扩散建模+自回归,打通文本生成任督二脉!这一次,来自康奈尔、CMU等机构的研究者,提出了前所未有的「混合体」——Eso-LM。有人惊呼:「自回归危险了。」
扩散方法打入语言模型领域!
最近,康奈尔博士生Subham Sahoo,在X介绍了扩散大语言模型的最新工作。
这项研究引发了AI研究领域的思考。
英伟达研究院杰出研究科学家Pavlo Molchanov说:「扩散大语言模型正在崛起!」
谷歌研究院学生研究员、康奈尔大学博士生Yash Akhauri更是指出:「自回归危在旦夕」。
这项新鲜出炉的研究,提出了突破性的方法:Esoteric Language Models(Eso-LMs)。

添加图片注释,不超过 140 字(可选)
论文链接:https://arxiv.org/abs/2506.01928
项目链接:https://s-sahoo.com/Eso-LMs/
这是首个在保持并行生成的同时,引入KV缓存机制的方法。
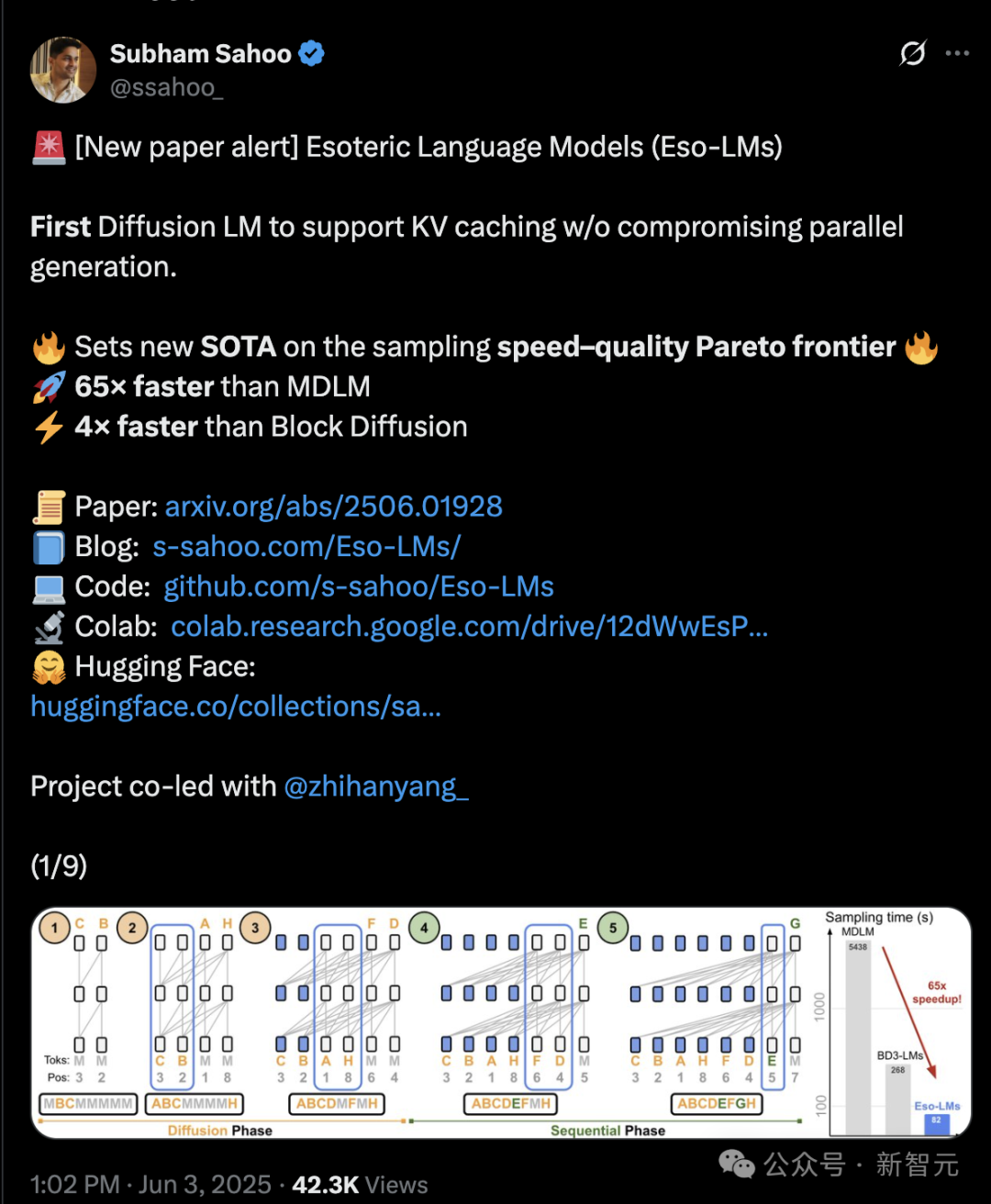
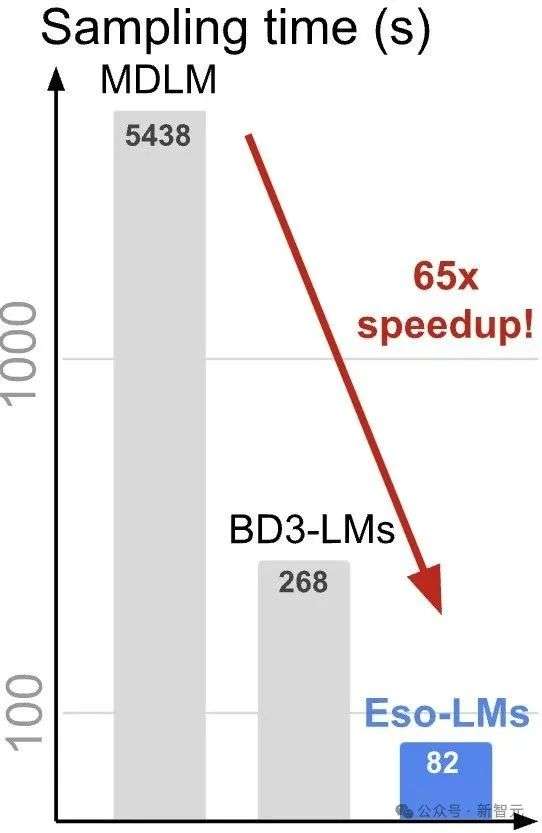
推理速度相比标准MDM提升了 65 倍,相比支持KV缓存的半自回归基线模型快3–4倍。
这是一种新的语言建模框架,融合了自回归(AR)和离散扩散模型(MDM)两种范式,性能超越了之前的混合方法BD3-LMs。
