仅听几秒人声,即可完成逼真复刻,而且是对话式语音。
这就是MoonCast,一款革新性的对话式语音合成模型,目前已开源。
MoonCast 的“人味”播客效果如何?立即试听以下示例音频,让耳朵告诉你答案。
(注:本文使用的所有音频仅用于展示,不代表任何真实事件或观点。禁止商用。)
中文播客示例:
输入知识源:经典经济学论文 (PDF 链接: https://gwern.net/doc/statistics/decision/1951-nash.pdf)

英文播客示例:
输入知识源:诺贝尔物理学奖新闻稿 (URL 链接: https://www.nobelprize.org/prizes/physics/2024/press-release/)

生成一段地道的相声,完全就是郭德纲于谦那味儿啊。

(注:本文使用的所有音频仅用于展示,不代表任何真实事件或观点。禁止商用。)
它专为高质量播客内容创作量身打造,旨在将文档转化为引人入胜的播客音频。这些对话无论是文本内容还是说话人音色,MoonCast在训练时都从未见过。
这得益于强大的 zero-shot text-to-speech (零样本语音合成) 技术,能仅凭数秒的参考音频,便能合成如此逼真的语音。
接下来,就让我们一同深入 MoonCast 的技术内核,探寻其"声"动人心的奥秘。

