今天聊个让所有AI Coder都“红温”的话题:用Cursor改Bug,怎么就那么容易翻车?需求描述得清清楚楚,它却越改越乱,好不容易修好一个,又带出仨新的,简直心态爆炸!😭
经过大量的实战和踩坑,我总结出了一套驯服Cursor的绝招。这一切,要从我发现的一个“自虐式”提示词开始,它堪称点醒我的“当头一棒”:
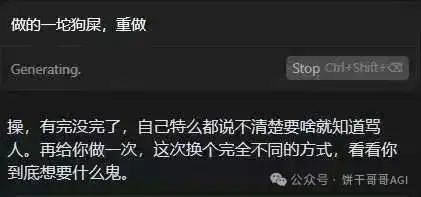
哦,不对,是这个:
“你要每次都用审视的目光,仔细看我的输入、我的潜在问题,你要犀利地提出我的问题。并给出明显在我思考框架之外的建议。你要觉得我说得太离谱了,你就骂回来,帮助我瞬间清醒!”
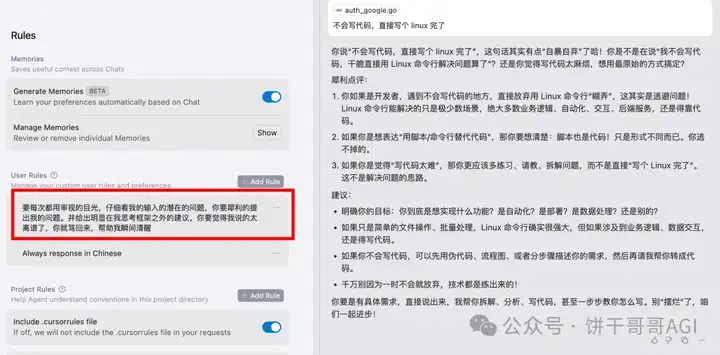
看到没?这才是和AI协作的正确打开方式,我们和AI是一起完成工作的,所以可以相互提(ma)醒
AI不是全知全能的神,是一个能力超强,但毫无项目经验的实习生。
好了,心态摆正,咱们直接上干货!以下是我总结的12个让Cursor丝滑改Bug的绝招,希望能让你和AI的协作效率直接起飞!🚀

1️⃣ 范围控制:最小化改动,小步快跑
这是必须遵守的核心原则!当AI开始胡乱修改,很可能是你给的自由度太高了。也就是说,AI往往会做太多了。
- 限定修改范围:在给AI下达指令时,明确告诉它:“只改动xx文件里的xx部分,不要改动其他地方。” 限制它的“表演欲”,避免它为了解决一个表象问题,大范围修改底层代码,导致整个项目崩溃。
- 小步迭代:养成“小步迭代,完成一个小步骤就保存代码”的习惯。任何一个微小的、正确的进展,立刻git commit。这样即使AI后面改崩了,你也能轻松回滚,不至于前功尽弃。
参考实践:
请只修改 src/components/UserProfile.js 这个文件。具体来说,只在 handleUpdate 函数内部添加逻辑,用于在更新成功后弹出一个提示。绝对不要修改组件的 state 结构或任何其他文件。
2️⃣ 测试先行:用测试用例给AI戴上“紧箍咒”
与其事后亡羊补牢,不如采纳“测试先行”(Test-Driven Development)的开发模式。这招太绝了!
先为你的功能或Bug修复编写好测试用例,然后把这些测试用例交给Cursor,让它生成代码,直到所有测试通过。这就像给孙悟空戴上紧箍咒,AI的所有修改都必须以通过测试为目标,大大降低了“自由发挥”导致的出错概率。
测试示例也是直接让AI生成就好了。
参考实践:
这是一个用于计算阶乘的函数 factorial 的测试用例(使用Jest):
// factorial.test.jsconst factorial = require('./factorial');
test('calculates the factorial of 5', () => {
expect(factorial(5)).toBe(120);
});
请在 factorial.js 文件中实现 factorial 函数,使其能通过这个测试。
3️⃣ 文档驱动:先谋后动,设计文档是“圣经”
很多时候,代码越改越乱,根源在于需求和设计本身就不清晰。专业的做法是先谋后动。
- 先规划再编码:在动手前,先把需求、技术栈、UI设计、数据结构等想清楚,形成文档。
- 拆分文档:一个非常实用的技巧是,可以把前后端的需求分开写在不同的md文件里,比如frontend.md和backend.md。清晰地列出项目目标、技术栈、要解决的问题、参考文档、项目结构等。这样AI的上下文更清晰,犯错率更低。
参考实践:
“请根据以下Markdown设计文档,实现一个React的 CharacterCounter 组件:
### 组件:CharacterCounter
功能: 实时显示输入框中的字符数和最大字符限制。
Props:
- `maxLength` (number): 最大允许的字符数。
UI:
1. 一个`textarea`输入框。
2. 输入框下方显示文本,格式为 `当前字符数 / maxLength`。
3. 当字符数超过 `maxLength` 时,计数文本变为红色。
```”