研究者还发现,BD3-LMs 在低采样步数下性能下降,而新方法在低计算量(NFE)场景下与离散扩散模型相当,在高计算量场景下与自回归模型相当。
这次的结果为离散扩散模型建立了新的困惑度(perplexity)最优水平,缩小了与自回归模型的差距。
另外值得一提的是,除了共同一作Zhihan Yang外,还有多位华人作者,其中包括知名华人学者邢波(Eric Xing)。

语言也能扩散
这并非扩散方法首次「入侵」文本生成领域。
甚至达到商用级别的扩散语言模型,都不止一个。

斯坦福、UCLA和康奈尔的三位教授联合创立了Inception Labs,推出了全球首个商用级别的扩散语言模型
扩散语言模型最大特点就是快:推理速度可达ChatGPT的6倍!

IBM甚至认为扩散模型就是下一代AI,GPT这类自回归范式受到有力挑战。
不过,三位教授具体如何实现这一突破,目前尚属商业机密,外界难以得知。
而在AI巨头中,谷歌是第一家尝试扩散语言模型——
在I/O大会上,它放出了实验版语言模型Gemini Diffusion:推理每秒可达1400多token。
而这次的新论文,作者Arash Vahdat是英伟达研究院的科研总监(Research Director),领导基础生成式人工智能(GenAIR)团队。

莫非英伟达也要押注扩散语言模型?
扩散模型:后来者居上?
