研究人员发现,大语言模型的遗忘并非简单的信息删除,而是可能隐藏在模型内部。通过构建表示空间分析工具,区分了可逆遗忘和不可逆遗忘,揭示了真正遗忘的本质是结构性的抹除,而非行为的抑制。
近年来,大语言模型(LLM)的能力突飞猛进,但随之而来的隐私风险也逐渐浮出水面,训练数据中的敏感信息也会被模型「记住」,并在推理阶段暴露出来。
在此背景下,机器遗忘(Machine Unlearning)技术应运而生,其目标是在不影响整体能力的前提下,有选择性地抹除特定知识。
然而,当前评估方法主要聚焦于token级别的表现(如准确率、困惑度),这些表层指标真的足以说明模型已「遗忘」?
最近,香港理工大学、卡内基梅隆大学和加州大学圣克鲁兹分校的研究人员首次揭示了遗忘现象背后的表示结构变化规律,通过构建一套表示空间的诊断工具,系统性地区分了「可逆性遗忘」与「灾难性不可逆遗忘」的本质差异。
论文中整理成了一个统一的表示层分析工具箱(PCA相似度与偏移、CKA、Fisher信息),支持诊断大模型在Unlearning / Relearning / Finetuning等过程中的内在变化。

论文地址:https://arxiv.org/abs/2505.16831
工具箱地址:https://github.com/XiaoyuXU1/Representational_Analysis_Tools.git
研究人员在多种方法(GA、NPO、RLabel)、数据集(arXiv、GitHub、NuminaMath)与模型(Yi-6B、Qwen-2.5-7B)上进行了全面实证,并从参数扰动角度揭示遗忘可逆性的理论依据。