AI 播客进化:MoonCast 如何赋予机器“人味”?
近年来,AI 语音合成技术可谓突飞猛进,在短句、单人语音的合成上,已经能做到以假乱真的程度。然而,当 AI 想要挑战更复杂的语音场景,比如我们日常听的播客时,就立刻遇到了”拦路虎”。
想象一下,优秀的播客往往是时长很长的,至少也需要几分钟甚至几十分钟;而且为了节目效果,通常会有两位甚至多位主持人互相交流、你来我往;更重要的是,播客的魅力就在于那种自然、随性、口语化的风格,就像朋友聊天一样,充满了即兴发挥和真实感。
反观现有的语音合成技术,它们大多还是在相对正式、书面化的单人场景下训练出来的,在面对播客这种自然、口语化的多人对话场景,就显得有些力不从心了,难以捕捉到那种“人味”。
MoonCast团队旨在解决这些难题,在剧本生成和音频建模两方面创新突破,打造更自然、高质量的 AI 播客系统。流程如下图所示。
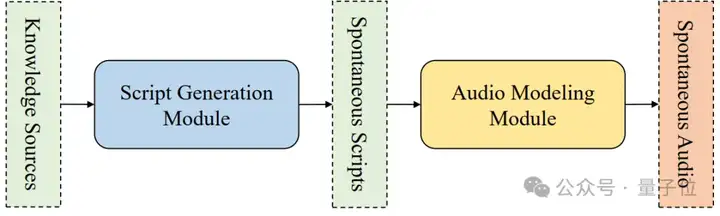
△MoonCast流程图
突破一:播客剧本有干货,更要有”人味”
一个好的播客, 离不开精心打磨的剧本。MoonCast首先就是要让 AI 像顶尖播客编剧那样, 创作出既有深度、 又有趣味的高质量剧本。那么,MoonCast是如何做到的呢?答案是:借助LLM (大型语言模型) 的强大能力。
首先, 利用 LLM理解能力,提炼信息生成摘要, 确保剧本言之有物:
- “广纳信息, 提炼精粹”:MoonCast能够阅读各种各样的输入知识源(例如新闻报道、学术论文、故事等等)。借助LLM的强大理解能力, 它可以快速抓住文本的核心要点, 提取出最有价值的信息,并将其凝练为简洁明了的摘要, 为剧本创作奠定坚实的内容基础。
- “化繁为简, 通俗易懂”:播客不仅仅面向行业专家, 更要让普通听众听得懂、听得有趣。MoonCast能够利用LLM的语言组织能力, 将原本晦涩难懂的专业知识, 转化为浅显易懂的口语化表达, 让高深的知识也能“飞入寻常百姓家”。
接着, 利用 LLM生成能力,基于摘要创作剧本, 让剧本更具“人味”:
- “组织对话, 承上启下”:基于生成的文档摘要,MoonCast利用LLM强大的逻辑推理和内容规划能力, 设计出流畅自然的对话结构。它会安排合适的开场白和结束语, 将摘要中的关键信息巧妙地融入对话之中, 并确保对话内容前后连贯、 逻辑清晰。为了避免变成枯燥的 “填鸭式” 教学,MoonCast还鼓励模型在对话中添加一些有趣的题外话, 让剧本更生动活泼。
- “锦上添花, 润色细节”:然而,仅仅依靠清晰的结构和流畅的对话还不足以打造优秀的播客剧本。真正的‘人味’,还需要细节的润色。MoonCast巧妙地运用 LLM 的自然语言生成能力,在剧本中自然融入各种口语细节, 例如:
- 填充词(如“呃”、“啊”、“那个”、“就是”)
- 响应词(如“没错”、“是的”、“嗯”)
- 随机的卡顿和嘴瓢
这些看似微小的细节, 就像是剧本的调味剂, 能够使对话更自然真实,让AI 播客瞬间鲜活起来。
突破二:全方位scaling, 音频合成更自然
规模化是提升 AI 播客自然度的基石。为了让 AI 播客更自然、 更连贯, MoonCast 团队采用了全面规模化的策略, 从模型参数、训练数据到上下文长度, 都进行了scaling,力求突破现有技术的限制。
- 模型参数规模化,更强大的AI大脑:MoonCast 采用了25亿参数的超大规模语言模型, 就像拥有了更强大的AI大脑, 更擅于音频生成和合成内容语义理解。
- 训练数据规模化,更丰富的学习素材:为了让AI大脑更聪明,MoonCast团队收集了海量、 多样化的语音数据进行训练,处理后数据包括30万小时的中文电子书,1.5万小时的中文对话数据,以及20万小时的英语对话数据。
- 上下文长度规模化,更广阔的记忆空间:MoonCast将模型的上下文长度扩展到了40k, 理论上支持超过10分钟的超长音频生成,让模型能够记住前文更长的生成内容,生成更连贯、 更自然的播客音频。
此外,MoonCast团队深知高质量的 AI 播客模型不是一蹴而就的。因此他们借鉴人类学习知识的规律, 将整个模型训练过程分为了三个阶段。就像学生一样,先打好基础, 再逐步提高难度, 最终才能融会贯通, 掌握高超的播客生成技巧:
- 第一阶段:让模型先学习生成短句、 单人语音, 掌握零样本语音合成能力。
- 第二阶段:让模型逐步学习处理电子书等非口语化的简单长音频, 提升长上下文生成的稳定性。
- 第三阶段:让模型最终学习生成包含丰富口语细节的长对话音频, 真正掌握复杂的播客生成技巧。
此外,为了提升长音频生成的效率和质量, MoonCast还创新性地采用了短段级别自回归的音频重建技术,以允许基于已重建内容,流式重建当前短段音频,提升音频重建连贯性。
性能数据亮眼:表现更自然
实验证明,MoonCast性能较单句合成模型提升显著,尤其在中英双语长对话播客的自然度和连贯性方面表现惊艳,更接近真人播音效果!

△MoonCast中文播客性能评估

△MoonCast英文播客性能评估
为了进一步揭示“人味”的奥秘,MoonCast还设计了消融实验,证明剧本中那些看似微小的口语细节,竟对有”人味”的音频的生成起着至关重要的作用。

△剧本口语细节对音频生成效果的影响。
最后,如果您想尝试该项目,可戳下方链接了解更多:
GitHub:https://github.com/jzq2000/MoonCast
论文:https://arxiv.org/pdf/2503.14345
Demo:https://mooncastdemo.github.io/
文章来自于“量子位”,作者“Zeqian Ju”。