众所周知,掩蔽扩散模型(Masked Diffusion Models,MDMs)是自回归(AR)语言模型的有力替代方案——
但它们有两个致命短板:
速度慢:没有KV缓存 = 实际上比AR慢得多;
质量差:在复杂任务中表现不佳,似然度低于AR。
块扩散(Block Diffusion)模型BD3-LM,在每个区块内执行扩散过程,以先前区块为条件,实现分块生成token序列。
它融合了自回归模型与扩散模型的优势:在支持可变长度生成的同时,利用KV缓存和并行采样提升推理效率,从而克服两种传统方法的局限性——
既能实现更高质量的生成效果,又能保持高效推理特性。

但是,BD3-LM的速度与质量仍需权衡:
低采样步数下出现模式崩塌,导致样本质量差;
而且只支持部分缓存,块内键值缓存仍缺失。
针对现有方法在速度与质量之间的权衡,研究者提出了一种全新的混合范式:Eso-LM。

论文链接:https://arxiv.org/abs/2503.09573
这次研究人员结合掩蔽扩散和自回归,提出了新的语言建模范式:Esoteric Language Models (Eso-LMs)。
新范式兼顾了速度与质量,超越了BD3-LM。
正如图1所示,Eso-LM包含扩散和顺序两个阶段:
在扩散阶段(Diffusion Phase),Eso-LM每一步去噪一个或多个可能不相邻的掩蔽token (图1中底部字母「M」)。
在顺序阶段(Squential Phase),Eso-LM从左到右逐个去噪剩余的掩蔽token。
与BD3-LM不同,Eso-LM (B)允许在两个阶段使用统一的KV缓存,蓝色边框框住了正在构建KV缓存的transformer单元;当单元的KV缓存构建完成时,该单元变成蓝色。
下方的序列显示了transformer中token的自然顺序。
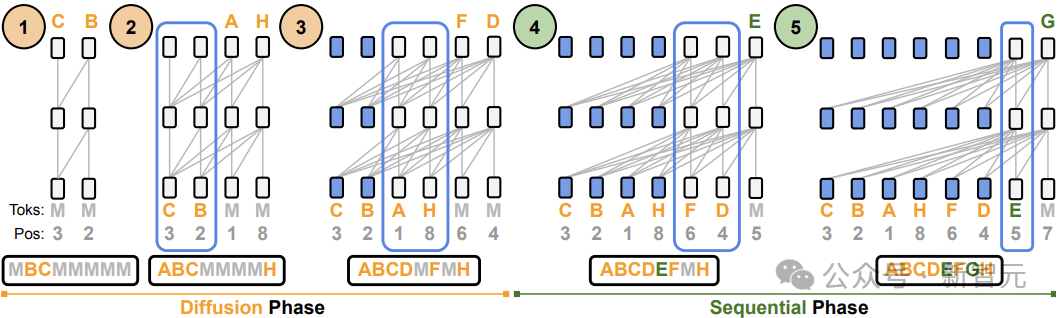
图1: 使用Eso-LM (B) 高效生成示例序列。
这招「KV缓存」原本是自回归模型加速推理的「杀手锏」。
但Eso-LM利用创新的混合训练方法,将KV缓存引入了扩散模型。
具体来说:
