GraphRAG的索引速度慢,LightRAG的查询延迟高?
这些影响效率的难题,现在终于迎来改进——
由华东师范大学李翔老师带领的的Planing Lab团队推出高效解决方法E²GraphRAG。

该方法在大部分测试中接近了最优的GraphRAG方法。
并且值得关注的是,该方法在构建索引时间上是GraphRAG的1/10,在查询时间上是LightRAG的1/100。
动机与背景
现有的RAG方法中,大部分都是依赖于文本知识库,通过向量检索的方式,从中检索到与问题相关的一些文档片段作为补充知识。
这种方法难以实现对整个文档知识库的全局理解,比如通过普通RAG的方法,模型仍然无法回答“这篇小说的主旨是什么”这类问题。
为了解决对知识库的全局理解问题,RAPTOR提出了先对文档块进行聚类,然后递归构建文档总结树,然后在这个文档总结树上进行向量查询的方法,来引入不同粒度的信息;
GraphRAG则利用了大模型强大的信息抽取能力,由大模型从逐个文档块中抽取出三元组,然后构成一张图,之后再通过图分割算法分割成多个社区,再由大模型对社区进行总结,从而得到了不同粒度的信息。
然而,GraphRAG在图构建以及查询的过程中需要调用太多次大模型,导致其开销过重,难以实用。
为了解决这一问题,LightRAG让大模型一次性抽取出所有粒度的三元组,从而减少了总结不同社区带来的大模型调用开销;
FastGraphRAG则是在查询的过程中利用了PageRank算法来聚合全局信息,从而避免了查询时的大模型开销。
但是这些方法仍然面临一些问题:
每一个文档块需要调用一次大模型,带来的开销仍然相对较高;
严重依赖于大模型自身的能力,当模型参数量较小或者不支持Json格式输出的时候,这些方法难以实现;
需要手动设置查询模式,限制了其面对不同类型问题时的灵活性。
因此,本文中提出通过使用SpaCy来进行文档中的实体识别,利用实体之间的句中共现关系构成一张图,然后利用大模型对文档块按顺序递归总结,将其构建成不同粒度的文档总结树,之后结合利用图和树来进行查询,实现高效率、高性能。
