FLUX 的 Kontext 最近太猛,基本上除了不能写中文已经是全能的图像编辑应用了。
我前几天也写了非常详细的各种应用案例,比如简单的图片局部修改、去水印、去掉景区人员等。

后面大概写了一下如何使用, 但是还是很多人不会用。
然后我发现 liblib 居然上线了 FLUX Kontext,而且 Web UI 和 Comfyui 都支持,这下爽了。
不需要本地跑 Comfyui ,可以在线处理,而且还可以使用 Liblib 生态中的其他内容做图片的后续处理。
刚好写一个保姆级教程,手把手教你如何在 Liblib 使用 FLUX Kontext 修改和融合图片。
主要内容:
- 如何在 WebUI 用 FLUX Kontext 处理图片
- 如何使用藏师傅搭的 Kontext 工作流在 Comfyui 中处理图片(单图修复图片、双图和三图和超分)
在 Web UI 上简单体验 Kontext
这里先教一下如何用最基本的 WebUI 里的 Kontext 对图片进行修改,需要注意的是 Web UI 只支持单图。
首先我们需要在 liblib 首页(liblib.art/)找到 F.1 Kontext,然后进到详情页里面点加模型库。
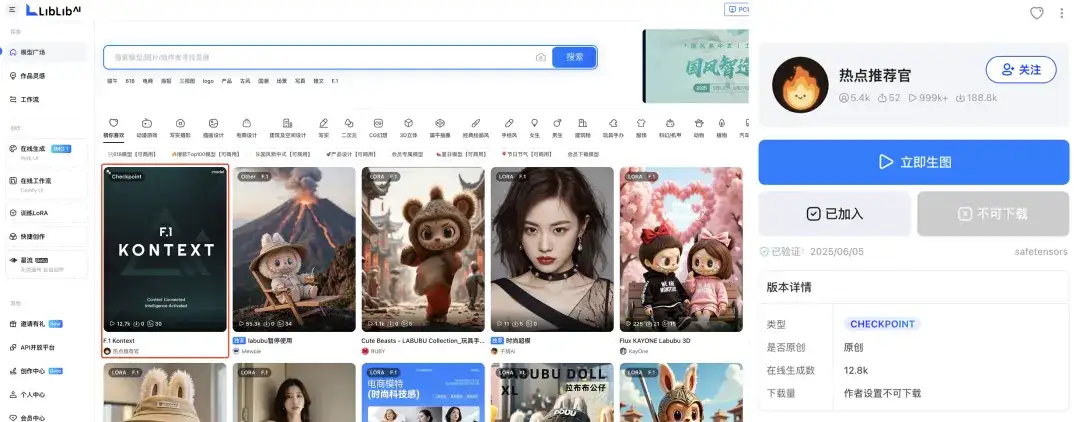
然后我们在侧边栏找到“在线生成”就可以进入到 web UI 的界面了,下面跟着我的操作设置就行:
1. 在页面最上面 CHECKPOINT 部分选择你刚刚加入到模型库的 F.1 Kontext 模型
2. 然后选择图生图模式
3. 之后输入提示词,Liblib 这里的提示词输入框可以一键帮你把中文提示词翻译为英文,非常省心
4. 我们可以在页面下方这里调整你期望生成的图像比例
5. 最后点击开始生图就好,我们的厨神 Labubu 就诞生了

这里我们的提示词是:
想象它在厨房里忙碌的样子。一件白色的厨师小上衣,或者一件带有可爱图案(比如小草莓、小饼干)的围裙系在腰间。头上戴一顶小小的白色厨师帽。如果能制作一些迷你的烘焙工具,比如擀面杖、打蛋器,或者一盘“刚出炉”的小饼干作为道具,那就更完美了。

另外,Web UI 近几天也会上线 Kontext 的多图参考能力,到时候可以实现下面类似的效果。
如果你实在不想用 Comfyui 也可以在 Web UI 里使用多图。
女孩拿着化妆品瓶子
女孩穿着这件 T 恤