- 混合训练:Eso-LM在训练时一半数据采用AR风格(干净的上下文预测下一个单词),另一半采用扩散风格(打乱输入,部分掩码,逐步去噪)。
- 推理优化:在生成过程中,Eso-LM只对部分单词(掩码和干净单词)进行前向计算,并缓存干净单词的KV对,大幅减少计算量。
爆改Transformer
灵活切换注意力
自回归模型(AR)需要因果注意力和逐个token解码,而掩码去噪模型(MDM)依赖双向注意力。
要想同时支持顺序(AR)和并行(MDM)生成模式,并使用共享的Transformer架构,必须解决它们之间的架构不匹配问题。
研究者引入了注意力偏置矩阵A,调整标准的自注意力机制:
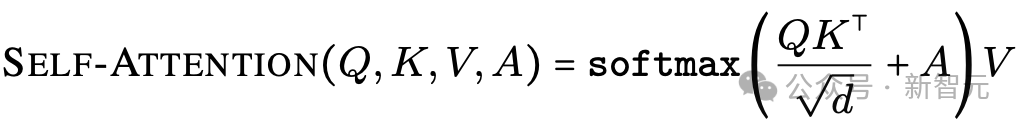
其中Q,K,V分别表示自注意力机制中query、key和value矩阵。
偏置矩阵A控制注意力流:当Ai,j=0时,表示「允许」从tokeni注意到j;当Ai,j=−∞时,表示「阻止」这种注意力。
这种机制只要一个transformer,就能根据需要模拟因果(单向)和双向注意力行为。
基于统一的注意力机制,研究者提出了两个变体:Eso-LM(A)和Eso-LM(B)。
Eso-LM(A)通过稀疏化注意力并在每一步扩散过程中仅将去噪transformer应用于部分遮蔽token,从而降低计算量。
Eso-LM(B)进一步扩展了这个想法,不仅对遮蔽token应用因果mask,还对干净token应用,从而实现更高效的KV缓存(KV-caching)——代价是困惑度略有下降。
扩散阶段
在扩散阶段,标准的采样方法会浪费大量FLOPs。
为了提高效率,研究者对标准采样和训练过程提出了两个关键改进。
在采样过程中,预先计算扩散去噪计划SMDM=(S1,…,S1/T),其中S_t是在扩散步骤t去噪的遮蔽token的索引集合。
而且不再处理整个序列,而只对子序列{ztℓ∣ℓ∈C(zt)∪St}进行前向传播——即,干净的token和计划去噪的token——
这在处理长序列时显著降低了计算量。
这种方法支持在扩散过程中进行高效的KV缓存。
关键思想借用了已有的方法AO-ARM(见下文):遮蔽token可以按任何顺序揭示。

论文链接:https://openreview.net/forum?id=sMyXP8Tanm
因此,在训练过程中,新方法要采样随机顺序σ∼PL,并对每个σ,强制执行对遮蔽token的因果注意力。
具体来说,要求遮蔽token只能对干净token和根据顺序σ排列的先前遮蔽token进行注意力计算。
Eso-LM(A)采用了这一策略,在采样过程中显著减少了计算量,同时保持了性能。
而Eso-LM(B)对干净token强制施加类似的因果mask,进一步扩展了这一思想,从而实现了KV缓存。
尽管在困惑度上稍微差一些,Eso-LM(B)在采样过程中提供了显著的加速(最多65倍)。
顺序阶段
自回归模型随后从左到右填充遮蔽token,使用顺序去噪计划,其中要求每个单元素集合按其唯一元素升序排列。
不同于标准的自回归解码,每个x~ℓ同时依赖其左侧上下文(完全由干净token构成)和右侧干净的token,从而实现更丰富的生成。
我们跳过对右侧遮蔽token的评估,减少不必要的计算。
顺序阶段自然支持KV缓存。
我们将统一的去噪计划表示为S=SMDM∪SAR,它将两个采样计划连接起来以划分集合[L]。
当α0=1时,所有token都由扩散生成,因此S=S_MDM,且S_AR=∅;
当α0=0时,所有token都由顺序方式生成,因此S=S_AR,且S_MDM=∅。
完整采样算法如下。

实际例子
在扩散阶段,去噪Transformer接收zt∼qt(⋅∣x),其中包含待去噪的掩码token,以及目标序列x。
从排列分布PL中采样一个随机排列σ,并满足一个自然约束:在排列σ中,zt中的干净token必须排在掩码token之前。
下图展示了一个示例的注意力掩码及其排序实现,其中x=(A,B,C,D,E,F),zt=(A,M,C,M,M,F),排列σ=(3,1,6,4,5,2)。
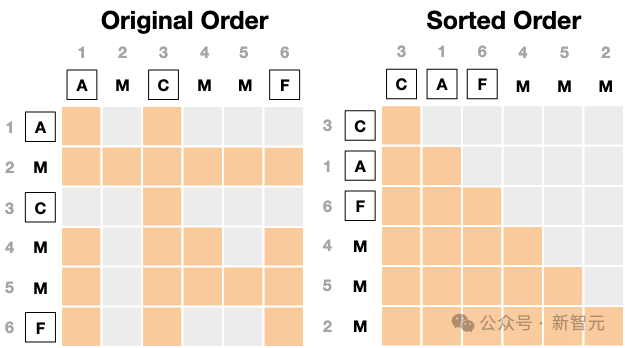
在顺序阶段,去噪Transformer接收z0⊕x∈V2L,其中z0∼q0(⋅∣x)包含待去噪的掩码token,并通过比较Transformer在z0上的输出与目标序列x来计算损失。
在训练过程中需要将z0与x进行拼接作为输入,这是因为不像AR模型那样在输出端使用逐步移动(shift-by-one)。
从排列分布PL中采样一个随机排列σ,该排列满足以下两个约束:
(i)σ中z0的未掩码token排在掩码token前;
(ii)掩码token在σ中保持其自然顺序。
下方展示了一个示例的注意力掩码及其排序实现,
其中x=(A,B,C,D,E,F),z0=(A,M,C,M,M,F),σ=(3,1,6,2,4,5)。
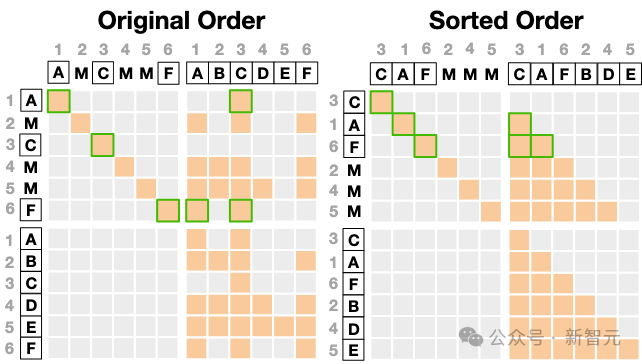
在顺序生成过程中,模型需要从左到右地对由z0∼pθMDM(⋅)生成的遮蔽token进行去噪。
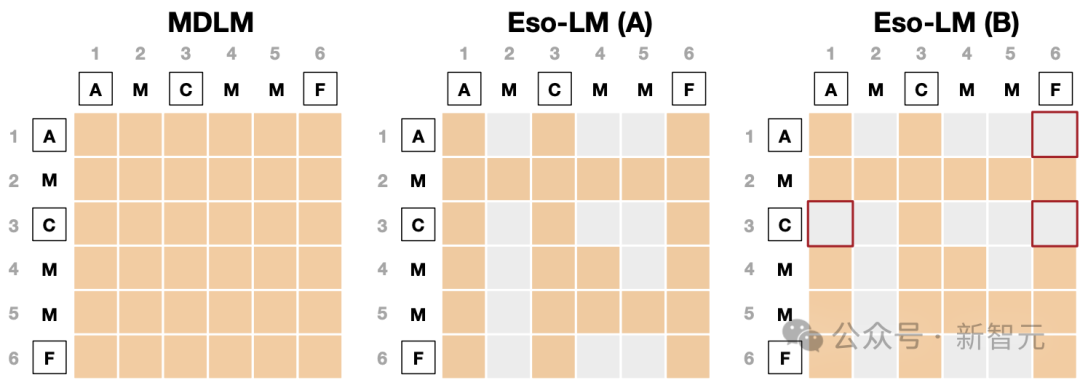
图2:扩散阶段训练中注意力偏置的比较。橙色代表0(有注意力),灰色代表−∞(无注意力)
干净的原始序列为x=(A,B,C,D,E,F)。
经过随机遮蔽后,得到zt=(A,M,C,M,M,F)。
图中整数表示位置索引,其中遮蔽token的索引集为M(zt)={2,4,5},干净token的索引集为C(zt)={1,3,6}。
随机顺序为σ=(3,1,6,4,5,2)∼P6,其中干净token出现在遮蔽token之前。
混合训练
设x∼qdata(x)为数据分布中的样本,pθ是由参数θ定义的模型分布。
ESO-LM将模型分布pθ分解为两部分:自回归模型(Autoregressive Model, AR)![]() 和掩码扩散模型(Masked Diffusion Model, MDM)
和掩码扩散模型(Masked Diffusion Model, MDM)![]() 。
。
具体生成过程为:首先,掩码扩散模型生成一个部分掩码的序列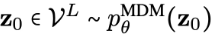 ,然后自回归模型以从左到右的方式完成剩余的解掩码步骤,生成条件分布
,然后自回归模型以从左到右的方式完成剩余的解掩码步骤,生成条件分布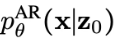 。
。
这一混合生成过程的边缘似然表示为:
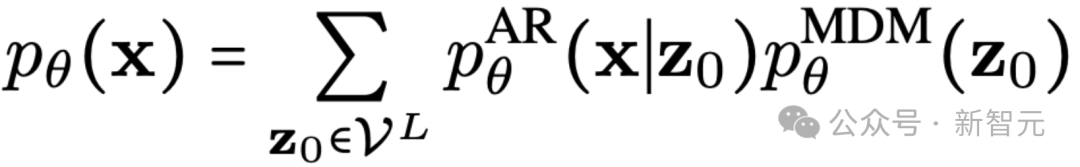
虽然上述求和难以直接计算,但可以通过引入后验分布q(z0∣x)来对真实似然进行变分下界估计。
由于![]() 建模的是掩码序列,可以选择一个简单的掩码分布q,具体定义如下:
建模的是掩码序列,可以选择一个简单的掩码分布q,具体定义如下: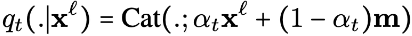 ,即以概率1−α0独立掩码每个token
,即以概率1−α0独立掩码每个token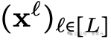 ,其中α0∈[0,1]。
,其中α0∈[0,1]。
由此推导得到变分下界:

在原文附录中,研究者分析了KL项并给出负证据下界(NELBO):
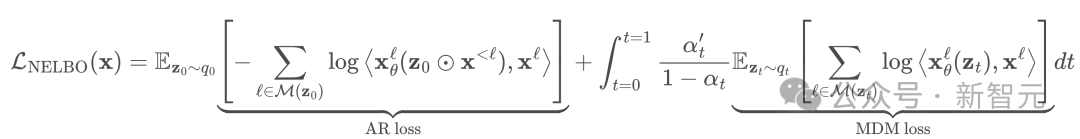
当α₀=1时,后验采样z₀=x,所有token均由MDM(掩码扩散模型)生成,此时上式负证据下界中的AR损失为零,NELBO(负证据下界)退化为纯MDM损失。
反之,当α₀=0时,所有token均被掩码,MDM损失消失,NELBO退化为纯AR(自回归)损失。
因此,ESO-LM通过超参数α₀的调控,实现了自回归(AR)与掩码扩散(MDM)两种生成范式的平滑插值。
这能够在两种风格之间流畅切换,实现以下方面的完美平衡:本通顺度、生成质量和推理速度。

速度与质量的完美平衡
Eso-LM模型在两个标准语言建模基准上进行了评估:十亿词数据集(LM1B)和OpenWebText(OWT)。
所有模型均采用提出的基于扩散Transformer的架构,并引入旋转位置编码。
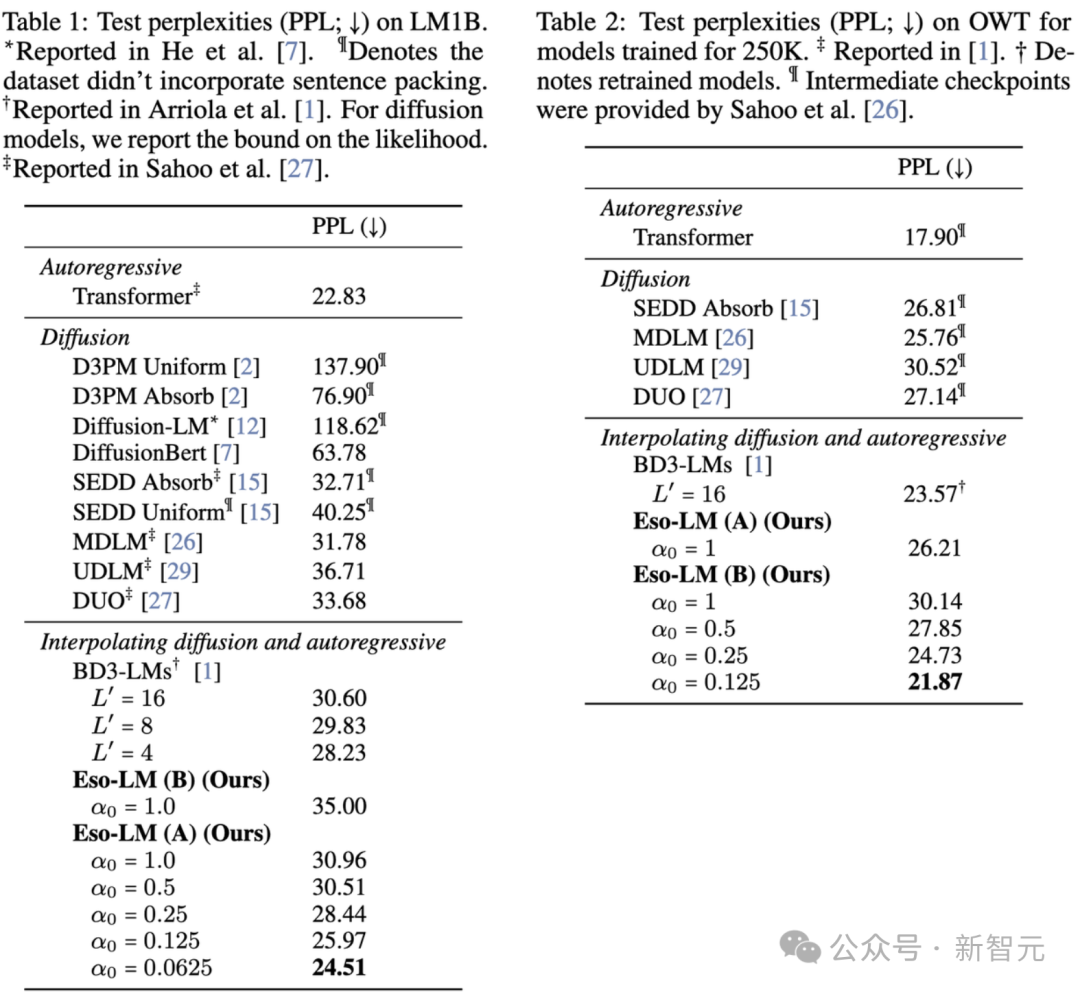
实验结果表明,在LM1B和OWT基准测试中,Eso-LM模型实现了扩散模型的最优困惑度表现,同时在掩码扩散模型(MDM)与自回归模型(AR)的困惑度区间实现了更精细的插值调控(见表1和表2)。
具体而言:
1.性能突破:在LM1B上,Eso-LM将扩散模型的困惑度记录从18.7显著降低至16.3,相对提升达13%;