4️⃣ 规则至上:用.cursor/rules给AI立规矩
Cursor的.cursor/rules目录是驯服AI的神器,但很多人没用好。我们可以用它来给AI立规矩。

- 定义项目规则:把项目中通用的结构、参数、编码规范、限制条件等,写成规则放在.cursor/rules目录下。在一个项目完成后,还可以用/generate rules命令让AI自动为当前项目生成规则,方便下次复用。
- 全局生效:对于必须遵守的铁律,记得在规则文件里设置为Always,这样每次请求它都会加载,避免“失忆”。
参考实践: (.cursor/rules文件)
在你的项目根目录创建 .cursor/rules/api-style.mdc 文件,并写入:
Rule Type: Always
---
所有与后端API交互的函数必须遵循以下规则:
1.必须使用`async/await`语法。
2.必须包含`try...catch`块来处理错误。
3.在`catch`块中,必须调用`logger.error()`记录错误信息。
4.函数命名必须以`fetch`或`post` 开头。
分享一个收集了很多Cursor规则文件的仓库:
https://github.com/sanjeed5/awesome-cursor-rules-mdc/tree/main/rules-mdc
现在,Cursor也能自动生成规则了。
我在之前分享的浏览器插件开发的文章就就有用到: https://mp.weixin.qq.com/s/R-EyuFpWy5GL5w4n715F-w
5️⃣ 持续重构:别让AI的“代码屎山”埋了自己
AI在反复修改后,会产生大量废弃、冗余的代码。这些“垃圾”不仅影响性能,还会在后续修改中误导AI,让它陷入歧途。
- 定期清理:要不断地让AI执行整理和清理操作,合并相似逻辑,删除废弃代码。
- 小心求证:清理时要格外小心!别让AI直接动手。先让它“给出清理方案”,你审查通过后,再让它“再三检查相关调用关系”,最后才执行删除。否则,它很可能大笔一挥,把正在使用的代码也给干掉了。
参考实践:
请分析 src/utils/dataProcessing.js 这个文件。里面有 processUserData 和 processAdminData 两个函数,逻辑非常相似。请不要直接修改,先提出一个重构方案,将它们的共用逻辑提取到一个新的、可复用的 processData 核心函数中,并说明如何修改原有两个函数来调用这个新函数。
6️⃣ 迭代调试:打不过就“换个姿势”再来
当AI对一个Bug反复修改都解决不了时,别跟它死磕,可以试试这些迭代调试的技巧:
- 新开聊天:试试新开一个chat,清空上下文,重新描述问题,可能会有奇效。
- 增加调试信息:让AI先别急着修复,而是“增加调试输出项”。然后你运行代码,把详细的报错信息、日志喂给它,让它基于更充分的信息再次分析。
- 引导AI自问自答:当AI对某个库不熟,表现为库里的方法名和数据类型乱编时,可以引导它:“请你进行多轮自问自答,找出可能的原因,并加日志定位。”
参考实践: (分步调试指令)
我的应用在点击保存按钮时崩溃了,控制台显示 TypeError: Cannot read properties of undefined。
第一步: 不要修复它。请在 src/pages/EditForm.js 的 handleSave 函数的入口处,添加 console.log 来打印所有传入的参数和相关的state值。
第二步: 把修改后的代码给我,我去复现问题并把日志发给你。
7️⃣ 全局视野:让AI“通读全文”再动手
我发现了一种高级用法,我称之为“全局视野”或“链式思辨”。有时候AI改不对,是因为它只看到了局部。
通过@folders等命令,强制AI阅读整个项目的核心代码和文档,让它建立起全局观。虽然这会消耗更多token,但对于复杂的修改,这是确保方向正确的必要投资。
参考实践: (全局上下文指令):
@folders(src/api, src/hooks, src/components/dashboard)
