扩散模型风头正盛,何恺明最新论文也与此相关。
研究的是如何把扩散模型和表征学习联系起来——
给扩散模型加上“整理收纳”功能,使其内部特征更加有序,从而生成效果更加自然逼真的图片。

具体来说,论文提出了Dispersive Loss——一种即插即用的正则化方法。
核心思想是,在模型输出的标准回归损失(如去噪)外,引入一个目标函数,用于对模型的中间表示进行正则化。
这有点类似于对比学习中的排斥效应。但相较于对比学习,其独特的优势在于:
- 无需正样本对,避免了对比学习中的复杂性;
- 具有高度通用性,可以直接应用于现有扩散模型,不需要修改模型结构;
- 计算开销低,几乎不增加额外的计算成本;
- 与原始损失兼容,不干扰扩散模型原有的回归训练目标,易于在现有框架中集成。
让中间表示在隐藏空间中分散
一起来看论文细节。
何恺明和合作者Runqian Wang的出发点有三:
- 扩散模型的局限性
扩散模型在生成复杂数据分布方面表现出色,但其训练通常依赖于基于回归的目标函数,缺乏对中间表示的明确正则化。
- 表征学习的启发
表征学习(特别是对比学习)通过鼓励相似样本靠近、不同样本分散,能有效学习通用表示。
对比学习在分类、检测等任务中已经取得成功,但在生成任务中的潜力尚未被充分探索。
- 现有方法的不足
REPA(表征对齐)等现有方法尝试通过对齐生成模型的中间表示和预训练表示来改进生成效果,但存在依赖外部数据、额外模型参数和预训练过程的问题,代价高昂且复杂。
他们开始考虑,如何借鉴对比自监督学习,鼓励生成模型的中间表示在隐藏空间中分散,从而提高模型的泛化能力和生成质量。
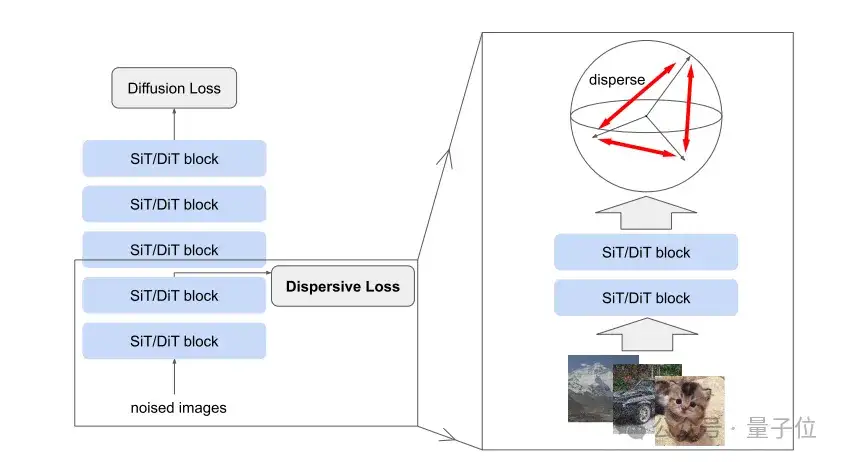
基于这样的核心思想,他们设计了Dispersive Loss:通过正则化模型的中间表示,增大中间表示的分散性,使其在隐藏空间中分布得更加均匀。
与对比学习的不同之处在于,在对比学习中,正样本对需要通过数据增强等方法手动定义,并通过损失函数将正样本对拉近、负样本对分开。
Dispersive Loss则不需要定义正样本对,仅通过鼓励负样本对之间的分散性来实现正则化。

可以看到,Dispersive Loss的实现非常简洁,不需要额外的样本对或复杂操作,可以直接作用于模型的中间层表示。
并且不仅支持单层应用,也支持多层叠加——理论上可以在多个中间层同时应用Dispersive Loss,进一步增强不同层级特征的分散性。
实验结果
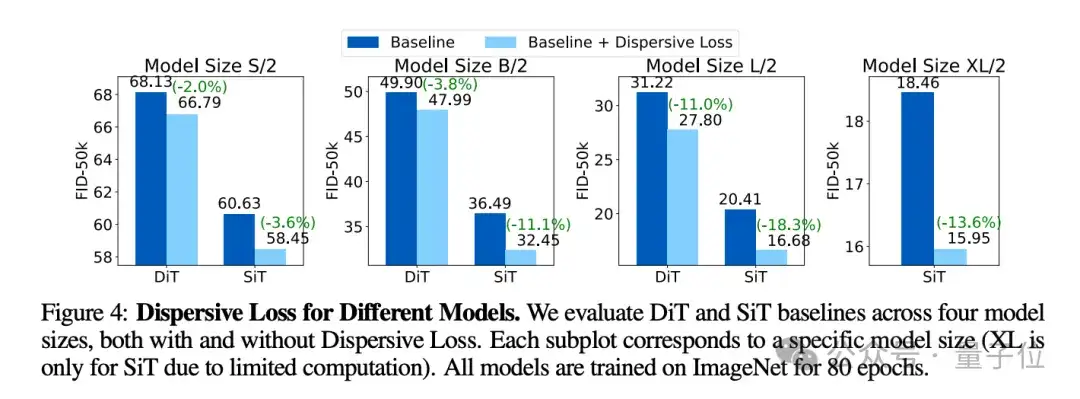
作者在ImageNet上,使用DiT和SiT作为基线模型,对不同规模的模型进行了广泛测试。
结果显示,Dispersive Loss在所有模型和设置中均提高了生成质量。比如,在SiT-B/2模型上,FID从36.49降到了32.45。
与REPA方法相比,Dispersive Loss不依赖预训练模型或外部数据,生成质量则并不逊色。
在SiT-XL/2 模型上,Dispersive Loss的FID为1.97,而REPA的FID为1.80。

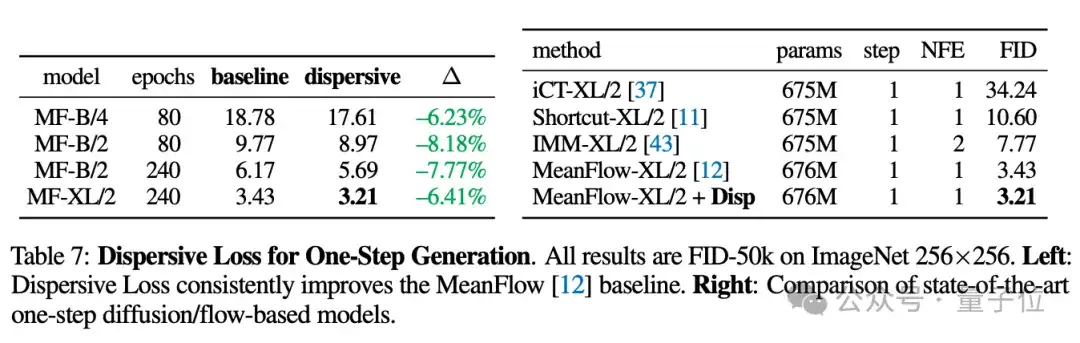
另外,无论是多步扩散模型还是单步生成模型,都能基于Dispersive Loss得到明显改进。
作者认为,不仅是在图像生成任务上,Dispersive Loss在图像识别等其他任务上也具有潜力。
论文地址:
https://arxiv.org/abs/2506.09027v1
文章来自于微信公众号“量子位”。