模型遗忘
真正的遗忘,是结构性的抹除,而非行为的抑制
研究人员提出:「一个模型若仅仅在token输出上『忘记』,而其内部结构几乎未变,那它随时可以恢复原样。」
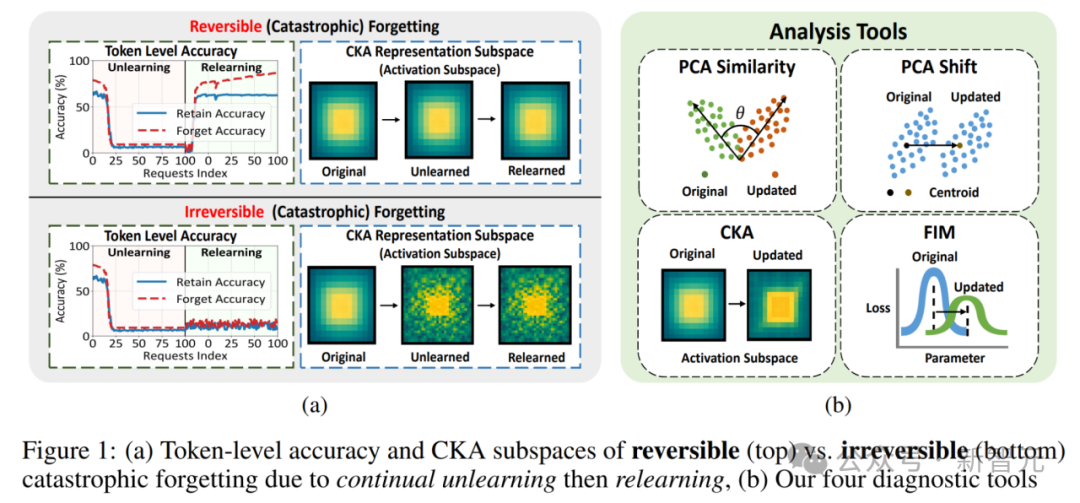
上图左侧(a)展示了两种典型遗忘场景:
- 上方:虽然Unlearning阶段准确率急剧下降,但Relearning之后快速恢复,表示空间保持稳定,属于可逆(灾难性)遗忘;
- 下方:虽然行为表现下降,但结构严重扰动,重训练也难以恢复,属于不可逆(灾难性)遗忘。
右侧(b)则展示了研究人员构建的表示空间分析工具,包括PCA Similarity / Shift、CKA相似性分析、Fisher信息矩阵(FIM)。
表征空间分析揭示了「遗忘的可逆边界」
研究人员在Yi-6B模型上对不同方法(GA, GA+KL, NPO, RLabel)进行了单次遗忘实验,比较了三种指标:
- MIA:攻击者能否识别遗忘目标是否出现过;
- F.Acc:遗忘样本的准确率;
- R.Acc:保留样本的准确率。
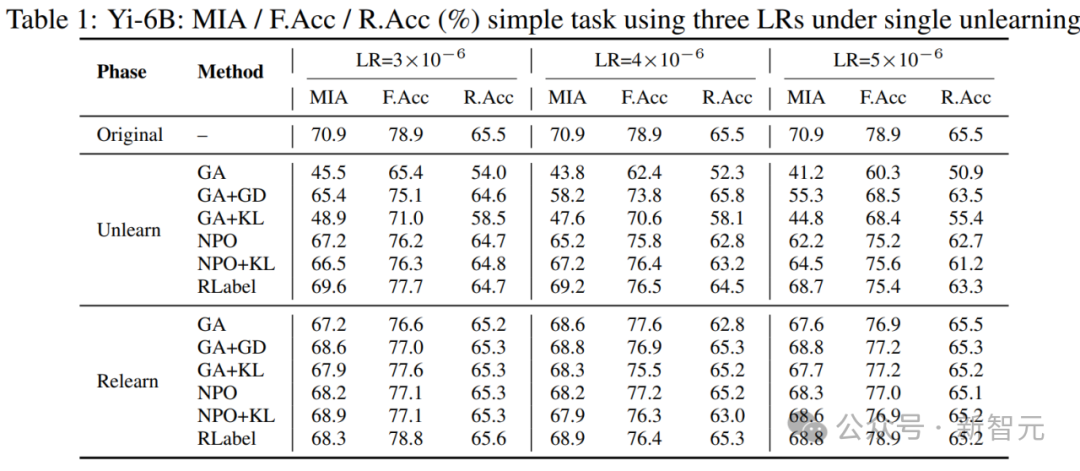
在不同学习率下,多种方法的单次遗忘结果对比
进一步,研究人员探究了不同请求数量(N)和学习率(LR)组合下的变化:
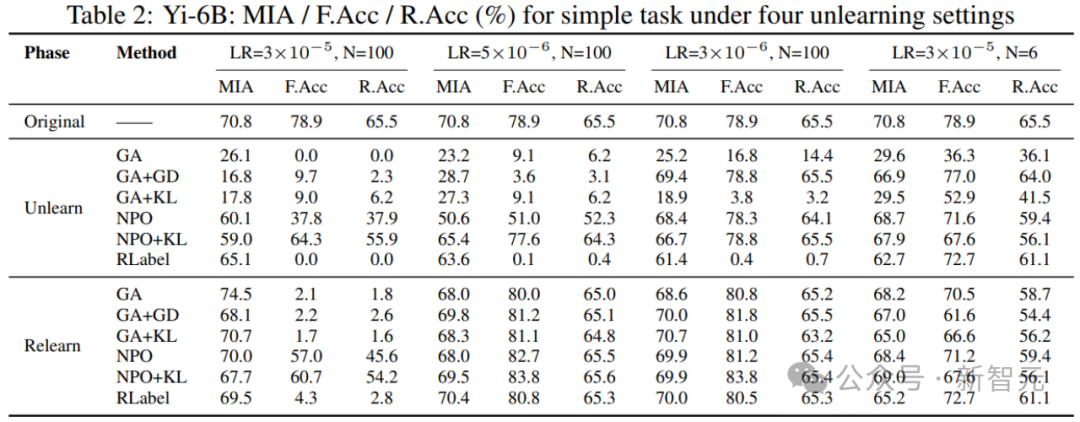
在持续遗忘场景下,更大规模的遗忘实验配置(N×LR组合)下的性能波动
可视化诊断:模型真的「忘记」了吗?
