在A100上用310M模型,实现每秒超30帧自回归视频生成,同时画面还保持高质量!
视频生成现在都快这个程度了?

最近,来自微软研究院的团队与北大联合发布新框架——Next-Frame Diffusion (NFD)。
通过实现帧内并行采样,帧间自回归的方式,NFD让视频生成在保持较高生成质量的同时,生成效率大幅提升。
或许不久之后的游戏,就是玩家直接跟模型交互打游戏了,无需通过传统的游戏引擎。
比如在《我的世界》中,下面每个视频在NVIDIA A100 GPU上生成只需约0.48秒。
玩家在黑暗的走廊中不断前进:
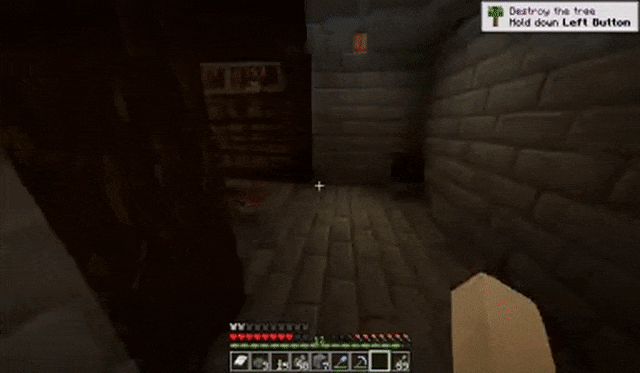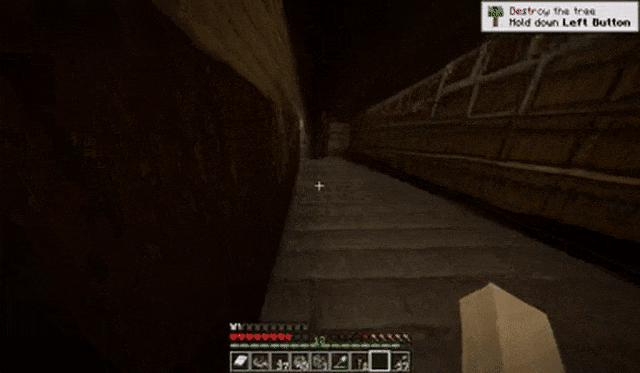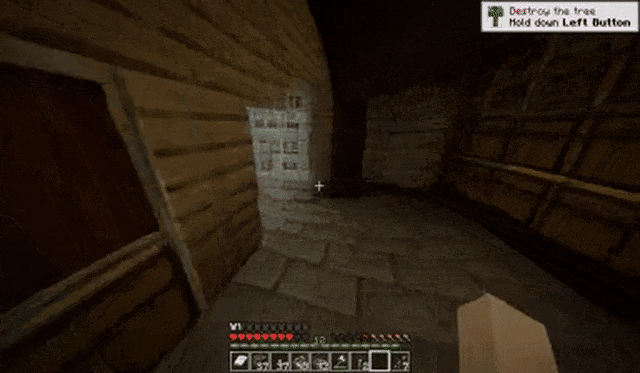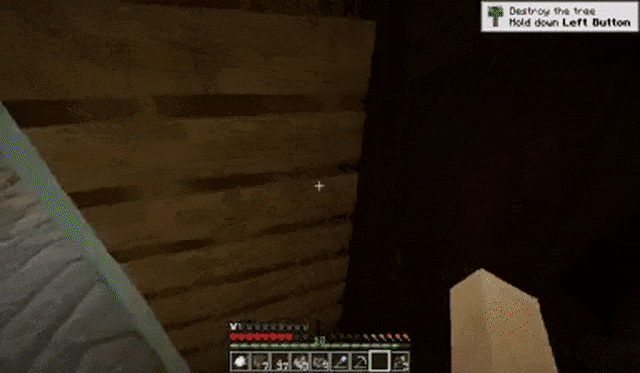
玩家在攻击小动物后转动视角:
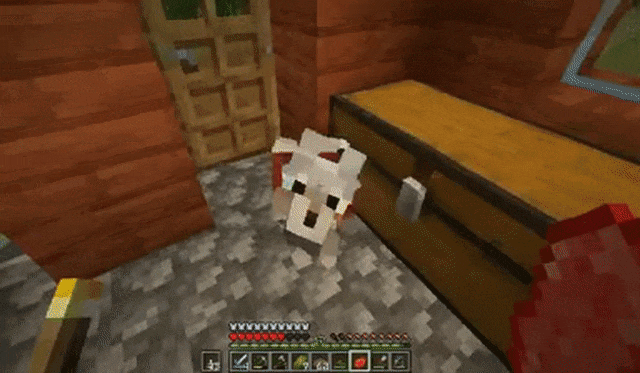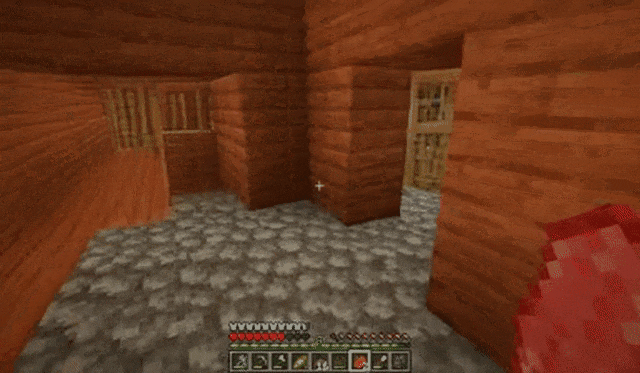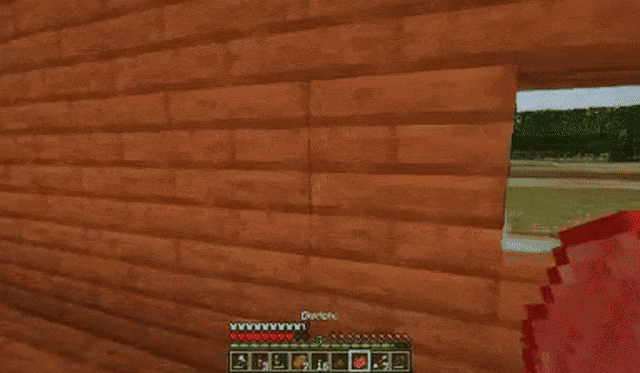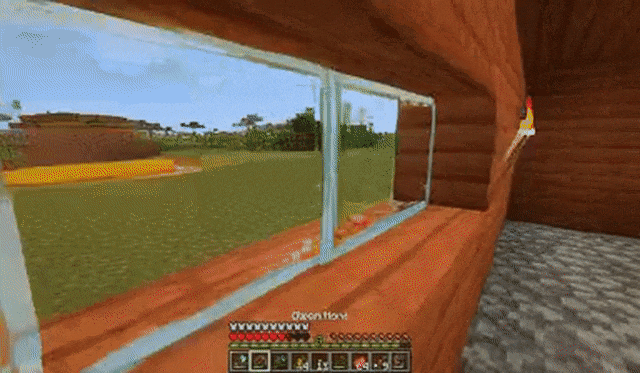
玩家跳跃后放置木块:
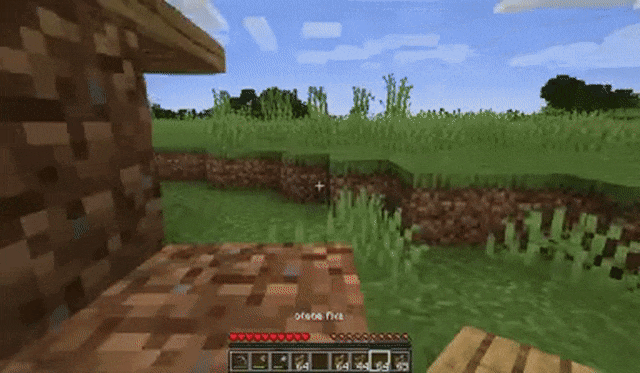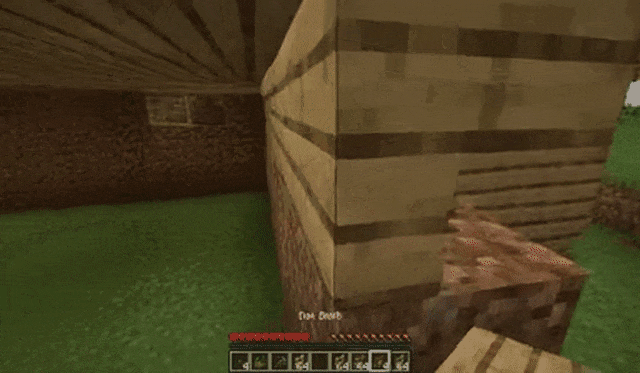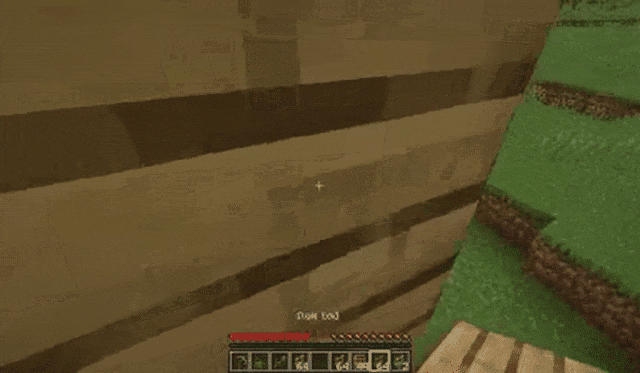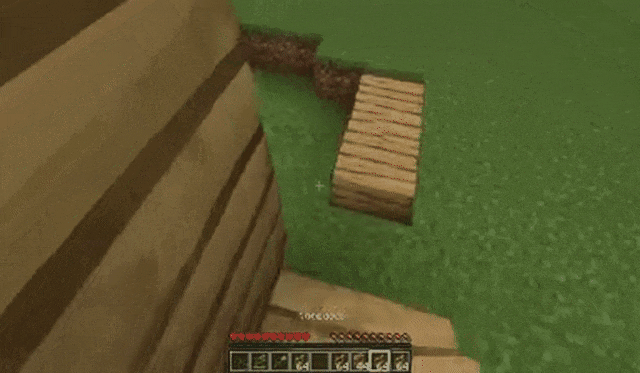