方法
构建阶段
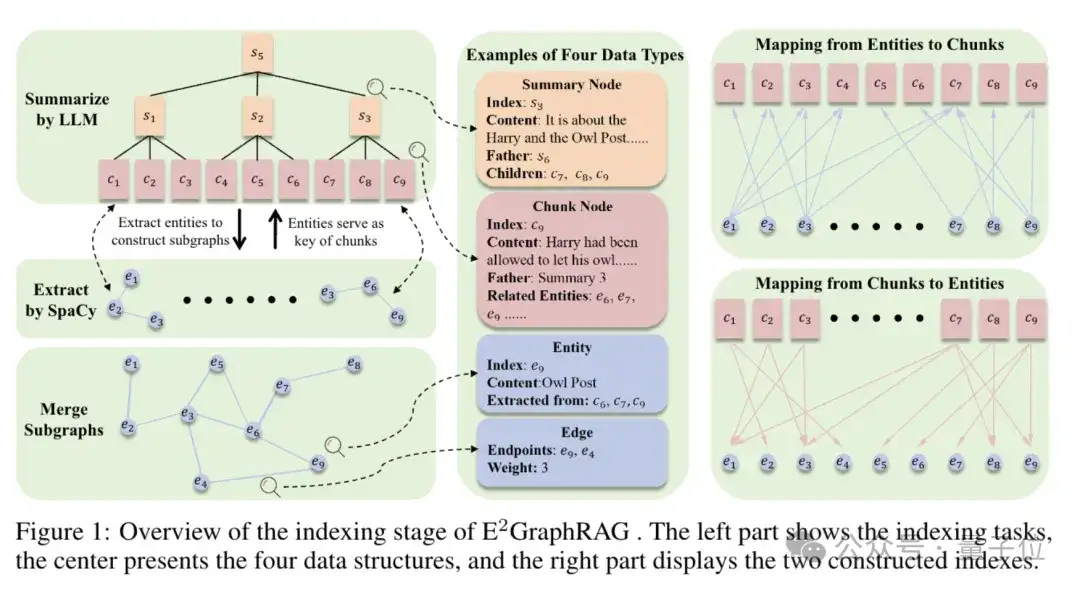
首先和普通RAG一样,先将长文档进行分块,本文中选取1200tokens一块,相邻块间有100tokens的重叠,follow了LightRAG的实验设置。然后构建阶段主要有两个任务:
利用LLM递归总结文档树:将文档块按照顺序排列,每g个文档块一组,交给大模型来进行内容总结,由于文档块是连续的,这里的相邻文档块之间的重叠可以合并,节约token消耗;
然后对于大模型生成的总结,继续每g个一组,进一步总结,构成一个文档树。
通过这种方式,团队得到了不同层次、不同粒度的信息,越接近根节点,信息越全局;
越接近叶子节点,信息越具体。
利用SpaCy抽取实体图:对于每一个文档块,团队利用SpaCy抽取其中的实体以及名词(他们可能是潜在的实体的代称),然后在同一句子内出现的实体以及名词之间构建连边,体现二者之间存在一定关系。
然后将所有的文档块对应的子图合并到一起,构成一个针对整个文档中的实体关系的实体图。
同时,团队构建两个index,来描绘文档和实体之间的关系,即文档块中抽取出哪些实体,一个实体能从哪些文档块中抽取出来。
通过这两个任务,团队得到了上图中的四种数据结构以及两个索引,即总结节点、文档节点、实体、边;以及实体到文档块的一对多索引,文档块到实体的一对多索引。
检索阶段
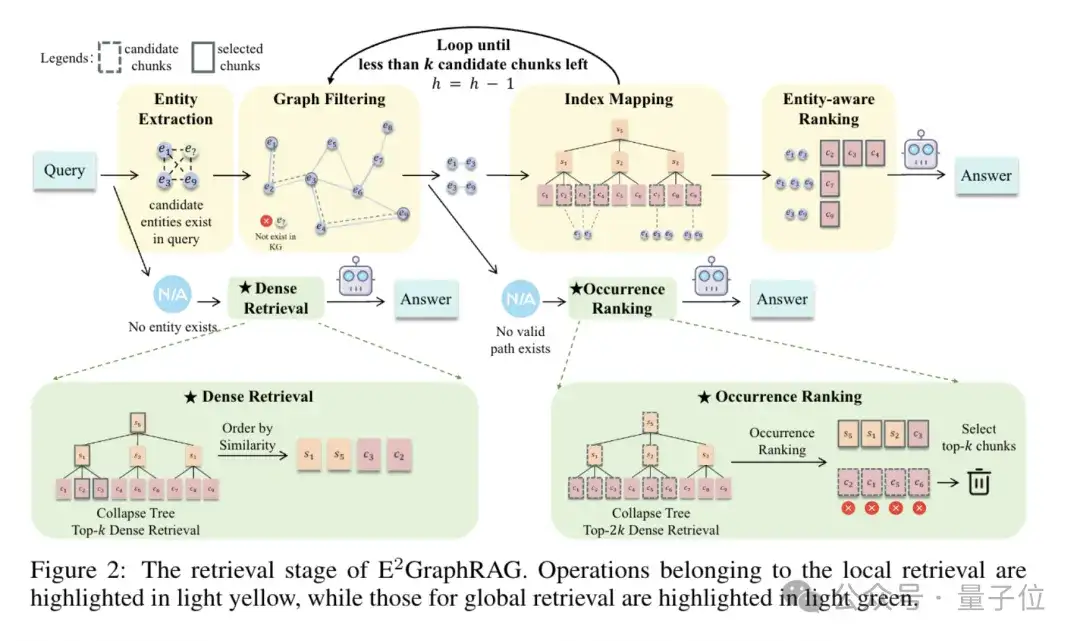

团队的检索方式可以根据问题的内容来自动选择local or global的检索方式,为了区分这两种检索方式,在下文中用斜体来表示global检索,以示区分。
同时团队提供了伪代码,其中标![]() 的是全局检索的部分。
的是全局检索的部分。
假设要检索最多k个文档块,具体步骤如下:
1.利用SpaCy从问题中抽取出来实体,然后将这些实体两两组合(无序),假设有n个实体,团队会得到*个候选实体对(即图中Entity Extraction步骤)。