Comfyui 上解锁 Kontext 高级技巧
可能很多人听到 Comfyui 又头疼了。
没事,在 Liblib 不需要你处理复杂的插件安装和模型下载问题。
即使是最复杂工作流搭建我也帮你搞好了你直接用就行。
这里获取藏师傅的 FLUX Kontext 工作流:https://pan.quark.cn/s/d91f31b6ae97
单图 Kontext 工作流使用
首先我们需要在 Liblib 左侧导航找到“在线工作流”,然后打开页面之后将你获取到的「FLUX Kontext 单图工作流」拖入到界面中就可以了。
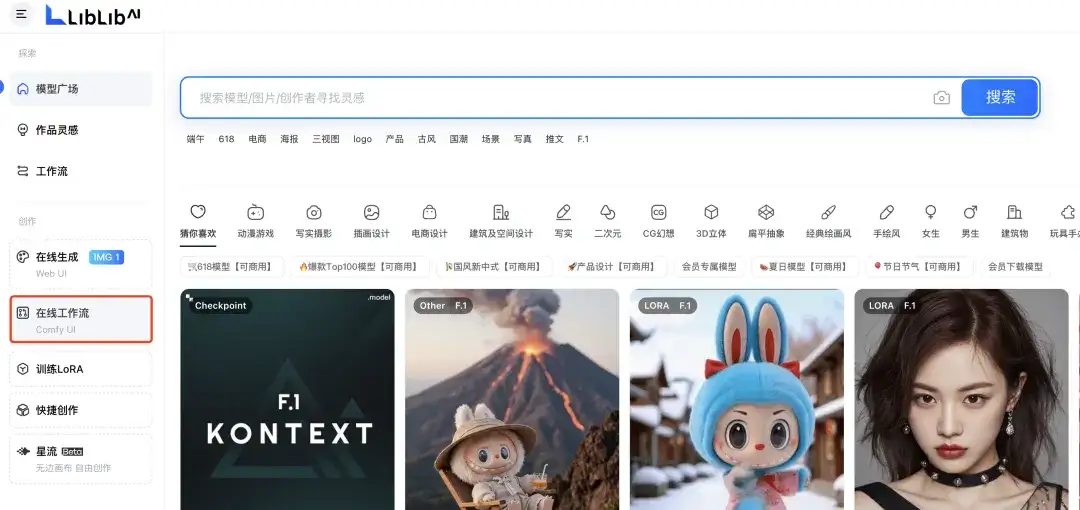
我们其实需要关注的就是三个地方,首先在「加载图像」节点上传你需要修改的图片。
然后在 Liblib Translate 节点输入中文的提示词,这个节点会自动帮你将提示词翻译为英文传输到 Kontext 节点里。
之后我们需要关注的就是 Kontext 节点中的 aspect_ratio 参数,这里的意思是输出图片的比例,按你需求的来就行。
最后点击右上角的运行按钮,等待就行。

这里不得不再次感叹 FLUX 的强大,我就从小米 YU7 官网截了两张图,随便输了一下提示词。
直接就能完成环境的转变,而且他还知道黄昏的时候把车灯提亮,在赛道的运动模糊也不止给轮胎加,还给出了车身之外的环境也加上了,而且微调了车身角度,及其智能。
环境更换为黄昏的沙滩
环境更换为赛车比赛的赛道,给车轮加上运动模糊

双图和三图 Kontext 工作流的使用
接下来我们就真正到 Kontext 最独特的功能了,他支持将多张图片的元素融合在一张图片中,比如将产品放在指定环境的图片里面,让模特穿上指定的服饰等。
而且 Kontext 不止支持双图的融合还支持三图进行融合非常强大。
我们还是先将双图工作流拖放到 Liblib 的 Comfyui 界面中。
跟单图的时候区别不大,只是这次需要我们上传两张图片。
之后会自动拼合为一张传给模型,然后输入提示词选择生成图片的比例就行。
多图融合有两个注意点:
- 提示词尽量描述两张图片的环境或者物品内容,不要用左边右边的图片这种词
- 如果工作流运行报错的话,大概率是有图片过大了或者某个图片的比例太奇怪,需要处理一下
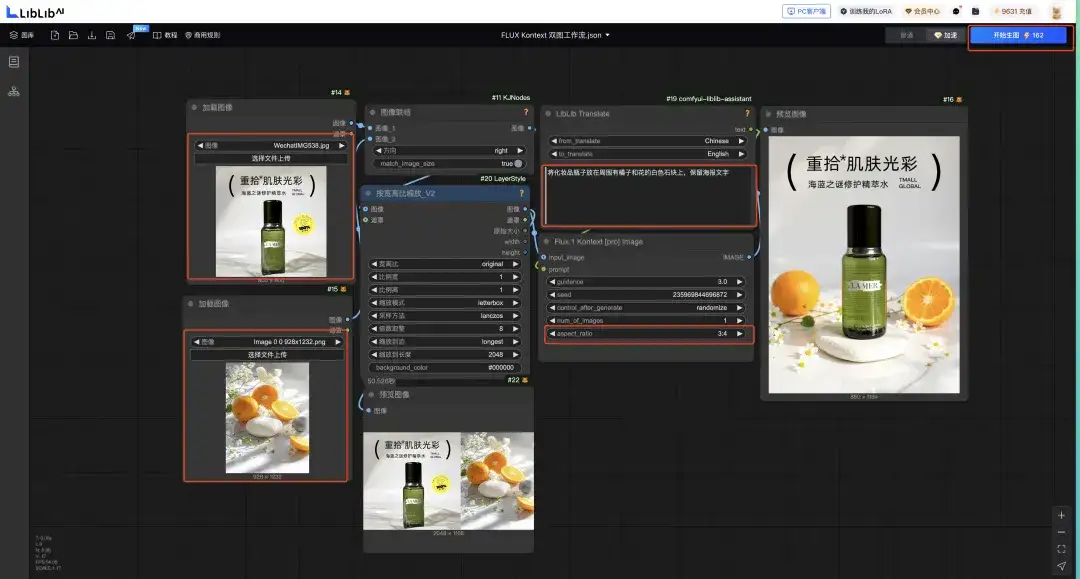
这里我们输入的提示词就是“将化妆品瓶子放在周围有橘子和花的白色石块上,保留海报文字”。
一般在多图融合的时候 Kontext 会尽量还原产品的细节,但是环境图片的细节会跟原图有出入。
她会优先保证自然度,比如上面这里石头的位置和画面角度都不适合将瓶子放在小石头上,它机会自己提取石头元素和橘子元素重新布局画面。
可以看到 LAMER 的化妆品瓶子细节保持的非常好,甚至透过瓶身依然可以看到后面的文字。

接下来三图也是一样的操作,我们现在可以混合更加复杂的场景,比如让模特拿着指定的化妆品站在指定的场景中。
你还是只需要设置你的三张图片、提示词和生成图像的比例,其他不需要管。
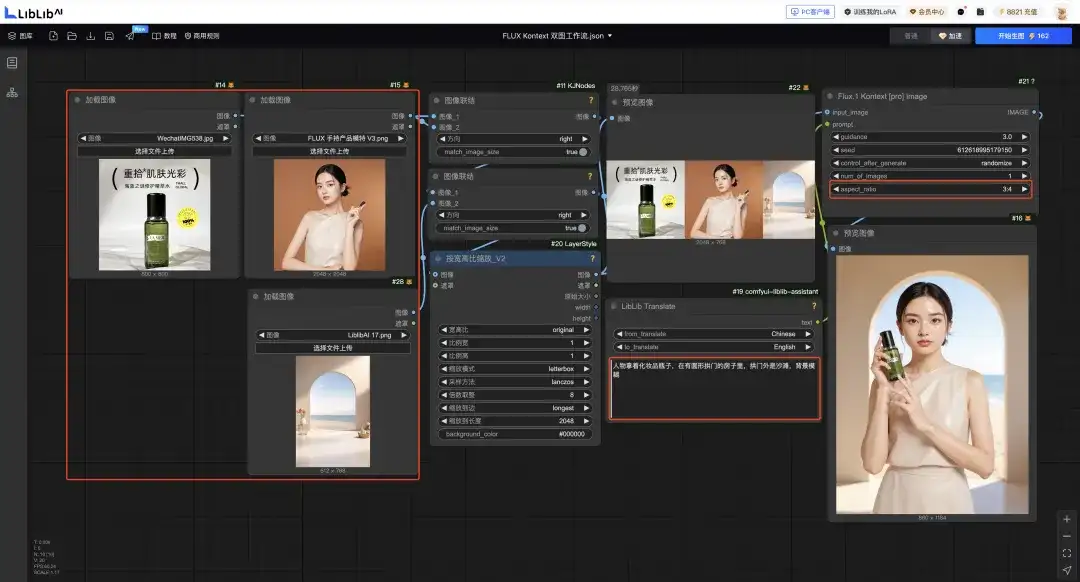
可以看到在这种需求下,Kontext 会依然优先选择保持产品细节,模特的脸和背景的环境都会发生细微的变化,确保图片是自然而且合理的。
人物拿着化妆品瓶子,在有圆形拱门的房子里,拱门外是沙滩,背景模糊

最后其实 Kontext 生成的图片分辨率不太高,所以可能很多时候大家有放大图片的需求。
索性在 liblib 的 Comfyui 有很多其他的基建,所以藏师傅就找了一个图像放大流程然后整合到了里面。
只需要拖动「FLUX Kontext 三图加放大工作流」这个文件到 comfyui 界面就行。
你需要关注的参数依然是那几个,放大那部分完全不需要管,全是自动的。
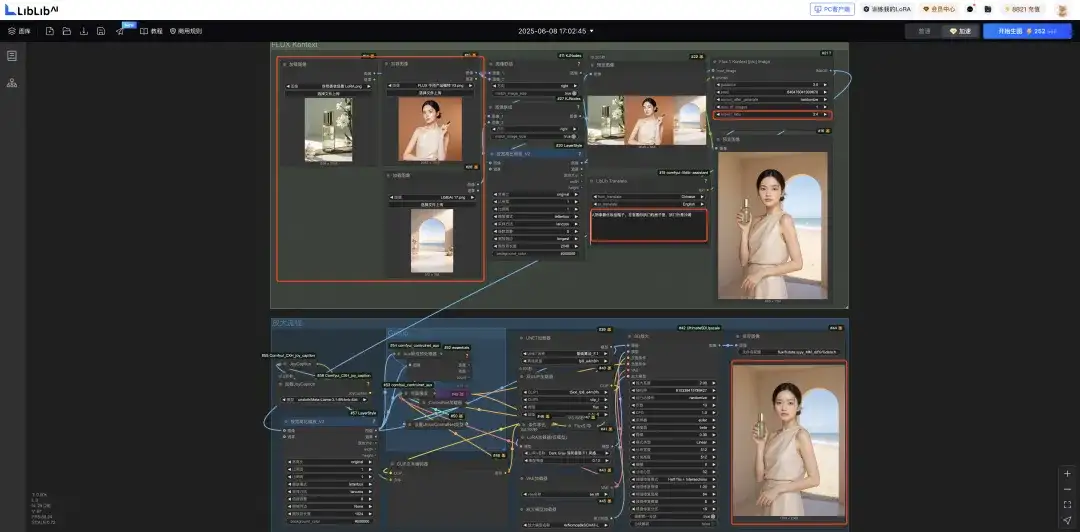
而且我还加上了一个我训练的 FLUX Lora,可以非常好的去掉 FLUX 的有你感觉,可以看到人物的肤质、服装材质和画面颜色都好了很多。
当然这种超分对一致性肯定会有些影响,如果你很在意的话可以不用。

好了这次的教程基本就到这里了。
文章来自于微信公众号“歸藏的AI工具箱”。

【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