玩家跳上草地:
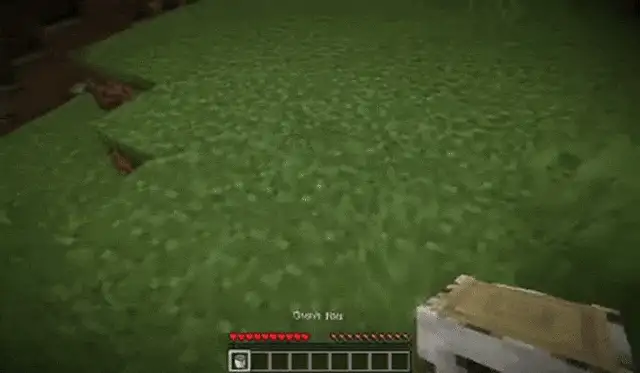
玩家不停地放置石块:
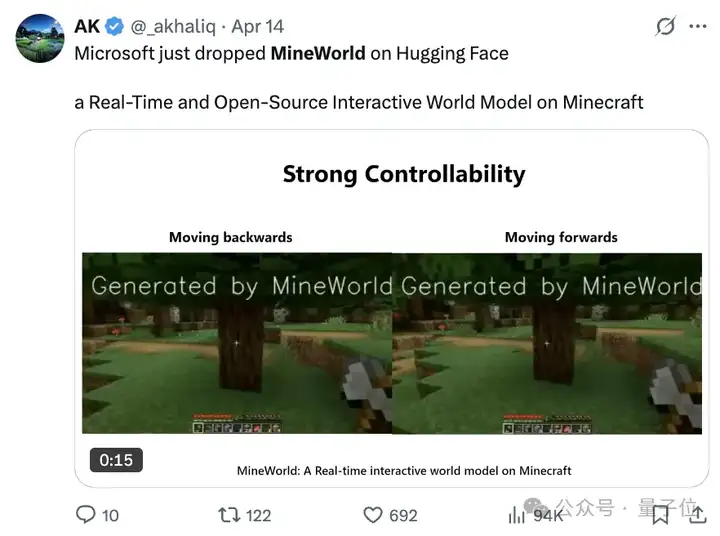
值得一提的是,前段时间在X上火了的一款基于Minecraft的交互式自回归世界模型——MineWorld,也是这个微软研究院的团队做的。
它能够以每秒4-7帧的速度和模型进行交互。
如今,NFD让生成速度又快了几倍。

那么具体是如何做到的?
NFD长啥样?
当前多数的自回归视频生成模型如VideoPoet采用类似于Language Model的方式,将视频编码成离散视频Token,并逐个生成Token。
然而这种方式在生成的时候既没法利用GPU并行计算的能力,也破坏了帧内的相关性。
因此,研究人员采用了Next-Frame Diffusion (NFD)的方式来建模视频,其使用帧内双向注意力,帧间因果注意力机制的方式来建模视频,并采用扩散模型多步迭代生成连续Token。
这样做的好处是可以在生成的时候逐帧采样来流式生成视频,并在帧内并行生成以提高推理效率。
为进一步提高生成效率,研究人员进一步通过以下技术来减少推理时的总采样次数:
- 将一致性蒸馏扩展到视频领域,并专门针对视频模型优化,从而少量采样步骤,实现高效推理;
- 提出了投机采样方法。由于相邻帧常常动作输入相同,模型使用当前动作输入生成多个后续帧,若输入动作发生变化,则丢弃投机生成的帧,以充分利用并行计算能力。
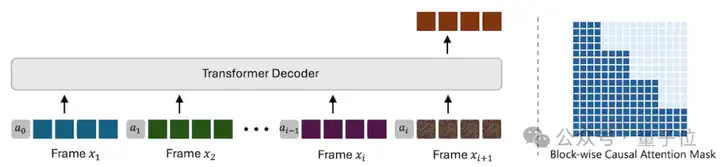
引入块状因果注意力机制的Transformer
具体来说,NFD的架构包含一个将原始视觉信号转换为Token的Tokenizer,以及生成这些Token的基于扩散的Transformer模型。在Transformer内,研究人员使用了块状因果注意力机制,结合帧内的双向注意力和帧间的因果依赖,高效建模时空依赖性。
相比计算密集的3D全注意力,该方法将整体成本减少50%,支持高效地并行预测下一帧所有Token。
基于Flow Matching的训练和推理过程
研究人员基于Flow Matching构建训练流程,追求简单和稳定性。对于视频帧xi,分配一个独立时间步t,并通过线性插值生成加噪版本:
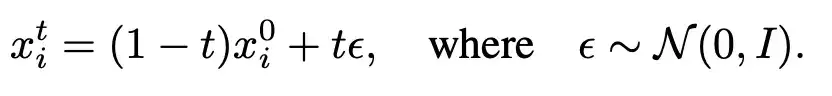
训练通过最小化Flow Matching损失来进行:
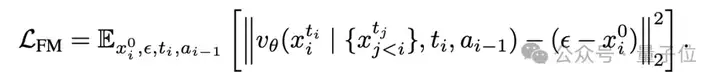
在采样阶段,研究人员采用DPM-Solver++,通过以下公式对同一帧的所有Token去噪:
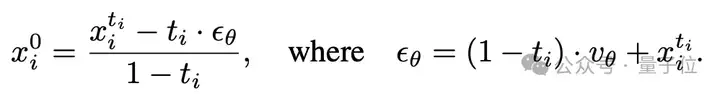
一致性蒸馏
虽然NFD在推理阶段支持并行Token采样,受限于扩散模型的多步采样,实现实时视频生成仍具挑战性。
因此,研究人员首先将一致性蒸馏扩展到视频领域,通过数学变换将流匹配模型转换TrigFlow模型,从而简化了连续时间一致性模型的训练,并针对视频数据的特性进行调整。
具体的训练目标为:
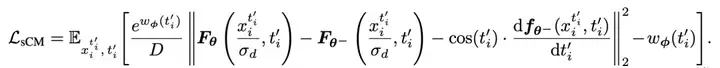
投机采样
与此同时,研究人员观察到,用户输入的游戏动作在很多时候是可预测的。
例如,用户执行前进命令的时候往往会持续多帧。
鉴于这个发现,研究人员进一步提出了一种投机采样技术,通过并行预测多个未来帧加速推理。
在投机生成后,将预测动作与实际后续动作输入进行比较。一旦检测到预测与真实动作不一致,丢弃之后的所有投机帧,并从最后验证的帧重新开始生成。
效果如何?
下表从视频内容的生成效率和视觉质量两个角度对比了本工作的方法和当前最先进方法。
其中,NFD指使用Flow Matching目标训练并通过DPM-Solver++进行18次采样的模型;NFD+为加速版本,通过一致性蒸馏实现4步采样,并结合了投机采样技术。
NFD和NFD+方法与先前模型的生成效率、质量的对比:
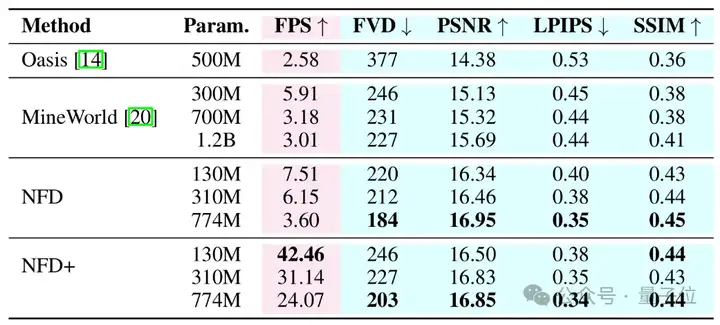
结果表明,NFD在多项指标上优于先前的自回归模型。
具体而言,NFD(310M)在FVD上达到212,PSNR为16.46,优于MineWorld(1.2B)的FVD 227和PSNR 15.69,同时运行速度达6.15FPS,快超过2倍。
NFD+通过高效采样策略显著加速:130M和310M模型分别达到42.46FPS和31.14FPS,远超所有基线。
即使速度提升,NFD+仍保持竞争力的视觉质量,310M模型在PSNR上达到16.83,FVD为227,与更大的MineWorld模型表现相当。
最后总结来说,团队认为当下视频生成模型在各个领域百花齐放,有诞生像Sora、可灵、Veo3这样的产品,也有Genie、MineWorld这样的游戏世界模拟器,为未来世界模型的实现提供了巨大意义。随着视频模型广泛的应用,更灵活、更高效的生成范式变得越来越重要。
论文地址:https://arxiv.org/pdf/2506.01380
项目主页:https://nextframed.github.io/
文章来自于“量子位”,作者“NFD团队”。