2.如果步骤1中不存在实体,那么认为这是一个全局的问题,同时无法利用实体信息来辅助检索,直接通过向量检索的方式,从文档树上检索到相关的文档块。
3.候选实体对中肯定存在噪声,因此拿它到团队构建好的图中去过滤,即两个实体如果在图中的距离超过h跳,那么就认为他们是无关的,将其排除(即图中Graph Filtering步骤)。
4.根据上一步剩余的实体对数量,团队如果有剩余的实体,进行5的local检索,如果没有,则执行步骤6的全局检索:
5.如果有剩余的实体对,团队利用实体到文档块的索引将每个实体对中的两个实体映射到各自对应的文档块上,然后对这两个文档块集合取交集,即得到了和这两个实体均相关的文档块(即图中的Index Mapping步骤)。
6.如果没有剩余的实体对,那么也就意味实体并非紧密相关,那么这也更可能是一个全局查询,因此团队首先通过向量检索检索到树上的top- 2k个相关的文档块作为候选;然后由于问题中也有实体,因此实体可以辅助进行查询,即计算每一个候选文档块中实体的出现次数作为权重,如果这个候选文档块是总结块,那么其对应的权重即为其子节点的权重之和,向下一直递归。这样的设计自然会给总结块更高的权重,自然符合了这是一个全局查询的假设(即图中的Occurrence Ranking步骤)。
7.如果步骤5返回了超过k个文档, 那说明团队的约束太松,因此团队令h =h-1,然后重新执行步骤5,循环至只剩下不超过k个文档。
8.如果步骤7返回了0个文档,那么取缩紧约束之前的一个查询结果,从其中进行筛选,具体筛选指标为:
- 看这个文档包含了多少个不同的问题相关的实体;
- 看这个文档中问题相关的实体出现了多少次。
团队首先比较指标1,当指标1打平时,比较指标2,取最高的k个文档作为结果。
最后团队将其整理为实体1,实体2:文档内容的形式,输入给模型。
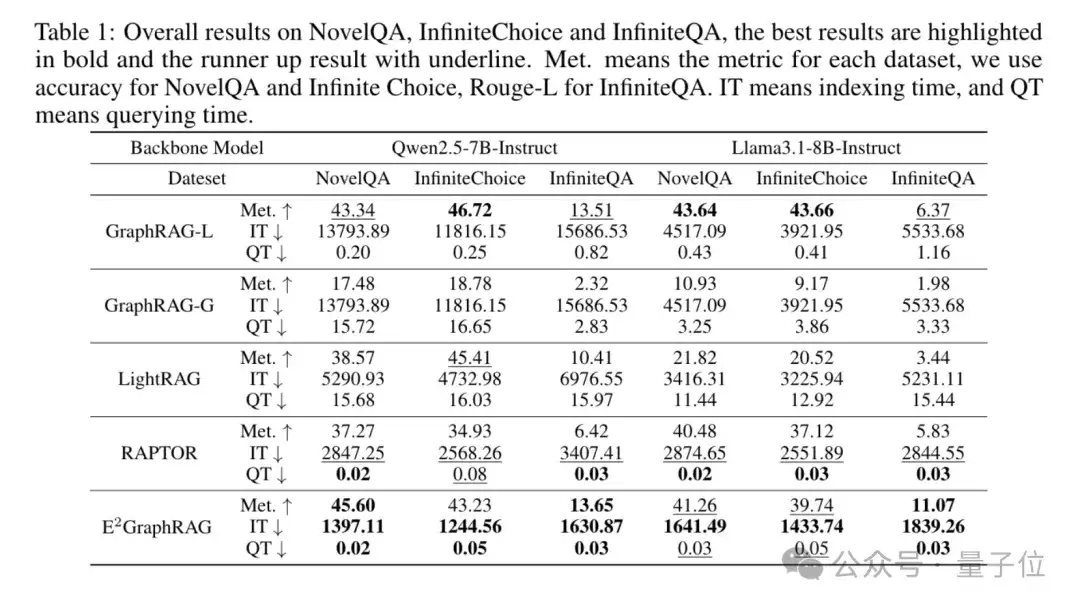
实验结果