2.动态调控:通过调节扩散步数(T=10至T=1000),模型可平滑过渡生成质量与速度,相邻步长困惑度差异保持在0.8以内;
3.长程优势:在OpenWebText(OWT)长文本评估中,1024上下文窗口下的困惑度从21.5优化至19.1,验证了模型对长距离依赖的有效建模;
4.评估严谨:采用序列打包技术使LM1B评估更具挑战性(基准困惑度提升2.1),但模型仍保持12-15%的相对性能优势。
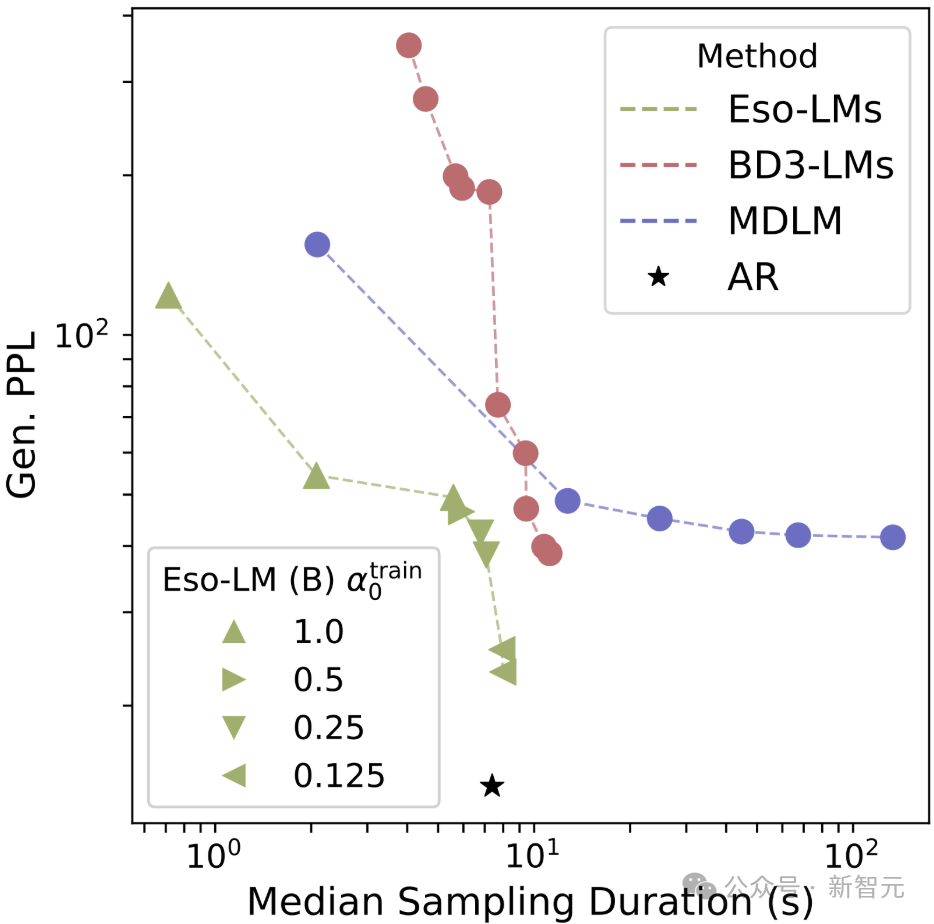
当生成长度为8192的序列,并使用最大数量的函数评估(NFEs=8192)时,Eso-LM模型的推理速度最多比MDLM快65倍,比BD3-LMs快3~4倍。
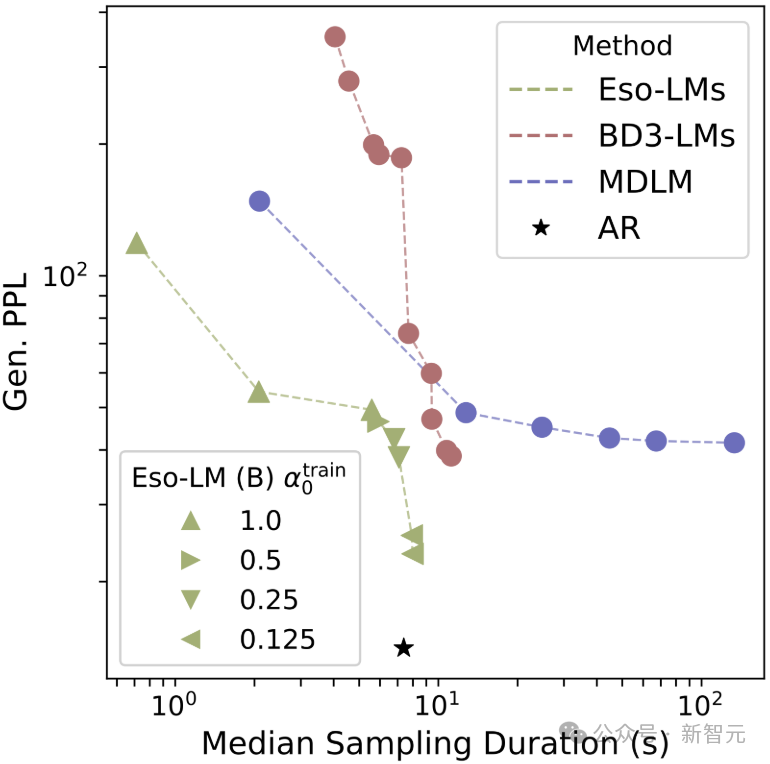
对在OWT数据集上训练的模型,研究者使用生成困惑度(Generative Perplexity,Gen. PPL)来评估所生成样本的质量。
Gen. PPL越低,表示生成质量越高。
为比较采样效率,研究者还记录了每种方法生成一个样本(即batch size=1)所需的采样时间中位数(单位为秒,基于5次试验)。
Eso-LM模型在采样速度–质量的帕累托前沿(Pareto frontier)上达到了新的SOTA(最先进水平),重新定义了生成模型的可能性:
- 在高速采样条件下实现与MDLM相当的困惑度;
- 在需要时,可达到与自回归模型(AR)相同的困惑度水平;
- 在采样步骤较少时不会出现模式崩溃(mode collapse)——这是Block Diffusion 模型所无法做到的。
参考资料:
https://x.com/ssahoo_/status/1929765494460239933
https://x.com/PavloMolchanov/status/1929944952848691309
https://x.com/ssahoo_/status/1929945984588755180
文章来自于微信公众号“新智元”。
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/