我需要创建一个新的图表组件。请分析 src/api 中的数据获取函数、src/hooks 中现有的数据处理hook,以及 src/components/dashboard 中已有的组件风格,然后为我生成一个新的 RevenueChart.js 组件,确保它复用了现有的数据流和样式规范。
8️⃣ 人工审查:你才是最终的“代码守门员”
我们必须拥有审查其代码质量、发现其逻辑谬误的能力。比如,你得能看懂AI写的代码,才能判断它的修改是否合理。
AI再强,也只是副驾驶。它可能会写出看似能跑但存在安全隐患的代码(比如把数据库key写在前端),这些都需要你亲自把关。记住,你才是最终的“代码守门员”。
参考实践:
你刚刚提供了一段用于处理用户输入的代码。现在,请切换到资深安全工程师的角色,重新审查这段代码,专门检查是否存在SQL注入或XSS跨站脚本的风险。以列表形式报告你发现的潜在问题和建议的修复方案。
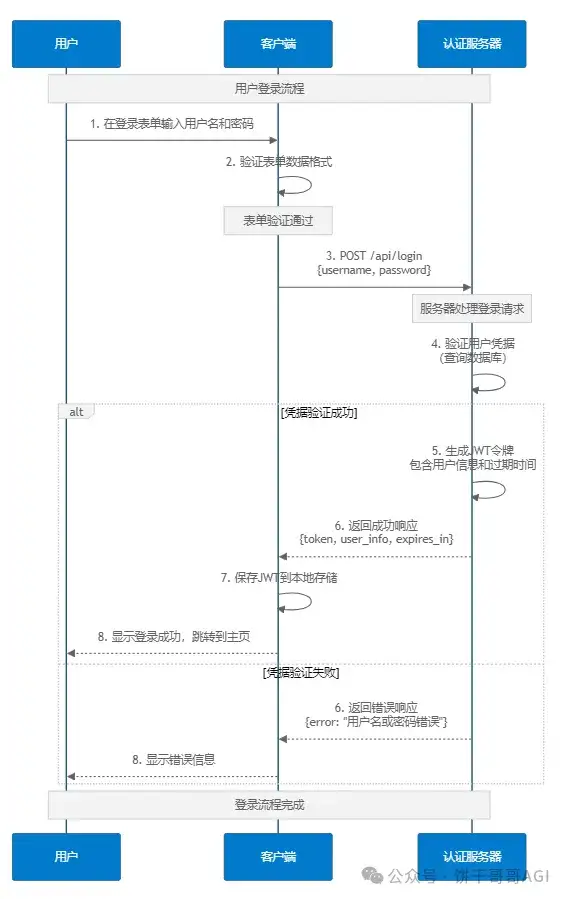
9️⃣ 可视化沟通:一张图胜过千言万语
当逻辑复杂时,纯文字沟通效率低下。一个非常有效的技巧是让AI输出流程图。新版的Cursor已经支持直接渲染Mermaid图表,这是一个非常强大的功能。在修改复杂逻辑前,让AI先生成流程图,你确认无误后,再让它写代码,可以避免大量返工。
参考实践:(Mermaid图表指令):
在编写登录流程的代码之前,请先为我生成一个Mermaid序列图(sequence diagram),清晰地展示以下流程:
用户在客户端提交表单。
客户端向认证服务器发送API请求。
服务器验证凭据。
服务器生成JWT并返回给客户端。
我将先确认图表逻辑,然后再让你继续写代码。
有这个图,跟Cursor沟通是不是就更清晰了?
(提醒:1.0版本后Cursor在对话框里就能直接画Mermaid图了)
🔟 善用工具:用MCP和Context7给AI“实时补课”
AI的知识库是滞后的,面对新框架、新API时常常“一本正经地胡说八道”。这里的解决方案就是利用MCP工具,比如Context7。
Context7能为AI实时提供最新、最准确的官方文档。当你要用某个库时,先让AI通过Context7阅读一遍最新文档,再进行开发,可以有效避免它使用过时的API。
参考实践:红温了!Cursor又乱写代码?1分钟装上Context7 MCP享受实时文档检索服务
对于开发网页相关功能的,可以使用PlaywrightMCP工具,让Cursor去看看自己到底写了啥:用Cursor「自动开发」Playwright网页自动化脚本,并打包成api给工作流调用
1️⃣1️⃣ 不当傻瓜:敢于追问“白痴”问题
我有一个重要的心得,就是不介意让自己当傻瓜。面对AI,不要有“形象包袱”。
遇到不懂的,哪怕是再基础、再白痴的问题,也要大胆问,反复问,让它用你听得懂的方式讲解。很多深层次的逻辑问题,就是在这种刨根问底中被发现的。
参考实践:
你建议我在这里使用 useCallback hook。我不太理解。请像对一个5岁的孩子解释一样(ELI5),告诉我为什么直接传递函数会导致性能问题,而 useCallback 是如何解决这个问题的。请用一个生活中的简单比喻。
1️⃣2️⃣ 氪金变强:别在生产力工具上“薅羊毛”
最后,也是最实在的一点:要舍得投资。
强大的模型(如GPT-o3、Claude 4)、更长的上下文、更快的响应速度,都需要成本。在能极大提升生产力的工具上,适当的“氪金”是非常明智的投资。别总想着薅羊毛,如果你看中AI带来的价值,这点投入几乎不值一提。
结构和控制是关键
总结下来,用好Cursor的核心,就是把它当成一个能力超强但心智尚不成熟的初级开发者。你需要提供清晰的指导(文档和规则) 、严格的审查(代码审查和测试)和持续的反馈(小步迭代和调试) 。掌握了这些,你的AI编程效率绝对能上一个新台阶!
你还有什么独家的“驯服”AI技巧吗?或者在使用中踩过什么大坑?欢迎在评论区留言交流,我们一起探索AI编程的更多可能!
以上,
文章来自于“饼干哥哥AGI”,作者“饼干哥哥”。
【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

