定制,让图像生成更灵活,同时显著降低训练成本,提高生成速度:原本的图像生成始终学习从噪声到图像的映射,因此流匹配所需要学到的 path 的复杂度是确定的。而 CrossFlow 则建立了一个可学习的源分布到图像的映射,通过不同的方法来学习源分布,可以改变两个分布之间的差异以及 path 的复杂度,实现更灵活、快速的生成。
具体来说,相比 DALL-E 2 等模型,CrossFlow 训练资源需求大幅减少(630 A100 GPU 天 vs. 数千天),而后续的研究工作也表明,通过对源分布的设计,可以进一步将训练时间缩短至 208 A100 GPU 天,并提高 6.62 倍的采样速度。
4. 由于流匹配的 “双向映射” 的特性(bi-directional flow property),可以直接将文本到图像生成模型反过来使用,成为一个图像描述(image captioning)模型——该模型在 COCO 上取得了 SOTA 水平。

5. 无需基于任务的特定设计,即可以在多个任务上(图像生成、图像描述、深度估计、超分辨率)的多个数据集上取得 SOTA 的水平,推动模型使用统一、单一框架适配多任务。


结语
CrossFlow 的诞生标志着生成式 AI 从 “噪声中创造” 迈向 “语义间流转” 的新阶段。其简洁的设计、卓越的性能与灵活的扩展性,为跨模态生成提供了更多的可能性。
文章来自于“机器之心”,作者“刘启昊”。