PCA Similarity:衡量表示空间主方向变化
可以发现,对于可逆性遗忘,其表示空间在Relearning后高度恢复原始主方向,而不可逆性遗忘则呈现广泛漂移:
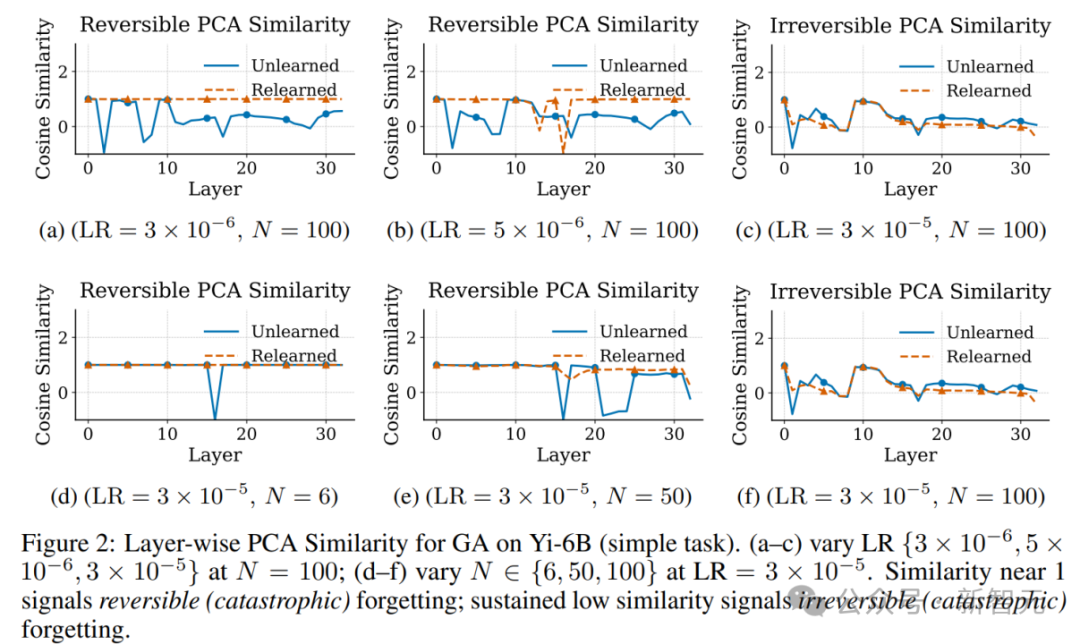
各层PCA主方向变化(Cosine相似度)分析
PCA Shift:量化表示分布中心的偏移程度
对于不可逆性遗忘,其「表示漂移」不仅方向变化,更伴随大尺度的空间位移,Relearning难以还原:
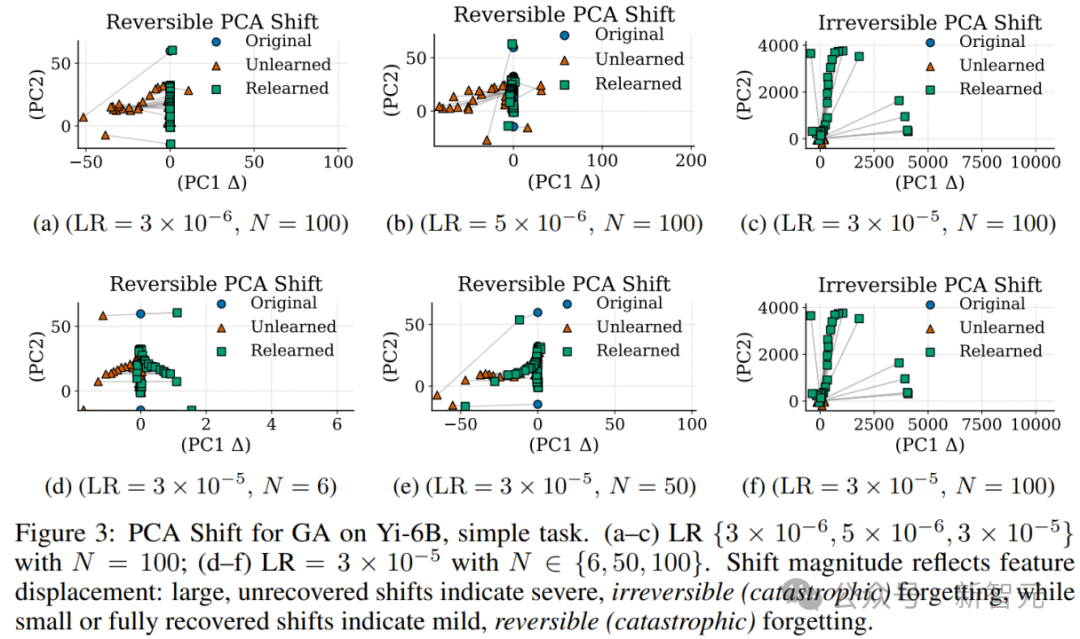
各阶段的PCA散点漂移示意图
CKA:表示空间结构相似性分析
Linear CKA可以测量各层之间的结构保留程度。
可逆性场景下,CKA几乎未受破坏,而不可逆性场景则迅速退化为低相关结构:
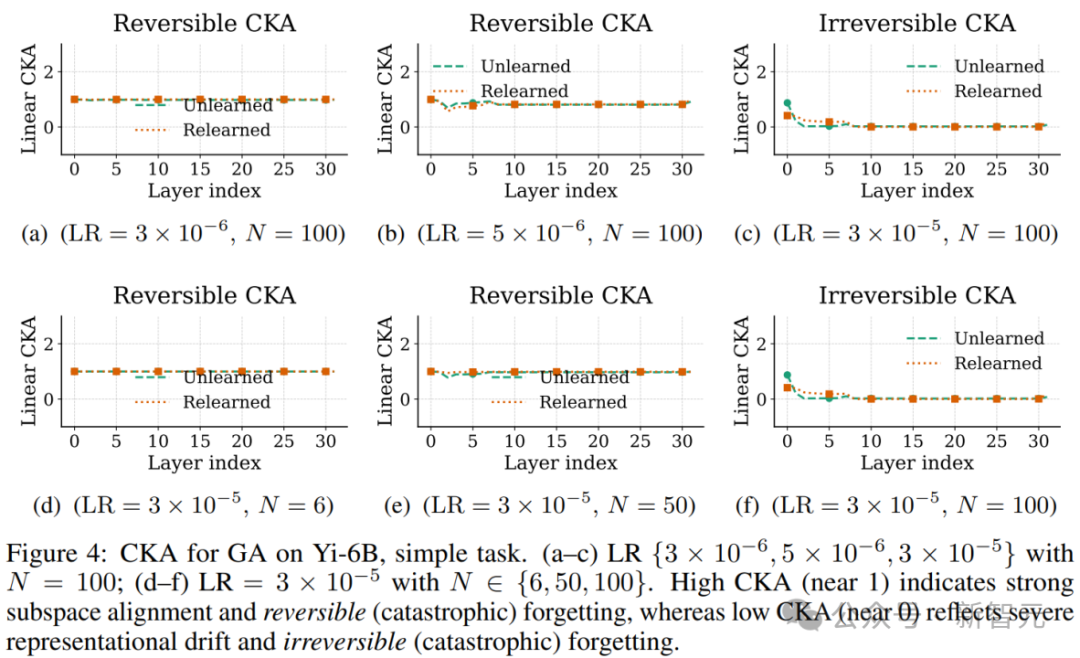
CKA曲线分析(逐层)
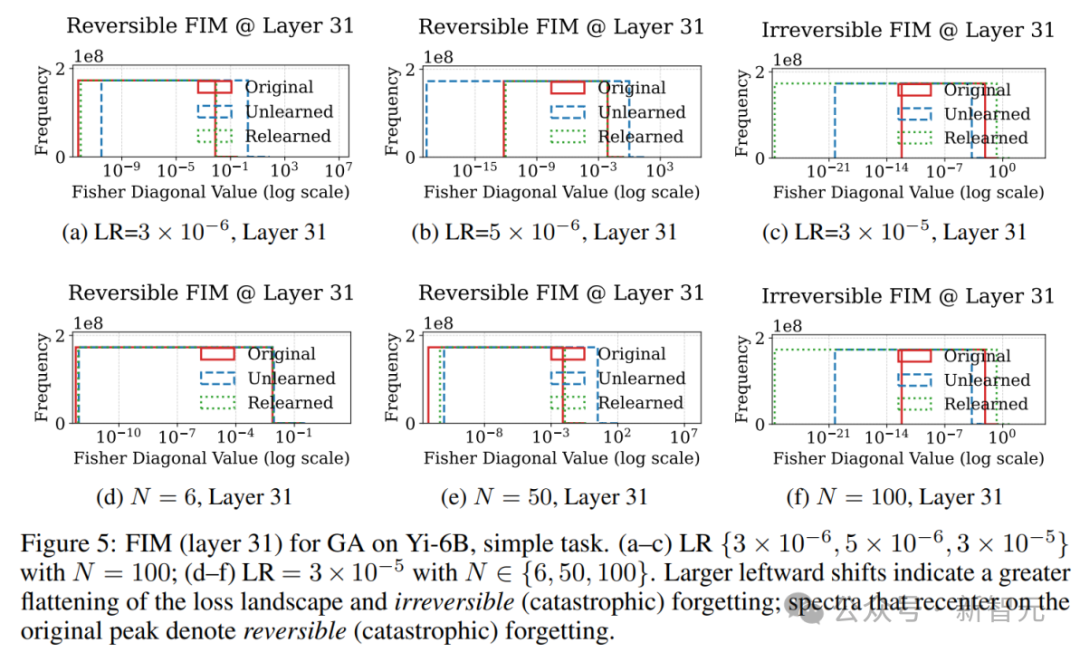
Fisher信息矩阵:重要参数的扰动程度
FIM从参数空间的角度提供了视角,研究人员聚焦Layer 31,观察其Fisher分布是否仍保留原始结构。
更复杂任务:可逆性能否扩展至复杂任务?
在Qwen2.5-7B上,研究人员扩展实验至MATH和GSM8K推理任务。
尽管任务复杂,依然能观察到「受控Relearning」可带来准确率恢复,尤其在可逆场景中甚至超越初始性能。
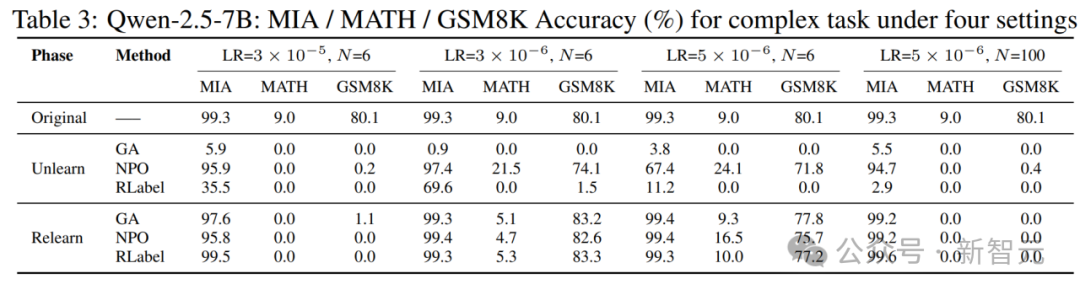
MATH与GSM8K任务下各方法表现对比
结论
研究人员们从结构层面系统剖析了大模型遗忘的可逆性,得出以下核心结论:
持续遗忘风险远高于单次操作,GA/RLabel破坏性强:单次遗忘多数可恢复,而持续性遗忘(如100条请求)易导致彻底崩溃。GA、RLabel易过度遗忘,GA+KL、NPO类方法能显著提高稳定性。
真正的遗忘表现为结构漂移而非输出下降:不可逆遗忘伴随PCA主方向旋转、分布漂移、Fisher质量下降;仅凭token-level指标难以揭示这种深层变化。
遗忘可能带来隐式增强效果:在部分场景中,Relearning后模型对遗忘集的表现优于原始状态,提示Unlearning可能具有对比式正则化或课程学习效果。
结构诊断工具支持可控性遗忘设计:PCA/CKA/FIM不仅揭示是否崩溃,更可定位破坏位置,为实现「可控、局部、不可逆」的安全遗忘机制奠定基础。
参考资料:
https://arxiv.org/abs/2505.16831
文章来自于微信公众号“新智元”。