团队在7-8B的相对易部署的模型上进行实验,确保了该方法在资源受限的情况下仍然能够有良好表现。
团队发现,该方法达到了最短的索引构建时间,同时没有带来查询的延迟。
在性能上,在大部分实验设置下超过或者接近了最优的GraphRAG方法,实现了效率与性能的均衡。
值得关注的是,该方法在构建索引时间上是GraphRAG的1/10,在查询时间上是LightRAG的1/100。
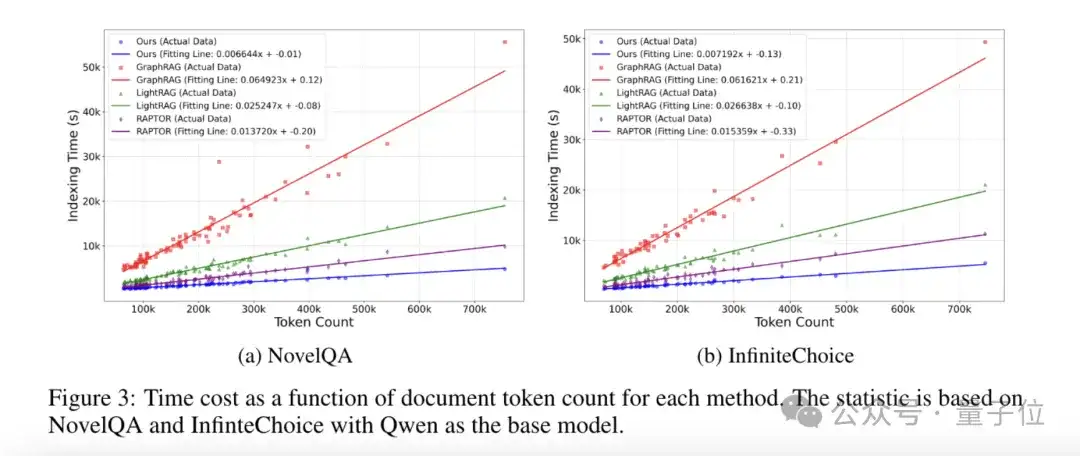
同时,团队绘制了文档token数量和构建索引时间的散点图,并且拟合成直线。
团队发现该方法构建索引时间随着文档token数量以最低的斜率线性增长,体现该方法可以扩展到更大的文档上。
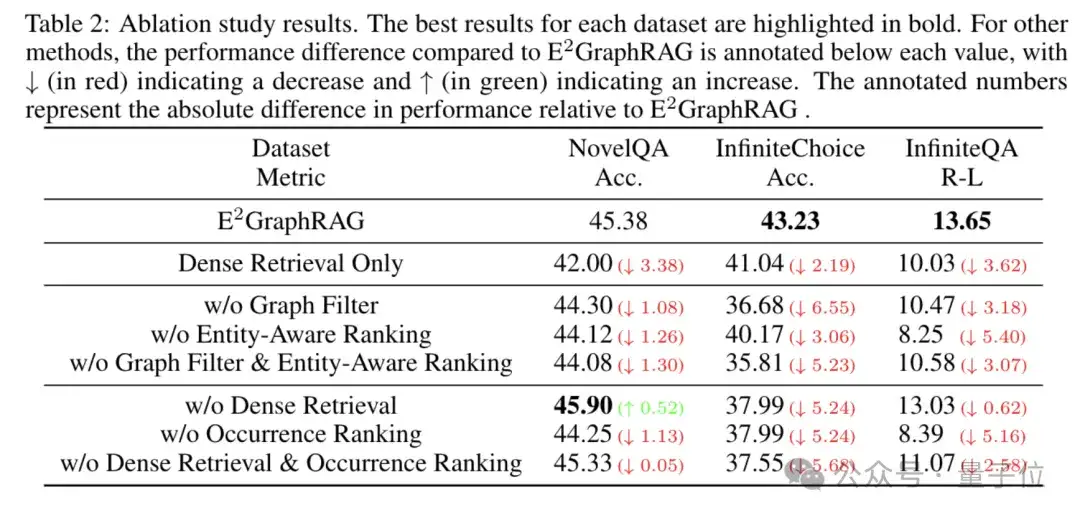
团队进一步进行了消融实验,三栏分别是:
- 针对团队整体方法必要性的消融:只用向量检索,确保团队的local-global检索系统是有效的;
- 针对local检索的消融:分别以及同时消去Graph Filter以及Entity-aware Ranking,确保团队的local检索的部件是有效的;
- 针对global检索的消融:分别以及同时消去Dense Retrieval以及Occurrence Ranking,发现在NovelQA上出现了一个异常的升高,可能是由于模型的幻觉导致的。
通过结合树与图,该团队达成了GraphRAG效率与效果的平衡,在该方法中,图主要用于信息点的关系发现以及过滤噪声,而树则主要用于提供具体不同粒度的信息内容,二者各有所长,相互依赖。
论文地址:https://arxiv.org/abs/2505.24226
代码仓库:https://github.com/YiboZhao624/E-2GraphRAG
文章来自于微信公众号“量子位”。
【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI


