还记得DeepSeek-R1发布时AI圈的那波狂欢吗?"提示工程已死"、"再也不用费心写复杂提示了"、"推理模型已经聪明到不再需要学习提示词了"......这些观点在社交媒体上刷屏,连不少技术大佬都在转发。再到最近,“提示词写死了”......现实总是来得这么快——乔治梅森大学的研究者们用一个严谨得让人无法反驳的实验,狠狠打了所有人的脸!即使是DeepSeek-R1这样的强推理模型,在事件抽取任务上仍然能从精心优化的提示中获得高达23%的性能提升。我见过提升1%都有发论文的,提升23%可不是小打小闹的边际改进,而是实实在在的质的飞跃。

业界共识的大反转:推理能力≠提示理解
当R1展示出惊人的数学推理和代码生成能力时,整个AI社区都在讨论一个问题:既然模型能自己"想"了,还需要我们手把手教它怎么做吗?这种想法看起来很合理——如果一个学生已经足够聪明能独立思考,老师是不是就可以少费点心思了?但研究者们发现,推理能力强并不等于对任务指令的理解就完美。就像一个数学天才可能在理解题意上还需要老师的指导一样,强推理模型在面对复杂的结构化任务时,仍然需要精确的"调教"。
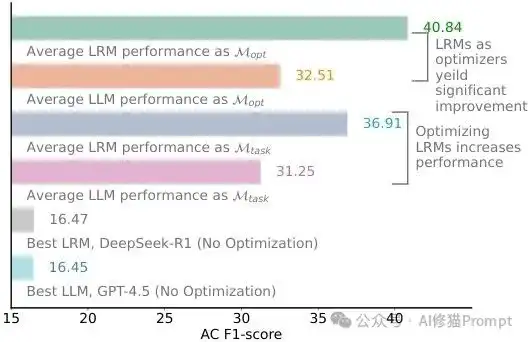
研究主要发现:LRM模型在事件抽取任务中通过提示优化获得显著性能提升,DeepSeek-R1提升幅度达23%"
"提示工程已死"遇上了事件抽取这块"硬骨头"
社交媒体那些"告别提示工程"的热帖看起来很有道理,但忽略了一个关键问题:大家都在数学题和代码生成上测试推理模型,鲜有类似本研究的现实任务。研究者们偏偏选择了事件抽取来"找茬"——这是一个需要AI同时扮演侦探、律师和档案管理员的复杂任务。
让我们看个具体例子,理解任务到底有多难
假设有这样一句新闻:
"Orders went out today to deploy 17,000 U.S. Army soldiers in the Persian Gulf region."
对人类来说,这很容易理解:有个"Transport"事件,触发词是"deploy",涉及执行者(U.S. Army)、被运输对象(soldiers)、目的地(Persian Gulf region)和时间(today)。
但AI模型经常在这里"翻车":
🔴 优化前的DeepSeek-R1输出:
Transport(mention="deploy",
agent=["U.S. Army"],
artifact=["17,000 U.S. Army soldiers"], # ❌ 包含多余修饰词
destination=["Persian Gulf region"],
time=["today"])
🟢 优化后的DeepSeek-R1输出:
Transport(mention="deploy",
agent=["U.S. Army"],
artifact=["soldiers"], # ✅ 简洁准确
destination=["Persian Gulf region"],
time=["today"])
看到区别了吗?优化后的模型学会了"去除数量词和所属关系修饰"这个专家级规则。
事件抽取的四重挑战——为什么这是AI的"地狱模式"
让我简单解释一下这个任务为什么这么难:
触发器识别(TI)
在茫茫文字中找到"事件信号灯",比如"deploy"、"convicted"、"died"
触发器分类(TC)
不仅要找到,还要正确分类:"deploy"→Transport,"convicted"→Convict
论元识别(AI)
找出所有参与者:谁、什么时候、在哪里、用什么方式
论元分类(AC)
最难的部分:在法庭事件中准确区分plaintiff(原告)vs defendant(被告)
这四个层次环环相扣,任何一环出错都会导致整个信息抽取失败。如果连DeepSeek-R1这样的"推理之王"在这种任务上都需要精心调教,那"提示工程已死论"基本就是个笑话了。
实验结果:数字会说话
研究者们的发现让所有人大跌眼镜:
📈 性能提升数据
- DeepSeek-R1:16.45% → 44.26%(+169%提升)
- OpenAI o1:13.94% → 39.81%(+185%提升)
- GPT-4.5:16.47% → 37.74%(+129%提升)
这不是实验室里的数字游戏,而是能直接影响产品效果的质的飞跃!
更神奇的是,优化后的模型自动学会了很多"人类专家级"的规则:
- 智能去冗余:移除"a/an/the",但保留"The Hague"专有名词
- 代词消解:将"his appeal"中的"his"解析为具体人名
- 异常处理:识别"went bust"这种非标准破产表达
- 上下文理解:从"If convicted of killings"正确提取犯罪类型
关键是:这些规则不是程序员手工编写的,而是DeepSeek-R1通过分析错误自动发现的。这才是真正的"AI调教AI"!
MCTS搜索框架:像下棋一样优化提示
研究者们设计了一个相当巧妙的框架,把提示优化当作下棋来处理。他们使用Monte Carlo Tree Search(MCTS),每一步都要做四件事:让任务模型生成答案,用Python解释器找错误,让优化器模型分析问题,最后根据反馈更新提示。这个过程就像AlphaGo下棋一样,不断探索、评估、回溯,直到找到最优策略。整个搜索空间虽然巨大,但MCTS能够智能地平衡探索新可能性和利用已知好方案。
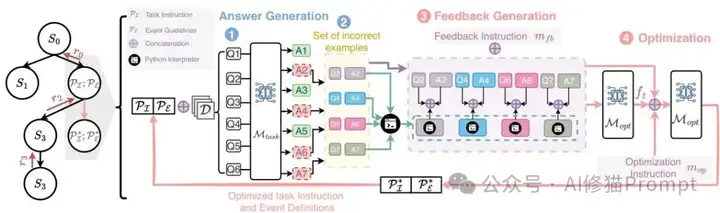
完整的MCTS提示优化流程,展示了四个关键步骤的循环过程
实验设计:小数据集见真章
您可能想问,他们是怎么验证的?研究者们在ACE05数据集上做了精心设计的实验,比较了两个推理模型(DeepSeek-R1和o1)和两个传统大语言模型(GPT-4o和GPT-4.5)。有意思的是,他们故意用了很小的训练集——ACE_low只有15个样本,ACE_med也就120个样本。这样做的好处是能看出在资源稀缺情况下,哪种方法更有效。评估指标包括触发器识别、触发器分类、论元识别和论元分类四个维度。
第一个发现:推理模型更爱"吃"优化提示
结果让人意外,推理模型从提示优化中获得的收益比传统模型还要大!在小数据集上,o1和DeepSeek-R1都获得了约8%的AC性能提升,而在中等数据集上更是达到了23%的惊人提升。相比之下,GPT-4o和GPT-4.5的提升幅度分别只有7%和5%(小数据集)以及14%和20%(中等数据集)。这说明强推理能力和提示优化不是对立关系,而是相互促进的。
第二个发现:推理模型收敛更快更稳
当研究者们深入到完整的MCTS搜索时,发现了另一个有趣现象。DeepSeek-R1在搜索深度2就能达到最佳性能,而传统模型需要探索到深度4或5才行。更重要的是,推理模型的性能方差更小,这意味着它们的表现更可预测、更稳定。对您这样的开发者来说,这就像拥有了一个更可靠的"调参助手",不会因为随机性而让您的产品性能忽高忽低。
第三个发现:推理模型是更好的"提示医生"
这可能是最有实用价值的发现了。当把这些模型当作提示优化器使用时,DeepSeek-R1表现得像个经验丰富的"提示医生"。它生成的优化提示不仅更短(约1750个token),还包含了很多精妙的抽取规则,比如"移除冠词除非是官方名称"、"解析代词到具体实体"等。相比之下,传统模型往往生成冗长的提示,却缺乏这种针对性的优化策略。
DeepSeek-R1的"聪明"行为:选择性编辑
让我给您举个具体例子说明DeepSeek-R1有多"聪明"。当分析错误时,它会判断某个错误是否真的来自提示问题,还是模型本身的能力限制。比如在处理共指消解错误时,DeepSeek-R1可能会推理:"这个错误可能是因为模型没有执行共指消解,而不是指南不清楚,所以我不修改这个事件的定义。"这种选择性编辑能力让它平均只修改6.7个事件类型,而其他模型往往不分青红皂白地修改所有定义。这不是偷懒,而是精准的"手术刀"式优化。
第四个发现:效率和稳定性双重优势
使用DeepSeek-R1作为优化器时,整个优化过程变得更加高效。其他模型能更快达到收敛状态,而且性能波动更小。这就像有了一个更好的"教练",不仅能让"学员"(任务模型)学得更快,还能保证训练过程的稳定性。对于需要在生产环境中部署的您来说,这种可预测的优化过程显然更有价值。
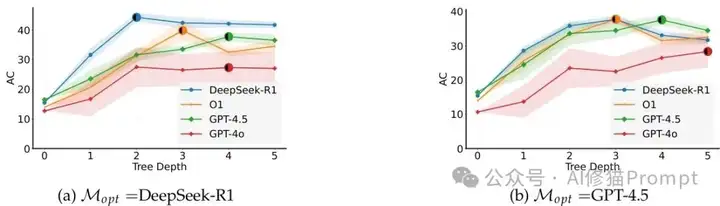
DeepSeek-R1作为优化器时收敛更快更稳定,而GPT-4.5作为优化器时波动较大
技术实现:四步循环的精妙设计
让我详细说说这个优化循环是怎么工作的,这个架构复现起来并不复杂。可以看一下上图完整的MCTS提示优化流程图,第一步是答案生成,当前提示加上批量查询输入到任务模型,得到预测结果;第二步是错误提取,用Python解释器自动识别格式错误、未定义事件类、幻觉等问题;第三步是反馈生成,优化器模型分析错误模式并给出改进建议;第四步是提示更新,根据反馈重写任务指令和事件指南。这四步形成一个闭环,每次迭代都让提示变得更精准。
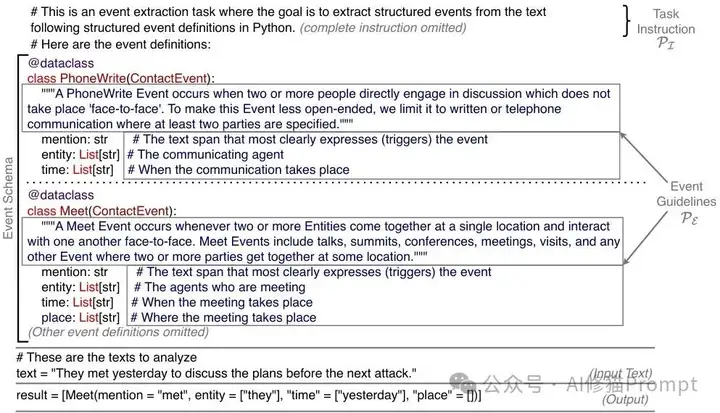
Python代码格式的提示结构,包含任务指令和事件模式定义
批处理技术:降本增效的小技巧
研究者们还用了一个很实用的技巧——批处理提示。把多个查询合并成一个大提示发给模型,这样能减少API调用次数,降低成本。格式是这样的:[提示 || 查询1 || 查询2 || ... || 查询n],模型返回对应的结构化回答。虽然看起来简单,但在大规模应用中这种优化能节省不少费用。对您的产品预算来说,这绝对是个值得考虑的优化点。
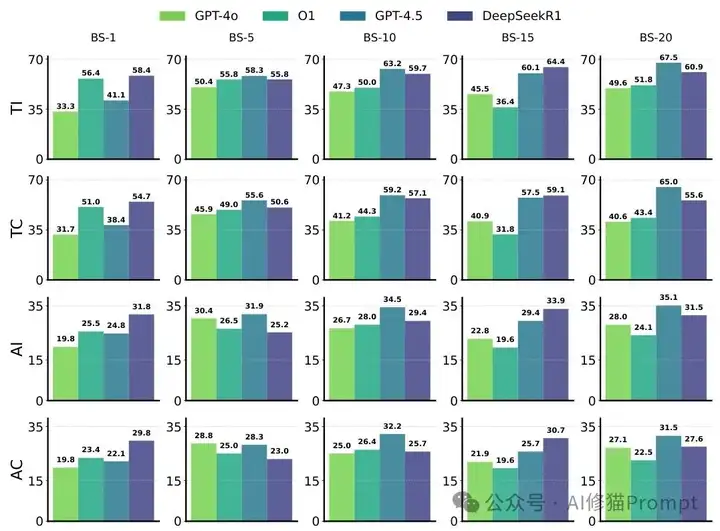
批处理策略性能对比:展示不同批次大小下的F1分数变化,验证批处理的成本效益优势
性能数据:具体数字说话
让我给您看一些具体的性能数据。在ACE_med数据集上,DeepSeek-R1经过优化后的AC F1分数从16.45提升到44.26,提升幅度达到27.81个百分点。o1的表现也很不错,从13.94提升到39.81,提升了25.87个百分点。而传统的GPT-4.5和GPT-4o的提升幅度分别是21.27和14.63个百分点。这些数字清楚地表明,推理模型确实能更好地利用优化后的提示。
开创性意义:首次系统研究的价值
这项研究的重要性不仅在于结果,更在于它是第一次系统性地研究LRMs在提示优化中的表现。以前的研究要么专注于传统LLMs的提示优化,要么研究LRMs在推理任务上的能力,但从来没人问过:"强推理模型是否还需要提示优化?"这个看似简单的问题背后,其实关系到整个AI应用开发的范式转变。如果答案是否定的,那我们可能需要重新思考提示工程的价值;如果是肯定的,那就意味着即使最先进的AI也需要精心"调教"。
错误分析:七种常见问题类型
研究者们把模型的错误分成了七类:解析错误(格式不正确)、幻觉(生成不存在的信息)、多重事件(漏掉部分事件)、标签噪声(数据集标注不一致)、共指错误(代词解析失败)、跨度过度预测(提取信息过多)、隐式事件(错过隐含事件)。通过优化,推理模型生成的提示能显著减少前几种错误,特别是在处理复杂语义关系方面表现更佳。
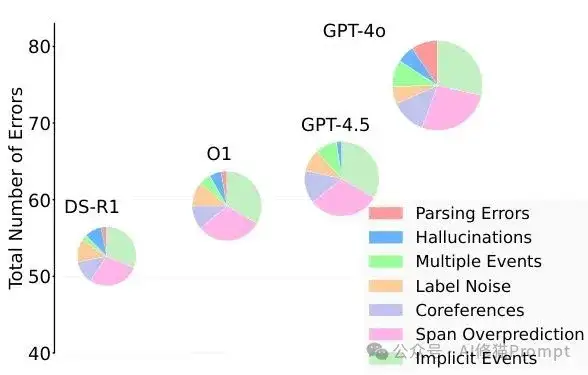
使用不同优化器后的错误分布变化,LRM优化器能更好地减少各类错误
提示长度与效果的有趣关系
这里有个反直觉的发现:并不是提示越长效果越好。DeepSeek-R1用最短的提示(约1750个token)达到了最佳性能,而其他模型往往需要更长的提示才能获得相似效果。这说明提示的质量比数量更重要,精准的规则比冗长的描述更有价值。对您的实际应用来说,这意味着不要盲目地往提示里塞更多信息,而要专注于提炼关键规则。
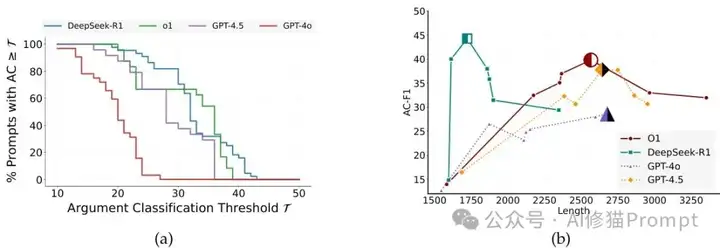
提示生存曲线和长度-性能关系,DeepSeek-R1用最短提示达到最佳效果
如何在您的项目中落地
如果您想在自己的项目中应用这套方法,建议这样做:第一步,选择一个结构化程度较高的任务作为试点,比如信息抽取、数据标注等;第二步,准备50-100个高质量样本作为训练集,不需要太多;第三步,设计两个元提示模板(错误分析和提示重写),这是整个系统的大脑;第四步,实现四步循环的自动化流程,重点是错误检测机制。记住,关键不在于一次性搞定所有问题,而是让系统能够自我迭代改进。
成本效益分析:投入产出比值得吗?
您可能会担心这套方法的成本问题。确实,MCTS搜索需要多次调用模型,但研究者们给出了一个重要发现:推理模型作为优化器时收敛更快,通常在2-3轮就能达到最佳效果,而传统方法可能需要5轮以上。以DeepSeek-R1为例,虽然单次调用成本较高,但总体优化成本可能反而更低。更重要的是,一旦获得优化后的提示,就能在后续大量推理中持续受益,这个ROI是相当可观的。
范式转变:从"调参"到"调教"的区别
这项研究其实揭示了一个更深层的变化:我们正在从传统的"调参"时代进入"调教"时代。传统的提示优化更像是盲人摸象,试错式地调整参数;而这种新方法更像是有经验的老师在指导学生,能够分析错误原因、给出针对性建议。DeepSeek-R1生成的那些精准规则——"移除冠词但保留官方名称"、"解析代词到具体实体"——不是随机试出来的,而是基于错误分析得出的智能决策。这种质的飞跃,可能会重新定义人机协作的方式。
最后:自我优化的AI生态
这项研究打开了一个有趣的可能性:如果AI模型能够优化其他AI模型的提示,那是否意味着我们正在构建一个自我优化的AI生态?假设,您的产品中不仅有执行任务的AI,还有专门负责优化其他AI表现的"元AI"。这种分工合作的模式可能会成为复杂AI系统的标准架构。更进一步,随着多模态推理模型的发展,这套框架甚至可能扩展到图像、视频等其他模态的任务优化上。您对此有兴趣可以看下《!离AGI更近了!!0.31元运行谷歌的AlphaEvolve和UBC的DGM「达尔文-哥德尔机」?》我的文章除了非必要,都会复现一下再发,为了向读者负责,也为自己存档。今天这篇,我只说一句,复现起来并不复杂。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

